Spark内核-任务调度机制
作者:十一喵先森
链接:https://juejin.im/post/5e1c414fe51d451cad4111d1
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
对上文的总结
Spark 任务调度概述
一个Spark应用程序包括Job、Stage以及Task三个概念:
Job是以Action方法为界,遇到一个Action方法则触发一个Job;
Stage是Job的子集,以RDD宽依赖(即Shuffle)为界,遇到Shuffle做一次划分;
Task是Stage的子集,以并行度(分区数)来衡量,分区数是多少,则有多少个task。
Spark的任务调度总体来说分两路进行,一路是Stage级的调度,一路是Task级的调度,
Spark Stage级调度
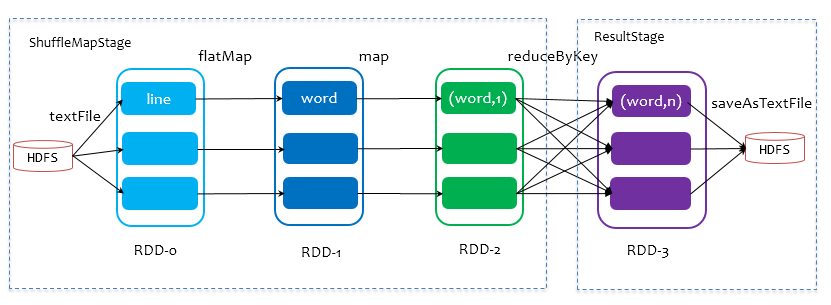
Job由saveAsTextFile触发,该Job由RDD-3和saveAsTextFile方法组成,根据RDD之间的依赖关系从RDD-3开始回溯搜索,直到没有依赖的RDD-0,在回溯搜索过程中,RDD-3依赖RDD-2,并且是宽依赖,所以在RDD-2和RDD-3之间划分Stage,RDD-3被划到最后一个Stage,即ResultStage中,RDD-2依赖RDD-1,RDD-1依赖RDD-0,这些依赖都是窄依赖,所以将RDD-0、RDD-1和RDD-2划分到同一个Stage,即ShuffleMapStage中,实际执行的时候,数据记录会一气呵成地执行RDD-0到RDD-2的转化。不难看出,其本质上是一个深度优先搜索算法。
一个Stage是否被提交,需要判断它的父Stage是否执行,只有在父Stage执行完毕才能提交当前Stage,如果一个Stage没有父Stage,那么从该Stage开始提交。
总结:
stage调度算法:从前往后.
Spark Task 级调度
TaskScheduler支持两种调度策略,一种是FIFO,也是默认的调度策略,另一种是FAIR
FIFO: 先来先到;
FAIR: 根据优先级来调度.
失败重试与黑名单机制
对于失败的Task,会记录它失败的次数,如果失败次数还没有超过最大重试次数,那么就把它放回待调度的Task池子中,否则整个Application失败。
黑名单记录Task上一次失败所在的Executor Id和Host,以及其对应的“拉黑”时间,“拉黑”时间是指这段时间内不要再往这个节点上调度这个Task了。
Spark内核-任务调度机制的更多相关文章
- 【大数据】Spark内核解析
1. Spark 内核概述 Spark内核泛指Spark的核心运行机制,包括Spark核心组件的运行机制.Spark任务调度机制.Spark内存管理机制.Spark核心功能的运行原理等,熟练掌握Spa ...
- 【Spark 内核】 Spark 内核解析-上
Spark内核泛指Spark的核心运行机制,包括Spark核心组件的运行机制.Spark任务调度机制.Spark内存管理机制.Spark核心功能的运行原理等,熟练掌握Spark内核原理,能够帮助我们更 ...
- 【Spark 内核】 Spark 内核解析-下
Spark内核泛指Spark的核心运行机制,包括Spark核心组件的运行机制.Spark任务调度机制.Spark内存管理机制.Spark核心功能的运行原理等,熟练掌握Spark内核原理,能够帮助我们更 ...
- Spark内核解析
Spark内核概述 Spark内核泛指Spark的核心运行机制,包括Spark核心组件的运行机制.Spark任务调度机制.Spark内存管理机制.Spark核心功能的运行原理等,熟练掌握Spark内核 ...
- 大数据计算平台Spark内核解读
1.Spark介绍 Spark是起源于美国加州大学伯克利分校AMPLab的大数据计算平台,在2010年开源,目前是Apache软件基金会的顶级项目.随着 Spark在大数据计算领域的暂露头角,越来越多 ...
- (升级版)Spark从入门到精通(Scala编程、案例实战、高级特性、Spark内核源码剖析、Hadoop高端)
本课程主要讲解目前大数据领域最热门.最火爆.最有前景的技术——Spark.在本课程中,会从浅入深,基于大量案例实战,深度剖析和讲解Spark,并且会包含完全从企业真实复杂业务需求中抽取出的案例实战.课 ...
- 大数据计算平台Spark内核全面解读
1.Spark介绍 Spark是起源于美国加州大学伯克利分校AMPLab的大数据计算平台,在2010年开源,目前是Apache软件基金会的顶级项目.随着Spark在大数据计算领域的暂露头角,越来越多的 ...
- 锁相关知识 & mutex怎么实现的 & spinlock怎么用的 & 怎样避免死锁 & 内核同步机制 & 读写锁
spinlock在上一篇文章有提到:http://www.cnblogs.com/charlesblc/p/6254437.html 通过锁数据总线来实现. 而看了这篇文章说明:mutex内部也用到 ...
- [内核同步]浅析Linux内核同步机制
转自:http://blog.csdn.net/fzubbsc/article/details/37736683?utm_source=tuicool&utm_medium=referral ...
随机推荐
- [大雾雾雾雾] 告别该死的 EFCore Fluent API (续)
朋友们好啊, 我是 .NET 打工人 玩双截棍的熊猫 刚才有个朋友问我 猫猫发生什么事了 我说 怎么回事? 给我发了一张截图 我一看!嗷!原来是zuo天有两个数据库, 一个四十多岁,一个三十多岁 它们 ...
- Ayoa:麻雀虽小、五脏俱全的思维导图工具
Ayoa是一款简单好用的思维导图软件,在PC端可以使用Ayoa网页版,也就是不用下载即可使用,十分轻便省力.但麻雀虽小,五脏可十分俱全,同类的其他大型软件有的东西它可一点不少,甚至还有更多的特殊功能. ...
- 实现 Application_Start 和 Application_End
理解 ASP.NET Core: 实现 Application_Start 和 Application_End 在 ASP.NET 中两个常用的处理节点是 Application_Start() 和 ...
- 15.java设计模式之访问者模式
基本需求: 电脑需要键盘鼠标等固定的组件组成 现在分为个人,组织等去买电脑,而同一种组件对不同的人(访问者)做出不同的折扣,从而电脑的价格也不一样 传统的解决方法:在组件内部进行判断访问人的类型,从而 ...
- Linux 学习笔记05丨在Ubuntu 20.04配置FTP服务器
感谢 linuxconfig.org 上的这篇英文教程 FTP用于访问和传输本地网络上的文件,通过安装 VSFTPD 软件,打开热点,配置相关信息后即能够启动并运行FTP服务器了. 1. 安装和配置V ...
- X86中断/异常与APIC
异常(exception)是由软件或硬件产生的,分为同步异常和异步异常.同步异常即CPU执行指令期间同步产生的异常,比如常见的除零错误.访问不在RAM中的内存 .MMU 发现当前虚拟地址没有对应的物理 ...
- Executor类
//测试的线程 public class Record implements Run ...
- moviepy音视频剪辑:与大小相关的视频变换函数详解
☞ ░ 前往老猿Python博文目录 ░ 一.引言 在<moviepy音视频剪辑:moviepy中的剪辑基类Clip详解>介绍了剪辑基类的fl.fl_time.fx方法,在<movi ...
- PyQt信号connect连接槽方法时报:native Qt signal is not callable错误
专栏:Python基础教程目录 专栏:使用PyQt开发图形界面Python应用 专栏:PyQt入门学习 老猿Python博文目录 老猿学5G博文目录 在将一个信号连接到槽方法时,程序异常退出,捕获异常 ...
- PyQt(Python+Qt)学习随笔:Model/View中的枚举类 Qt.MatchFlag的取值及含义
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 枚举类 Qt.MatchFlag描述在模型中搜索项时可以使用的匹配类型,它可以在QStandardI ...