深度学习 | 训练网络trick——mixup
1.mixup原理介绍
mixup 论文地址
mixup是一种非常规的数据增强方法,一个和数据无关的简单数据增强原则,其以线性插值的方式来构建新的训练样本和标签。最终对标签的处理如下公式所示,这很简单但对于增强策略来说又很不一般。
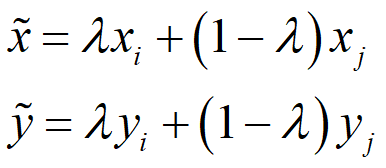

,两个数据对是原始数据集中的训练样本对(训练样本和其对应的标签)。其中是一个服从B分布的参数,
。Beta分布的概率密度函数如下图所示,其中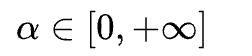
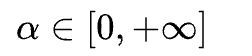
因此,α 是一个超参数,随着α的增大,网络的训练误差就会增加,而其泛化能力会随之增强。而当 α→∞ 时,模型就会退化成最原始的训练策略。
2.mixup的代码实现
如下代码所示,实现mixup数据增强很简单,其实我个人认为这就是一种抑制过拟合的策略,增加了一些扰动,从而提升了模型的泛化能力。
def get_batch(x, y, step, batch_size, alpha=0.2):
"""
get batch data
:param x: training data
:param y: one-hot label
:param step: step
:param batch_size: batch size
:param alpha: hyper-parameter α, default as 0.2
:return:
"""
candidates_data, candidates_label = x, y
offset = (step * batch_size) % (candidates_data.shape[0] - batch_size)
# get batch data
train_features_batch = candidates_data[offset:(offset + batch_size)]
train_labels_batch = candidates_label[offset:(offset + batch_size)]
# 最原始的训练方式
if alpha == 0:
return train_features_batch, train_labels_batch
# mixup增强后的训练方式
if alpha > 0:
weight = np.random.beta(alpha, alpha, batch_size)
x_weight = weight.reshape(batch_size, 1, 1, 1)
y_weight = weight.reshape(batch_size, 1)
index = np.random.permutation(batch_size)
x1, x2 = train_features_batch, train_features_batch[index]
x = x1 * x_weight + x2 * (1 - x_weight)
y1, y2 = train_labels_batch, train_labels_batch[index]
y = y1 * y_weight + y2 * (1 - y_weight)
return x, y
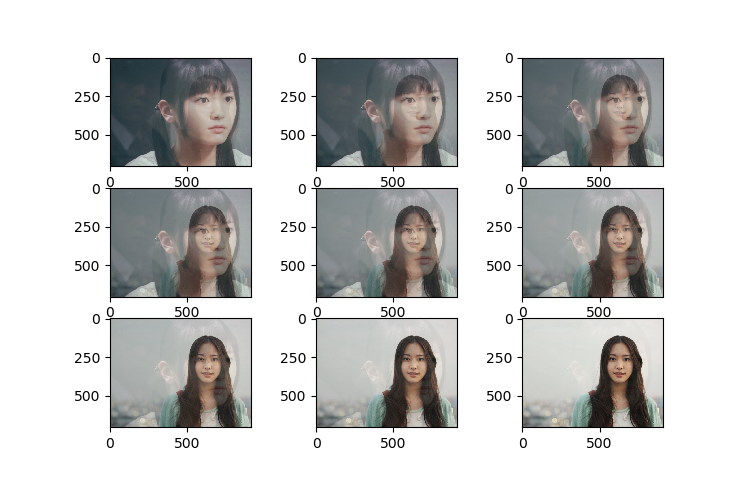
3.mixup增强效果展示
import matplotlib.pyplot as plt
import matplotlib.image as Image
import numpy as np
im1 = Image.imread(r"C:\Users\Daisy\Desktop\1\xyjy.png")
im2 = Image.imread(r"C:\Users\Daisy\Desktop\1\xyjy2.png")
for i in range(1,10):
lam= i*0.1
im_mixup = (im1*lam+im2*(1-lam))
plt.subplot(3,3,i)
plt.imshow(im_mixup)
plt.show()
————————————————————
后来又发现一篇好文:https://www.zhihu.com/question/308572298?sort=created
深度学习 | 训练网络trick——mixup的更多相关文章
- 中文译文:Minerva-一种可扩展的高效的深度学习训练平台(Minerva - A Scalable and Highly Efficient Training Platform for Deep Learning)
Minerva:一个可扩展的高效的深度学习训练平台 zoerywzhou@gmail.com http://www.cnblogs.com/swje/ 作者:Zhouwan 2015-12-1 声明 ...
- TensorRT深度学习训练和部署图示
TensorRT深度学习训练和部署 NVIDIA TensorRT是用于生产环境的高性能深度学习推理库.功率效率和响应速度是部署的深度学习应用程序的两个关键指标,因为它们直接影响用户体验和所提供服务的 ...
- 基于NVIDIA GPUs的深度学习训练新优化
基于NVIDIA GPUs的深度学习训练新优化 New Optimizations To Accelerate Deep Learning Training on NVIDIA GPUs 不同行业采用 ...
- MLPerf结果证实至强® 可有效助力深度学习训练
MLPerf结果证实至强 可有效助力深度学习训练 核心与视觉计算事业部副总裁Wei Li通过博客回顾了英特尔这几年为提升深度学习性能所做的努力. 目前根据英特尔 至强 可扩展处理器的MLPerf结果显 ...
- java web应用调用python深度学习训练的模型
之前参见了中国软件杯大赛,在大赛中用到了深度学习的相关算法,也训练了一些简单的模型.项目线上平台是用java编写的web应用程序,而深度学习使用的是python语言,这就涉及到了在java代码中调用p ...
- 深度学习训练过程中的学习率衰减策略及pytorch实现
学习率是深度学习中的一个重要超参数,选择合适的学习率能够帮助模型更好地收敛. 本文主要介绍深度学习训练过程中的6种学习率衰减策略以及相应的Pytorch实现. 1. StepLR 按固定的训练epoc ...
- 【Deeplearning】(转)深度学习知识网络
转自深度学习知识框架,小象牛逼! 图片来自小象学院公开课,下面直接解释几条线 神经网络 线性回归 (+ 非线性激励) → 神经网络 有线性映射关系的数据,找到映射关系,非常简单,只能描述简单的映射关系 ...
- 一天搞懂深度学习-训练深度神经网络(DNN)的要点
前言 这是<一天搞懂深度学习>的第二部分 一.选择合适的损失函数 典型的损失函数有平方误差损失函数和交叉熵损失函数. 交叉熵损失函数: 选择不同的损失函数会有不同的训练效果 二.mini- ...
- 深度学习卷积网络中反卷积/转置卷积的理解 transposed conv/deconv
搞明白了卷积网络中所谓deconv到底是个什么东西后,不写下来怕又忘记,根据参考资料,加上我自己的理解,记录在这篇博客里. 先来规范表达 为了方便理解,本文出现的举例情况都是2D矩阵卷积,卷积输入和核 ...
随机推荐
- DEP(Data Execution Prevention) 数据执行保护
1.原理 数据执行保护,简称“DEP”,英文全称为“Data Execution Prevention”,是一组在存储器上运行额外检查的硬件和软件技术,有助于防止恶意程序码在系统上运行. 此技术由Mi ...
- GPO - Set Date and Time for Updates
For Windows Update, the limitation normally is a time window, disk space, network bandwidth. Create ...
- JavaWeb基础(day15)( http + tomcat + servlet + 响应)
HTTP+Tomcat+Servlet+响应 HTTP HTTP 超文本传输协议(Hyper Text Transfer Protocol ),一种网络协议. 协议的组成和过程 HTTP协议由 ...
- try-catch- finally块中, finally块唯一不执行的情况是什么?
除非在try块或者catch块中调用了退出虚拟机的方法(即System.exit(1);),否则不管在try块.catch块中执行怎样的代码,出现怎样的情况,异常处理的finally块总是会被执行的 ...
- 012.Nginx负载均衡
一 负载均衡概述 1.1 负载均衡介绍 负载均衡是将负载分摊到多个操作单元上执行,从而提高服务的可用性和响应速度,带给用户更好的体验.对于Web应用,通过负载均衡,可以将一台服务器的工作扩展到多台服务 ...
- vue 应用 :关于 ElementUI 的 message 组件
我们知道,这个东西的基本用法是这样的: this.$message({ message: '恭喜你,这是一条成功消息', type: 'success' }); 但是我觉得这样还是有点麻烦,所以我决定 ...
- Python API 操作Hadoop hdfs详解
1:安装 由于是windows环境(linux其实也一样),只要有pip或者setup_install安装起来都是很方便的 >pip install hdfs 2:Client——创建集群连接 ...
- python-多任务编程03-迭代器(iterator)
迭代器是一个可以记住遍历的位置的对象.迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束.迭代器只能往前不会后退. 可迭代对象(Iterable) 能够被循环遍历(迭代)的对象称为可迭代 ...
- DJANGO-天天生鲜项目从0到1-009-购物车-Ajax实现添加至购物车功能
本项目基于B站UP主‘神奇的老黄’的教学视频‘天天生鲜Django项目’,视频讲的非常好,推荐新手观看学习 https://www.bilibili.com/video/BV1vt41147K8?p= ...
- java判断当前系统是win还是linux
private static final boolean isWin = System.getProperty("os.name").toLowerCase().contains( ...