Spider_基础总结5--动态网页抓取--元素审查--json--字典
# 静态网页在浏览器中展示的内容都在HTML的源码中,但主流网页使用 Javascript时,很多内容不出现在HTML的源代码中,此时仍然使用
# requests+beautifulsoup是不能够成功的,如:
# 动态网页的爬取,使用 requests+beautifulsoup是不会成功的:
# import requests
# from bs4 import BeautifulSoup
# url = 'https://api-zero.livere.com/v1/comments/list?callback=jQuery112406954584941688864_1592120544800&limit=10&repSeq=4547710&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=1afecb1fc5912d454d80ffc6&_=1592120544802'
# headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'}
# html = requests.get(url, headers= headers)
# bs=BeautifulSoup(html.text,'html.parser')
# comments_tags=bs.find_all('div',{'class':'reply-content-wrapper'})
# for comment in comments_tags:
# print(comment.attrs['data-content'])
# Ajax: Asynchronous Javascript And XML,异步JvvaScript和 XML; 在不重新加载整个网页的情况下对网页的某部分进行更新,节省流量,速度快。
# 加大了 爬虫的难度。为解决这个问题,可以采用两种技术: 1)通过浏览器审查元素解析真实网页的地址。2)使用 Selenium模拟浏览器的方法。
# 本节内容:通过浏览器审查元素解析真实网页的地址:
# 真实网址:
# 第一页: https://api-zero.livere.com/v1/comments/list?callback=jQuery112406954584941688864_1592120544800&limit=10&repSeq=4547710&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=1afecb1fc5912d454d80ffc6&_=1592120544802
# 第二页: https://api-zero.livere.com/v1/comments/list?callback=jQuery112408983696804040213_1592128123614&limit=10&offset=2&repSeq=4547710&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=1afecb1fc5912d454d80ffc6&_=1592128123621
# 重新刷新第二页: https://api-zero.livere.com/v1/comments/list?callback=jQuery1124042695935490813275_1592128347126&limit=10&offset=2&repSeq=4547710&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=1afecb1fc5912d454d80ffc6&_=1592128347133
# 第一页和第二页最明显的区别在于:
# offset (虽然有其他地方也不一样,但不影响,只有 offset起决定作用),所以可以通过控制 offset来翻页。
# 请求头: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362
# 根据上面信息,我们将代码设计为:
import requests
url = """https://api-zero.livere.com/v1/comments/list?callback=jQuery112406954584941688864_1592120544800&limit=10&repSeq=4547710&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=1afecb1fc5912d454d80ffc6&_=1592120544802"""
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'}
r = requests.get(url, headers= headers)
print (r.text)
/**/ typeof jQuery112406954584941688864_1592120544800 === 'function' && jQuery112406954584941688864_1592120544800({"results":{"parents":[{"replySeq":42003685,"name":"奔跑的苹果树","memberId":"oBVoaxMyiTIYdTYmbPxXxNVrAxz4","memberIcon":"http://thirdwx.qlogo.cn/mmopen/vi_32/2CBNK5cDVstrL3W33VXJSCic8Pu3jczS4UNQtf04ZhdpVtk1PlRc8slz1lzJCakwKeFLtdGO0cqj9dDBosicWq6w/132","memberUrl":"http://www.wechat.com","memberDomain":"wechat","good":0,"bad":0,"police":0,"parentSeq":42003685,"directSeq":0,"shortUrl":null,"title":"第四章- 动态网页抓取 (解析真实地址 + selenium)","site":"http://www.santostang.com/2018/07/14/%E7%AC%AC%E5%9B%9B%E7%AB%A0%EF%BC%9A%E5%8A%A8%E6%80%81%E7%BD%91%E9%A1%B5%E6%8A%93%E5%8F%96-%E8%A7%A3%E6%9E%90%E7%9C%9F%E5%AE%9E%E5%9C%B0%E5%9D%80-selenium/","email":null,"ipAddress":"112.102.211.149","isMobile":"0","agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36","septSns":null,"targetService":null,"targetUserName":null,"info1":null,"info2":null,"info3":null,"image1":null,"image2":null,"image3":null,"link1":null,"link2":null,"link3":null,"isSecret":0,"isModified":0,"confirm":0,"subCount":0,"regdate":"2020-06-14T07:35:53.000Z","deletedDate":null,"file1":null,"file2":null,"file3":null,"additionalSeq":0,"content":"真实地址怎么获取?点击右键检查了也没发现啊。","quotationSeq":null,"quotationContent":null,"consumerSeq":1020,"livereSeq":28583,"repSeq":4547710,"memberGroupSeq":32374754,"memberSeq":32926179,"status":0,"repGroupSeq":0,"adminSeq":25413747,"deleteReason":null,"sticker":0,"version":null},{"replySeq":41888279,"name":"Creep","memberId":"oBVoaxAxqLr16sfwz1GXm9UaHVF4","memberIcon":"http://thirdwx.qlogo.cn/mmopen/vi_32/62cLVFreHtJN80DNyHnEGqrC9v42QWErXr20KB2icDCSQuNAPuYibpO7yAYTb5FY90MSpl1gLIabf7KktQibia4nNA/132","memberUrl":"http://www.wechat.com","memberDomain":"wechat","good":0,"bad":0,"police":0,"parentSeq":41888279,"directSeq":0,"shortUrl":null,"title":"第四章- 动态网页抓取 (解析真实地址 + selenium)","site":"http://www.santostang.com/2018/07/14/%E7%AC%AC%E5%9B%9B%E7%AB%A0%EF%BC%9A%E5%8A%A8%E6%80%81%E7%BD%91%E9%A1%B5%E6%8A%93%E5%8F%96-%E8%A7%A3%E6%9E%90%E7%9C%9F%E5%AE%9E%E5%9C%B0%E5%9D%80-selenium/","email":null,"ipAddress":"58.62.87.37","isMobile":"0","agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.159 Safari/537.36","septSns":null,"targetService":null,"targetUserName":null,"info1":null,"info2":null,"info3":null,"image1":null,"image2":null,"image3":null,"link1":null,"link2":null,"link3":null,"isSecret":0,"isModified":0,"confirm":0,"subCount":0,"regdate":"2020-06-01T12:20:08.000Z","deletedDate":null,"file1":null,"file2":null,"file3":null,"additionalSeq":0,"content":"学习中","quotationSeq":null,"quotationContent":null,"consumerSeq":1020,"livereSeq":28583,"repSeq":4547710,"memberGroupSeq":32349986,"memberSeq":32901188,"status":0,"repGroupSeq":0,"adminSeq":25413747,"deleteReason":null,"sticker":0,"version":null},{"replySeq":41882866,"name":"余非鱼^*^","memberId":"oBVoaxHwTIri5lNP36JXwSK2NMzg","memberIcon":"http://thirdwx.qlogo.cn/mmopen/vi_32/Q0j4TwGTfTIl3ibbP9gC9ES0zN5LIhvfzPB4zICW123JG2PawaXS9c0oiaoFDQp4RJrupZf8AolXZQH3tNI2QwWA/132","memberUrl":"http://www.wechat.com","memberDomain":"wechat","good":0,"bad":0,"police":0,"parentSeq":41882866,"directSeq":0,"shortUrl":null,"title":"第四章- 动态网页抓取 (解析真实地址 + selenium)","site":"http://www.santostang.com/2018/07/14/%E7%AC%AC%E5%9B%9B%E7%AB%A0%EF%BC%9A%E5%8A%A8%E6%80%81%E7%BD%91%E9%A1%B5%E6%8A%93%E5%8F%96-%E8%A7%A3%E6%9E%90%E7%9C%9F%E5%AE%9E%E5%9C%B0%E5%9D%80-selenium/","email":null,"ipAddress":"171.34.101.38","isMobile":"0","agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36","septSns":null,"targetService":null,"targetUserName":null,"info1":null,"info2":null,"info3":null,"image1":null,"image2":null,"image3":null,"link1":null,"link2":null,"link3":null,"isSecret":0,"isModified":0,"confirm":0,"subCount":0,"regdate":"2020-06-01T02:35:00.000Z","deletedDate":null,"file1":null,"file2":null,"file3":null,"additionalSeq":0,"content":"一起学习","quotationSeq":null,"quotationContent":null,"consumerSeq":1020,"livereSeq":28583,"repSeq":4547710,"memberGroupSeq":32348903,"memberSeq":32900097,"status":0,"repGroupSeq":0,"adminSeq":25413747,"deleteReason":null,"sticker":0,"version":null},{"replySeq":41458240,"name":"無","memberId":"UID_43B3E8679B3B9880BEB734882BCE59B3","memberIcon":"http://thirdqq.qlogo.cn/g?b=oidb&k=zuYsrwicH5EvoOeKJibGVaaQ&s=100&t=1584881994","memberUrl":"https://qq.com/","memberDomain":"qq","good":0,"bad":0,"police":0,"parentSeq":41458240,"directSeq":0,"shortUrl":null,"title":"第四章- 动态网页抓取 (解析真实地址 + selenium)","site":"http://www.santostang.com/2018/07/14/%E7%AC%AC%E5%9B%9B%E7%AB%A0%EF%BC%9A%E5%8A%A8%E6%80%81%E7%BD%91%E9%A1%B5%E6%8A%93%E5%8F%96-%E8%A7%A3%E6%9E%90%E7%9C%9F%E5%AE%9E%E5%9C%B0%E5%9D%80-selenium/","email":null,"ipAddress":"117.166.113.250","isMobile":"0","agent":"Mozilla/5.0 (Windows NT 10.0; ) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36","septSns":null,"targetService":null,"targetUserName":null,"info1":null,"info2":null,"info3":null,"image1":null,"image2":null,"image3":null,"link1":null,"link2":null,"link3":null,"isSecret":0,"isModified":0,"confirm":0,"subCount":0,"regdate":"2020-04-22T04:29:49.000Z","deletedDate":null,"file1":null,"file2":null,"file3":null,"additionalSeq":0,"content":"一句话,给我爬!!!!","quotationSeq":null,"quotationContent":null,"consumerSeq":1020,"livereSeq":28583,"repSeq":4547710,"memberGroupSeq":32277925,"memberSeq":32828481,"status":0,"repGroupSeq":0,"adminSeq":25413747,"deleteReason":null,"sticker":0,"version":null},{"replySeq":41085166,"name":"astin2020","memberId":"xiangxuexi2018@163.com","memberIcon":"https://cdn-city.livere.com/images/user_profile_4","memberUrl":"https://livere.com","memberDomain":"livere","good":0,"bad":0,"police":0,"parentSeq":41085166,"directSeq":0,"shortUrl":null,"title":"第四章- 动态网页抓取 (解析真实地址 + selenium)","site":"http://www.santostang.com/2018/07/14/%E7%AC%AC%E5%9B%9B%E7%AB%A0%EF%BC%9A%E5%8A%A8%E6%80%81%E7%BD%91%E9%A1%B5%E6%8A%93%E5%8F%96-%E8%A7%A3%E6%9E%90%E7%9C%9F%E5%AE%9E%E5%9C%B0%E5%9D%80-selenium/","email":null,"ipAddress":"125.67.134.151","isMobile":"0","agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36","septSns":null,"targetService":null,"targetUserName":null,"info1":null,"info2":null,"info3":null,"image1":null,"image2":null,"image3":null,"link1":null,"link2":null,"link3":null,"isSecret":0,"isModified":0,"confirm":0,"subCount":0,"regdate":"2020-03-22T17:13:25.000Z","deletedDate":null,"file1":null,"file2":null,"file3":null,"additionalSeq":0,"content":"为什么不多放几个回帖","quotationSeq":null,"quotationContent":null,"consumerSeq":1020,"livereSeq":28583,"repSeq":4547710,"memberGroupSeq":32204920,"memberSeq":32754725,"status":0,"repGroupSeq":0,"adminSeq":25413747,"deleteReason":null,"sticker":0,"version":null},{"replySeq":41085164,"name":"astin2020","memberId":"xiangxuexi2018@163.com","memberIcon":"https://cdn-city.livere.com/images/user_profile_4","memberUrl":"https://livere.com","memberDomain":"livere","good":0,"bad":0,"police":0,"parentSeq":41085164,"directSeq":0,"shortUrl":null,"title":"第四章- 动态网页抓取 (解析真实地址 + selenium)","site":"http://www.santostang.com/2018/07/14/%E7%AC%AC%E5%9B%9B%E7%AB%A0%EF%BC%9A%E5%8A%A8%E6%80%81%E7%BD%91%E9%A1%B5%E6%8A%93%E5%8F%96-%E8%A7%A3%E6%9E%90%E7%9C%9F%E5%AE%9E%E5%9C%B0%E5%9D%80-selenium/","email":null,"ipAddress":"125.67.134.151","isMobile":"0","agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36","septSns":null,"targetService":null,"targetUserName":null,"info1":null,"info2":null,"info3":null,"image1":null,"image2":null,"image3":null,"link1":null,"link2":null,"link3":null,"isSecret":0,"isModified":0,"confirm":0,"subCount":0,"regdate":"2020-03-22T17:13:01.000Z","deletedDate":null,"file1":null,"file2":null,"file3":null,"additionalSeq":0,"content":"哎,还要多少啊。","quotationSeq":null,"quotationContent":null,"consumerSeq":1020,"livereSeq":28583,"repSeq":4547710,"memberGroupSeq":32204920,"memberSeq":32754725,"status":0,"repGroupSeq":0,"adminSeq":25413747,"deleteReason":null,"sticker":0,"version":null},{"replySeq":41085162,"name":"astin2020","memberId":"xiangxuexi2018@163.com","memberIcon":"https://cdn-city.livere.com/images/user_profile_4","memberUrl":"https://livere.com","memberDomain":"livere","good":0,"bad":0,"police":0,"parentSeq":41085162,"directSeq":0,"shortUrl":null,"title":"第四章- 动态网页抓取 (解析真实地址 + selenium)","site":"http://www.santostang.com/2018/07/14/%E7%AC%AC%E5%9B%9B%E7%AB%A0%EF%BC%9A%E5%8A%A8%E6%80%81%E7%BD%91%E9%A1%B5%E6%8A%93%E5%8F%96-%E8%A7%A3%E6%9E%90%E7%9C%9F%E5%AE%9E%E5%9C%B0%E5%9D%80-selenium/","email":null,"ipAddress":"125.67.134.151","isMobile":"0","agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36","septSns":null,"targetService":null,"targetUserName":null,"info1":null,"info2":null,"info3":null,"image1":null,"image2":null,"image3":null,"link1":null,"link2":null,"link3":null,"isSecret":0,"isModified":0,"confirm":0,"subCount":0,"regdate":"2020-03-22T17:12:40.000Z","deletedDate":null,"file1":null,"file2":null,"file3":null,"additionalSeq":0,"content":"我不知道要多少帖子才能翻篇啊,你们没有买他的书吗","quotationSeq":null,"quotationContent":null,"consumerSeq":1020,"livereSeq":28583,"repSeq":4547710,"memberGroupSeq":32204920,"memberSeq":32754725,"status":0,"repGroupSeq":0,"adminSeq":25413747,"deleteReason":null,"sticker":0,"version":null},{"replySeq":41085159,"name":"astin2020","memberId":"xiangxuexi2018@163.com","memberIcon":"https://cdn-city.livere.com/images/user_profile_4","memberUrl":"https://livere.com","memberDomain":"livere","good":0,"bad":0,"police":0,"parentSeq":41085159,"directSeq":0,"shortUrl":null,"title":"第四章- 动态网页抓取 (解析真实地址 + selenium)","site":"http://www.santostang.com/2018/07/14/%E7%AC%AC%E5%9B%9B%E7%AB%A0%EF%BC%9A%E5%8A%A8%E6%80%81%E7%BD%91%E9%A1%B5%E6%8A%93%E5%8F%96-%E8%A7%A3%E6%9E%90%E7%9C%9F%E5%AE%9E%E5%9C%B0%E5%9D%80-selenium/","email":null,"ipAddress":"125.67.134.151","isMobile":"0","agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36","septSns":null,"targetService":null,"targetUserName":null,"info1":null,"info2":null,"info3":null,"image1":null,"image2":null,"image3":null,"link1":null,"link2":null,"link3":null,"isSecret":0,"isModified":0,"confirm":0,"subCount":0,"regdate":"2020-03-22T17:11:49.000Z","deletedDate":null,"file1":null,"file2":null,"file3":null,"additionalSeq":0,"content":"我要疯了。作者拜托你能不能改一下啊","quotationSeq":null,"quotationContent":null,"consumerSeq":1020,"livereSeq":28583,"repSeq":4547710,"memberGroupSeq":32204920,"memberSeq":32754725,"status":0,"repGroupSeq":0,"adminSeq":25413747,"deleteReason":null,"sticker":0,"version":null},{"replySeq":41085152,"name":"astin2020","memberId":"xiangxuexi2018@163.com","memberIcon":"https://cdn-city.livere.com/images/user_profile_4","memberUrl":"https://livere.com","memberDomain":"livere","good":0,"bad":0,"police":0,"parentSeq":41085152,"directSeq":0,"shortUrl":null,"title":"第四章- 动态网页抓取 (解析真实地址 + selenium)","site":"http://www.santostang.com/2018/07/14/%E7%AC%AC%E5%9B%9B%E7%AB%A0%EF%BC%9A%E5%8A%A8%E6%80%81%E7%BD%91%E9%A1%B5%E6%8A%93%E5%8F%96-%E8%A7%A3%E6%9E%90%E7%9C%9F%E5%AE%9E%E5%9C%B0%E5%9D%80-selenium/","email":null,"ipAddress":"125.67.134.151","isMobile":"0","agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36","septSns":null,"targetService":null,"targetUserName":null,"info1":null,"info2":null,"info3":null,"image1":null,"image2":null,"image3":null,"link1":null,"link2":null,"link3":null,"isSecret":0,"isModified":0,"confirm":0,"subCount":0,"regdate":"2020-03-22T17:11:22.000Z","deletedDate":null,"file1":null,"file2":null,"file3":null,"additionalSeq":0,"content":"一页到底能装多少回帖啊?","quotationSeq":null,"quotationContent":null,"consumerSeq":1020,"livereSeq":28583,"repSeq":4547710,"memberGroupSeq":32204920,"memberSeq":32754725,"status":0,"repGroupSeq":0,"adminSeq":25413747,"deleteReason":null,"sticker":0,"version":null},{"replySeq":41085150,"name":"astin2020","memberId":"xiangxuexi2018@163.com","memberIcon":"https://cdn-city.livere.com/images/user_profile_4","memberUrl":"https://livere.com","memberDomain":"livere","good":0,"bad":0,"police":0,"parentSeq":41085150,"directSeq":0,"shortUrl":null,"title":"第四章- 动态网页抓取 (解析真实地址 + selenium)","site":"http://www.santostang.com/2018/07/14/%E7%AC%AC%E5%9B%9B%E7%AB%A0%EF%BC%9A%E5%8A%A8%E6%80%81%E7%BD%91%E9%A1%B5%E6%8A%93%E5%8F%96-%E8%A7%A3%E6%9E%90%E7%9C%9F%E5%AE%9E%E5%9C%B0%E5%9D%80-selenium/","email":null,"ipAddress":"125.67.134.151","isMobile":"0","agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36","septSns":null,"targetService":null,"targetUserName":null,"info1":null,"info2":null,"info3":null,"image1":null,"image2":null,"image3":null,"link1":null,"link2":null,"link3":null,"isSecret":0,"isModified":0,"confirm":0,"subCount":0,"regdate":"2020-03-22T17:10:59.000Z","deletedDate":null,"file1":null,"file2":null,"file3":null,"additionalSeq":0,"content":"好累啊","quotationSeq":null,"quotationContent":null,"consumerSeq":1020,"livereSeq":28583,"repSeq":4547710,"memberGroupSeq":32204920,"memberSeq":32754725,"status":0,"repGroupSeq":0,"adminSeq":25413747,"deleteReason":null,"sticker":0,"version":null}],"children":[],"quotations":[]},"resultCode":200,"resultMessage":"Okay, livere"});
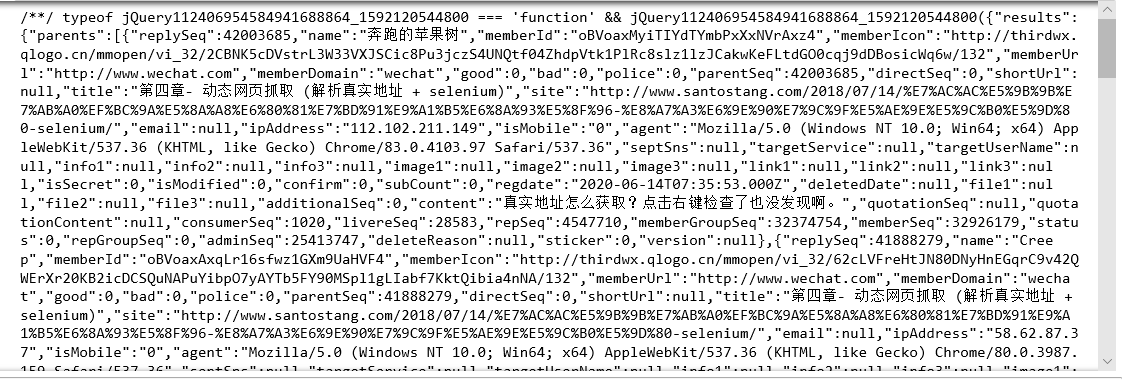

# 只获取第一页评论:
# 解析得到的字符串r.text(即 json字符串)可以使用json库来完成解析:
import json
import requests
url = """https://api-zero.livere.com/v1/comments/list?callback=jQuery112406954584941688864_1592120544800&limit=10&repSeq=4547710&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=1afecb1fc5912d454d80ffc6&_=1592120544802"""
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'}
r = requests.get(url, headers= headers)
json_data_dict=json.loads(r.text[r.text.find('{'):-2])
# 将从左大括号开始至倒数第三个字符(即将字符串末尾的括号和分号去除掉)load反序列化成字典。
# json_data_dict是一个字典嵌套字典的数据结构(字典的value是字典)。
# 其中外部字典的results键对应一个字典,该字典的parents键对应一个值是列表(列表的元素又是字典)。
comments_list=json_data_dict['results']['parents']
for comment_dict in comments_list:
print(comment_dict['content'])
# 或 :
import json
import requests
import jsonpath
url = """https://api-zero.livere.com/v1/comments/list?callback=jQuery112406954584941688864_1592120544800&limit=10&repSeq=4547710&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=1afecb1fc5912d454d80ffc6&_=1592120544802"""
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'}
r = requests.get(url, headers= headers)
json_data_dict=json.loads(r.text[r.text.find('{'):-2])
comments_list=jsonpath.jsonpath(json_data_dict,'$.results.parents[*].content')
for comment in comments_list:
print(comment)
# 真实地址怎么获取?点击右键检查了也没发现啊。
# 学习中
# 一起学习
# 一句话,给我爬!!!!
# 为什么不多放几个回帖
# 哎,还要多少啊。
# 我不知道要多少帖子才能翻篇啊,你们没有买他的书吗
# 我要疯了。作者拜托你能不能改一下啊
# 一页到底能装多少回帖啊?
# 好累啊
# 获取两页评论:
import json
import requests
def get_comments(page_num):
global comments_list
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'}
url='https://api-zero.livere.com/v1/comments/list?callback=jQuery1124042695935490813275_1592128347126&limit=10&offset='\
+page_num+\
'&repSeq=4547710&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=1afecb1fc5912d454d80ffc6&_=1592128347133'
r = requests.get(url, headers= headers)
json_data_dict=json.loads(r.text[r.text.find('{'):-2]) # 将从左大括号开始至倒数第三个字符(即将字符串末尾的 ');'括号和分号去除掉)load反序列化成字典。
# json_data_dict是一个字典嵌套字典的数据结构(字典的value是字典)。
# 其中外部字典的results键对应一个字典,该字典的parents键对应一个值是列表(列表的元素又是字典)。
comments_list.extend(json_data_dict['results']['parents']) # 列表
if __name__=='__main__':
comments_list=[]
for page_num in range(1,3):
get_comments(str(page_num))
for comment_dict in comments_list:
print(comment_dict['content'])
# 真实地址怎么获取?点击右键检查了也没发现啊。
# 学习中
# 一起学习
# 一句话,给我爬!!!!
# 为什么不多放几个回帖
# 哎,还要多少啊。
# 我不知道要多少帖子才能翻篇啊,你们没有买他的书吗
# 我要疯了。作者拜托你能不能改一下啊
# 一页到底能装多少回帖啊?
# 好累啊
# 还不够哦
# 如果这样违反了你的规定,请原谅,我也是没有办法,只能帮你把水灌上
# 不然好多代码我没有办法去按照你书上的内容操作。很郁闷
# 主人可能忘记爬虫的跟帖必须要翻过两页才能测试啊
# 是不是要10页才翻篇
# 我要追加多少评论才够两页呢
# 为什么我能看到评论呢??
# 学习
# 不是
# 我是第一个来的吗?
# 回顾:
# 1)--代码在 IDE里的换行:
a='aaaaaaaaaaaaaaaaaaaaabbbbbbccc\
ggggg'
print(a) # aaaaaaaaaaaaaaaaaaaaabbbbbbcccggggg
b='aaaaaaaaaaaaaaaaaaaaabbbbbbccc'\
+\
'ggggg'
print(b) # aaaaaaaaaaaaaaaaaaaaabbbbbbcccggggg
# 2)--在输出里换行,换行符是字符串本身的一部分:
c='aaaaaaaaaaaaaaaaaaaaabbbbbbccc\nggggg'
print(c)
# aaaaaaaaaaaaaaaaaaaaabbbbbbccc
# ggggg
i=True
if\
i==True:
print('haha')
Spider_基础总结5--动态网页抓取--元素审查--json--字典的更多相关文章
- Spider_基础总结6--动态网页抓取--selenium
# 有些网站使用 '检查元素'也不能够好使,它们会对地址进行加密,此时使用Selenium 调用浏览器渲染引擎可以模拟用户的操作,完成抓取: # 注:selenium既可以抓取静态网页也可以抓取动态网 ...
- Python开发爬虫之动态网页抓取篇:爬取博客评论数据——通过Selenium模拟浏览器抓取
区别于上篇动态网页抓取,这里介绍另一种方法,即使用浏览器渲染引擎.直接用浏览器在显示网页时解析 HTML.应用 CSS 样式并执行 JavaScript 的语句. 这个方法在爬虫过程中会打开一个浏览器 ...
- python网络爬虫-动态网页抓取(五)
动态抓取的实例 在开始爬虫之前,我们需要了解一下Ajax(异步请求).它的价值在于在与后台进行少量的数据交换就可以使网页实现异步更新. 如果使用Ajax加载的动态网页抓取,有两种方法: 通过浏览器审查 ...
- 面向初学者的Python爬虫程序教程之动态网页抓取
目的是对所有注释进行爬网. 下面列出了已爬网链接.如果您使用AJAX加载动态网页,则有两种方式对其进行爬网. 分别介绍了两种方法:(如果对代码有任何疑问,请提出改进建议)解析真实地址爬网示例是参考链接 ...
- java+phantomjs实现动态网页抓取
1.下载地址:http://phantomjs.org/download.html 2.java代码 public void getHtml(String url) { HTML="&quo ...
- Spider--动态网页抓取--审查元素
# 静态网页在浏览器中展示的内容都在HTML的源码中,但主流网页使用 Javascript时,很多内容不出现在HTML的源代码中,我们需要使用动态网页抓取技术. # Ajax: Asynchronou ...
- 动态网页爬取例子(WebCollector+selenium+phantomjs)
目标:动态网页爬取 说明:这里的动态网页指几种可能:1)需要用户交互,如常见的登录操作:2)网页通过JS / AJAX动态生成,如一个html里有<div id="test" ...
- Python爬虫之三种网页抓取方法性能比较
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块. 1. 正则表达式 如果你对正则表达式还不熟悉,或是需要一些提 ...
- Python之HTML的解析(网页抓取一)
http://blog.csdn.net/my2010sam/article/details/14526223 --------------------- 对html的解析是网页抓取的基础,分析抓取的 ...
随机推荐
- 3.Android网络编程-http介绍
1.HTTP请求方法 根据HTTP标准,HTTP请求可以使用多种请求方法. HTTP1.0定义了三种请求方法: GET(查), POST(改)和 HEAD(获取报头,一般用来测试链接是否正常)方法. ...
- lftp源码安装时 error: Package requirements (gnutls >= 1.0.0) were not met: No package 'gnutls' found
lftp 使用疑惑与解决方法: 一,从官网下载源码后,解压./configure后,报错: error: Package requirements (gnutls >= 1.0.0) were ...
- 【UR #9】App 管理器
UOJ小清新题表 题目内容 UOJ链接 一句话题意:给出一个强联通的混合图,有一些有向边和无向边.删除一些边使其维持强联通的状态,求删边方案. 数据范围 \(1\leq n\leq 5000,0\le ...
- ORACLE结构化查询语句
- php超全局数组 为什么swoole的http服务不能用
php的超全局数组$_GET等九个 可以直接使用 无需定义 实际上是浏览器请求到Apache或者nginx的时候 转发到PHP处理模块 fpm转发给php解释器处理 php封装好后丢给php的 sw ...
- ps 批量kill进程
Linux下批量kill掉进程 ps -ef|grep java|grep -v grep|cut -c 9-15|xargs kill -9 管道符"|"用来隔开两个命令,管 ...
- Go语言中Goroutine与线程的区别
1.什么是Goroutine? Goroutine是建立在线程之上的轻量级的抽象.它允许我们以非常低的代价在同一个地址空间中并行地执行多个函数或者方法.相比于线程,它的创建和销毁的代价要小很多,并且它 ...
- day72:drf:
目录 1.续:反序列化功能(5-8) 1.用户post类型提交数据,反序列化功能的步骤 2.反序列化功能的局部钩子和全局钩子 局部钩子和全局钩子在序列化器中的使用 反序列化相关校验的执行顺序 3.反序 ...
- ubuntu JDK&SDK 环境变量配置
ubuntu JDK&SDK 环境变量配置 一.下载JDK 1. 先卸载Ubuntu 带的openJDK: sudo apt-get purge openjdk* 2.到http://www. ...
- mybatis 架构及基础模块
1. mybatis整体架构 基础支撑层详解 1.日志模块 mybatis日志模块没有实现类,需要接入第三方的组件,问题是第三方的组件有各自的log级别,为了能接入第三方组件,mybati日志模块定义 ...