【总结】jvm
一.jvm体系结构
1.jvm整体结构
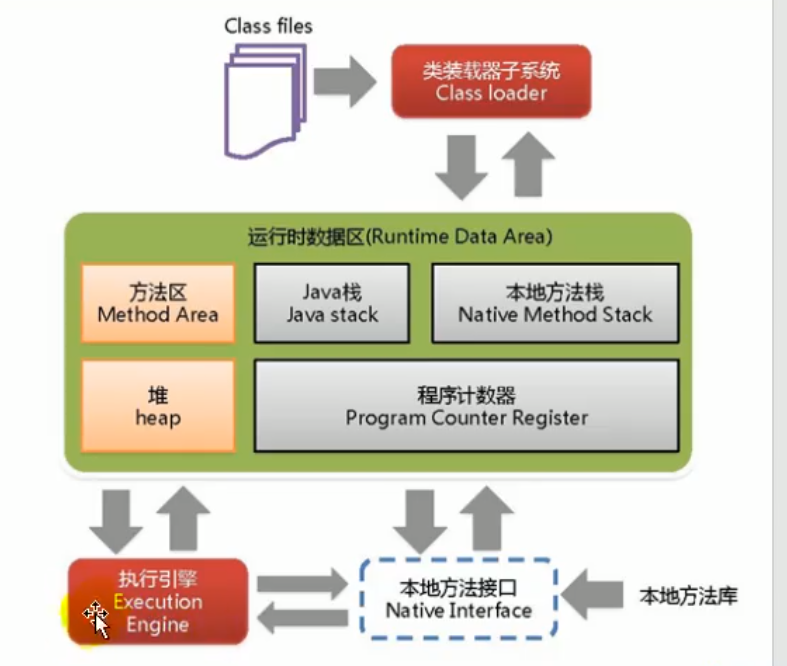
jvm总体上是由类装载子系统(ClassLoader)、运行时数据区、执行引擎三个部分组成。
(jvm本质上就是一个java进程)
2.jvm生命周期
(1)jvm启动:通过一个引导类加载器创建一个初始类来完成,这个类由虚拟机具体实现指定
(2)jvm运行:执行java程序
(3)jvm退出:①程序执行结束或遇到异常②某线程调用System或Runtime类的exit方法或Runtime的halt方法
3.jvm发展历程
(1)sun classic VM:世界上第一款商用虚拟机(jdk1.4时被完全淘汰)只有解释器,hotspot内置此虚拟机
(2)exact VM:JDK1.2引入,可以知道内存中某个位置的数据具体是什么类型(eg:不能判断某个数据是数值还是地址,要通过handler句柄去找,很麻烦)
(3)hotspot VM:jdk1.3称为默认虚拟机。具备热点代码探测技术(引入方法区的概念)
(4)Jrockit:专注于服务器端应用。不关注启动速度,因此不包含解析器实现,所有代码都靠即时编译器编译后执行
(5)J9:ibm公司,广泛应用与ibm的各种java产品
二.类加载子系统
1.作用
加载class文件,加载的类信息存放于方法区(除类信息外方法区还有运行时常量池,字符串字面量和数字常量)
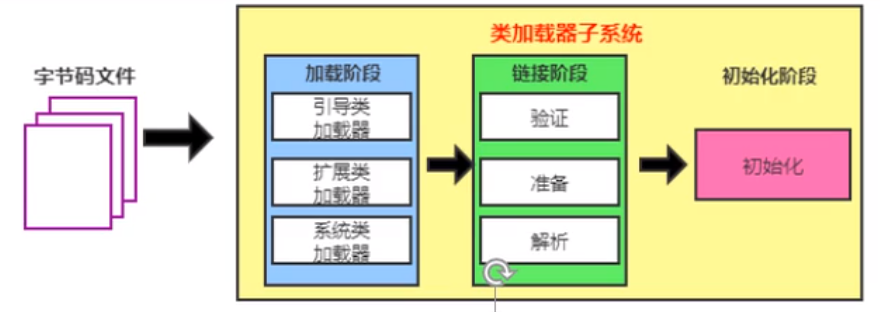
2.加载过程
1.加载:通过类的全限定名获取类的二进制字节流(从磁盘或网路加载类到内存),在方法区生成一个代表这个类的class对象
2.链接:
(1)验证:确保class文件包含的信息符合当前虚拟机的需求
(2)准备:为类变量分配内存(方法区),并设置默认初始值,即0(注意:不包含final修饰的static,因为在编译阶段就会初始化)
(3)解析:将常量池内符号引用转化为直接引用(加载类中用到的其它类如System)
3.初始化
类初始化阶段是类加载过程的最后一步,到了这个阶段才真正开始执行类中定义的Java程序代码(或者说是字节码)。在准备阶段,变量已经赋过一次系统要求的初始值,而在初始化阶段,则根据程序员通过程序制定的主观计划去初始化类变量和其他资源。
静态初始化——父类初始化——子类初始化
父类静态成员和static块-子类静态成员和static块
父类普通成员和非static块-父类构造函数
子类普通成员和非static块-子类构造函数
3.类加载器分类
(1)启动类加载器:使用c/c++实现,加载java的核心库(jre的lib下rt.jat)
(2)扩展类加载器:java编写,父加载器为启动类加载器(从jre/lib/ext下加载类库)
(3)应用类加载器:程序中默认的类加载器(加载classpath下的类库)
4.双亲委派机制
1.机制
(1)一个类加载器收到类加载请求,不会自己加载,而是交给父类的加载器去加载
(2)父类加载器还存在父加载器,进一步向上委托,直到达到顶层的启动类加载器
(3)父类加载器可以完成类加载,就成功返回。如果不能子类加载器才尝试加载
2.好处
(1)避免类重复加载,父classloader加载后没必要子classloader再加载
(2)安全保证,java核心api定义的类型不会被随意替换
三.运行时数据区
1.程序计数器
1.程序计数器作用:指向下一条指令的地址 线程私有(唯一一个再jvm中没有内存溢出的区域)
2.为什么需要?:cpu需要不停的切换各个线程,切换回来后需要知道从哪开始继续执行
2.虚拟机栈
1.概述
每个线程创建时都会创建一个虚拟机栈,内部保存着一个个栈帧,对应着方法的执行
2.设置栈内存大小
-Xss:设置线程最大的栈空间
3.栈帧
(1)局部变量表:主要用于存储方法参数和方法体内的局部变量(基本单位是slot(变量槽)32位以内占一个槽,64位占两个槽)
变量的分类:
成员变量:又分为类变量和实例变量(根据是否static修饰)
局部变量:方法内的变量
(2)操作数栈:在方法执行过程中,根据字节码指令往栈中写入或提取数据。即入栈/出栈
(3)动态链接:将符号引用转化为直接引用
每个栈帧内部包含一个指向运行时常量池中该栈帧所属方法的引用(可以理解为栈中保存的方法的地址,真正的方法结构是在方法区的运行时常量池中)
(4)方法返回地址:调用程序计数器的值作为返回地址。即调用吓一条指令的地址
3.本地方法栈
作用:用于管理本地方法(native)的调用
4.堆
1.概述
所有的对象和数组都应当在运行时分配在堆上 。
2.堆的内存细分
java8前,新生区(Eden和Survivor)+老年区+永久区
java8后,新生区(Eden和Survivor)+老年区+元空间
3.堆空间大小设置
(1)
-Xms:表示堆区的起始内存
-Xmx:表示堆区的最大内存(超出OOM)
(通常两个参数值相等,避免了gc后频繁的调整堆内存大小)
(2)默认初始大小:电脑内存/64
,最大内存大小 电脑内存/4
(3)查看设置的方式
方式一:
jps (查看java进程)
jstat -gc 进程id (显示gc相关的堆信息)
方式二:
-XX:+PrintGCDetails
4.年轻代与老年代
(1)参数配置
①默认-XX:NewRatio 新生代占1,老年代占2
②默认-XX:SurvivorRatio=8 Eden和两个survivor-1:8:8
5. 对象分配一般过程
1.new的对象先放到Eden,此区有大小限制
2.当Eden满时,会进行young gc(stop the world),将Eden死亡的对象销毁,加载新的对象进eden
3.将Eden剩余的对象放到survivor0
4.再次gc时,会将eden和survivor0存活的对象放到survivor1
5.当对象的年龄超过一定次数(默认15)进入老年区
(-XX:MaxTenuringThreshold=15)
6.对象分配的特殊情况
1.对象过大,Eden区放不下,直接放到老年代 (老年代也放不下进行old gc)
2.从eden放survivor的对象放不下,直接放老年代
7.yong gc ,old gc, full gc?
1.yong gc:只是新生代的垃圾收集(eden,s0,s1)(stw)
2.old gc:针对老年代的收集(stw)
(stw原因:避免垃圾回收的时候用户线程再产生垃圾)
3.full gc:针对整个堆和方法区的垃圾收集
full gc出发机制:①调用System.gc() ②老年代空间不足 ③方法区空间不足
5.方法区
1.概述
和堆一样,线程共享。存储 类信息,常量,静态变量,编译后的代码。实现方式是永久代(1.8之前)和元空间(1.8之后)(非堆)
2.永久代和元空间的区别?
1.永久代使用jvm内存,元空间使用本地内存
2.运行时常量池从永久代放入堆中
3.参数设置
1.8之前:
-XX:permsize 设置永久代初始空间
-xx:maxpermsize 永久代最大空间
1.8之后:
-xx:metaspacesize 默认元空间大小
-xx:maxmetaspacesize 最大元空间大小
4.常量池和运行时常量池
字节码文件,内部包含了常量池
方法区,内部包含了运行时常量池
1.常量池
一个java源文件中的类,接口编译产生字节码文件。代码中可能用到system,print等结构。如果把他们所有的信息都存在这个class文件,那文件就会非常大。所以把他们标识存到常量池。所以它可以看作一个表,虚拟机指令根据这张表找到曜执行的类,方法等。
2.运行时常量池
类加载后会将常量池中的内容加载到方法区的运行时常量池中
5.jdk6 7 8 方法区的演进?
jdk1.6:有永久代,静态变量存放在永久代
jdk1.7:有永久代,字符串常量池,静态变量保存在堆
jdk1.8:永久代变元空间。类信息,常量保存在元空间。字符串常量池,静态变量仍在堆
6.jdk1.7后字符串常量池为什么放到堆中?
永久代回收效率很低,在full gc的时候才会触发。而full gc是老年代空间不足,永久代不足时才会触发。这就导致字符串常量池回收效率不高。开发过程我们会创建大量的字符串。所以放到堆里能及时回收
6.对象的实例化
1.对象创建的方式
1.new
2.Class的newInstance()
3.Constructor的newInstance方法
4.clone() 不调用任何构造器,当前类实现cloneable接口,实现clone方法
5.使用反序列化
2.创建对象的步骤
1.判断对象对应的类是否加载,连接,初始化
2.为对象分配内存
(1)如果内存规整,虚拟机采用指针碰撞来分配内存。所有用过的内存放在一边,空闲的内存放在另一边。中间放着一个指针作为分界点指示器,分配内存就仅仅把指针空闲那一边挪动一段与对象大小相等的距离
(2)如果内存不规整,虚拟机采用空闲列表法来分配内存。列表上记录哪些块是可用的,在分配的时候从列表找到一块足够大的空间分配给列表实例
3.处理并发安全问题。采用cas失败重试,区域加锁保证更新的原子性
4.初始化属性值
5.设置对象的对象头
6.执行init进行初始化(显示初始化)
7.string
1.string的不可变性
字符串创建后就不可改变,即使对它进行拼接等操作也是在新的字符串的基础上做的
2.string创建的位置
通过字面量给字符串赋值,此时字符串值声明在字符串常量池。(字符串常量池不会存储相同的字符串——底层使用map)
(1)String str1= “abc”; 在编译期,JVM会去常量池来查找是否存在“abc”,如果不存在,就在常量池中开辟一个空间来存储“abc”;如果存在,就不用新开辟空间。然后在栈内存中开辟一个名字为str1的空间,来存储“abc”在常量池中的地址值。
(2)String str2 = new String("abc") ;在编译阶段JVM先去常量池中查找是否存在“abc”,如果过不存在,则在常量池中开辟一个空间存储“abc”。在运行时期,通过String类的构造器在堆内存中new了一个空间,然后将String池中的“abc”复制一份存放到该堆空间中,在栈中开辟名字为str2的空间,存放堆中new出来的这个String对象的地址值。
3.string拼接操作
1.常量与常量的拼接结果在常量池,原理是编译期优化
String s1 = "a" + "b" + "c";
String s2 = "abc"
s1 == s2 //true
2.常量池中不会存在相同内容的常量
3.只要有一个是变量,结果就在堆中(相当于new String)。变量拼接的原理是stringBuilder
String s1 = "a";
String s2 ="b";
String s3 = "a" + s2;
String s4 = s1 + s2;
String s5 = "a" + "b"
s3 == s4 //false
s4 == s5 //false
String s6 = s3.intern()
s6 == s5 //true
4.拼接结果调用intern()方法,则主动将常量池中还没有的对象放入池中。并返回此对象地址(常量池中的地址)
4.拼接操作与append效率对比?
(1)
String s = "";
Random r = new Random();
for (int i = 0;i < 10;i++) {
s = s + r.nextInt(1000) + " ";
}
(2)
String s = "";
StringBuilder sb = new StringBuilder();
for(int i = 0; i < 10; i++){
sb.append(" ");
}
变量的字符串拼接,底层调用的是stringBuilder的append方法。在for循环中这样拼接的话每次都创建一个stringBuilder对象
5.new string创建对象的个数?
1.new string("ab");会创建几个对象?
两个,堆空间+字符串常量池
2.new String("a") + new String("b")创建几个对象?
(1)StringBuilder
(2)new string("a")
(3)常量池中的"a"
(4)new string("b")
(5)常量池中的"b"
四.执行引擎
1.执行引擎概述
将字节码指令解释/编译(注意区分和前面java的编译)为对应平台上的本地机器指令
2.解释器和编译器
1.解释器:对字节码采用逐行解释的方式执行,将字节码指令解释为本地本地机器指令
2.编译器:将Java编译为class代码
五.对象存活判断(标记阶段)
1.引用计数算法
1.概述
每个对象关联一个引用计数器属性,任何一个对象引用了A,引用计数器的值加1.当引用失效时,引用计数器就减1.当引用计数器的值为0时,表示对象不再被使用,可进行回收
2.缺点
1.需要单独的字段存储计数器,这样增加了存储空间的开销
2.每次赋值都要更新计数器值,增加了时间开销
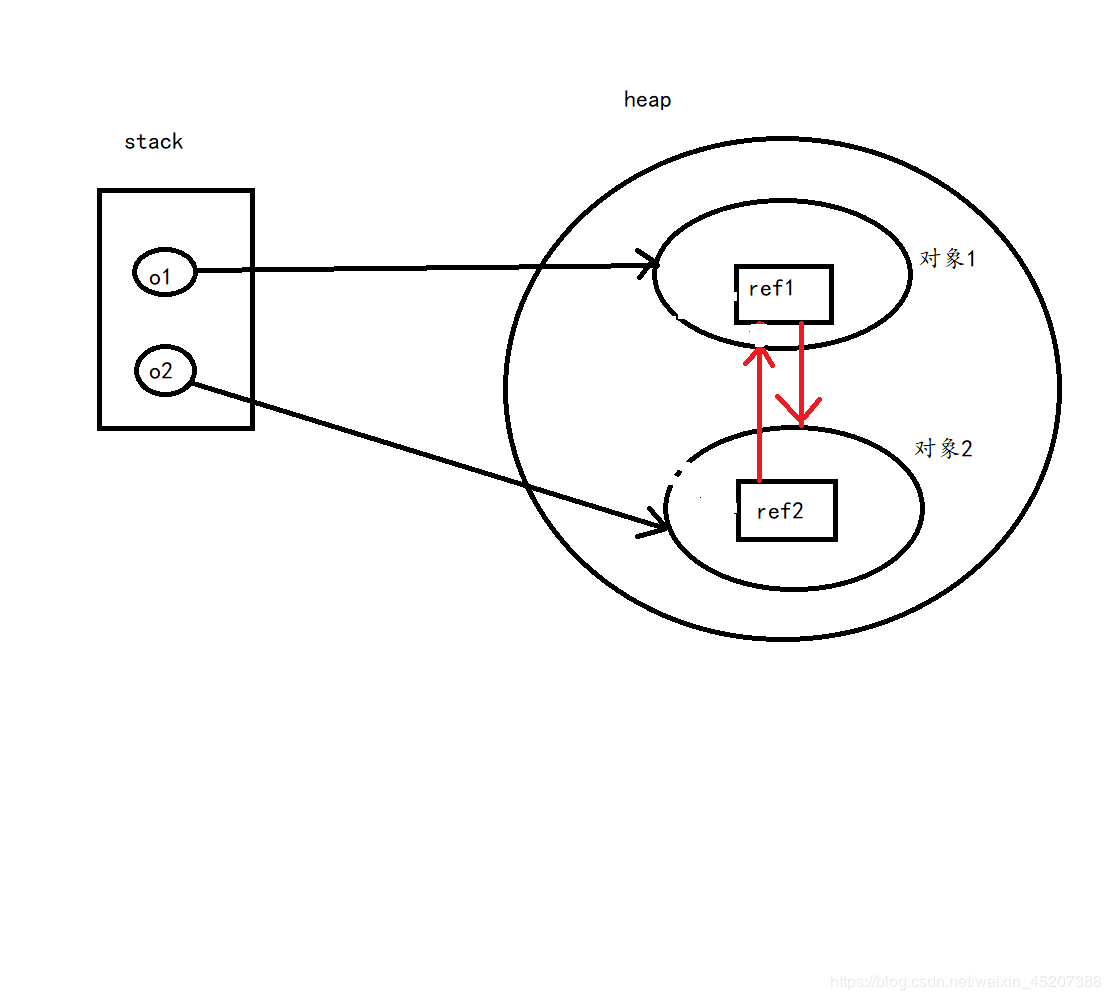
3.存在循环引用的问题(所以jvm不用)
`
public class TestClass {
private Object ref;
public static void main(String[] args) {
TestClass o1 = new TestClass(); // 1
TestClass o2 = new TestClass(); // 2
o1.ref = o2; // 3
o2.ref = o1; // 4
o1 = null; // 5
o2 = null; // 6
}
}
`
2.可达性分析法
1.概念
设立若干根对象,当任何一个根对象到某一个对象均不可达时,认为这个对象可以被回收
2.哪些可以作为gc roots?
1.虚拟机栈(栈帧中的本地变量表)中引用的对象;
2.本地方法栈中JNI(即一般说的Native方法)中引用的对象
3.方法区中的类静态属性引用的对象;
4.方法区中常量引用的对象;
(GC Root Object可以从Java堆的外部访问,也就是不受GC的自动回收管制。可以理解为有免死金牌的Java对象)
六.垃圾清除算法(清除阶段)
1.标记-清除算法
1.概述
标记-清除算法:通过根节点,标记所有根节点开始的可达对象,清除未被标记对象(会产生内存碎片)
2.缺点
1.stop the world,gc的时候停止整个应用程序
2.产生碎片,需要维护一个空闲列表(记录垃圾所在的位置,新对象到时可以直接覆盖该区域)
3.效率不高(进行了两次O(N)的遍历)
2.复制算法(新生代默认)
1.概述
将内存分为一块较大的Eden和两块较小的survivor,每次使用Eden和其中一块survivor。Gc时将标记的对象复制到另一块survivor
1.优点
1.没有标记和清除的过程,运行高效
2.复制过去以后保证空间的连续性,不会有碎片产生
2.缺点
浪费内存空间,始终要有一个空闲的survivor
3.标记-整理算法
1.概述
将标记的对象移动到内存的一端,清除边界外的所有空间(解决了碎片问题)
4.三种算法的对比
速度:复制>标记清除>标记整理
5.分代收集算法
目前几乎所有的gc采用分代收集算法进行垃圾回收
年轻代:复制算法
老年代:标记清除与标记整理混合
七.垃圾收集器
新生代收集器:
serial
pranew
parallel scavenge
老年代收集器:
serial old
parallel old
cms
整堆收集器:
G1
1.serial
新生代单线程收集器
采用复制算法
stw
2.pranew
新生代并行收集器
采用复制算法
stw
3.parallel scavenge
并行收集器,追求高吞吐(代码运行时间/(代码运行时间+垃圾收集时间))
采用复制算法
stw
4.serial old
serial的老年代版本
采用标记整理算法
一般是作为CMS收集器的后备预案,在并发收集发生concurrent mode failure时使用
(concurrent mode failure是在执行CMS GC(并发标记/清除)的过程中同时有对象要放入老年代,而此时老年代空间不足造成的,此时要进行full gc)
5.parallel old
parallel scavenge的老年代版本
6.cms
以获得最短停顿时间为目的的收集器
标记-清除
收集步骤:
(1)初始标记:仅标记gc root直接关联的对象
(2)并发标记:标记所有gc root关联的对象
(3)重新标记:标记并发阶段发生变化的对象
(4)并发清除:回收所有的垃圾对象
缺点:
(1)cms无法处理浮动垃圾(并发gc过程中用户线程产生的垃圾)导致,concurrent mode failure,从而产生full gc
(2)基于标记-清除,产生大量碎片
7.G1
新生代和老年代收集器,把堆内存划分为不同的region。来代替eden,s0,s1,老年代等。跟踪各个region的垃圾价值(垃圾的数量和垃圾收集的时间)。维护一个优先级列表,优先收集价值最大的region。避免了堆中全区域的垃圾收集
采用标记-整理 算法
jdk1.7后全新的回收器,用于取代cms收集器
收集步骤:
(1)初始标记:仅标记gc root直接关联的对象
(2)并发标记:标记所有gc root关联的对象
(3)重新标记:标记并发阶段发生变化的对象
(4)筛选回收:根据优先级,对region进行回收
【总结】jvm的更多相关文章
- 46张PPT讲述JVM体系结构、GC算法和调优
本PPT从JVM体系结构概述.GC算法.Hotspot内存管理.Hotspot垃圾回收器.调优和监控工具六大方面进行讲述.(内嵌iframe,建议使用电脑浏览) 好东西当然要分享,PPT已上传可供下载 ...
- java 利用ManagementFactory获取jvm,os的一些信息--转
原文地址:http://blog.csdn.net/dream_broken/article/details/49759043 想了解下某个Java项目的运行时jvm的情况,可以使用一些监控工具,比如 ...
- Jvm 内存浅析 及 GC个人学习总结
从诞生至今,20多年过去,Java至今仍是使用最为广泛的语言.这仰赖于Java提供的各种技术和特性,让开发人员能优雅的编写高效的程序.今天我们就来说说Java的一项基本但非常重要的技术内存管理 了解C ...
- JVM类加载
JVM的类加载机制就是:JVM把描述类的class文件加载到内存,并对数据进行校验.转换解析和初始化,最终形成可以被JVM直接使用的Java类型 ClassLoader JVM中的ClassLoade ...
- Java虚拟机 JVM
finalize();(不建议使用,代价高,不确定性大) 如果你在一个类中覆写了finalize()方法, 那么你可以在第一次被GC的时候,挽救一个你想挽救的对象,让其不被回收,但只能挽救一次. GC ...
- 在 Linux 中安装 Oracle JDK 8 以及 JVM 的类加载机制
参考资料 该文中的内容来源于 Oracle 的官方文档 Java SE Tools Reference .Oracle 在 Java 方面的文档是非常完善的.对 Java 8 感兴趣的朋友,可以直接找 ...
- MapReduce剖析笔记之六:TaskTracker初始化任务并启动JVM过程
在上面一节我们分析了JobTracker调用JobQueueTaskScheduler进行任务分配,JobQueueTaskScheduler又调用JobInProgress按照一定顺序查找任务的流程 ...
- java太low,又舍不得jvm平台的丰富资源?试试kotlin吧(一)
尝试kotlin的起因 因为各种原因(版权,人员招聘),公司的技术体系从c#转到了java,我花了大概两周的时间来上手java,发现java的语法还是非常简单的,基本看着代码就知道什么意思.学习jav ...
- Jvm --- 常用工具
jps:虚拟机进程状况工具 JVM Process Status Tool. 可以列出所有目前正在运行虚拟机的进程. jps -l 详细参数: -q 输出LVMID,省略主类名称 -m 输出虚拟机进程 ...
- JVM虚拟机结构
JVM的主要结构如下图所示,图片引用自舒の随想日记. 方法区和堆由所有线程共享,其他区域都是线程私有的 程序计数器(Program Counter Register) 类似于PC寄存器,是一块较小的内 ...
随机推荐
- burp suite 之 Scanner(漏洞扫描)
Scanner选项:是一个进行自动发现 web 应用程序的安全漏洞的工具. 将抓取的包 通过选项卡发送至 Scanner下的Scan queue 首先来介绍 Scanner 下的 lssue acti ...
- 使用redis来调用iptables,封禁恶意IP
话不多说,通常大多数站点都会有被薅羊毛的情况,防护无非也就是业务层做处理,短时内不再响应恶意请求啦.虽然不响应了,可还是会消耗资源的,比如我要从数据库(当然也可能是内存数据库)去查询下,你是不是恶意的 ...
- Redis 作者 Antirez 与 Contributor Mattsta 之间关于 CRC 的 Battle
大家好,我是 yes. 昨天表弟说有个学妹问他 Redis 为什么要用 CRC16(key) mod 16384 来计算 key 所处槽的位置,我想这 CRC 一般都是用来校验的,通过多项式转换成二进 ...
- CLP(FD)有限域上的约束逻辑式编程
译自http://www.pathwayslms.com/swipltuts/clpfd/clpfd.html#_simple_constraints,SWI-Prolog官网所推荐的进阶教程.目前还 ...
- 【学习笔记】Polya定理
笔者经多番周折终于看懂了\(\text{Burnside}\)定理和\(\text{Polya}\)定理,特来写一篇学习笔记来记录一下. 群定义 定义:群\((G,·)\)是一个集合与一个运算·所定义 ...
- Apache账户密码加密方式介绍
一.apache密码存储格式 apache的用户密码一般会生成保存在.htpasswd文件中,保存路径由用户创建时确定,根据使用加密算法有五种保存格式: [注]:如果用户指定了保存密码的文件名,视用户 ...
- Java 客户端操作 FastDFS 实现文件上传下载替换删除
FastDFS 的作者余庆先生已经为我们开发好了 Java 对应的 SDK.这里需要解释一下:作者余庆并没有及时更新最新的 Java SDK 至 Maven 中央仓库,目前中央仓库最新版仍旧是 1.2 ...
- Docker镜像仓库Harbor部署
一.Harbor组件 组件 功能 harbor-adminserver 配置管理中心 harbor-db Mysql数据库 harbor-jobservice 负责镜像复制 harbor-log 记录 ...
- win10 home安装docker快速攻略
本文适用于win10 Home用户,专业版和企业版直接见官网.win7版本见Docker Toolbox. 安装清单 软件 说明 Docker Desktop Installer 步骤介绍页:http ...
- CMD/ENTROYPOINT区别
CMD/ENTROYPOINT区别 相同点:都是指定一个容器:启动时要运行的命令 不同点(重点): CMD: dockerfile中可以有多个CMD指令,但是只有最后一个生效,CMD会被docker ...