更简易的机器学习-pycaret的安装和环境初始化
1、安装
pip install pycaret
在谷歌colab中还要运行:
from pycaret.utils import enable_colab
enable_colab()
2、获取数据
(1)利用pandas库加载
import pandas as pd
data = pd.read_csv('c:/path_to_data/file.csv')
(2)使用自带的数据
from pycaret.datasets import get_data
data = get_data('juice')
数据集列表:
| Dataset | Data Types | Default Task | Target Variable | # Instances | # Attributes |
| anomaly | Multivariate | Anomaly Detection | None | 1000 | 10 |
| france | Multivariate | Association Rule Mining | InvoiceNo, Description | 8557 | 8 |
| germany | Multivariate | Association Rule Mining | InvoiceNo, Description | 9495 | 8 |
| bank | Multivariate | Classification (Binary) | deposit | 45211 | 17 |
| blood | Multivariate | Classification (Binary) | Class | 748 | 5 |
| cancer | Multivariate | Classification (Binary) | Class | 683 | 10 |
| credit | Multivariate | Classification (Binary) | default | 24000 | 24 |
| diabetes | Multivariate | Classification (Binary) | Class variable | 768 | 9 |
| electrical_grid | Multivariate | Classification (Binary) | stabf | 10000 | 14 |
| employee | Multivariate | Classification (Binary) | left | 14999 | 10 |
| heart | Multivariate | Classification (Binary) | DEATH | 200 | 16 |
| heart_disease | Multivariate | Classification (Binary) | Disease | 270 | 14 |
| hepatitis | Multivariate | Classification (Binary) | Class | 154 | 32 |
| income | Multivariate | Classification (Binary) | income >50K | 32561 | 14 |
| juice | Multivariate | Classification (Binary) | Purchase | 1070 | 15 |
| nba | Multivariate | Classification (Binary) | TARGET_5Yrs | 1340 | 21 |
| wine | Multivariate | Classification (Binary) | type | 6498 | 13 |
| telescope | Multivariate | Classification (Binary) | Class | 19020 | 11 |
| glass | Multivariate | Classification (Multiclass) | Type | 214 | 10 |
| iris | Multivariate | Classification (Multiclass) | species | 150 | 5 |
| poker | Multivariate | Classification (Multiclass) | CLASS | 100000 | 11 |
| questions | Multivariate | Classification (Multiclass) | Next_Question | 499 | 4 |
| satellite | Multivariate | Classification (Multiclass) | Class | 6435 | 37 |
| asia_gdp | Multivariate | Clustering | None | 40 | 11 |
| elections | Multivariate | Clustering | None | 3195 | 54 |
| Multivariate | Clustering | None | 7050 | 12 | |
| ipl | Multivariate | Clustering | None | 153 | 25 |
| jewellery | Multivariate | Clustering | None | 505 | 4 |
| mice | Multivariate | Clustering | None | 1080 | 82 |
| migration | Multivariate | Clustering | None | 233 | 12 |
| perfume | Multivariate | Clustering | None | 20 | 29 |
| pokemon | Multivariate | Clustering | None | 800 | 13 |
| population | Multivariate | Clustering | None | 255 | 56 |
| public_health | Multivariate | Clustering | None | 224 | 21 |
| seeds | Multivariate | Clustering | None | 210 | 7 |
| wholesale | Multivariate | Clustering | None | 440 | 8 |
| tweets | Text | NLP | tweet | 8594 | 2 |
| amazon | Text | NLP / Classification | reviewText | 20000 | 2 |
| kiva | Text | NLP / Classification | en | 6818 | 7 |
| spx | Text | NLP / Regression | text | 874 | 4 |
| wikipedia | Text | NLP / Classification | Text | 500 | 3 |
| automobile | Multivariate | Regression | price | 202 | 26 |
| bike | Multivariate | Regression | cnt | 17379 | 15 |
| boston | Multivariate | Regression | medv | 506 | 14 |
| concrete | Multivariate | Regression | strength | 1030 | 9 |
| diamond | Multivariate | Regression | Price | 6000 | 8 |
| energy | Multivariate | Regression | Heating Load / Cooling Load | 768 | 10 |
| forest | Multivariate | Regression | area | 517 | 13 |
| gold | Multivariate | Regression | Gold_T+22 | 2558 | 121 |
| house | Multivariate | Regression | SalePrice | 1461 | 81 |
| insurance | Multivariate | Regression | charges | 1338 | 7 |
| parkinsons | Multivariate | Regression | PPE | 5875 | 22 |
| traffic | Multivariate | Regression | traffic_volume | 48204 | 8 |
3、设置环境
(1)第一步:导入模块
pycaret提供以下6种模块,当你导入相应的模块之后,就将环境切换到了该环境下。
| S.No | Module | How to Import |
| 1 | Classification | from pycaret.classification import * |
| 2 | Regression | from pycaret.regression import * |
| 3 | Clustering | from pycaret.clustering import * |
| 4 | Anomaly Detection | from pycaret.anomaly import * |
| 5 | Natural Language Processing | from pycaret.nlp import * |
| 6 | Association Rule Mining | from pycaret.arules import * |
(2)第二步:初始化设置
对于PyCaret中的所有模块都是通用的,设置是开始任何机器学习实验的第一步,也是唯一的必需步骤。 除默认情况下执行一些基本处理任务外,PyCaret还提供了广泛的预处理功能,这些功能在结构上将普通的机器学习实验提升为高级解决方案。 在本节中,我们仅介绍了设置功能的必要部分。 可以在此处找到所有预处理功能的详细信息。 下面列出的是初始化设置时PyCaret执行的基本默认任务:
数据类型推断:在PyCaret中执行的任何实验都始于确定所有特征的正确数据类型。 设置函数执行有关数据的基本推断,并执行一些下游任务,例如忽略ID和Date列,分类编码,基于PyCaret内部算法推断的数据类型的缺失值插补。 执行设置后,将出现一个对话框(请参见以下示例),其中包含所有特征及其推断的数据类型的列表。 数据类型推断通常是正确的,但是一旦出现对话框,用户应查看列表的准确性。 如果正确推断了所有数据类型,则可以按Enter键继续,否则,请键入“ quit”以停止实验。

如果您由于无法正确推断一种或多种数据类型而选择输入“退出”,则可以在setup命令中覆盖它们,方法是传递categorical_feature参数以强制分类类型,而numeric_feature参数则强制数字类型。 同样,为了忽略某些功能以成为实验的一部分,您可以在设置程序中传递ignore_features参数。
注意:如果您不希望PyCaret显示确认数据类型的对话框,则可以在设置过程中以“ True”(静默)方式传递为True,以执行无人看管的实验。 我们不建议您这样做,除非您完全确定推断是正确的,或者您之前已经进行过实验,或者正在使用numeric_feature和categorical_feature参数覆盖数据类型。
数据清理和准备:设置功能会自动执行缺失值插补和分类编码,因为它们对于任何机器学习实验都是必不可少的。 默认情况下,平均值用于数字特征的插补,而最频繁使用的值或模式用于分类特征。 您可以使用numeric_imputation和categorical_imputation参数来更改方法。 对于分类问题,如果目标不是数字类型,则安装程序还将执行目标编码。
数据采样:如果样本量大于25,000,PyCaret会根据不同的样本量自动构建初步的线性模型,并提供可视化效果,以根据样本量显示模型的性能。 然后可以使用该图来评估模型的性能是否随样本数量的增加而增加。 如果不是,您可以选择较小的样本量,以提高实验的效率和性能。 请参见下面的示例,在该示例中,我们使用了pycaret存储库中的“银行”数据集,其中包含45,211个样本。
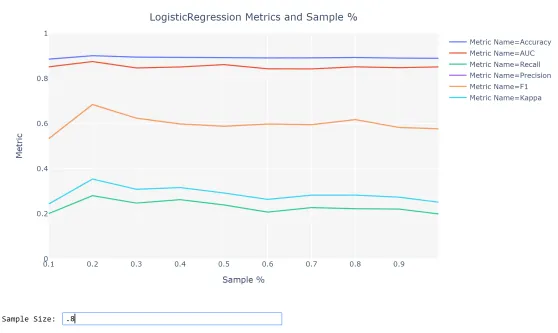
训练测试拆分:设置功能还执行训练测试拆分(针对分类问题进行了分层)。 默认的分割比例为70:30,但是您可以在设置程序中使用train_size参数进行更改。 仅在Train set上使用k倍交叉验证,才能对PyCaret中已训练好的机器学习模型和超参数优化进行评估。
将会话ID分配为种子:如果未传递session_id参数,则会话ID是默认生成的伪随机数。 PyCaret将此id作为种子分发给所有函数,以隔离随机效应。 这样可以在以后在相同或不同的环境中实现可重现性。
以下是一些例子:
分类:
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# Importing module and initializing setup
from pycaret.classification import *
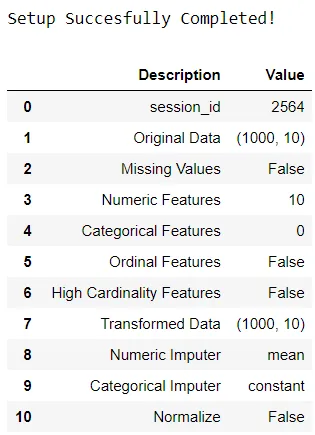
clf1 = setup(data = diabetes, target = 'Class variable')

回归:
from pycaret.datasets import get_data
boston = get_data('boston')
# Importing module and initializing setup
from pycaret.regression import *
reg1 = setup(data = boston, target = 'medv')

聚类:
from pycaret.datasets import get_data
jewellery = get_data('jewellery')
# Importing module and initializing setup
from pycaret.clustering import *
clu1 = setup(data = jewellery)

异常检测:
from pycaret.datasets import get_data
anomalies = get_data('anomaly')
# Importing module and initializing setup
from pycaret.anomaly import *
ano1 = setup(data = anomalies)
自然语言处理:
from pycaret.datasets import get_data
kiva = get_data('kiva')
# Importing module and initializing setup
from pycaret.nlp import *
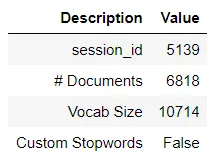
nlp1 = setup(data = kiva, target = 'en')
关联规则挖掘:
from pycaret.datasets import get_data
france = get_data('france')
# Importing module and initializing setup
from pycaret.arules import *
arules1 = setup(data = france, transaction_id = 'InvoiceNo', item_id = 'Description')

更简易的机器学习-pycaret的安装和环境初始化的更多相关文章
- 机器学习实战__安装python环境
环境:win7 64位系统 第一步:安装python 1.下载python2.7.3 64位 msi 版本(这里选择了很多2.7的其他更高版本导致安装setuptools失败,也不知道是什么原因,暂时 ...
- CentOS7+CDH5.14.0安装全流程记录,图文详解全程实测-1虚拟机安装及环境初始化
1.软件准备: VMware-workstation-full-14.1.2-8497320.exe CentOS-7-x86_64-DVD-1804.iso 2.VMare激活码: AU5WA-0E ...
- 微软开源自动机器学习工具NNI安装与使用
微软开源自动机器学习工具 – NNI安装与使用 在机器学习建模时,除了准备数据,最耗时耗力的就是尝试各种超参组合,找到最佳模型的过程了.对于初学者来说,常常是无从下手.即使是对于有经验的算法工程师 ...
- 机器学习库shark安装
经过两天的折腾,一个对c++和机器学习库的安装都一知半解的人终于在反复安装中,成功的将shark库安装好了,小小纪念一下,多亏了卡门的热心帮忙. shark的安装主要分为以下几个部分: (1)下载 s ...
- 机器学习linux系统环境安装
机器学习linux系统环境安装 安装镜像下载 可以自己去ubuntu官方网站按照提示下载amd64的desktop版本 或者考虑到国内镜像站点下载,如tuna,163, ali等 课程使用最新的17. ...
- Windows+Python+anaconda机器学习安装及环境配置步骤
Windows+Python+anaconda机器学习安装及环境配置步骤 1. 下载安装python3.6以上版本(包含pip,不用自己安装)2. 直接下载安装pycharm安装包(用于编写pytho ...
- django 简易博客开发 1 安装、创建、配置、admin使用
首先贴一下项目地址吧 https://github.com/goodspeedcheng/sblog 到现在位置项目实现的功能有: 1.后台管理使用Admin ,前端显示使用bootstrap 2. ...
- 在Windows/Ubuntu下安装OpenGL环境(GLUT/freeglut)与跨平台编译(mingw/g++)
GLUT/freeglut 是什么? OpenGL 和它们有什么关系? OpenGL只是一个标准,它的实现一般自带在操作系统里,只要确保显卡驱动足够新就可以使用.如果需要在程序里直接使用OpenGL, ...
- 第一章 andriod studio 安装与环境搭建
原文 http://blog.csdn.net/zhanghefu/article/details/9286123 第一章 andriod studio 安装与环境搭建 一.Android Stu ...
随机推荐
- 使用代码给Unity中的动画片段绑定回调函数
在制作动作游戏的时候,需要播放许多动画,同时还有个需求,那就是动画播放到一定时间时,给一个回调函数,好做对应的状态变更, 我查了一下,发现如果使用的是unity自带的动画系统,要做到这样的话,需要这样 ...
- python小白入门基础(四:浮点型和布尔型)
# Number (int float bool complex)# (1) float 浮点型 也就是小数# 表达方式一floatvar = 0.98print(floatvar)print(typ ...
- Spring security OAuth2.0认证授权学习第一天(基础概念-认证授权会话)
这段时间没有学习,可能是因为最近工作比较忙,每天回来都晚上11点多了,但是还是要学习的,进过和我的领导确认,在当前公司的技术架构方面,将持续使用Spring security,暂不做Shiro的考虑, ...
- 关于取表中id最大值+1的select语句,哪种效率更高?
需求:取stock表中id最大值+1,作为下一个id值. 特殊情况:考虑到表中会没有值,max(id)会返回空,因此需要用case when进行判断. 实现一:select (case max(id) ...
- [Java数据结构]LinkedHashMap,TreeMap
HashMap不能记住插入时的顺序,但LinkedHashMap可以做到这一点. 例程: Map<Integer,String> empMap=new LinkedHashMap<I ...
- 2020重新出发,NOSQL,MongoDB分布式集群架构
MongoDB分布式集群架构 看到这里相信你已经掌握了 MongoDB 的大部分基本知识,现在在单机环境下操作 MongoDB 已经不存在问题,但是单机环境只适合学习和开发测试,在实际的生产环境中,M ...
- 一、loadrunner脚本录制及回放
录制及回放的注意点: 1.测试系统教复杂时,正确的划分action,对监控的每一个业务模型和操作,起到重要作用 2.录制完成后,先进行编译(改动脚本之后检查下有没有语法错误):工具栏Vuser下有一个 ...
- 【二叉树-BFS系列1】二叉树的右视图、二叉树的锯齿形层次遍历
题目 199. 二叉树的右视图 给定一棵二叉树,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值. 示例: 输入: [1,2,3,null,5,null,4] 输出: [1, ...
- Hadoop入门学习整理(一)
今天是2020年4月8日,是一个平凡而又特殊的日子,武汉在经历了77天的封城之后,于今日0点正式解封.从1月14日放寒假离开武汉,到今天已近3个月,学校的花开了又谢了.随着疫情好转,春回大地,万物复苏 ...
- 三年之久的 etcd3 数据不一致 bug 分析
问题背景 诡异的 K8S 滚动更新异常 笔者某天收到同事反馈,测试环境中 K8S 集群进行滚动更新发布时未生效.通过 kube-apiserver 查看发现,对应的 Deployment 版本已经是最 ...