Pytorch_第七篇_深度学习 (DeepLearning) 基础 [3]---梯度下降
深度学习 (DeepLearning) 基础 [3]---梯度下降法
Introduce
在上一篇“深度学习 (DeepLearning) 基础 [2]---神经网络常用的损失函数”中我们介绍了神经网络常用的损失函数。本文将继续学习深度学习的基础知识,主要涉及基于梯度下降的一类优化算法。首先介绍梯度下降法的主要思想,其次介绍批量梯度下降、随机梯度下降以及小批量梯度下降(mini-batch)的主要区别。
以下均为个人学习笔记,若有错误望指出。
梯度下降法
主要思想:沿着梯度反方向更新相关参数,使得代价函数逐步逼近最小值。
思路历程:
假设给我们一个损失函数,我们怎么利用梯度下降法找到函数的最小值呢(换一种说法,即如何找到使得函数最小的参数x)?首先,我们应该先清楚函数的最小值一般位于哪里。按我的理解应该是在导数为0的极值点,然而极值点又不一定都是最小值点,可能是局部极小值点。那么,既然知道了最小值点在某个极值点(梯度为0),那么我们使得损失函数怎么逼近这个极值点呢?
现在我们反过来思考上述梯度下降法的主要思想。首先,要理解这个主要思想,我们需要理解梯度方向是什么。梯度方向指的是曲面当前点方向导数最大值的方向(指向函数值增大的方向)。假设我们现在处在函数上x=xt这个点(梯度不为0,不是极值点),因此现在我们需要确定增加x还是减少x能帮忙我们逼近函数的最小值。前面说过梯度方向指向函数值增大的方向,因此我们只要往梯度的反方向更新x,就能找到极小值点。(可能还是有点迷,下面结合例子具体看梯度下降的执行过程来理解其主要思想)
(note: 由于凸函没有局部极小值,因此梯度下降法可以有效找到全局最小值,对于非凸函数,梯度下降法可能陷入局部极小值。)
举个梨子:
假设有一个损失函数如下(当x=0的时候取得最小值,我们称x=0为最优解):
\]
我们需要利用梯度下降法更新参数x的值使得损失函数y达到最小值。首先我们随机初始化参数x,假设我们初始化参数x的值为xt,如下图所示:
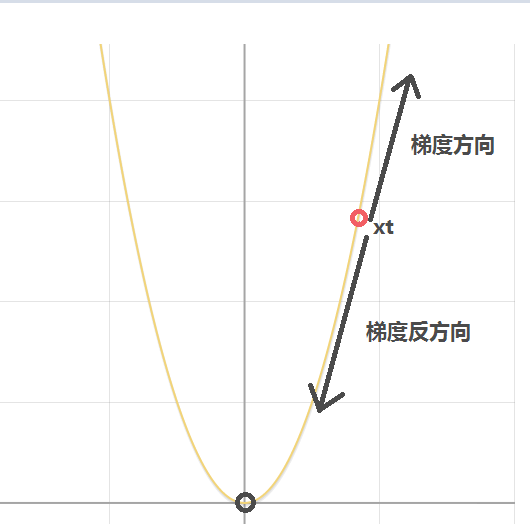
现在问题转化为我们怎么更新参数x的值(当前为xt)使得其越来越靠近使得函数达到最小值的最优参数x。直观上看我们需要减小x的值,才能使得其越来越靠近最优参数。
现在我们求取y对参数x的导(当有多个参数时,为偏导),如下:
\]
由于xt>0,因此当我们代入xt到y',我们可以发现在点xt处导数(梯度)为正值,所指方向为图中所示的梯度方向。很明显,我们不能随着梯度指示的方向更新参数x,而应该往梯度方向的负方向更新。如上图所示,很明显,应该减小x的值才能慢慢靠近最优解。因此,不难给出参数x的更新公式(即梯度下降的参数一般更新公式)如下(α为学习率):
\]
我们来验证上述更新公式。
- 当x=xt(xt>0)(位于y轴右边),则在x处的导数也大于0,由更新公式,下一时刻的x会减少(如上图所示x=xt减少会越来越靠近最优解x=0)。
- 当x=-xt(xt>0)(位于y轴左边),则在x处的导数也小于0,代入更新公式,我们发现下一时刻x会增加(如上图所示x=-xt增加会越来越靠近最优解x=0)。因此推导出的梯度下降参数更新公式符合我们的目标。
- 因此不断对参数x对上述更新,最终x的值会慢慢靠近最优解x=0.
上述便是梯度下降法的原理了,只不过举的例子比较简单,多参数(如神经网络中的参数w和b)的可以类似推理。
一个注意点:假设我们现在处在x=xt这个点,若学习率α设置过大,虽然收敛速度可能会加快(每次跨步大),但是xt也可能会过度更新,即(一次性减得太多)可能会越过最优解(跑到最优解的左边),再一次更新的话也可能会再次越过最优解(一次性加得太多,跑到最优解的右边),emmm,就这样反复横跳,始终达不到最优解。另外,学习率设置太小的话,x虽然更可能达到最优解,但是算法收敛太慢(x的每一个跨步太短)。对于学习率的选择,可以按0.001、0.01、0.1、1.0这样子来筛选。
现在依次介绍三种类型的梯度下降法,批量梯度下降、随机梯度下降以及小批量梯度下降。 以下介绍均以Logistic回归模型的损失函数(凸函数)为例,如下:
\]
\]
\]
其中input = (x1,x2)为输入的训练样本。我们的目标是在训练样本集(假设有N个训练样本)上寻找最优参数w1、w2以及b使得损失函数在训练样本上达到最小的损失。(神经网络的训练过程过程就是输入训练样本,计算损失,损失函数反向对待更新参数求梯度,其次按照梯度下降法的参数更新公式朝着梯度反方向更新所有参数,如此往复,直到找到使得损失最小的最优参数或者达到最大迭代次数)(注意到损失函数上还有一个常量n我们没有解释,其实我觉得以下三个基于梯度下降的优化算法主要区别就是在n的取值上)
批量梯度下降(n=N的情况)
对于上述问题,批量梯度下降的做法是什么样的呢?其每次将整个训练样本集都输入神经网络模型,然后对每个训练样本都求得一个损失,对N个损失加权求和取平均,然后对待更新参数求导数,其次按照梯度下降法的参数更新公式朝着梯度反方向更新所有参数。通俗来讲就是每次更新参数都用到了所有训练样本(等价于上述损失公式中的n=N)。每一轮参数更新中,每个训练样本对参数更新都有贡献(每一个样本都给了参数更新一定的指导信息),因此理论上每一轮参数更新提供的信息是很丰富的,参数更新的幅度也是比较大的,使得参数更新能在少数几轮迭代中就达到收敛(对于凸优化问题能达到全局最优)。然而,对于大数据时代,训练样本可能有很多很多,每轮都是用那么多的样本进行参数更新的指导的话,更新一次(一次epoch)会非常非常久,这是这种方法的主要缺点。
随机梯度下降(n=1的情况)
对于上述优化问题,随机梯度下降(SGD)与批量梯度下降法的主要区别就是, SGD每一轮参数更新都只用一个训练样本来指导参数更新(n=1)。也就是说每次只计算出了某训练样本的损失,并进行反向传播指导参数更新。其优点是每一轮迭代的时间开销非常低(因为只用到了一个训练样本)。然而一个训练样本提供的信息可能比较局限,即其可能使得某次参数更新方向并不是朝着全局最优的方向(如噪声样本提供的信息可能就是错误的,导致其往偏离全局最优的方向更新),但是整体上是朝着全局最优的方向的。虽然随机梯度下降可能最终只能达到全局最优附近的某个值,但是相对于批量梯度下降来说最好的地方就是速度很快,因此基于精度和效率权衡,更常用的还是SGD。
小批量(mini-batch)梯度下降(n=num_batch)
小批量梯度下降是上述两种方法的一个折中,即既考虑精度也考虑了收敛速度。那么折中方法是怎么做的呢?首先小批量梯度需要设置一个批量的大小(假设是num_batch),然后每次选取一个批量的训练样本,计算得到num_batch个损失,求和取平均后反向传播来指导参数更新(n=num_batch)。通俗来说就是每一轮的参数更新我们既不是用上整个训练样本集(时间开销大),也不是只用一个训练样本(可能提供错误信息),我们是使用一个小批量的样本(1<n<N)来指导参数更新。虽然可能效果没有批量梯度下降法好,速度没有随机梯度下降法快,但是这种方法在精度和收敛速度上是一个很好的折中。因此,在深度学习中,用得比较多的一般还是小批量(mini-batch)梯度下降。
Pytorch_第七篇_深度学习 (DeepLearning) 基础 [3]---梯度下降的更多相关文章
- Pytorch_第八篇_深度学习 (DeepLearning) 基础 [4]---欠拟合、过拟合与正则化
深度学习 (DeepLearning) 基础 [4]---欠拟合.过拟合与正则化 Introduce 在上一篇"深度学习 (DeepLearning) 基础 [3]---梯度下降法" ...
- Pytorch_第六篇_深度学习 (DeepLearning) 基础 [2]---神经网络常用的损失函数
深度学习 (DeepLearning) 基础 [2]---神经网络常用的损失函数 Introduce 在上一篇"深度学习 (DeepLearning) 基础 [1]---监督学习和无监督学习 ...
- Pytorch_第五篇_深度学习 (DeepLearning) 基础 [1]---监督学习与无监督学习
深度学习 (DeepLearning) 基础 [1]---监督学习与无监督学习 Introduce 学习了Pytorch基础之后,在利用Pytorch搭建各种神经网络模型解决问题之前,我们需要了解深度 ...
- 深度学习必备:随机梯度下降(SGD)优化算法及可视化
补充在前:实际上在我使用LSTM为流量基线建模时候,发现有效的激活函数是elu.relu.linear.prelu.leaky_relu.softplus,对应的梯度算法是adam.mom.rmspr ...
- 吴恩达深度学习:2.3梯度下降Gradient Descent
1.用梯度下降算法来训练或者学习训练集上的参数w和b,如下所示,第一行是logistic回归算法,第二行是成本函数J,它被定义为1/m的损失函数之和,损失函数可以衡量你的算法的效果,每一个训练样例都输 ...
- Pytorch_第十篇_卷积神经网络(CNN)概述
卷积神经网络(CNN)概述 Introduce 卷积神经网络(convolutional neural networks),简称CNN.卷积神经网络相比于人工神经网络而言更适合于图像识别.语音识别等任 ...
- (zhuan) 126 篇殿堂级深度学习论文分类整理 从入门到应用
126 篇殿堂级深度学习论文分类整理 从入门到应用 | 干货 雷锋网 作者: 三川 2017-03-02 18:40:00 查看源网址 阅读数:66 如果你有非常大的决心从事深度学习,又不想在这一行打 ...
- 2020年深度学习DeepLearning技术实战班
深度学习DeepLearning核心技术实战2020年01月03日-06日 北京一.深度学习基础和基本思想二.深度学习基本框架结构 1,Tensorflow2,Caffe3,PyTorch4,MXNe ...
- 深度学习DeepLearning核心技术理论与实践
深度学习DeepLearning核心技术开发与应用时间地点:2019年11月01日-04日(北京) 联系人杨老师 电话(同微信)17777853361
随机推荐
- python数据处理(八)之展示数据
1.前言 1.1.不要擅自假定要讲的故事和数据是一致的,要先研究数据,然后讲述数据研究所得 1.2.讲故事是成为领域专家的重要部分. 1.3.将故事方法: a. 确定想要讲的故事 b.无论选择什么方式 ...
- 06 drf源码剖析之权限
06 drf源码剖析之权限 目录 06 drf源码剖析之权限 1. 权限简述 2. 权限使用 3.源码剖析 4. 总结 1. 权限简述 权限与身份验证和限制一起,决定了是否应授予请求访问权限. 权限检 ...
- L-BFGS算法详解(逻辑回归的默认优化算法)
python信用评分卡建模(附代码,博主录制) https://study.163.com/course/introduction.htm?courseId=1005214003&utm_ca ...
- bzoj1742[Usaco2005 nov]Grazing on the Run 边跑边吃草*&&bzoj3074[Usaco2013 Mar]The Cow Run*
bzoj1742[Usaco2005 nov]Grazing on the Run 边跑边吃草 bzoj3074[Usaco2013 Mar]The Cow Run 题意: 数轴上有n棵草,牛初始在L ...
- bzoj2016[Usaco2010]Chocolate Eating*
bzoj2016[Usaco2010]Chocolate Eating 题意: n块巧克力,每次吃可以增加ai点快乐,每天早晨睡觉起来快乐值会减半,求如何使d天睡觉前的最小快乐值最大.n,d≤5000 ...
- toad for oracle 小技巧
在SQL*LOADER 工具上(或者称为SQLLDR,读为:“sequel loader”),因为它仍然是装载数据的主要方法,SQLLDR 能够在极短的时间内装 载庞大数量的数据. 我也是初使用,理解 ...
- OSCP Learning Notes - Post Exploitation(1)
Linux Post Exploitation Target Sever: Kioptrix Level 1 1. Search the payloads types. msfvenom -l pay ...
- Saas Erp以及分销 助手
首先贴一下相关的截图 SaasErp 登陆页 Saas Erp主页 Saas Erp 其中的商品页 Saas Erp 打印模板设计页 分销助手登录页/手势密码页/主页 1.SaaS是Software ...
- MapReduce之自定义分区器Partitioner
@ 目录 问题引出 默认Partitioner分区 自定义Partitioner步骤 Partition分区案例实操 分区总结 问题引出 要求将统计结果按照条件输出到不同文件中(分区). 比如:将统计 ...
- 题解 CF510E 【Fox And Dinner】
可以用网络流解决这个题. 注意到\(a_i \geqslant 2\),所以当相邻数字要和为质数时,这两个数要一个为奇数,一个为偶数. 所以就先将所有数按奇偶分为两列,其就构成了一个二分图,二分图中和 ...