GAN和GAN的改进
GAN
原始GAN中判别器要最小化如下损失函数,尽可能把真实样本分为正例,生成样本分为负例:
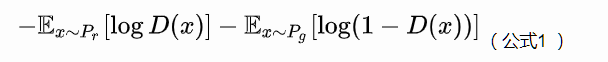
其中是真实样本分布,
是由生成器产生的样本分布。

第一个式子我们不看梯度符号的话即为判别器的损失函数,logD(xi)为判别器将真实数据判定为真实数据的概率,log(1-D(G(zi)))为判别器将生成器生成的虚假数据判定为真实数据的对立面即将虚假数据仍判定为虚假数据的概率。判别器就相当于警察,在鉴别真伪时,必须要保证鉴别的结果真的就是真的,假的就是假的,所以判别器的总损失即为二者之和,应当最大化该损失。由于判别器(警察)鉴别真伪的能力随着训练次数的增加越来越高,生成器就要与之“对抗”,生成器就要相应地提高“造假”技术,来迷惑判别器。第二个式子为第一个式子的第二项,含义相同,只不过对于生成器应当最小化该项,生成器当然希望辨别器将虚假数据仍判定为虚假数据的概率越低越好,即将虚假数据误判定为真实数据的概率越大越好,即最大化log(D(G(zi)))损失函数。所以二者相互提高或者减小自身的损失,以不断互相对抗。
从公式1可以得到,在生成器G固定参数时最优的判别器D应该是什么。对于一个具体的样本,它可能来自真实分布也可能来自生成分布,它对公式1损失函数的贡献是
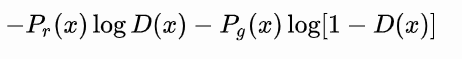
令其关于的导数为0,得
化简得最优判别器为:
(公式4)
看一个样本来自真实分布和生成分布的可能性的相对比例。如果
且
,最优判别器就应该非常自信地给出概率0;如果
,说明该样本是真是假的可能性刚好一半一半,此时最优判别器也应该给出概率0.5。
(公式2)
GAN训练的问题之一,就是别把判别器训练得太好,否则在实验中生成器会完全学不动(loss降不下去),为了探究背后的原因,我们就可以看看在极端情况——判别器最优时,生成器的损失函数变成什么。给公式2加上一个不依赖于生成器的项,使之变成
最小化这个损失函数等价于最小化公式2,而且它刚好是判别器损失函数的相反数。代入最优判别器即公式4,再进行简单的变换可以得到
(公式5)
从而可以得到KL散度和JS散度(衡量量两个分布的差异区别)
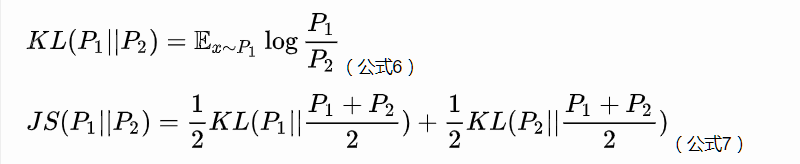
于是公式5就可以继续写成
(公式8)
目前得到的结论:根据原始GAN定义的判别器loss,我们可以得到最优判别器的形式;而在最优判别器的下,我们可以把原始GAN定义的生成器loss等价变换为最小化真实分布与生成分布
之间的JS散度。我们越训练判别器,它就越接近最优,最小化生成器的loss也就会越近似于最小化
和
之间的JS散度。
问题就出在这个JS散度上。我们会希望如果两个分布之间越接近它们的JS散度越小,我们通过优化JS散度就能将“拉向”
,最终以假乱真。这个希望在两个分布有所重叠的时候是成立的,但是如果两个分布完全没有重叠的部分,或者它们重叠的部分可忽略(下面解释什么叫可忽略),它们的JS散度是多少呢?
答案是,因为对于任意一个x只有四种可能:
且
且
且
且
第一种对计算JS散度无贡献,第二种情况由于重叠部分可忽略所以贡献也为0,第三种情况对公式7右边第一个项的贡献是,第四种情况与之类似,所以最终
。
换句话说,无论跟
是远在天边,还是近在眼前,只要它们俩没有一点重叠或者重叠部分可忽略,JS散度就固定是常数
,而这对于梯度下降方法意味着——梯度为0!此时对于最优判别器来说,生成器肯定是得不到一丁点梯度信息的;即使对于接近最优的判别器来说,生成器也有很大机会面临梯度消失的问题。
但是与
不重叠或重叠部分可忽略的可能性有多大?不严谨的答案是:非常大。比较严谨的答案是:当
与
的支撑集(support)是高维空间中的低维流形(manifold)时,
与
重叠部分测度(measure)为0的概率为1。
- 支撑集(support)其实就是函数的非零部分子集,比如ReLU函数的支撑集就是
,一个概率分布的支撑集就是所有概率密度非零部分的集合。
- 流形(manifold)是高维空间中曲线、曲面概念的拓广,我们可以在低维上直观理解这个概念,比如我们说三维空间中的一个曲面是一个二维流形,因为它的本质维度(intrinsic dimension)只有2,一个点在这个二维流形上移动只有两个方向的自由度。同理,三维空间或者二维空间中的一条曲线都是一个一维流形。
- 测度(measure)是高维空间中长度、面积、体积概念的拓广,可以理解为“超体积”。
在(近似)最优判别器下,最小化生成器的loss等价于最小化与
之间的JS散度,而由于
与
几乎不可能有不可忽略的重叠,所以无论它们相距多远JS散度都是常数
,最终导致生成器的梯度(近似)为0,梯度消失。
- 首先,
与
之间几乎不可能有不可忽略的重叠,所以无论它们之间的“缝隙”多狭小,都肯定存在一个最优分割曲面把它们隔开,最多就是在那些可忽略的重叠处隔不开而已。
- 由于判别器作为一个神经网络可以无限拟合这个分隔曲面,所以存在一个最优判别器,对几乎所有真实样本给出概率1,对几乎所有生成样本给出概率0,而那些隔不开的部分就是难以被最优判别器分类的样本,但是它们的测度为0,可忽略。
- 最优判别器在真实分布和生成分布的支撑集上给出的概率都是常数(1和0),导致生成器的loss梯度为0,梯度消失。
有了这些理论分析,原始GAN不稳定的原因就彻底清楚了:判别器训练得太好,生成器梯度消失,生成器loss降不下去;判别器训练得不好,生成器梯度不准,四处乱跑。只有判别器训练得不好不坏才行,但是这个火候又很难把握,甚至在同一轮训练的前后不同阶段这个火候都可能不一样,所以GAN才那么难训练。
WGAN
引入Wasserstein距离
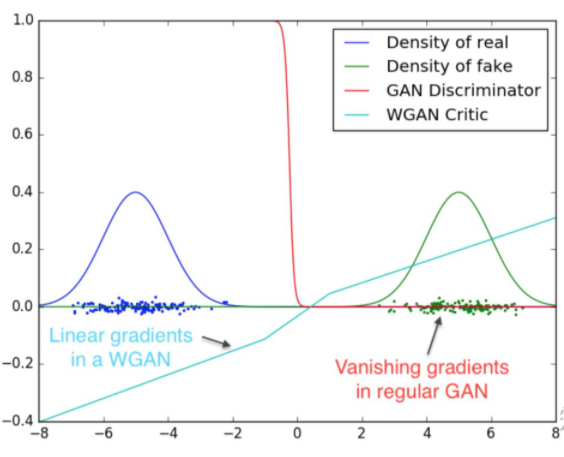
希望建立一个平滑的,处处可导的cost function。在图中,蓝色为真实分布,绿色为生成数据的分布。红色为discriminator的cost function,我们发现虽然discriminator有效的区分了两个分布,但是当蓝绿两个分布没有交集时,在大量的点上的cost function为常数值,梯度为0,generator 不能更新了。这时看一下wasserstein 距离,它体现为那个草绿色的线,它平滑,可导这就是我们要寻找的cost function。
数学定义如下:
(公式12)
解释如下:是
和
组合起来的所有可能的联合分布的集合,反过来说,
中每一个分布的边缘分布都是
和
。对于每一个可能的联合分布
而言,可以从中采样
得到一个真实样本
和一个生成样本
,并算出这对样本的距离
,所以可以计算该联合分布
下样本对距离的期望值
。在所有可能的联合分布中能够对这个期望值取到的下界
,就定义为Wasserstein距离。
Wasserstein距离相比KL散度、JS散度的优越性在于,即便两个分布没有重叠,Wasserstein距离仍然能够反映它们的远近。
但是
因为Wasserstein距离定义(公式12)中的没法直接求解,不过没关系,作者用了一个已有的定理把它变换为如下形式
(公式13)
Lipschitz连续。它其实就是在一个连续函数上面额外施加了一个限制,
的导函数绝对值不超过
。限制了一个连续函数的最大局部变动幅度。
公式13的意思就是在要求函数的Lipschitz常数
不超过
的条件下,对所有可能满足条件的
取到
的上界,然后再除以
。特别地,我们可以用一组参数
来定义一系列可能的函数
,此时求解公式13可以近似变成求解如下形式
(公式14)
再用上我们搞深度学习的人最熟悉的那一套,不就可以把用一个带参数
的神经网络来表示嘛!由于神经网络的拟合能力足够强大,我们有理由相信,这样定义出来的一系列
虽然无法囊括所有可能,但是也足以高度近似公式13要求的那个
了。
最后,还不能忘了满足公式14中这个限制。我们其实不关心具体的K是多少,只要它不是正无穷就行,因为它只是会使得梯度变大
倍,并不会影响梯度的方向。所以作者采取了一个非常简单的做法,就是限制神经网络
的所有参数
的不超过某个范围
,比如
,此时关于输入样本
的导数
也不会超过某个范围,所以一定存在某个不知道的常数
使得
的局部变动幅度不会超过它,Lipschitz连续条件得以满足。具体在算法实现中,只需要每次更新完
后把它clip回这个范围就可以了。
到此为止,我们可以构造一个含参数、最后一层不是非线性激活层的判别器网络
,在限制
不超过某个范围的条件下,使得
(公式15)
尽可能取到最大,此时就会近似真实分布与生成分布之间的Wasserstein距离(忽略常数倍数
)。注意原始GAN的判别器做的是真假二分类任务,所以最后一层是sigmoid,但是现在WGAN中的判别器
做的是近似拟合Wasserstein距离,属于回归任务,所以要把最后一层的sigmoid拿掉。
接下来生成器要近似地最小化Wasserstein距离,可以最小化,由于Wasserstein距离的优良性质,我们不需要担心生成器梯度消失的问题。再考虑到
的第一项与生成器无关,就得到了WGAN的两个loss。
(公式16,WGAN生成器loss函数)
(公式17,WGAN判别器loss函数)
公式15是公式17的反,可以指示训练进程,其数值越小,表示真实分布与生成分布的Wasserstein距离越小,GAN训练得越好。

WGAN与原始GAN第一种形式相比,只改了四点:
- 判别器最后一层去掉sigmoid
- 生成器和判别器的loss不取log
- 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
- 不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行
GAN和GAN的改进的更多相关文章
- 【GAN】GAN的原理及推导
把GAN的论文看完了, 也确实蛮厉害的懒得写笔记了,转一些较好的笔记,前面先贴一些 原论文里推理部分,进行备忘. GAN的解释 算法流程 GAN的理论推理 转自:https://zhuanlan.zh ...
- 【GAN】GAN设计与训练集锦
以下内容纯属经验之谈,无公式推断!部分内容源自其他博客或课程,并已标注来源. 问题篇[1] 1.模式崩溃 在某个模式(mode)下出现大量重复样本,如左图中,生成的样本分布靠得很近,较聚集,可视化如右 ...
- 【生成对抗网络学习 其一】经典GAN与其存在的问题和相关改进
参考资料: 1.https://github.com/dragen1860/TensorFlow-2.x-Tutorials 2.<Generative Adversarial Net> ...
- GAN︱生成模型学习笔记(运行机制、NLP结合难点、应用案例、相关Paper)
我对GAN"生成对抗网络"(Generative Adversarial Networks)的看法: 前几天在公开课听了新加坡国立大学[机器学习与视觉实验室]负责人冯佳时博士在[硬 ...
- 深度学习新星:GAN的基本原理、应用和走向
深度学习新星:GAN的基本原理.应用和走向 (本文转自雷锋网,转载已获取授权,未经允许禁止转载)原文链接:http://www.leiphone.com/news/201701/Kq6FvnjgbKK ...
- Improved GAN
https://www.bilibili.com/video/av9770302/?p=16 从之前讲的basic gan延伸到unified framework,到WGAN 再到通过WGAN进行Ge ...
- [Deep-Learning-with-Python]GAN图片生成
GAN 由Goodfellow等人于2014年引入的生成对抗网络(GAN)是用于学习图像潜在空间的VAE的替代方案.它们通过强制生成的图像在统计上几乎与真实图像几乎无法区分,从而能够生成相当逼真的合成 ...
- Generative Adversarial Nets(原生GAN学习)
学习总结于国立台湾大学 :李宏毅老师 Author: Ian Goodfellow • Paper: https://arxiv.org/abs/1701.00160 • Video: https:/ ...
- GAN综述
生成式对抗模型GAN (Generativeadversarial networks) 是Goodfellow等[1]在 2014年提出的一种生成式模型,目前已经成为人工智能学界一个热门的研究方向,著 ...
随机推荐
- [Luogu P3338] [ZJOI2014]力 (数论 FFT 卷积)
题面 传送门: 洛咕 BZOJ Solution 写到脑壳疼,我好菜啊 我们来颓柿子吧 \(F_j=\sum_{i<j}\frac{q_i*q_j}{(i-j)^2}-\sum_{i>j} ...
- [Luogu P4777] 【模板】扩展中国剩余定理(EXCRT) (扩展中国剩余定理)
题面 传送门:洛咕 Solution 真*扩展中国剩余定理模板题.我怎么老是在做模板题啊 但是这题与之前不同的是不得不写龟速乘了. 还有两个重点 我们在求LCM的时候,记得先/gcd再去乘另外那个数, ...
- Raft算法原理剖析
一.复制状态机(replicated state machine) Raft协议可以使得一个集群的服务器组成复制状态机,在详细了解Raft算法之前,我们先来了解一下什么是复制状态机.一个分布式的复制状 ...
- AQS源码深入分析之条件队列-你知道Java中的阻塞队列是如何实现的吗?
本文基于JDK-8u261源码分析 1 简介 因为CLH队列中的线程,什么线程获取到锁,什么线程进入队列排队,什么线程释放锁,这些都是不受我们控制的.所以条件队列的出现为我们提供了主动式地.只有满足指 ...
- nginx下配置php5和php7
用的是lnmp 一键安装的 php5.6版本网上百度Ubuntu安装多版本PHP就行 参考文章原链接:http://blog.csdn.net/21aspnet/article/details/476 ...
- 深入学习OpenCV文档扫描及OCR识别(文档扫描,图像矫正,透视变换,OCR识别)
如果需要处理的原图及代码,请移步小编的GitHub地址 传送门:请点击我 如果点击有误:https://github.com/LeBron-Jian/ComputerVisionPractice 下面 ...
- 3.java设计模式之工厂模式
基本需求: 一个披萨店需要订购不同种类的披萨 传统方式: 实现思路 在订购类中根据用户不同的输入直接创建不同的披萨实体类进行返回 UML类图 代码实现 披萨类 // 抽象父类 public abstr ...
- 深坑啊!同一个Spring AOP的坑,我一天踩了两次!
GitHub 18k Star 的Java工程师成神之路,不来了解一下吗! GitHub 18k Star 的Java工程师成神之路,真的不来了解一下吗! GitHub 18k Star 的Java工 ...
- 开发IDE的一些设置
一.修改和设置idea或eclipse的快捷键: 二.idea的settings的一些设置: settings 可以导出,也可以导入.也可以设置每次新建和新打开一个工程用同一个setting 三.全局 ...
- simple-rpc
RPC的实现原理 正如上一讲所说,RPC主要是为了解决的两个问题: 解决分布式系统中,服务之间的调用问题. 远程调用时,要能够像本地调用一样方便,让调用者感知不到远程调用的逻辑. 还是以计算器Calc ...