Python之爬虫(十七) Scrapy框架中Spiders用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页
工作流程分析
- 以初始的URL初始化Request,并设置回调函数,当该request下载完毕并返回时,将生成response,并作为参数传给回调函数. spider中初始的requesst是通过start_requests()来获取的。start_requests()获取 start_urls中的URL,并以parse以回调函数生成Request
- 在回调函数内分析返回的网页内容,可以返回Item对象,或者Dict,或者Request,以及是一个包含三者的可迭代的容器,返回的Request对象之后会经过Scrapy处理,下载相应的内容,并调用设置的callback函数
- 在回调函数内,可以通过lxml,bs4,xpath,css等方法获取我们想要的内容生成item
- 最后将item传递给Pipeline处理
我们以通过简单的分析源码来理解
我通常在写spiders下写爬虫的时候,我们并没有写start_requests来处理start_urls中的url,这是因为我们在继承的scrapy.Spider中已经写过了,我们可以点开scrapy.Spider查看分析
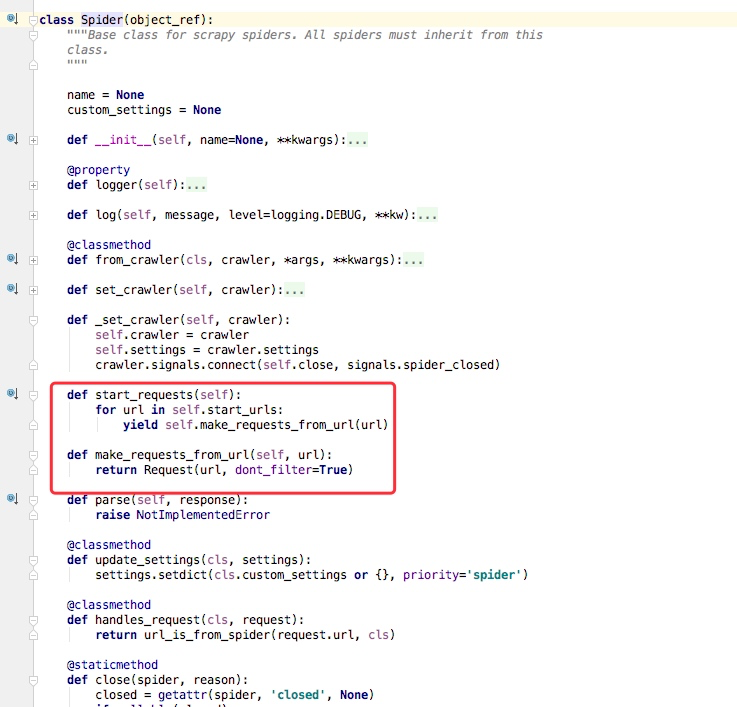
通过上述代码我们可以看到在父类里这里实现了start_requests方法,通过make_requests_from_url做了Request请求
如下图所示的一个例子,parse回调函数中的response就是父类列start_requests方法调用make_requests_from_url返回的结果,并且在parse回调函数中我们可以继续返回Request,如下属代码中yield Request()并设置回调函数。

spider内的一些常用属性
我们所有自己写的爬虫都是继承与spider.Spider这个类
name
定义爬虫名字,我们通过命令启动的时候用的就是这个名字,这个名字必须是唯一的
allowed_domains
包含了spider允许爬取的域名列表。当offsiteMiddleware启用时,域名不在列表中URL不会被访问
所以在爬虫文件中,每次生成Request请求时都会进行和这里的域名进行判断
start_urls
起始的url列表
这里会通过spider.Spider方法中会调用start_request循环请求这个列表中每个地址。
custom_settings
自定义配置,可以覆盖settings的配置,主要用于当我们对爬虫有特定需求设置的时候
设置的是以字典的方式设置:custom_settings = {}
from_crawler
这是一个类方法,我们定义这样一个类方法,可以通过crawler.settings.get()这种方式获取settings配置文件中的信息,同时这个也可以在pipeline中使用
start_requests()
这个方法必须返回一个可迭代对象,该对象包含了spider用于爬取的第一个Request请求
这个方法是在被继承的父类中spider.Spider中写的,默认是通过get请求,如果我们需要修改最开始的这个请求,可以重写这个方法,如我们想通过post请求
make_requests_from_url(url)
这个也是在父类中start_requests调用的,当然这个方法我们也可以重写
parse(response)
这个其实默认的回调函数
负责处理response并返回处理的数据以及跟进的url
该方法以及其他的Request回调函数必须返回一个包含Request或Item的可迭代对象
Python之爬虫(十七) Scrapy框架中Spiders用法的更多相关文章
- scrapy框架中Spiders用法
scrapy框架中Spiders用法 Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据 总的来说spider就是定义爬取的动作以及分析某个网页 工作流程分析 以 ...
- Python爬虫从入门到放弃(十五)之 Scrapy框架中Spiders用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页 工作流程分析 以初始的URL初始化Request,并设 ...
- Python网络爬虫之Scrapy框架(CrawlSpider)
目录 Python网络爬虫之Scrapy框架(CrawlSpider) CrawlSpider使用 爬取糗事百科糗图板块的所有页码数据 Python网络爬虫之Scrapy框架(CrawlSpider) ...
- Python逆向爬虫之scrapy框架,非常详细
爬虫系列目录 目录 Python逆向爬虫之scrapy框架,非常详细 一.爬虫入门 1.1 定义需求 1.2 需求分析 1.2.1 下载某个页面上所有的图片 1.2.2 分页 1.2.3 进行下载图片 ...
- 16.Python网络爬虫之Scrapy框架(CrawlSpider)
引入 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法). 方法 ...
- 16,Python网络爬虫之Scrapy框架(CrawlSpider)
今日概要 CrawlSpider简介 CrawlSpider使用 基于CrawlSpider爬虫文件的创建 链接提取器 规则解析器 引入 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话, ...
- Python学习---爬虫学习[scrapy框架初识]
Scrapy Scrapy是一个框架,可以帮助我们进行创建项目,运行项目,可以帮我们下载,解析网页,同时支持cookies和自定义其他功能. Scrapy是一个为了爬取网站数据,提取结构性数据而编写的 ...
- 5-----Scrapy框架中Spiders用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页 工作流程分析 1.以初始的URL初始化Request, ...
- python爬虫之scrapy框架介绍
一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等) ...
随机推荐
- Python正则式 - re
目录 1. 相关概念 1.1. rstring 1.2. 元字符 2. 模式Pattern 2.1. re.flag 3. API 4. 其他 4.1. 单词边界 '\b' 4.2. 贪婪和非贪婪 4 ...
- SQL Msg 18054, Level 16, State 1
今天接到一个看起来很简单的任务--修改数据库中的一项数据.听起来很简单吧. 在网上搜索了一下,很快就拼凑出了相应的 SQL 语句: UPDATE [suivi].[dbo].[numSerie]SET ...
- @atcoder - AGC026F@ Manju Game
目录 @description@ @solution@ @accepted code@ @details@ @description@ 给定一个含 N 个数的序列,Alice 与 Bob 在博弈.Al ...
- fastjson对String、JSONObject、JSONArray相互转换
String——>>>JSONArray String st = "[{name:Tim,age:25,sex:male},{name:Tom,age:28,sex:mal ...
- 解决错误【selenium.common.exceptions.SessionNotCreatedException】
以前能用,突然不能用了,是浏览器版本可能升级了,与原来的weddriver驱动版本不符合 解决办法:1.更新浏览器驱动, 2.降低浏览器版本
- Android学习笔记基于监听的事件处理
事件处理流程 代码格式: Button btn1 = findViewById(R.id.btn1); btn1.setOnClickListener(new View.OnClickListener ...
- 【译】Announcing Entity Framework Core 5.0 Preview 5
今天我们宣布EF Core 5.0发布第五个预览版. 1 先决条件 EF Core 5.0 的预览版要求 .NET Standard 2.1.这意味着: EF Core 5.0 在 .NET Cor ...
- Java容器相关知识点整理
结合一些文章阅读源码后整理的Java容器常见知识点.对于一些代码细节,本文不展开来讲,有兴趣可以自行阅读参考文献. 1. 思维导图 各个容器的知识点比较分散,没有在思维导图上体现,因此看上去右半部分很 ...
- MySQL的分页存储过程
-- 创建分页存储过程-- 1 判断存在即删除DROP PROCEDURE IF EXISTS popp;-- 2 创建万能分页CREATE PROCEDURE popp(_fls VARCHAR( ...
- Linux下如何查看硬件信息?
我们在 Linux 下进行开发时,有时也需要知道当前的硬件信息,比如:CPU几核?使用情况?内存大小及使用情况?USB设备是否被识别?等等类似此类问题.下面良许介绍一些常用的硬件查看命令. lshw ...