Python学习第四天----模块儿导入
1.命名空间
2.模块儿的引入:
第一种:
import t.c7 as m
print(m.a)
第二种:
from t.c7 import a
print(a)
//或者
# from t import c7
#print(c7.a)
from t.c7 import *
print(a)
print(c)
print(d)
a = 2
c = 3
d = 4
__all__ = ['a', 'c'] a = 2
c = 3
d = 4
from t.c7 import * print(a)
print(c)
print(d)
//2
//3
//Traceback (most recent call last):
// File ".\c8.py", line 9, in <module>
// print(d)
//NameError: name 'd' is not defined
第三种:
from c9 import a,b,c '''
from c9 import a
from c9 import b
from c9 import c
'''
from c9 import a,b,\
c
from c9 import (a,b,
c)
3.__init__.py文件的作用:
单个导入:

import t
#This is __init__.py file t中的__init__.py文件自动执行。
__all__ = ['c7']
e = 2
f = 3
g = 4
from t import *
print(c7.a)
#2
print(c8.e)
#error: NameError: name 'c8' is not defined
批量导入:
import sys
import datetime
import io
import t
print(t.sys.path)
#['F:\\pythonlearn\\my-pythonFirst\\six', 'E:\\py3\\python38.zip', 'E:\\py3\\DLLs', 'E:\\py3\\lib', 'E:\\py3', 'C:\\Users\\Administrator\\AppData\\Roaming\\Python\\Python38\\site-packages', 'E:\\py3\\lib\\site-packages']
包与模块儿:
from p2 import p2
p1 = 2
print(p2)
from p1 import p1
p2 = 2
Traceback (most recent call last):
File ".\p1.py", line 1, in <module>
from p2 import p2
File "F:\pythonlearn\my-pythonFirst\six\p\p2.py", line 1, in <module>
from p1 import p1
File "F:\pythonlearn\my-pythonFirst\six\p\p1.py", line 1, in <module>
from p2 import p2
ImportError: cannot import name 'p2' from partially initialized module 'p2' (most likely due to a circular import) (F:\pythonlearn\my-pythonFirst\six\p\p2.py)
模块儿的内置变量:
a = 2
c = 3 infos = dir();
print(infos)
# ['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'a', 'c']

'''
This is a c9 doc
'''
print("name:"+__name__)
print("package:"+__package__)
print("doc:"+__doc__)
print("file:"+__file__)
import t.t1.c9
name:t.t1.c9
package:t.t1
doc: This is a c9 doc
TypeError: can only concatenate str (not "NoneType") to str
入口文件和普通模块内置变量的区别:
import t.t1.c9
print("name:"+__name__)
print("package:"+__package__)
print("doc:"+__doc__)
print("file:"+__file__)
name:t.t1.c9
package:t.t1
doc: This is a c9 doc file:F:\pythonlearn\my-pythonFirst\six\t\t1\c9.py
name:__main__
Traceback (most recent call last):
File ".\c15.py", line 9, in <module>
print("package:"+__package__)
TypeError: can only concatenate str (not "NoneType") to str
'''
描述
'''
import t.t1.c9 print('~~~~~~~~~~~~~~~~~~~~c15~~~~~~~~~~~~~~~~~~~~~~~~~')
print("name:" + __name__)
print("package:" + (__package__ or '当前模块不属于任何包'))
print("doc:" + __doc__)
print("file:" + __file__)
name:t.t1.c9
package:t.t1
doc: This is a c9 doc file:F:\pythonlearn\my-pythonFirst\six\t\t1\c9.py
~~~~~~~~~~~~~~~~~~~~c15~~~~~~~~~~~~~~~~~~~~~~~~~
name:__main__
package:当前模块不属于任何包
doc:
描述 file:.\c15.py

if __name__ == "__main__":
pass
if __name__ == "__main__":
print('This is app') print('This is a module')
This is app
This is a module
This is a module
python -m six.c17
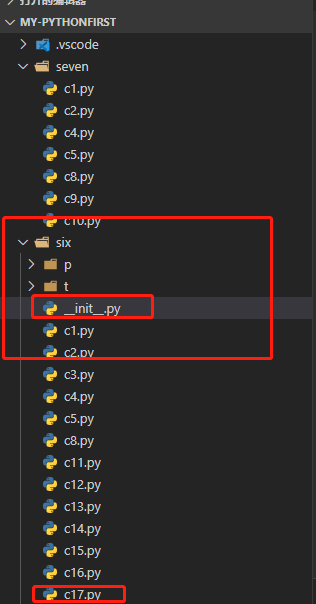
PS F:\pythonlearn\my-pythonFirst> python -m six.c17
This is app
This is a module
PS F:\pythonlearn\my-pythonFirst\six> python -m c17
This is app
This is a module //-m 后边如果是文件,则会报错
PS F:\pythonlearn\my-pythonFirst\six> python -m .\c17.py
E:\py3\python.exe: Relative module names not supported
'''
描述
'''
import t.t1.c9 print('~~~~~~~~~~~~~~~~~~~~c15~~~~~~~~~~~~~~~~~~~~~~~~~')
print("name:" + __name__)
print("package:" + (__package__ or '当前模块不属于任何包'))
print("doc:" + __doc__)
print("file:" + __file__)
'''
描述
'''
import six.t.t1.c9 print('~~~~~~~~~~~~~~~~~~~~c15~~~~~~~~~~~~~~~~~~~~~~~~~')
print("name:" + __name__)
print("package:" + (__package__ or '当前模块不属于任何包'))
print("doc:" + __doc__)
print("file:" + __file__)
name:six.t.t1.c9
package:six.t.t1
相对导入与绝对导入:
绝对导入:

print(__package__);
Module2.Module4
Module4

相对路径:
Python学习第四天----模块儿导入的更多相关文章
- python学习第四十八天json模块与pickle模块差异
在开发过程中,字符串和python数据类型进行转换,下面比较python学习第四十八天json模块与pickle模块差异. json 的优点和缺点 优点 跨语言,体积小 缺点 只能支持 int st ...
- Python学习(四)数据结构(概要)
Python 数据结构 本章介绍 Python 主要的 built-type(内建数据类型),包括如下: Numeric types int float Text Sequence ...
- python学习第四讲,python基础语法之判断语句,循环语句
目录 python学习第四讲,python基础语法之判断语句,选择语句,循环语句 一丶判断语句 if 1.if 语法 2. if else 语法 3. if 进阶 if elif else 二丶运算符 ...
- python学习第四次笔记
python学习第四次记录 列表list 列表可以存储不同数据类型,而且可以存储大量数据,python的限制是 536870912 个元素,64位python的限制是 1152921504606846 ...
- python学习-第四天补充-面向对象
python学习-第四天补充-面向对象 python 私有 --name mangling(名字修改.名字) 在命名时,通过使用两个下划线作为开头,可以使得这个变量或者函数编程私有的,但是这个其实的p ...
- Python学习笔记十_模块、第三方模块安装、模块导入
一.模块.包 1.模块 模块实质上就是一个python文件.它是用来组织代码的,意思就是把python代码写到里面,文件名就是模块的名称,test.py test就是模块的名称 2.包 包,packa ...
- Python学习第二阶段,Day2,import导入模块方法和内部原理
怎样导入模块和导入包?? 1.模块定义:代码越来越多的时候,所有代码放在一个py文件无法维护.而将代码拆分成多个py文件,同一个名字的变量互不影响,模块本质上是一个.py文件或者".py&q ...
- python学习日记(常用模块)
模块概念 什么是模块 常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀. 但其实import加载的模块分为四个通用类别: 1 使用python编写的代 ...
- 【Python学习之九】模块
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 python3.6 一.模块的使用和安装模块和C语言中的头文件以及Ja ...
随机推荐
- [Luogu P2387] [NOI2014]魔法森林 (LCT维护边权)
题面 传送门:https://www.luogu.org/problemnew/show/P2387 Solution 这题的思想挺好的. 对于这种最大值最小类的问题,很自然的可以想到二分答案.很不幸 ...
- Redis 和 Memcached 有什么区别?Redis 的线程模型是什么?为什么单线程的 Redis 比多线程的 Memcached 效率要高得多?
面试题 redis 和 memcached 有什么区别?redis 的线程模型是什么?为什么 redis 单线程却能支撑高并发? 面试官心理分析 这个是问 redis 的时候,最基本的问题吧,redi ...
- ElasticSearch初步了解和安装(windows上安装)
ElasticSearch是什么 ElasticSearch(一般简称es)是一个基于Lucene的分布式搜索和数据分析引擎.它提供了REST api 的操作接口.它可以快速的存储.搜索.分析海量数据 ...
- 力扣 - 剑指Offer 35.复杂链表的复制
目录 题目 思路1 代码实现 思路2 代码实现 题目 请实现 copyRandomList 函数,复制一个复杂链表.在复杂链表中,每个节点除了有一个 next 指针指向下一个节点,还有一个 rando ...
- How to Convert and Import VHD to VMDK (VMWare)
VHD or Virtual Hard Disk is the disk image format used by Microsoft virtualization software such as ...
- C++实现学校运动会管理系统
本文实例为大家分享了C++实现学校运动会管理系统的具体代码,供大家参考,具体内容如下 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 ...
- nginx&http 第二章 ngx启动多进程
Nginx服务器使用 master/worker 多进程模式. 主进程(Master process)启动后,会接收和处理外部信号: 主进程启动后通过fork() 函数产生一个或多个子进程(work ...
- ceph集群的安装和配置教程
本篇主题: 1.怎样配置ssh免登陆访问 2.为什么搭建集群要关闭防火墙和selinux,如何关闭 3.从哪里获取ceph的安装包,怎样安装才是快速正确的 4.为什么要配置时间同步服务,怎样配置 5. ...
- java基本权限指南之:文件和共享目录的基本权限
简介 java程序是跨平台的,可以运行在windows也可以运行在linux.但是平台不同,平台中的文件权限也是不同的.windows大家经常使用,并且是可视化的权限管理,这里就不多讲了. 本文主要讲 ...
- Environment Cubemap
要创建一个Cubemap(将您的环境捕获到一个Cubemap中),您需要去Unity Documentation复制RenderCubemapWizard.cs脚本! 然后在"Project ...