Shell编程—sed进阶
1多行命令
sed编辑器包含了三个可用来处理多行文本的特殊命令。
- N:将数据流中的下一行加进来创建一个多行组来处理。
- D:删除多行组中的一行。
- P:打印多行组中的一行。
1.1next命令
1. 单行的next命令
小写的n命令会告诉sed编辑器移动到数据流中的下一文本行,而不用重新回到命令的 开始再执行一遍。
- $ cat data1.txt
- This is the header line.
- This is a data line.
- This is the last line.
- $
- $ sed '/^$/d' data1.txt
- This is the header line.
- This is a data line.
- This is the last line.
由于要删除的行是空行,没有任何能够标示这种行的文本可供查找。解决办法是用n命令。在这个例子中,脚本要查找含有单词header的那一行。找到之后,n命令会让sed编辑器移动到文本的下一行,也就是那个空行。
- $ sed '/header/{n ; d}' data1.txt
- This is the header line.
- This is a data line.
- This is the last line.
2. 合并文本行
下面的例子演示了N命令的工作方式。
- $ cat data2.txt
- This is the header line.
- This is the first data line.
- This is the second data line.
- This is the last line.
- $
- $ sed '/first/{ N ; s/\n/ / }' data2.txt
- This is the header line.
- This is the first data line. This is the second data line.
- This is the last line.
sed编辑器脚本查找含有单词first的那行文本。找到该行后,它会用N命令将下一行合并到那行,然后用替换命令s将换行符替换成空格。结果是,文本文件中的两行在sed编辑器的输出中成了一行。
如果要在数据文件中查找一个可能会分散在两行中的文本短语的话,这是个很实用的应用程序。这里有个例子。
- $ cat data3.txt
- On Tuesday, the Linux System
- Administrator's group meeting will be held.
- All System Administrators should attend.
- Thank you for your attendance.
- $
- $ sed 'N ; s/System Administrator/Desktop User/' data3.txt
- On Tuesday, the Linux System
- Administrator's group meeting will be held.
- All Desktop Users should attend.
- Thank you for your attendance.
- $
替换命令会在文本文件中查找特定的双词短语System Administrator。如果短语在一行中的话,事情很好处理,替换命令可以直接替换文本。但如果短语分散在两行中的话,替换命令就没法识别匹配的模式了。这时N命令就可以派上用场了。
- $ sed 'N ; s/System.Administrator/Desktop User/' data3.txt
- On Tuesday, the Linux Desktop User's group meeting will be held.
- All Desktop Users should attend.
- Thank you for your attendance.
- $ cat data4.txt
- On Tuesday, the Linux System
- Administrator's group meeting will be held.
- All System Administrators should attend.
- $
- $ sed 'N
- > s/System\nAdministrator/Desktop\nUser/
- > s/System Administrator/Desktop User/
- > ' data4.txt
- On Tuesday, the Linux Desktop
- User's group meeting will be held.
- All System Administrators should attend.
- $ sed 'N ; s/System.Administrator/Desktop User/' data3.txt
- On Tuesday, the Linux Desktop User's group meeting will be held.
- All Desktop Users should attend.
- Thank you for your attendance.
- $ cat data4.txt
- On Tuesday, the Linux System
- Administrator's group meeting will be held.
- All System Administrators should attend.
- $
- $ sed 'N
- > s/System\nAdminis
由于System Administrator文本出现在了数据流中的 后一行,N命令会错过它,因为没有其他行可读入到模式空间跟这行合并。你可以轻松地解决这个问题——将单行命令放到N命令前面,并将多行命令放到N命令后面,像这样:
- $ sed '
- > s/System Administrator/Desktop User/
- > N
- > s/System\nAdministrator/Desktop\nUser/
- > ' data4.txt
- On Tuesday, the Linux Desktop
- User's group meeting will be held.
- All Desktop Users should attend.
1.2多行删除命令
删除命令d和N命令一起使用:
- $ sed 'N ; /System\nAdministrator/d' data4.txt
- All System Administrators should attend.
sed编辑器提供了多行删除命令D,它只删除模式空间中的第一行。该命令会删除到换行符(含换行符)为止的所有字符。
- $ sed 'N ; /System\nAdministrator/D' data4.txt
- Administrator's group meeting will be held.
All System Administrators should attend.
文本的第二行被N命令加到了模式空间,但仍然完好。如果需要删掉目标数据字符串所在行的前一文本行,它能派得上用场。这里有个例子,它会删除数据流中出现在第一行前的空白行。
- $ cat data5.txt
- This is the header line.
- This is a data line.
- This is the last line.
- $
- $ sed '/^$/{N ; /header/D}' data5.txt
- This is the header line.
- This is a data line.
- This is the last line.
1.3多行打印命令
多行打印命令(P)沿用了同样的方法。它只打印多行模式空间中的第一行。这包括模式空间中直到换行符为止的所有字符。
- $ sed -n 'N ; /System\nAdministrator/P' data3.txt
- On Tuesday, the Linux System
2保持空间
模式空间(pattern space)是一块活跃的缓冲区,在sed编辑器执行命令时它会保存待检查的文本。但它并不是sed编辑器保存文本的唯一空间。sed编辑器有另一块称作保持空间的缓冲区域。在处理模式空间中的某些行时,可以用保持空间来临时保存一些行。有5条命令可用来操作保持空间:
|
命 令 |
描 述 |
|
h |
将模式空间复制到保持空间 |
|
H |
将模式空间附加到保持空间 |
|
g |
将保持空间复制到模式空间 |
|
G |
将保持空间附加到模式空间 |
|
x |
交换模式空间和保持空间的内容 |
- $ cat data2.txt
- This is the header line.
- This is the first data line.
- This is the second data line.
- This is the last line.
- $
- $ sed -n '/first/ {h ; p ; n ; p ; g ; p }' data2.txt
- This is the first data line.
- This is the second data line.
- This is the first data line.
(1) sed脚本在地址中用正则表达式来过滤出含有单词first的行;
(2) 当含有单词first的行出现时,h命令将该行放到保持空间;
(3) p命令打印模式空间也就是第一个数据行的内容;
(4) n命令提取数据流中的下一行(This is the second data line),并将它放到模式空间;
(5) p命令打印模式空间的内容,现在是第二个数据行;
(6) g命令将保持空间的内容(This is the first data line)放回模式空间,替换当前文本;
(7) p命令打印模式空间的当前内容,现在变回第一个数据行了。
3排除命令
感叹号命令(!)用来排除(negate)命令,也就是让原本会起作用的命令不起作用。下面的例子演示了这一特性。
- $ sed -n '/header/!p' data2.txt
- This is the first data line.
- This is the second data line.
- This is the last line.
普通p命令只打印data2文件中包含单词header的那行。加了感叹号之后,情况就相反了:除了包含单词header那一行外,文件中其他所有的行都被打印出来了。
- $ sed 'N;
- > s/System\nAdministrator/Desktop\nUser/
- > s/System Administrator/Desktop User/
- > ' data4.txt
- On Tuesday, the Linux Desktop
- User's group meeting will be held.
- All System Administrators should attend.
- $
- $ sed '$!N;
- > s/System\nAdministrator/Desktop\nUser/
- > s/System Administrator/Desktop User/
- > ' data4.txt
- On Tuesday, the Linux Desktop
- User's group meeting will be held.
- All Desktop Users should attend.
这个例子演示了如何配合使用感叹号与N命令以及与美元符特殊地址。美元符表示数据流中的 后一行文本,所以当sed编辑器到了 后一行时,它没有执行N命令,但它对所有其他行都执行了这个命令。
反转数据流中文本行的顺序:
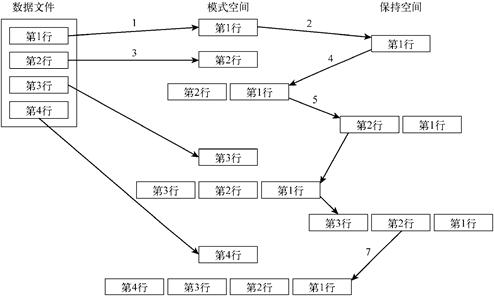
- $ cat data2.txt
- This is the header line.
- This is the first data line.
- This is the second data line.
- This is the last line.
- $
- $ sed -n '{1!G ; h ; $p }' data2.txt
- This is the last line.
- This is the second data line.
- This is the first data line.
- This is the header line.
4改变流
4.1分支
分支(branch)命令b的格式如下:
- [address]b [label]
address参数决定了哪些行的数据会触发分支命令。label参数定义了要跳转到的位置。如果没有加label参数,跳转命令会跳转到脚本的结尾。
- $ cat data2.txt
- This is the header line.
- This is the first data line.
- This is the second data line.
- This is the last line.
- $$ sed '{2,3b ; s/This is/Is this/ ; s/line./test?/}' data2.txt
- Is this the header test?
- This is the first data line.
- This is the second data line.
- Is this the last test?
分支命令在数据流中的第2行和第3行处跳过了两个替换命令。
要是不想直接跳到脚本的结尾,可以为分支命令定义一个要跳转到的标签。标签以冒号开始,多可以是7个字符长度。
- :label2
要指定标签,将它加到b命令后即可。使用标签允许你跳过地址匹配处的命令,但仍然执行脚本中的其他命令。
- $ sed '{/first/b jump1 ; s/This is the/No jump on/
- > :jump1
- > s/This is the/Jump here on/}' data2.txt
- No jump on header line
- Jump here on first data line
- No jump on second data line
- No jump on last line
跳转命令指定如果文本行中出现了first,程序应该跳到标签为jump1的脚本行。如果分支命令的模式没有匹配,sed编辑器会继续执行脚本中的命令,包括分支标签后的命令(因此,所有的替换命令都会在不匹配分支模式的行上执行)。如果某行匹配了分支模式, sed编辑器就会跳转到带有分支标签的那行。因此,只有 后一个替换命令会执行。
- $ echo "This, is, a, test, to, remove, commas." | sed -n '{
- > :start
- > s/,//1p
- > b start
- > }'
- This is, a, test, to, remove, commas.
- This is a, test, to, remove, commas.
- This is a test, to, remove, commas.
- This is a test to, remove, commas.
- This is a test to remove, commas.
- This is a test to remove commas.
- ^C
脚本的每次迭代都会删除文本中的第一个逗号,并打印字符串。这个脚本有个问题:它永远不会结束。这就形成了一个无穷循环,不停地查找逗号,直到使用Ctrl+C组合键发送一个信号,手动停止这个脚本。
要防止这个问题,可以为分支命令指定一个地址模式来查找。如果没有模式,跳转就应该 结束。
- $ echo "This, is, a, test, to, remove, commas." | sed -n '{
- > :start
- > s/,//1p
- > b start
- > }'
- This is, a, test, to, remove, commas.
- This is a, test, to, remove, commas.
- This is a test, to, remove, commas.
- This is a test to, remove, commas.
- This is a test to remove, commas.
- This is a test to remove commas.
- ^C
4.2测试
测试命令(t)也可以用来改变sed编辑器脚本的执行流程。测试命令会根据替换命令的结果跳转到某个标签,而不是根据地址进行跳转。如果替换命令成功匹配并替换了一个模式,测试命令就会跳转到指定的标签。如果替换命令未能匹配指定的模式,测试命令就不会跳转。测试命令使用与分支命令相同的格式。
- [address]t [label]
跟分支命令一样,在没有指定标签的情况下,如果测试成功,sed会跳转到脚本的结尾。
- $ sed '{
- > s/first/matched/
- > t
- > s/This is the/No match on/
- > }' data2.txt
- No match on header line
- This is the matched data line
- No match on second data line
- No match on last line
第一个替换命令会查找模式文本first。如果匹配了行中的模式,它就会替换文本,而且测试命令会跳过后面的替换命令。如果第一个替换命令未能匹配模式,第二个替换命令就会被执行。有了测试命令,你就能结束之前用分支命令形成的无限循环。
- $ echo "This, is, a, test, to, remove, commas. " | sed -n '{
- > :start
- > s/,//1p
- > t start
- > }'
- This is, a, test, to, remove, commas.
- This is a, test, to, remove, commas.
- This is a test, to, remove, commas.
- This is a test to, remove, commas.
- This is a test to remove, commas.
- This is a test to remove commas.
当无需替换时,测试命令不会跳转而是继续执行剩下的脚本。
5模式替代
5.1&符号
&符号可以用来代表替换命令中的匹配的模式。不管模式匹 4配的是什么样的文本,你都可以在替代模式中使用&符号来使用这段文本。
- $ echo "The cat sleeps in his hat." | sed 's/.at/"&"/g'
The "cat" sleeps in his "hat".
$
5.2替代单独的单词
sed编辑器用圆括号来定义替换模式中的子模式。你可以在替代模式中使用特殊字符来引用每个子模式。替代字符由反斜线和数字组成。数字表明子模式的位置。sed编辑器会给第一个子模式分配字符\1,给第二个子模式分配字符\2,依此类推。
来看一个在sed编辑器脚本中使用这个特性的例子。
- $ echo "The System Administrator manual" | sed '
- > s/\(System\) Administrator/\1 User/'
- The System User manual
这个替换命令用一对圆括号将单词System括起来,将其标示为一个子模式。然后它在替代模式中使用\1来提取第一个匹配的子模式。
- $ echo "That furry cat is pretty" | sed 's/furry \(.at\)/\1/'
- That cat is pretty
- $
- $ echo "That furry hat is pretty" | sed 's/furry \(.at\)/\1/'
- That hat is pretty
在这种情况下,你不能用&符号,因为它会替换整个匹配的模式。子模式提供了答案,允许你选择将模式中的某部分作为替代模式。
当需要在两个或多个子模式间插入文本时,这个特性尤其有用。这里有个脚本,它使用子模式在大数字中插入逗号。
- $ echo "" | sed '{
- > :start
- > s/\(.*[0-9]\)\([0-9]\{3\}\)/\1,\2/
- > t start
- > }'
- 1,234,567
这个脚本将匹配模式分成了两部分。
.*[0-9]
[0-9]{3}
这个模式会查找两个子模式。第一个子模式是以数字结尾的任意长度的字符。第二个子模式是若干组三位数字。如果这个模式在文本中找到了,替代文本会在两个子模式之间加一个逗号,每个子模式都会通过其位置来标示。
6 在脚本中使用 sed
6.1使用包装脚本
在shell脚本中,可以将普通的shell变量及参数和sed编辑器脚本一起使用。这里有个将命令行参数变量作为sed脚本输入的例子。
- $ cat reverse.sh
- #!/bin/bash
- # Shell wrapper for sed editor script.
- # to reverse text file lines. sed -n '{ 1!G ; h ; $p }' $1
名为reverse的shell脚本用sed编辑器脚本来反转数据流中的文本行。它使用shell参数$1从命令行中提取第一个参数,这正是需要进行反转的文件名。
- $ ./reverse.sh data2.txt
- This is the last line.
- This is the second data line.
- This is the first data line.
- This is the header line.
现在你能在任何文件上轻松使用这个sed编辑器脚本,再不用每次都在命令行上重新输入了。
6.2重定向 sed 的输出
用sed脚本来向数值计算的阶乘结果添加逗号。
- $ cat fact.sh
- #!/bin/bash
- # Add commas to number in factorial answer
- factorial=1
- counter=1
- number=$1
- while [ $counter -le $number ]
- do
- factorial=$[ $factorial * $counter ]
- counter=$[ $counter + 1 ]
- done
- result=$(echo $factorial | sed '{
- :start
- s/\(.*[0-9]\)\([0-9]\{3\}\)/\1,\2/ t
- start
- }')
- echo "The result is $result"
- #
- $ ./fact.sh 20
- The result is 2,432,902,008,176,640,000
Shell编程—sed进阶的更多相关文章
- shell编程基础进阶
为什么学习shell编程 shell脚本语言是实现linux/unix 系统管理机自动化运维所必备的重要工具,linux/unix系统的底层及基础应用软件的核心大部分涉及shell脚本的内容.每一个合 ...
- Shell编程—sed和gawk
1文本处理 1.1sed 编辑器 sed编辑器被称作流编辑器(stream editor),和普通的交互式文本编辑器恰好相反.在交互式文本编辑器中(比如vim),你可以用键盘命令来交互式地插入.删除或 ...
- shell编程sed笔记
源文件的内容 <modules> <module name="provider"> <!--发布模式--> <bds_mode/> ...
- shell编程awk进阶
awk操作符 算术操作符: x+y, x-y, x*y, x/y, x^y, x%y -x: 转换为负数 +x: 转换为数值 字符串操作符:没有符号的操作符,字符串连接 赋值操作 ...
- shell编程——sed用法之参数详解
sed格式: sed 参数 '正则表达式' 文件名 sed的常见参数有以下几种: 1.-n, --quiet, --silent 取消自动打印模式 不加n默认打印整个文件: [root@localho ...
- shell编程——sed用法
一.sed格式: sed 参数 '正则表达式' 文件名 演示文件的内容: [root@localhost ~]# cat test.sh #!/bin/bash 第一行 12345! 第二行 2345 ...
- Linux Shell编程 sed命令
概述 sed 是一种几乎可以应用在所有 UNIX 平台(包括 Linux)上的轻量级流编辑器,体积小.所以,它可以对从如管道这样的标准输入中接收的数据进行编辑. sed 主要是用来将数据进行选取.替换 ...
- Shell编程—gawk进阶
1使用变量 awk编程语言支持两种不同类型的变量: 内建变量 自定义变量 1.1内建变量 1. 字段和记录分隔符变量 数据字段变量允许你使用美元符号($)和字段在该记录中的位置值来引用记录对应的字段. ...
- 《Linux命令行与shell脚本编程大全》第二十一章 sed进阶
本章介绍一些sed编辑器提供的高级特性. 21.1 多行命令 按照之前的知识,所有的sed编辑器命令都是针对单行数据执行操作的. 在sed编辑器读取数据流时,它会基于换行符的位置将数据分成行,一次处理 ...
随机推荐
- OpenFeign使用步骤
1. 新建 cloud-consumer-feign-order80 2. pom.xml <?xml version="1.0" encoding="UTF-8& ...
- 3-Pandas之Series和DataFrame区别
一.Pandas pandas的数据元素包括以下几种类型: 类型 说明 object 字符串或混合类型 int 整型 float 浮点型 datetime 时间类型 bool 布尔型 二.Series ...
- PHP restore_error_handler() 函数
定义和用法 restore_error_handler() 函数恢复之前的错误处理程序. 该函数用于在通过 set_error_handler() 函数改变后恢复之前的错误处理程序. 该函数总是返回 ...
- PHP max() 函数
实例 通过 max() 函数查找最大值: <?phpecho(max(2,4,6,8,10) . "<br>");echo(max(22,14,68,18,15) ...
- IC行业常见用语
https://www.cnblogs.com/yeungchie/ Active Devices 有源器件 MOSFET Metal-Oxide-Semicoductor Field-Effect ...
- EC R 87 div2 D. Multiset 线段树 树状数组 二分
LINK:Multiset 主要点一下 二分和树状数组找第k大的做法. 线段树的做法是平凡的 开一个数组实现就能卡过. 考虑如树状数组何找第k大 二分+查询来判定是不优秀的. 考虑树状数组上倍增来做. ...
- 10分钟了解js的宏任务和微任务
熟悉宏任务和微任务以及js(nodejs)事件循环机制,在写业务代码还是自己写库,或者看源码都是那么重要 看了部分文档,自己总结和实践了一下 js中同步任务.宏任务和微任务介绍 同步任务: 普通任务 ...
- LeetCode(2)---路径总和
给定一个二叉树和一个目标和,判断该树中是否存在根节点到叶子节点的路径,这条路径上所有节点值相加等于目标和. 说明: 叶子节点是指没有子节点的节点. 示例: 给定如下二叉树,以及目标和 sum = ...
- Nginx介绍,安装,配置
引言 为什么要学习Nginx 问题一: 客户端到底要将请求发送给哪台服务器? 问题二: 如果所有客户端的请求都发送给了服务器1,那另一台岂不是废了 问题三: 客户端发送的请求可能是申请动态资源的,也可 ...
- 2020-04-07:假如你们系统接收十几种报文,用什么方式对应的各自的service,总不能都用if-else判断吧
福哥答案2020-04-08: 策略,工厂.