机器学习入门实战——基于knn的airbnb房租预测
数据读取
import pandas as pd
features=['accommodates','bathrooms','bedrooms','beds','price','minimum_nights','maximum_nights','number_of_reviews']
dc_listings=pd.read_csv('listings.csv')
dc_listings=dc_listings[features]
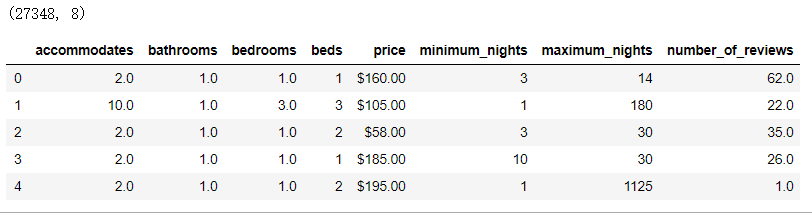
print(dc_listings.shape)
dc_listings.head()
运行结果:
K:候选对象个数,近邻数(如找3个和自己最近的样本)
import numpy as np
our_acc_value=3#房间数为3个
dc_listings['distance']=np.abs(dc_listings.accommodates-our_acc_value)#为dc_listings新增distance列,用于保存当前房间数与3的差值
dc_listings.distance.value_counts().sort_index()#统计各差值的情况
输出:
0.0 3370
1.0 17967
1.5 2
2.0 3865
3.0 1250
4.0 221
5.0 334
6.0 58
7.0 125
8.0 15
9.0 44
10.0 5
11.0 14
12.0 5
13.0 73
Name: distance, dtype: int64
原始数据统计过程中可能会存在一些规律,一般需要进行洗牌操作,打乱原有秩序(使用sample函数)
dc_listings=dc_listings.sample(frac=1,random_state=0)#洗牌 frac:抽取行的比例,1为100% random_state:0表示不得取重复数据 1表示可以取重复数据
dc_listings=dc_listings.sort_values('distance')#统计差值(房间数-3)的情况 将dc_listings按照distance列排序 将和房间数3最近的放在最前面
dc_listings.price.head()#取前5条的价格 由于数据时乱的,所以id和price均无规律
输出结果:
2732 $129.00
14798 $249.00
27309 $170.00
20977 $169.00
11178 $100.00
Name: price, dtype: object
对价格进行类型转换,去掉$符号,转换成float,然后对前五个价格取均值,用前5个的均值来预测当前房价
dc_listings['price']=dc_listings.price.str.replace("\$|,",'').astype(float)
mean_price=dc_listings.price.iloc[:5].mean()
mean_price
输出:163.4
拿75%的数据作为训练集,25%的数据作为测试集来进行模型的评估,训练集和测试集不可重复。
dc_listings.drop('distance',axis=1)#删除distance列
train_df=dc_listings.copy().iloc[:20544]#27392*0.75行为训练集
test_df=dc_listings.copy().iloc[20544:]#剩下的作为测试集(27392*0.25)
基于单变量预测价格
#new_listing_value:当前样本的feature_clolumn(如accomodates)列属性取值
#feture_column:计算房租使用的单属性
def predict_price(new_listing_value,feature_column):
temp_df=train_df#使用训练集来预测测试集房租结果
dc_listings[feature_column]=train_df[feature_column].astype(float)#统一将格式转换成float否则会报错
temp_df['distance']=np.abs(train_df[feature_column]-new_listing_value)
temp_df=temp_df.sort_values('distance')
knn_5=temp_df.price.iloc[:5]
predict_price=knn_5.mean()
return(predict_price)
对测试集的每一条记录使用accomodates属性预测其房租价格
#new_listing_value的值即为accommodates的取值
test_df['predicted_price']=test_df.accommodates.apply(predict_price,feature_column='accommodates')
test_df.predicted_price.head()
输出:
14122 134.0
23556 418.0
16317 134.0
26230 134.0
19769 134.0
Name: predicted_price, dtype: float64
root mean square error(RMSE)均方根误差
得到每个样本的预测值后计算均方根误差用于评估模型(值越小模型越好)

test_df['squared_error']=(test_df['predicted_price']-test_df['price'])**(2)
mse=test_df['squared_error'].mean()
rmse=mse**(1/2)
rmse
输出结果:
348.689169172284
试试不同的变量(属性)
for feature in ['accommodates','bedrooms','bathrooms','number_of_reviews']:
test_df['predicted_price']=test_df[feature].apply(predict_price,feature_column=feature)
test_df['squared_error']=(test_df['predicted_price']-test_df['price'])**(2)
mse=test_df['squared_error'].mean()
rmse=mse**(1/2)
print("RMSE for the {} column:{}".format(feature,rmse))
输出:
RMSE for the accommodates column:348.689169172284
RMSE for the bedrooms column:344.64855009943
RMSE for the bathrooms column:361.1230782594195
RMSE for the number_of_reviews column:383.4946020709275
注:由于每个测试集中的样本都要与训练集中样本一一比对,所以上述程序运行时间较长,需要耐心等待……
标准化
同时使用多个属性——如房间数(个位数)和房间面积(几十甚至上百)进行计算的时候,由于变量取值范围的不同(取值范围大的影响较大)会导致对计算结果的不良影响(如计算欧式距离时,房间面积差值平方计算结果通常较大,而房间数差值平方较小),而各个属性是独立的即它们是同等重要的,所以需要对数据进行标准化,如采用z-score标准化或归一化等手段进行预处理
z-score 标准化(Z-score normalization)
要求数据总体均值μ=0 标准差σ=1
转换公式如下:
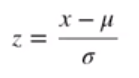
其中μ为原始数据均值,
机器学习入门实战——基于knn的airbnb房租预测的更多相关文章
- web安全之机器学习入门——3.1 KNN/k近邻
目录 sklearn.neighbors.NearestNeighbors 参数/方法 基础用法 用于监督学习 检测异常操作(一) 检测异常操作(二) 检测rootkit 检测webshell skl ...
- 分享《机器学习实战基于Scikit-Learn和TensorFlow》中英文PDF源代码+《深度学习之TensorFlow入门原理与进阶实战》PDF+源代码
下载:https://pan.baidu.com/s/1qKaDd9PSUUGbBQNB3tkDzw <机器学习实战:基于Scikit-Learn和TensorFlow>高清中文版PDF+ ...
- Spark入门实战系列--8.Spark MLlib(上)--机器学习及SparkMLlib简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .机器学习概念 1.1 机器学习的定义 在维基百科上对机器学习提出以下几种定义: l“机器学 ...
- Spark入门实战系列--8.Spark MLlib(下)--机器学习库SparkMLlib实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .MLlib实例 1.1 聚类实例 1.1.1 算法说明 聚类(Cluster analys ...
- 向大家介绍我的新书:《基于股票大数据分析的Python入门实战》
我在公司里做了一段时间Python数据分析和机器学习的工作后,就尝试着写一本Python数据分析方面的书.正好去年有段时间股票题材比较火,就在清华出版社夏老师指导下构思了这本书.在这段特殊时期内,夏老 ...
- 基于股票大数据分析的Python入门实战(视频教学版)的精彩插图汇总
在我写的这本书,<基于股票大数据分析的Python入门实战(视频教学版)>里,用能吸引人的股票案例,带领大家入门Python的语法,数据分析和机器学习. 京东链接是这个:https://i ...
- 【机器学习】机器学习入门01 - kNN算法
0. 写在前面 近日加入了一个机器学习的学习小组,每周按照学习计划学习一个机器学习的小专题.笔者恰好近来计划深入学习Python,刚刚熟悉了其基本的语法知识(主要是与C系语言的差别),决定以此作为对P ...
- Spark入门实战系列--1.Spark及其生态圈简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .简介 1.1 Spark简介 年6月进入Apache成为孵化项目,8个月后成为Apache ...
- Spark入门实战系列--3.Spark编程模型(上)--编程模型及SparkShell实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark编程模型 1.1 术语定义 l应用程序(Application): 基于Spar ...
随机推荐
- JVM(四)打破双亲委派和SPI机制
前言: 我们都知道判断两个类是不是同一个,要根据类加载器和全限定名.这是为什么呢?为什么不同的类加载器加载同一个类是不同的呢? 答案就是,不同的类加载器所加载的类在方法区的存储空间是不同的即Insta ...
- jvm源码解析java对象头
认真学习过java的同学应该都知道,java对象由三个部分组成:对象头,实例数据,对齐填充,这三大部分扛起了java的大旗对象,实例数据其实就是我们对象中的数据,对齐填充是由于为了规则分配内存空间,j ...
- 全栈性能测试修炼宝典-JMeter实战笔记(三)
JMeter体系结构 简介 JMeter是一款开源桌面应用软件,可用来模拟用户负载来完成性能测试工作. JMeter体系结构 X1~X5是负载模拟的一个过程,使用这些组件来完成负载的模拟 Y1:包含的 ...
- 线上一次大量 CLOSE_WAIT 复盘
https://mp.weixin.qq.com/s/PfM3hEsDa3CMLbbKqis-og 线上一次大量 CLOSE_WAIT 复盘 原创 ms2008 poslua 2019-07-05 最 ...
- 写给小白的 Nginx 文章
原文地址:Nginx concepts I wish I knew years ago 原文作者:Aemie Jariwala(已授权) 译者 & 校正:HelloGitHub-小鱼干 &am ...
- 利用Javascript制作网页特效(其他常见特效)
设置为首页和加入收藏夹 ①:在body标签内输入以下代码: <a onclick="this.style.behavior='url(#default#homepage)'; this ...
- Java8种排序算法学习
冒泡排序 public class test { public static void main(String[] args) { // TODO Auto-generated method stub ...
- OutOfMemoryError系列
OutOfMemoryError系列 1.[OutOfMemoryError系列(1): Java heap space](https://blog.csdn.net/renfufei/article ...
- python--可迭代对象、迭代器和生成器
迭代器 1.什么是迭代器? 不依赖于索引的取值方式 迭代是一个重复的过程,即每一次重复为一次迭代,并且每次迭代的结果都是下一次迭代的初始值 示例: str1 = 'abcde' count = 0 w ...
- Windows下使用poetry和pyproject.toml
0. 题引 为什么要使用poetry? 因为想使用pyproject.toml,并通过pyproject.toml进行依赖包管理,目前pip还不支持,所以poetry是首选 为什么要使用pyproje ...