Parquet 列式存储格式
Parquet 列式存储格式
参考文章:
https://blog.csdn.net/kangkangwanwan/article/details/78656940
http://parquet.apache.org/documentation/latest/
列式存储的优势
- 把IO只给查询需要用到的数据,只加载需要被计算的列
- 列式的压缩效果更好,节省空间
parquet只是一种存储格式,与上层语言无关
适配通用性
存储空间优化
计算时间优化
hive中metastore和数据是分开的,alter table只修改metastore,不会立即把数据进行转换,因此查询时可能出现转换失败的错误,parquet的schema也不会改变
词汇表
block:hdfs block
file:hdfs 文件,必须包含file metadata,不是一定包含实际数据
row group:多个column chunk组成,每个chunk标识row中的一列
column chunk:大量的数据集,针对某一列
page:chunk被分成多页,每一个页是一个压缩编码的单位,一个chunk可能多有个页
File Format
4-byte magic number "PAR1"
<Column 1 Chunk 1 + Column Metadata>
<Column 2 Chunk 1 + Column Metadata>
...
<Column N Chunk 1 + Column Metadata>
<Column 1 Chunk 2 + Column Metadata>
<Column 2 Chunk 2 + Column Metadata>
...
<Column N Chunk 2 + Column Metadata>
...
<Column 1 Chunk M + Column Metadata>
<Column 2 Chunk M + Column Metadata>
...
<Column N Chunk M + Column Metadata>
File Metadata
4-byte length in bytes of file metadata
4-byte magic number "PAR1"

Metadata is written after the data to allow for single pass writing.
Readers are expected to first read the file metadata to find all the column chunks they are interested in. The columns chunks should then be read sequentially.
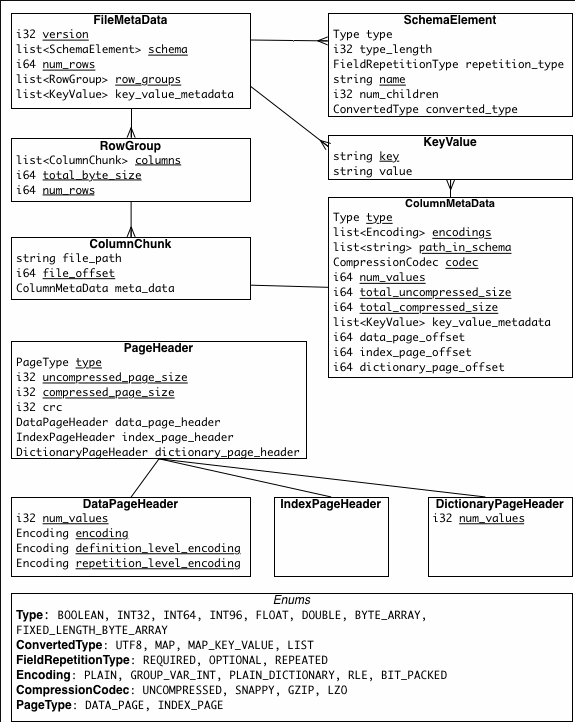
数据模型
message AddressBook {
required string owner; //required(出现1次)
repeated string ownerPhoneNumbers; //repeated(出现0次或者多次)
repeated group contacts { //Parquet格式没有复杂的Map, List,Set等而是使用repeated fields和groups来表示
required string name;
optional string phoneNumber; //optional(出现0次或者1次)
}
}
type可以是一个group或者一个primitive类型
一个schema有几个叶子节点就有多少列
[ AddressBook ]
/ | \
/ | \
required repeated repeated
owner ownerPhoneNumbers contacts
/ \
required optional
name phoneNumber
此处有4列
owner:string
ownerPhoneNumbers:string
contacts.name:string
contacts.phoneNumber:string
分段/组装算法
Definition Level
从根节点开始遍历,当某一个field的路径上的节点为空的时候,我们记录下当前深度作为这个field的Definition Level
最大Definition level:根据schema推算出来的,field路径都不为空时的Definition level
如果current definition level == max definition level ,则表示这个field是有数据的
Repetition level
记录该field的值是在哪一个深度上重复的。只有repeated类型的field需要Repetition Level,optional 和 required类型的不需要。Repetition Level = 0 表示开始一个新的record
如何存储
Parquet文件
所有数据水平切分成Row group:包含对应区间内的所有列的column chunk
column chunk:负责存储某一列的数据,由1个或多个Page组成
Page:压缩和编码的单元,对数据模型是透明的
Parquet文件尾部:Footer:文件的元数据信息和统计信息
推荐
row group size:一般情况下推荐配置一个Row group大小1G,一个HDFS块大小1G,一个HDFS文件只含有一个块,最大化顺序IO的性能优势
data page size:recommend 8KB for page sizes.小的page size有更好的读取性能,如单行查找时;大的page size带来少的空间成本和潜在的解析成本降低,因为page header变少了。Note:顺序扫描,不要去希望一次读完整个page,这不是IO意义上的数据块
疑问
多个列如何对应到同一行的
hbase存在列数据分布不均问题,即1列数据非常多,另一列数据非常少,导致有很多无用的block,推测parquet也存在这个问题,如果存在,那么会有很多空数据列来标识不存在的数据
org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat
MapredParquetOutputFormat将对象写入parquet文件,通过它,我们来追踪这些疑问,方法getHiveRecordWriter返回一个写入记录的对象用于最终将对象的多个fields写到文件中
/**
*
* Create the parquet schema from the hive schema, and return the RecordWriterWrapper which
* contains the real output format
*/
@Override
public org.apache.hadoop.hive.ql.exec.FileSinkOperator.RecordWriter getHiveRecordWriter(
final JobConf jobConf,
final Path finalOutPath,
final Class<? extends Writable> valueClass,
final boolean isCompressed,
final Properties tableProperties,
final Progressable progress) throws IOException {
LOG.info("creating new record writer..." + this);
final String columnNameProperty = tableProperties.getProperty(IOConstants.COLUMNS);
final String columnTypeProperty = tableProperties.getProperty(IOConstants.COLUMNS_TYPES);
List<String> columnNames;
List<TypeInfo> columnTypes;
if (columnNameProperty.length() == 0) {
columnNames = new ArrayList<String>();
} else {
columnNames = Arrays.asList(columnNameProperty.split(","));
}
if (columnTypeProperty.length() == 0) {
columnTypes = new ArrayList<TypeInfo>();
} else {
columnTypes = TypeInfoUtils.getTypeInfosFromTypeString(columnTypeProperty);
}
//根据列名和类型,生成schema
DataWritableWriteSupport.setSchema(HiveSchemaConverter.convert(columnNames, columnTypes), jobConf);
//类的构造方法生成 realOutputFormat = new ParquetOutputFormat<ParquetHiveRecord>(new DataWritableWriteSupport());
return getParquerRecordWriterWrapper(realOutputFormat, jobConf, finalOutPath.toString(),
progress,tableProperties);
}
protected ParquetRecordWriterWrapper getParquerRecordWriterWrapper(
ParquetOutputFormat<ParquetHiveRecord> realOutputFormat,
JobConf jobConf,
String finalOutPath,
Progressable progress,
Properties tableProperties
) throws IOException {
return new ParquetRecordWriterWrapper(realOutputFormat, jobConf, finalOutPath.toString(),
progress,tableProperties);
}
ParquetRecordWriterWrapper是RecordWriter包装类
public ParquetRecordWriterWrapper(
final OutputFormat<Void, ParquetHiveRecord> realOutputFormat,
final JobConf jobConf,
final String name, //finalOutPath
final Progressable progress, Properties tableProperties) throws
IOException {
try {
// create a TaskInputOutputContext
TaskAttemptID taskAttemptID = TaskAttemptID.forName(jobConf.get("mapred.task.id"));
if (taskAttemptID == null) {
taskAttemptID = new TaskAttemptID();
}
taskContext = ContextUtil.newTaskAttemptContext(jobConf, taskAttemptID);
//从tableProperties初始化blockSize,ENABLE_DICTIONARY,COMPRESSION,如果tableProperties没有对应属性,则什么都不做
LOG.info("initialize serde with table properties.");
initializeSerProperties(taskContext, tableProperties);
LOG.info("creating real writer to write at " + name);
//真正的writer
realWriter =
((ParquetOutputFormat) realOutputFormat).getRecordWriter(taskContext, new Path(name));
LOG.info("real writer: " + realWriter);
} catch (final InterruptedException e) {
throw new IOException(e);
}
}
疑问
blockSize是什么
进入ParquetRecordWriterWrapper.getRecordWriter来看realWriter生成方式
public RecordWriter<Void, T> getRecordWriter(Configuration conf, Path file, CompressionCodecName codec) throws IOException, InterruptedException {
WriteSupport<T> writeSupport = this.getWriteSupport(conf); //writeSupport是一个关键的东西 ,读取配置中的parquet.write.support.class,反射生成实例
CodecFactory codecFactory = new CodecFactory(conf);
long blockSize = getLongBlockSize(conf);
int pageSize = getPageSize(conf);
int dictionaryPageSize = getDictionaryPageSize(conf);
boolean enableDictionary = getEnableDictionary(conf);
boolean validating = getValidation(conf);
WriterVersion writerVersion = getWriterVersion(conf);
//通过conf.schema生成写入上下文
WriteContext init = writeSupport.init(conf);
//使用finalOutPath
ParquetFileWriter w = new ParquetFileWriter(conf, init.getSchema(), file);
w.start();
float maxLoad = conf.getFloat("parquet.memory.pool.ratio", 0.95F);
long minAllocation = conf.getLong("parquet.memory.min.chunk.size", 1048576L);
if (memoryManager == null) {
memoryManager = new MemoryManager(maxLoad, minAllocation);
} else if (memoryManager.getMemoryPoolRatio() != maxLoad) {
LOG.warn("The configuration parquet.memory.pool.ratio has been set. It should not be reset by the new value: " + maxLoad);
}
//realWriter
return new ParquetRecordWriter(w, writeSupport, init.getSchema(), init.getExtraMetaData(), blockSize, pageSize, codecFactory.getCompressor(codec, pageSize), dictionaryPageSize, enableDictionary, validating, writerVersion, memoryManager);
}
ParquetFileWriter,执行FS中的file
public ParquetFileWriter(Configuration configuration, MessageType schema, Path file, ParquetFileWriter.Mode mode) throws IOException {
this.blocks = new ArrayList();
this.state = ParquetFileWriter.STATE.NOT_STARTED; //writer初始状态
this.schema = schema;
FileSystem fs = file.getFileSystem(configuration);
boolean overwriteFlag = mode == ParquetFileWriter.Mode.OVERWRITE;
this.out = fs.create(file, overwriteFlag); //生成FSDataOutputStream,指定文件为file
}
真,最终 ParquetRecordWriter
public ParquetRecordWriter(ParquetFileWriter w, WriteSupport<T> writeSupport, MessageType schema, Map<String, String> extraMetaData, long blockSize, int pageSize, BytesCompressor compressor, int dictionaryPageSize, boolean enableDictionary, boolean validating, WriterVersion writerVersion, MemoryManager memoryManager) {
this.internalWriter = new InternalParquetRecordWriter(w, writeSupport, schema, extraMetaData, blockSize, pageSize, compressor, dictionaryPageSize, enableDictionary, validating, writerVersion);
this.memoryManager = (MemoryManager)Preconditions.checkNotNull(memoryManager, "memoryManager");
memoryManager.addWriter(this.internalWriter, blockSize);
}
ParquetRecordWriterWrapper写入一条记录,对应row级别
@Override
public void write(final Void key, final ParquetHiveRecord value) throws IOException {
try {
realWriter.write(key, value);
} catch (final InterruptedException e) {
throw new IOException(e);
}
}
调用到ParquetRecordWriter.write方法,最终指向InternalParquetRecordWriter.write
public void write(Void key, T value) throws IOException, InterruptedException {
this.internalWriter.write(value);
}
public void write(T value) throws IOException, InterruptedException {
this.writeSupport.write(value);
++this.recordCount;
this.checkBlockSizeReached();
}
既然writeSuppot是反射生成的,我们使用 GroupWriteSupport 来继续走完代码(spark自己写了一个WriteSupport:ParquetWriteSupport)
public void prepareForWrite(RecordConsumer recordConsumer) {
this.groupWriter = new GroupWriter(recordConsumer, this.schema);
}
public void write(Group record) {
this.groupWriter.write(record);
}
public class GroupWriter {
private final RecordConsumer recordConsumer;
private final GroupType schema;
public GroupWriter(RecordConsumer recordConsumer, GroupType schema) {
this.recordConsumer = recordConsumer; //MessageColumnIORecordConsumer类
this.schema = schema;
}
public void write(Group group) {
//标记record开始,预准备一些标识
this.recordConsumer.startMessage();
//写入row
this.writeGroup(group, this.schema);
//标记record结束,处理写完数据后的标识操作
this.recordConsumer.endMessage();
}
private void writeGroup(Group group, GroupType type) {
int fieldCount = type.getFieldCount();
//遍历所有field,对应column
for(int field = 0; field < fieldCount; ++field) {
int valueCount = group.getFieldRepetitionCount(field);
//有效数量,如果为0,则表示null,不需要此时写入
if (valueCount > 0) {
Type fieldType = type.getType(field);
String fieldName = fieldType.getName();
//标记field开始
this.recordConsumer.startField(fieldName, field);
for(int index = 0; index < valueCount; ++index) {
if (fieldType.isPrimitive()) {
//写入原始类型的值
group.writeValue(field, index, this.recordConsumer);
} else {
//复杂结构,递归调用
this.recordConsumer.startGroup();
this.writeGroup(group.getGroup(field, index), fieldType.asGroupType());
this.recordConsumer.endGroup();
}
}
//标记field结束
this.recordConsumer.endField(fieldName, field);
}
}
}
}
当所有列中有数据的列插入完毕后,执行this.recordConsumer.endMessage() ,
public void endMessage() {
//空值处理,writer中仅写入了非空值,这里把空值也写进去占位
this.writeNullForMissingFieldsAtCurrentLevel();
this.columns.endRecord();
if (MessageColumnIO.DEBUG) {
this.log("< MESSAGE END >");
}
if (MessageColumnIO.DEBUG) {
this.printState();
}
}
private void writeNullForMissingFieldsAtCurrentLevel() {
int currentFieldsCount = ((GroupColumnIO)this.currentColumnIO).getChildrenCount();
for(int i = 0; i < currentFieldsCount; ++i) {
if (!this.fieldsWritten[this.currentLevel].isWritten(i)) {
try {
ColumnIO undefinedField = ((GroupColumnIO)this.currentColumnIO).getChild(i);
int d = this.currentColumnIO.getDefinitionLevel();
if (MessageColumnIO.DEBUG) {
this.log(Arrays.toString(undefinedField.getFieldPath()) + ".writeNull(" + this.r[this.currentLevel] + "," + d + ")");
}
this.writeNull(undefinedField, this.r[this.currentLevel], d);
} catch (RuntimeException var5) {
throw new ParquetEncodingException("error while writing nulls for fields of indexes " + i + " . current index: " + this.fieldsWritten[this.currentLevel], var5);
}
}
}
}
ColumnWriterV1类定义了写空值,写非空值的方法。两个方法不同点是this.dataColumn.writeInteger(value);空值不为写入到dataColumn中,也没有写入null,因此不能认为存入的是规则的矩阵,因此解析时,需要根据repetition,definition来对应具体的data,
public void writeNull(int repetitionLevel, int definitionLevel) {
//写入列的repetitionLevel
this.repetitionLevelColumn.writeInteger(repetitionLevel);
this.definitionLevelColumn.writeInteger(definitionLevel);
//记录列的空数据个数
this.updateStatisticsNumNulls();
//
this.accountForValueWritten();
}
public void write(int value, int repetitionLevel, int definitionLevel) {
this.repetitionLevelColumn.writeInteger(repetitionLevel);
this.definitionLevelColumn.writeInteger(definitionLevel);
//写非空值时,多了一个dataColumn写操作
this.dataColumn.writeInteger(value);
this.updateStatistics(value);
this.accountForValueWritten();
}
//repetitionLevelColumn,definitionLevelColumn的生成方法如下,它依赖了共同的this.allocator:ByteBufferAllocator,作为写文件缓存
private ValuesWriter newColumnDescriptorValuesWriter(int maxLevel) {
//如果maxLevel为0,则返回一个DevNullValuesWriter,当执行write操作时,DevNullValuesWriter内部什么都不做
return (ValuesWriter)(maxLevel == 0 ? new DevNullValuesWriter() : new RunLengthBitPackingHybridValuesWriter(BytesUtils.getWidthFromMaxInt(maxLevel), 64, this.pageSizeThreshold, this.allocator));
}
当definitionLevel的maxLevel=0时,列为require节点
当repetitionLevel的maxLevel=0时,列没有涉及repeated字段
接下来再看看accountForValueWritten方法
private void accountForValueWritten() {
++this.valueCount; //值个数+1,如果个数超过了单个page的阈值,则触发大小判断
if (this.valueCount > this.valueCountForNextSizeCheck) {
long memSize = this.repetitionLevelColumn.getBufferedSize() + this.definitionLevelColumn.getBufferedSize() + this.dataColumn.getBufferedSize();
//计算列中repetitionLevel、definitionLevel、datas在内存缓冲区中的大小,如果大于pageSize阈值
if (memSize > (long)this.props.getPageSizeThreshold()) {
if (this.props.estimateNextSizeCheck()) {
this.valueCountForNextSizeCheck = this.valueCount / 2;
} else {
this.valueCountForNextSizeCheck = this.props.getMinRowCountForPageSizeCheck();
}
//将buffer写入文件
this.writePage();
} else if (this.props.estimateNextSizeCheck()) {
this.valueCountForNextSizeCheck = (int)((float)this.valueCount + (float)this.valueCount * (float)this.props.getPageSizeThreshold() / (float)memSize) / 2 + 1;
} else {
this.valueCountForNextSizeCheck += this.props.getMinRowCountForPageSizeCheck();
}
}
}
private void writePage() {
try {
//concat将repetitionLevel,definitionLevel,dataColumn顺序组装
this.pageWriter.writePage(BytesInput.concat(new BytesInput[]{this.repetitionLevelColumn.getBytes(), this.definitionLevelColumn.getBytes(), this.dataColumn.getBytes()}), this.valueCount, this.statistics, this.repetitionLevelColumn.getEncoding(), this.definitionLevelColumn.getEncoding(), this.dataColumn.getEncoding());
} catch (IOException var2) {
throw new ParquetEncodingException("could not write page for " + this.path, var2);
}
//重置内存,缓冲区
this.repetitionLevelColumn.reset();
this.definitionLevelColumn.reset();
this.dataColumn.reset();
this.valueCount = 0;
this.resetStatistics();
}
concat将 repetitionLevel,definitionLevel,dataColumn顺序组装,也就是说保存时他们是3个部分,而不是每一列一个组合。这里所有的repetitionLevel被组织在一起了,definitionLevel,dataColumn亦如是
public void writePage(BytesInput bytes, int valueCount, Statistics statistics, Encoding rlEncoding, Encoding dlEncoding, Encoding valuesEncoding) throws IOException {
long uncompressedSize = bytes.size();
if (uncompressedSize > 2147483647L) {
throw new ParquetEncodingException("Cannot write page larger than Integer.MAX_VALUE bytes: " + uncompressedSize);
} else {
//压缩
BytesInput compressedBytes = this.compressor.compress(bytes);
long compressedSize = compressedBytes.size();
if (compressedSize > 2147483647L) {
throw new ParquetEncodingException("Cannot write compressed page larger than Integer.MAX_VALUE bytes: " + compressedSize);
} else {
this.tempOutputStream.reset();
//写入pageMetadata
ColumnChunkPageWriteStore.parquetMetadataConverter.writeDataPageHeader((int)uncompressedSize, (int)compressedSize, valueCount, statistics, rlEncoding, dlEncoding, valuesEncoding, this.tempOutputStream);
this.uncompressedLength += uncompressedSize;
this.compressedLength += compressedSize;
this.totalValueCount += (long)valueCount;
++this.pageCount;
if (this.totalStatistics == null) {
this.totalStatistics = statistics.copy();
} else {
this.totalStatistics.mergeStatistics(statistics);
}
this.buf.collect(BytesInput.concat(new BytesInput[]{BytesInput.from(this.tempOutputStream), compressedBytes}));
this.rlEncodings.add(rlEncoding);
this.dlEncodings.add(dlEncoding);
this.dataEncodings.add(valuesEncoding);
}
}
}Parquet 列式存储格式的更多相关文章
- 【转】深入分析 Parquet 列式存储格式
Parquet 是面向分析型业务的列式存储格式,由 Twitter 和 Cloudera 合作开发,2015 年 5 月从 Apache 的孵化器里毕业成为 Apache 顶级项目,最新的版本是 1. ...
- 深入分析Parquet列式存储格式【转】
Parquet是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目,最新的版本是1.8.0. 列式存储 列式存 ...
- Parquet列式存储格式
Parquet是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目,最新的版本是1.8.0. 列式存储 列式存 ...
- 深入分析Parquet列式存储格式
Parquet是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目,最新的版本是1.8.0. 列式存储 列式存 ...
- parquet列式文件实战(未完,待续)
parquet列式文件实战 parquet code demo http://www.programcreek.com/java-api-examples/index.php?source_dir=h ...
- Parquet与ORC:高性能列式存储格式(收藏)
背景 随着大数据时代的到来,越来越多的数据流向了Hadoop生态圈,同时对于能够快速的从TB甚至PB级别的数据中获取有价值的数据对于一个产品和公司来说更加重要,在Hadoop生态圈的快速发展过程中,涌 ...
- Hadoop-No.4之列式存储格式
列式系统可提供的优势 对于查询内容之外的列,不必执行I/O和解压(若适用)操作 非常适合仅访问小部分列的查询.如果访问的列很多,则行存格式更为合适 相比由多行构成的数据块,列内的信息熵更低,所以从压缩 ...
- parquet列式文件实战
前言 列式文件,顾名思义就是按列存储到文件,和行式存储文件对应.保证了一列在一个文件中是连续的.下面从parquet常见术语,核心schema和文件结构来深入理解.最后通过java api完成writ ...
- Hadoop IO基于文件的数据结构详解【列式和行式数据结构的存储策略】
Charles所有关于hadoop的文章参考自hadoop权威指南第四版预览版 大家可以去safari免费阅读其英文预览版.本人也上传了PDF版本在我的资源中可以免费下载,不需要C币,点击这里下载. ...
随机推荐
- 缓动公式整理(附:C#实现及WPF原版对比)
前言 缓动在动画效果中应用非常广泛,在合适的时候使用一些缓动效果会使得效果更加符合人的直观感受,简单来说,会显得更加自然. WPF提供了11种缓动效果,涵盖了大部分的使用场景.不过如果需要在非WPF下 ...
- pwnable.kr-lotto-witeup
执行分析题目代码,发现是输入值和十进制是1到45的ASCII码系统生成对应字母做比较:而比较方法是遍历输入值的所有位和系统生成字符串的每个位作比较,相同计数为6则爆出flag.漏洞啊,只要押中有一字母 ...
- 结合 Shell 对 Koa 应用运行环境检查
在开发环境中,启动一个koa 应用服务,通常还需要同时启动数据库.比如.Mongodb.mysql 等 如果一直开着数据库服务,在不使用的话,电脑会占一定的性能.然而如果每次手动去启动服务,效率又不高 ...
- 【Hadoop】伪分布式安装
创建hadoop用户 创建用户命令: sudo useradd -m hadoop -s /bin/bash 创建好后需要更改hadoop用户的密码,命令如下: sudo passwd hadoop ...
- 《C++primerplus》第12章“队列模拟”程序
这个程序刚开始学有很多难点,个人认为主要有以下三项: 1.链表的概念 2.如何表示顾客随机到达的过程 3.程序执行时两类之间的关系,即执行逻辑 关于第一点,书上的图解释得比较清楚了,把"空指 ...
- 【题解】PTA-Little Bird
Link 单调队列板子. 题目大意:一个点可以由距离它不超过\(k\)的点跳过来,如果那个点比它高就不需要花费体力,否则花费\(1\)的体力.问走到\(n\)的最小体力,多组询问. 显然的转移方程,设 ...
- 利用 yum 命令和 rpm 命令升级 Nginx 或者安装最新版本 Nginx
方法一:使用 yum 命令升级 Nginx 1.在配置 YUM 仓库的目录(/etc/yum.repos.d/)下新增文件 nginx.repo vi /etc/yum.repos.d/nginx. ...
- 视频+图文教程 | Java之安装JDK与环境配置
演示所用软件JDK 8与Eclipse(Java开发工具)软件下载链接: 链接:https://pan.baidu.com/s/1Vg9ulrQH8WlGRAE89Y02UA提取码:swwl 视频介绍 ...
- iOS企业重签名管理软件之风车签名
这是一款在Mac平台下安全可控的iOS签名管理软件,旨在对签名后的APP能够完全控制,包括APP的开启或禁用.设置到期时间锁.注入第三方动态库文件.设置安装限量.修改APP名称和自定义Bundle I ...
- Python+Appium自动化测试(9)-自动选择USB用于传输文件(不依赖appium对手机页面元素进行定位)
一,问题 app自动化测试使用Android真机连接电脑时,通常会遇到两种情况: 1.测试机连接电脑会弹窗提示USB选项,选择USB用于"传输文件",有些手机不支持设置默认USB选 ...