云原生系列5 容器化日志之EFK
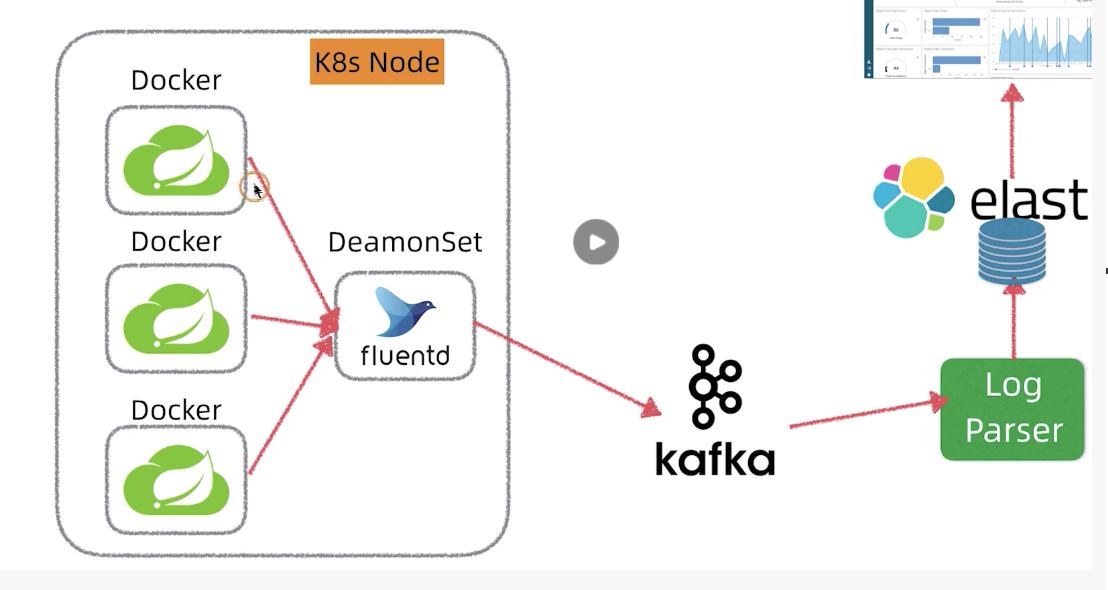
上图是EFK架构图,k8s环境下常见的日志采集方式。
日志需求
1 集中采集微服务的日志,可以根据请求id追踪到完整的日志;
2 统计请求接口的耗时,超出最长响应时间的,需要做报警,并针对性的进行调优;
3 慢sql排行榜,并报警;
4 异常日志排行榜,并报警;
5 慢页面请求排行,并告警;
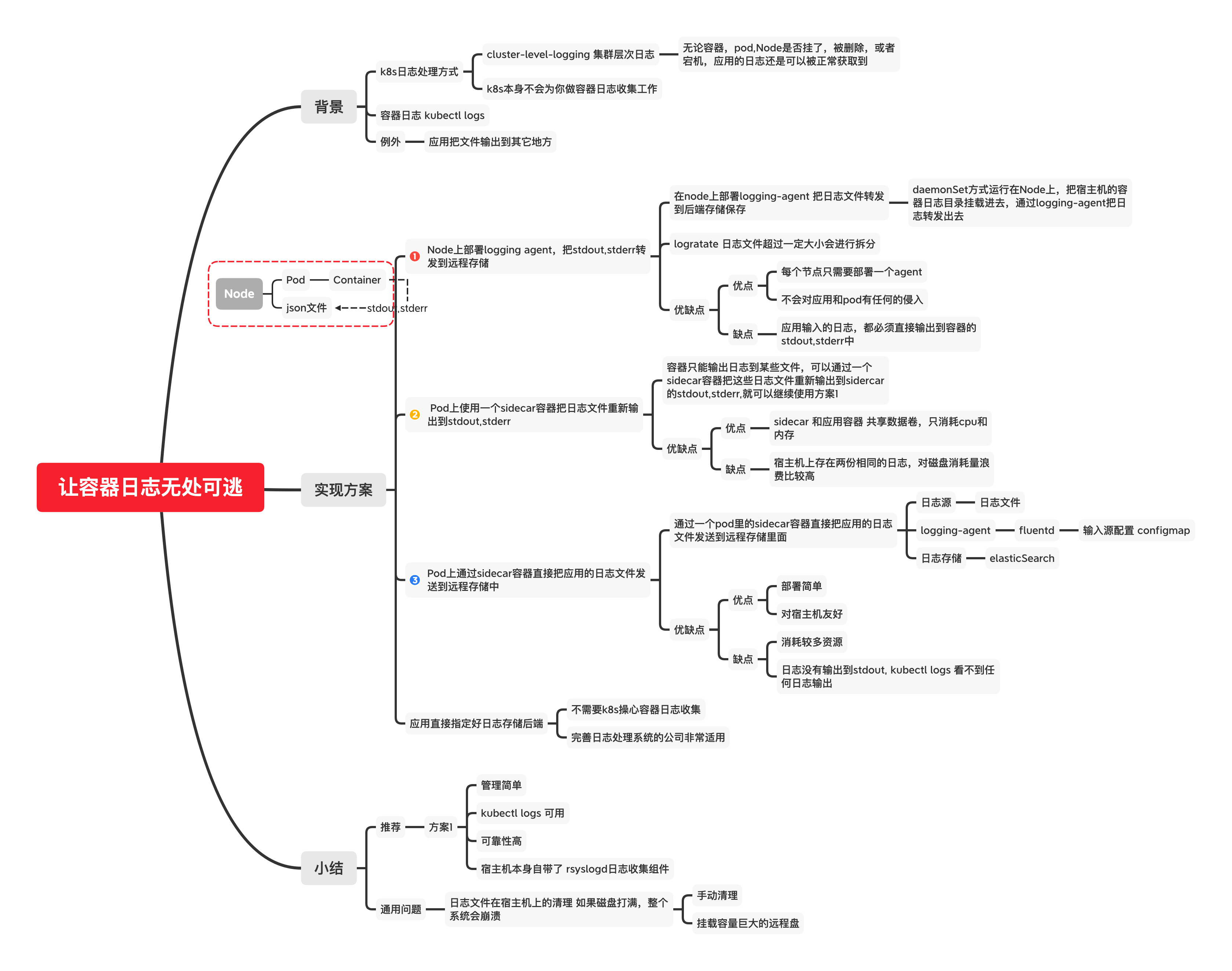
k8s的日志采集
k8s本身不会为你做日志采集,需要自己做;
k8s的容器日志处理方式采用的 集群层级日志,
即容器销毁,pod漂移,Node宕机不会对容器日志造成影响;
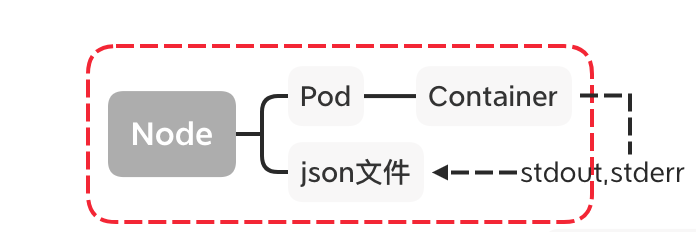
容器的日志会输出到stdout,stderr,对应的存储在宿主机的目录中,
即 /var/lib/docker/container ;
Node上通过日志代理转发
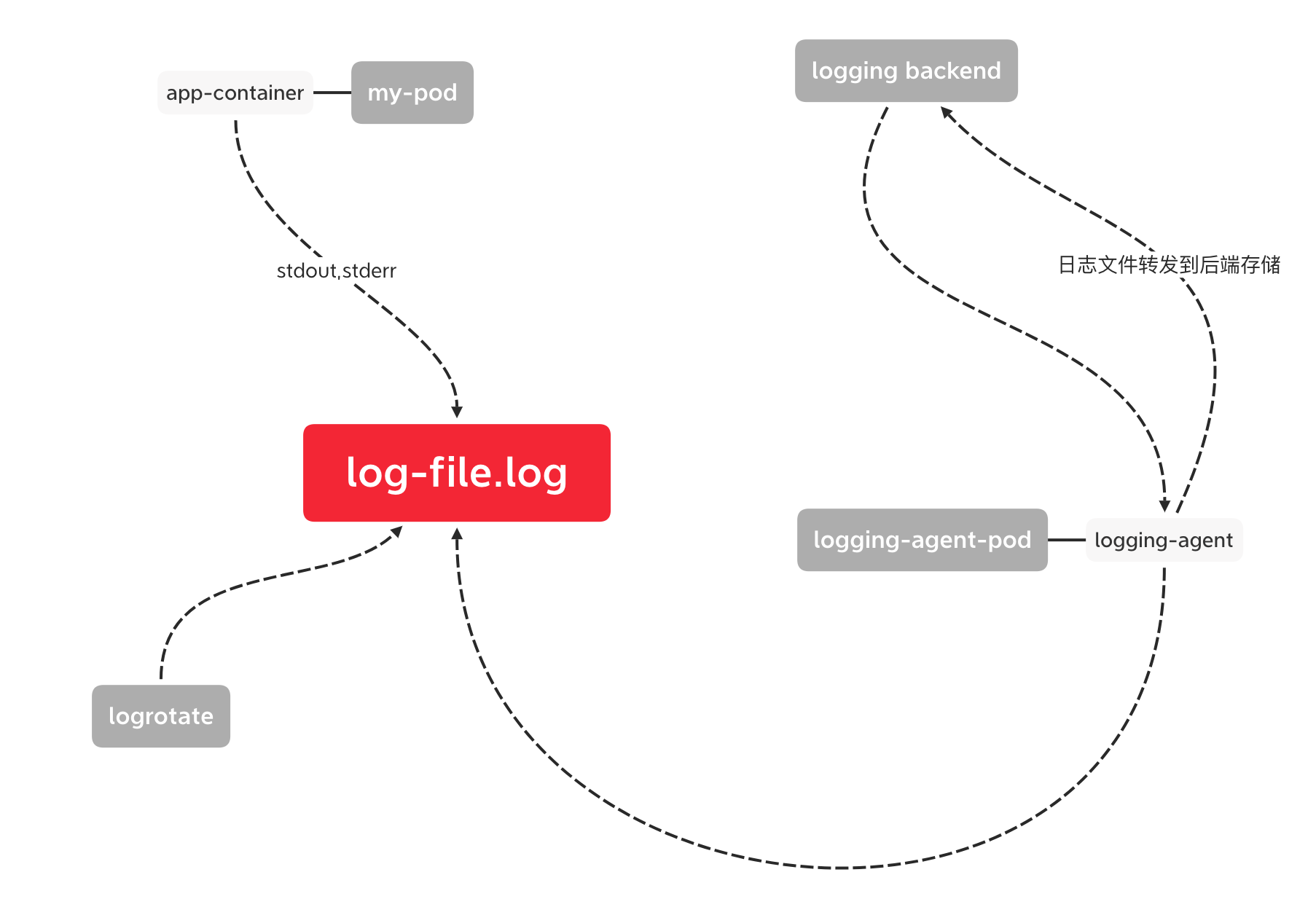
在每个node上部署一个daemonset , 跑一个logging-agent收集日志,
比如fluentd, 采集宿主机对应的数据盘上的日志,然后输出到日志存储服务或者消息队列;
优缺点分析:
| 对比 | 说明 |
|---|---|
| 优点 | 1每个Node只需要部署一个Pod采集日志 2对应用无侵入 |
| 缺点 | 应用输出的日志都必须直接输出到容器的stdout,stderr中 |
Pod内部通过sidecar容器转发到日志服务
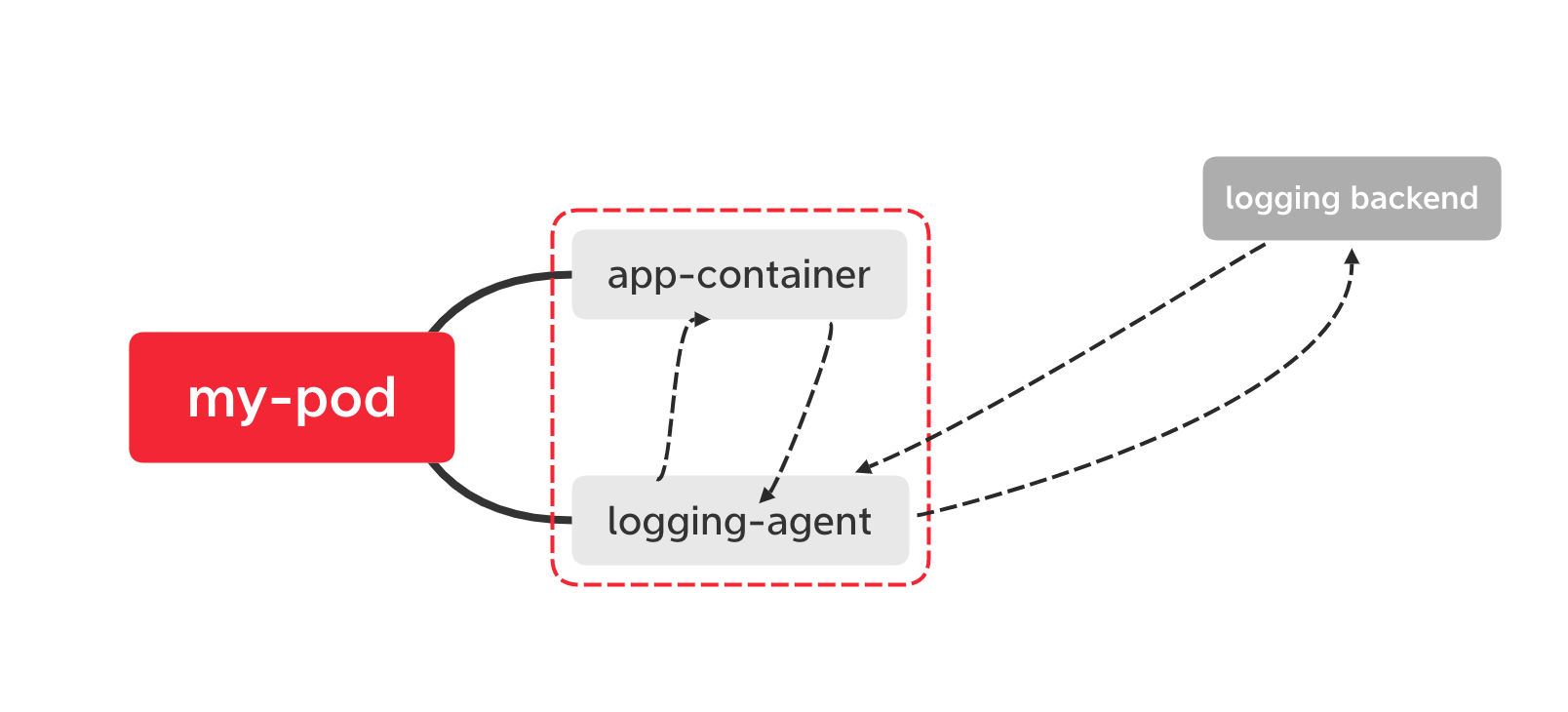
通过在pod中启动一个sidecar容器,比如fluentd, 读取容器挂载的volume目录,输出到日志服务端;
日志输入源: 日志文件
日志处理: logging-agent ,比如fluentd
日志存储: 比如elasticSearch , kafka
优缺点分析:
| 对比 | 说明 |
|---|---|
| 优点 | 1 部署简单;2 对宿主机友好; |
| 缺点 | 1. 消耗较多的资源;2. 日志通过kubectl logs 无法看到 |
示例:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i:$(data)" >> /var/log/1.log
echo "$(data) INFO $i" >> /var/log/2.log
i=$((i+1))
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-agent
image: k8s.gcr.io/fluentd-gcp:1.30
env:
- name: FLUENTD_ARGS
value: -c /etc/fluentd-config/fluentd.conf
valumeMounts:
- name: varlog
mountPath: /var/log
- name: config-volume
mountPath: /etc/fluentd-config
volumes:
- name: varlog
emptyDir: {}
- name: config-volume
configMap:
name: fluentd-config
Pod内部通过sidecar容器输出到stdout
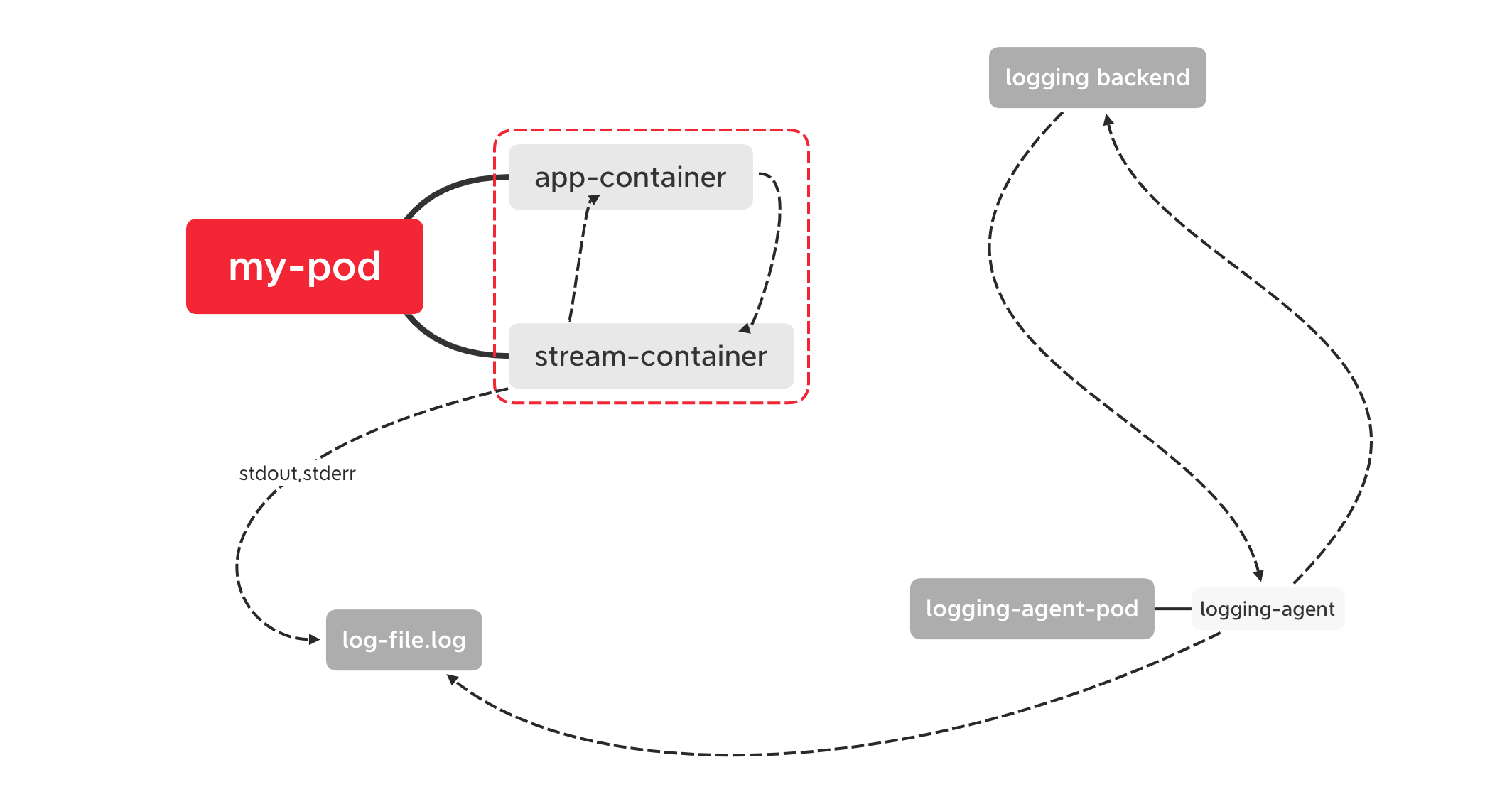
适用于应用容器只能把日志输出到文件,无法输出到stdout,stderr中的场景;
通过一个sidecar容器,直接读取日志文件,再重新输出到stdout,stderr中,
即可使用Node上通过日志代理转发的模式;
优缺点分析:
| 对比 | 说明 |
|---|---|
| 优点 | 只需耗费比较少的cpu和内存,共享volume处理效率比较高 |
| 缺点 | 宿主机上存在两份相同的日志,磁盘利用率不高 |
应用容器直接输出日志到日志服务
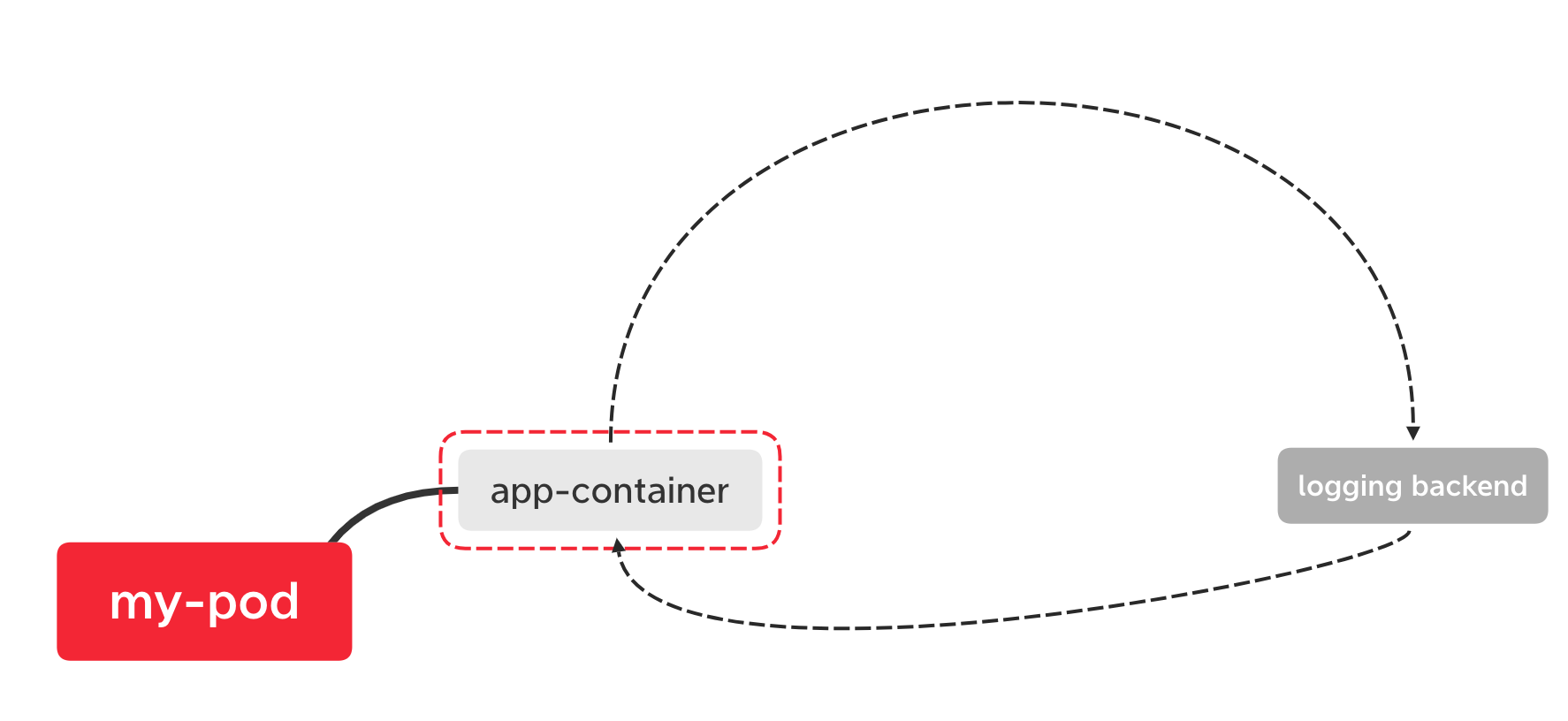
适用于有成熟日志系统的场景,日志不需要通过k8s;
EFK介绍
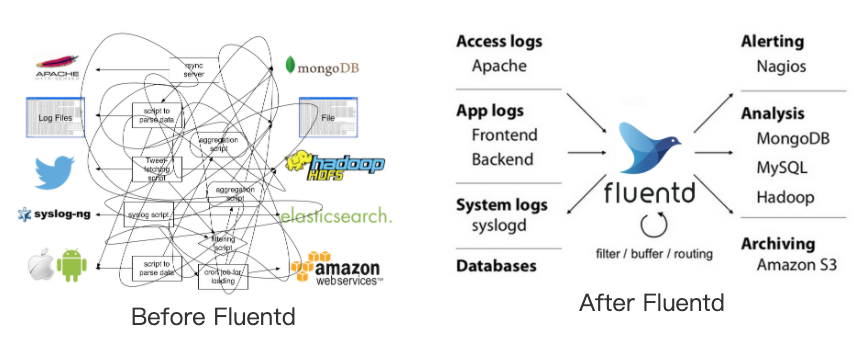
fluentd
fluentd是一个统一日志层的开源数据收集器。
flentd允许你统一日志收集并更好的使用和理解数据;

四大特征:
统一日志层
fluentd隔断数据源,从后台系统提供统一日志层;
简单灵活
提供了500多个插件,连接非常多的数据源和输出源,内核简单;
广泛验证
5000多家数据驱动公司以来Fluentd
最大的客户通过它收集5万多台服务器的日志
**云原生**
是云原生CNCF的成员项目
4大优势:
统一JSON日志

fluentd尝试采用JSON结构化数据,这就统一了所有处理日志数据的方面,收集,过滤,缓存,输出日志到多目的地,下行流数据处理使用Json更简单,因为它已经有足够的访问结构并保留了足够灵活的scemas;
插件化架构
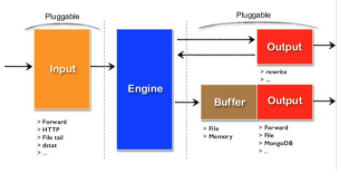
fluntd 有灵活的插件体系允许社区扩展功能,500多个社区贡献的插件连接了很多数据源和目的地; 通过插件,你可以开始更好的使用你的日志
最小资源消耗

c和ruby写的,需要极少的系统资源,40M左右的内存可以处理13k/时间/秒 ,如果你需要更紧凑的内存,可以使用Fluent bit ,更轻量的Fluentd
内核可靠
Fluentd支持内存和基于文件缓存,防止内部节点数据丢失;
也支持robust失败并且可以配置高可用模式, 2000多家数据驱动公司在不同的产品中依赖Fluentd,更好的使用和理解他们的日志数据
使用fluentd的原因:
简单灵活
10分钟即可在你的电脑上安装fluentd,你可以马上下载它,500多个插件打通数据源和目的地,插件也很好开发和部署;
开源
**基于Apache2.0证书 完全开源 **
可靠高性能
5000多个数据驱动公司的不同产品和服务依赖fluentd,更好的使用和理解数据,实际上,基于datadog的调查,是使用docker运行的排行top7的技术;
一些fluentd用户实时采集上千台机器的数据,每个实例只需要40M左右的内存,伸缩的时候,你可以节省很多内存
社区
fluentd可以改进软件并帮助其它人更好的使用
大公司使用背书: 微软 , 亚马逊; pptv ;


可以结合elasticSearch + kibana来一起组成日志套件;
快速搭建EFK集群并收集应用的日志,配置性能排行榜;
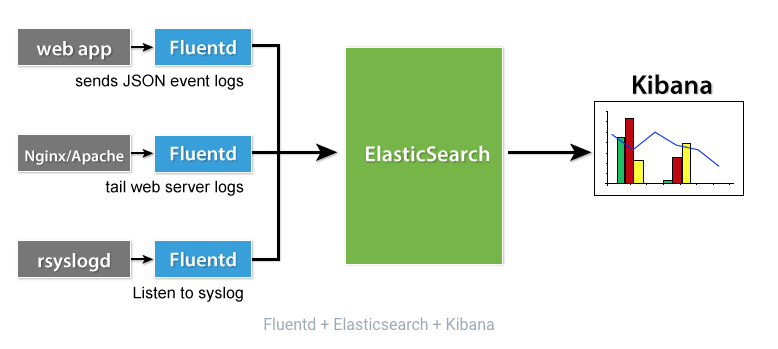
elasticsearch
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,
能够解决不断涌现出的各种用例。 作为 Elastic Stack 的核心,
它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
详细介绍:https://www.elastic.co/guide/cn/elasticsearch/guide/current/foreword_id.html
kibana
Kibana 是一款开源的数据分析和可视化平台,它是 Elastic Stack 成员之一,
设计用于和 Elasticsearch 协作。您可以使用 Kibana 对 Elasticsearch 索引中的数据进行搜索、
查看、交互操作。您可以很方便的利用图表、表格及地图对数据进行多元化的分析和呈现。
Kibana 可以使大数据通俗易懂。它很简单,
基于浏览器的界面便于您快速创建和分享动态数据仪表板来追踪 Elasticsearch 的实时数据变化.
详细介绍:https://www.elastic.co/guide/cn/kibana/current/introduction.html
容器化EFK实现路径
https://github.com/kayrus/elk-kubernetes
直接拖代码下来,然后配置后 context, namespace , 即可安装;
cd elk-kubernetes
./deploy.sh --watch
下面是deploy.sh的脚本,可以简单看一下:
#!/bin/sh
CDIR=$(cd `dirname "$0"` && pwd)
cd "$CDIR"
print_red() {
printf '%b' "\033[91m$1\033[0m\n"
}
print_green() {
printf '%b' "\033[92m$1\033[0m\n"
}
render_template() {
eval "echo \"$(cat "$1")\""
}
KUBECTL_PARAMS="--context=250091890580014312-cc3174dcd4fc14cf781b6fc422120ebd8"
NAMESPACE=${NAMESPACE:-sm}
KUBECTL="kubectl ${KUBECTL_PARAMS} --namespace=\"${NAMESPACE}\""
eval "kubectl ${KUBECTL_PARAMS} create namespace \"${NAMESPACE}\""
#NODES=$(eval "${KUBECTL} get nodes -l 'kubernetes.io/role!=master' -o go-template=\"{{range .items}}{{\\\$name := .metadata.name}}{{\\\$unschedulable := .spec.unschedulable}}{{range .status.conditions}}{{if eq .reason \\\"KubeletReady\\\"}}{{if eq .status \\\"True\\\"}}{{if not \\\$unschedulable}}{{\\\$name}}{{\\\"\\\\n\\\"}}{{end}}{{end}}{{end}}{{end}}{{end}}\"")
NODES=$(eval "${KUBECTL} get nodes -l 'sm.efk=data' -o go-template=\"{{range .items}}{{\\\$name := .metadata.name}}{{\\\$unschedulable := .spec.unschedulable}}{{range .status.conditions}}{{if eq .reason \\\"KubeletReady\\\"}}{{if eq .status \\\"True\\\"}}{{if not \\\$unschedulable}}{{\\\$name}}{{\\\"\\\\n\\\"}}{{end}}{{end}}{{end}}{{end}}{{end}}\"")
ES_DATA_REPLICAS=$(echo "$NODES" | wc -l)
if [ "$ES_DATA_REPLICAS" -lt 3 ]; then
print_red "Minimum amount of Elasticsearch data nodes is 3 (in case when you have 1 replica shard), you have ${ES_DATA_REPLICAS} worker nodes"
print_red "Won't deploy more than one Elasticsearch data pod per node exiting..."
exit 1
fi
print_green "Labeling nodes which will serve Elasticsearch data pods"
for node in $NODES; do
eval "${KUBECTL} label node ${node} elasticsearch.data=true --overwrite"
done
for yaml in *.yaml.tmpl; do
render_template "${yaml}" | eval "${KUBECTL} create -f -"
done
for yaml in *.yaml; do
eval "${KUBECTL} create -f \"${yaml}\""
done
eval "${KUBECTL} create configmap es-config --from-file=es-config --dry-run -o yaml" | eval "${KUBECTL} apply -f -"
eval "${KUBECTL} create configmap fluentd-config --from-file=docker/fluentd/td-agent.conf --dry-run -o yaml" | eval "${KUBECTL} apply -f -"
eval "${KUBECTL} create configmap kibana-config --from-file=kibana.yml --dry-run -o yaml" | eval "${KUBECTL} apply -f -"
eval "${KUBECTL} get pods $@"
简单分解一下部署的流程:
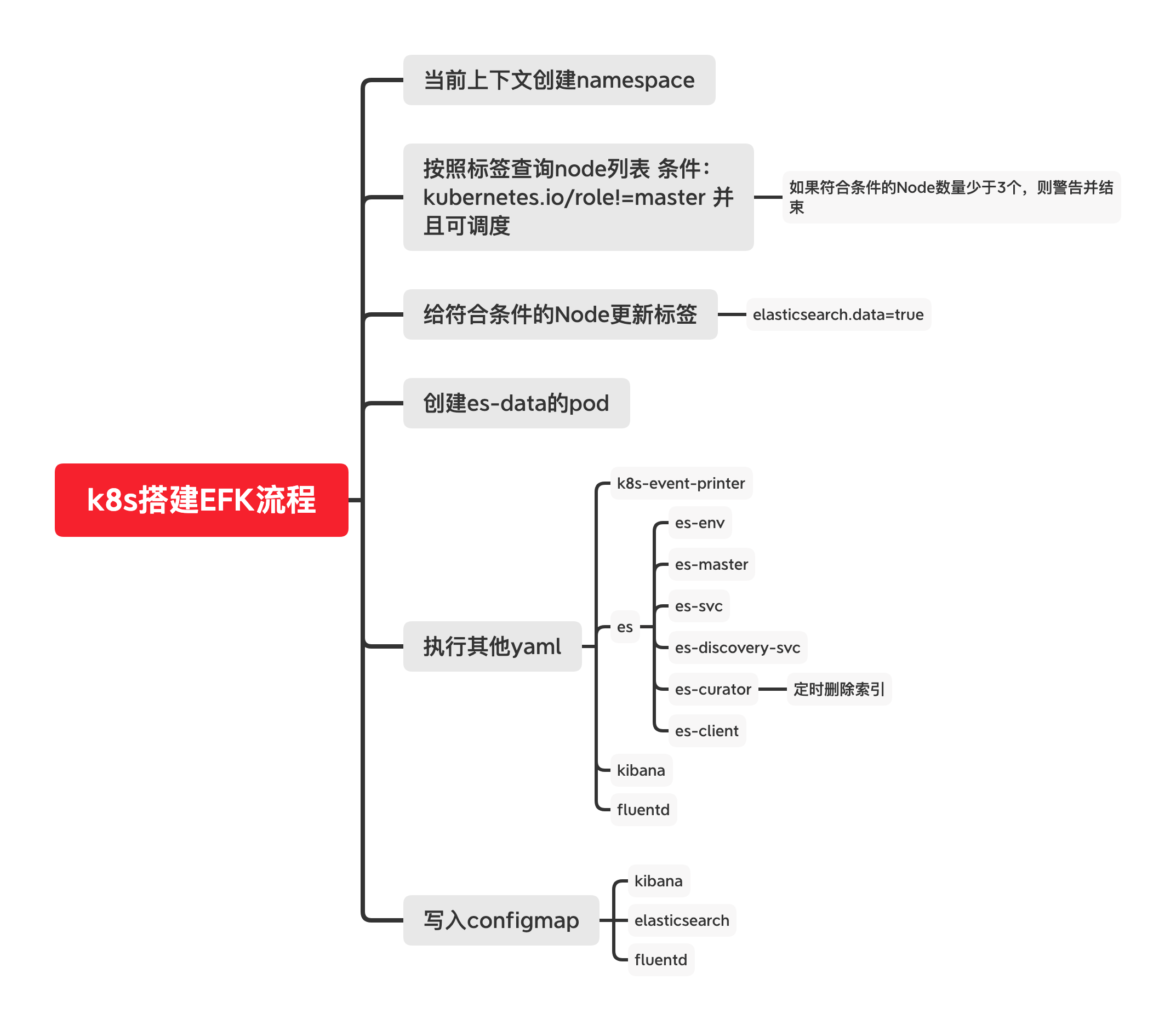
我的k8s环境中没有搭建成功,后续搭建成功了再出详细的安装笔记。
小结
一句话概括本篇:EFK是一种通过日志代理客户端采集应用日志比较常用的实现方式。
原创不易,关注诚可贵,转发价更高!转载请注明出处,让我们互通有无,共同进步,欢迎沟通交流。
云原生系列5 容器化日志之EFK的更多相关文章
- 8.云原生之Docker容器镜像构建最佳实践浅析
转载自:https://www.bilibili.com/read/cv15220861/?from=readlist 本章目录 0x02 Docker 镜像构建最佳实践浅析 1.Dockerfile ...
- 云原生系列2 部署你的第一个k8s应用
云原生的概念和理论体系非常的完备,but talk is cheap , show me the code ! 但是作为一名程序员,能动手的咱绝对不多BB,虽然talk并不cheap , 能跟不同层次 ...
- 云原生系列3 pod核心字段
pod是容器化的基础,好比大楼的地基. Pod跟容器的关系 类比一下: POD: 物理机容器: 物理机上的一个进程: 容器只是Pod的一个普通字段. Pod的作用范围 跟容器的linux namesp ...
- .NET Core/.NET5/.NET6 开源项目汇总6:框架与架构设计(DDD、云原生/微服务/容器/DevOps/CICD等)项目
系列目录 [已更新最新开发文章,点击查看详细] 开源项目是众多组织与个人分享的组件或项目,作者付出的心血我们是无法体会的,所以首先大家要心存感激.尊重.请严格遵守每个项目的开源协议后再使用.尊 ...
- 5.云原生之Docker容器网络介绍与实践
转载自:https://www.bilibili.com/read/cv15185166/?from=readlist 例如, 当在一台未经过特殊网络配置的centos 或 ubuntu机器上安装完d ...
- 2.云原生之Docker容器环境安装实践
转载自:https://www.bilibili.com/read/cv15181036/?from=readlist 官方一键安装脚本 补充时间:[2020年4月22日 11:00:59] 一键安装 ...
- 云原生系列1 pod基础
POD解决了什么问题? 成组资源调度问题的解决. mesos采用的资源囤积策略容易出现死锁和调度效率低下问题:google采用的乐观调度技术难度非常大: 而k8s使用pod优雅的解决了这个问题. po ...
- 云原生系列6 基于springcloud架构风格的本地debug实现
debug是程序员在日常开发中最常使用的操作, 那么,你是如何快速在微服务架构风格下快速debug后端服务呢? 开发现状 开发的理想状态 本地调测的使用步骤 登录智能网关 如果集成开发环境是在本地局域 ...
- 7.云原生之Docker容器Dockerfile镜像构建浅析与实践
转载自:https://www.bilibili.com/read/cv15220707/?from=readlist Dockerfile 镜像构建浅析与实践 描述:Dockerfile是一个文本格 ...
随机推荐
- SpringMVC听课笔记(六:视图和试图解析器)
1.spring mvc解析视图 2. 视图和视图解析器 3. 视图 4.常用的视图类 5.视图解析器 1) 2) 3) 4)JSTL 需要注意的是,配置了mvc:view-controller,为 ...
- hadoop(集群)完全分布式环境搭建
一,环境 主节点一台: ubuntu desktop 16.04 zhoujun 172.16.12.1 从节点(slave)两台:ubuntu server 16.04 hadoop2 ...
- Dotnet的局部函数和委托的对比
上一篇说了一下委托,这篇来说说局部函数和委托的对比. 把委托和局部函数放成前后篇,是因为这两个内容很像,用起来容易混. 需要了解委托相关内容,可以看这一篇 [传送门] 使用委托表达式(Lamb ...
- Word 脚本 (自用)
打开开发工具 右击功能区->自定义功能区 勾选开发工具->确定 导入代码 开发工具选项卡->Visual Basic 右击Normal->插入->模块 粘贴代码-> ...
- Codeforces Round #690 (Div. 3)
第一次 ak cf 的正式比赛,不正式的是寒假里 div4 的 Testing Round,好啦好啦不要问我为什么没有 ak div4 了,差一题差一题 =.= 不知不觉已经咕了一个月了2333. 比 ...
- The 2019 ICPC Asia Shanghai Regional Contest H Tree Partition k、Color Graph
H题意: 给你一个n个节点n-1条无向边构成的树,每一个节点有一个权值wi,你需要把这棵树划分成k个子树,每一个子树的权值是这棵子树上所有节点权值之和. 你要输出这k棵子树的权值中那个最大的.你需要让 ...
- HDU4787 GRE Words Revenge【AC自动机 分块】
HDU4787 GRE Words Revenge 题意: \(N\)次操作,每次记录一个\(01\)串或者查询一个\(01\)串能匹配多少个记录的串,强制在线 题解: 在线的AC自动机,利用分块来降 ...
- HDU - 2825 Wireless Password (AC自动机+状压DP)
题目连接:http://acm.hdu.edu.cn/showproblem.php?pid=2825 题意:给一些字符串,构造出长度为n的字符串,它至少包含k个所给字符串,求能构造出的个数. 题解: ...
- Strongly connected HDU - 4635 原图中在保证它不是强连通图最多添加几条边
1 //题意: 2 //给你一个有向图,如果这个图是一个强连通图那就直接输出-1 3 //否则,你就要找出来你最多能添加多少条边,在保证添加边之后的图依然不是一个强连通图的前提下 4 //然后输出你最 ...
- Codeforces Round #654 (Div. 2) B. Magical Calendar (结论)
题意:你需要在长度从\(1\)~\(k\),宽度无限的网格图中造图形(每个点四周必须连通),问最多能造出多少种不同的图形. 题解:感觉没什么好说的,就是画图找规律,如果\(r\ge n\)的话(即没有 ...