国内最具影响力科技创投媒体36Kr的容器化之路
本文由1月19日晚36Kr运维开发工程师田翰明在Rancher技术交流群的技术分享整理而成。微信搜索rancher2,添加Rancher小助手为好友,加入技术群,实时参加下一次分享~
田翰明,36Kr 运维开发工程师,在 36Kr 主要负责运维自动化,CI/CD 的建设,以及应用容器化的推动。
背景
36Kr是一家创立于2010年,专注于科技创投领域的媒体公司,业务场景并不复杂,前端主要使用NodeJS进行Render,移动端有Android也有iOS,后端服务几乎全都由PHP来支持。使用PHP的主要原因是在最初进行技术选型的时候发现,PHP进行Web开发效率比较高,后来就一直这样延续下来了。
但是在后期,随着业务的突飞猛涨,在程序设计中又没能进行解耦,就导致了许多服务耦合成了一个很臃肿的单体应用,逻辑耦合严重,进而导致了很多的性能问题,随着问题越来越难改,开发任务又越来越紧,就不得不往后拖,越往后拖留下的问题就更难改,形成了一个恶性循环,留下了很多的技术债,很不利于后续的开发任务,并且一旦出现了问题,也很难追溯具体原因,所以在那时候经常听到一句话 “这是历史遗留问题” 。
B/S、C/S、单体应用,这是一种很传统 也很简单的架构,但是缺点也暴露无遗,所以经常因为一个业务逻辑的性能问题,进而影响到所有的业务。在运维侧,运维只能够通过堆机器,升配置等策略来应对,投入了很多的机器成本和人力成本,但是收效甚微,很是被动。
这种情况已经是迫在眉睫了,终于技术团队决定使用 Java 语言进行重构,将单体应用进行微服务化拆解,彻底改变这种因为单体应用故障而导致生产环境出现大范围的故障。
需求分析 + 选型
在重构计划开始一段时间后,为了节省虚机资源,我们一台虚机上运行了多个 Java 程序,但是因为没有资源隔离和灵活的调度系统,其实也会导致一些资源的浪费。并且在高并发场景下,偶尔会有资源抢占导致一个应用影响另一个应用的情况。为此,我们运维专门开发了一套自动化部署系统,系统内包括部署、监控检测、部署失败回滚、重启等基础功能。
随着当时 K8s 的风靡,还有 Rancher 2.x 的发布,我们逐渐发现,我们所面临的这些问题,它们基本都能解决,比如资源隔离、deployment 的控制器模型、灵活的调度系统,这些都有,这就是最好的自动化部署系统啊,于是我们运维侧,也开始决定向容器化进军。
在选型上,因为我们的服务基本都在阿里云上面,所以第一个想到的是阿里云。时因为我们和华为有一些业务的往来,所以华为的 CCE 也作为了备选,但是考虑到我们的服务资源全部在阿里云上,这个迁移成本实在太大了,所以就没再考虑华为云。
我们一开始使用过Rancher 1.6,但是只是用来管理主机上部署的原生 Docker。也因此对Rancher的产品产生了很大的好感。
需求方面,因为要降低我们研发人员的学习成本,容器管理平台的易用性十分重要。此外,K8s 的基础功能是必须的,因为 K8s 还在高速发展阶段,所以能需要够随时跟上更新,有安全漏洞后也需要第一时间进行更新打补丁,同时还要有基本的权限控制。而且我们公司内部没有专门的K8S团队,运维人员也只有2位,所以如果能够有专业人员进行技术上的交流,发生了问题可以有专业的服务团队来协助也十分重要。
综上,基本上就是 Rancher 完胜,UI 做得非常友好,开发人员能够很快上手,更新迭代速度也非常快,发现漏洞后也会有详细的补丁方案,认证策略也完美支持我们的 OpenLDAP 协议,能够对开发、测试、运维人员进行不同权限控制,并且也是第一家做到支持多云环境的,方便以后我们做跨云的方案。
我们这次容器化的过程,主要经历了以下几个因素的考虑,今天我就来和大家分享我们在 Rancher 上的一些实践,希望能给大家带来帮助:
应用的容器化改造
Rancher 的高可用性
容器的运维
多租户隔离
应用的容器化改造
因为我们的开发人员,有相当一部分是没有接触过容器的,为了能对开发人员更友好一些,我们的镜像分成了两层,主要的 Dockerfile 编写是由我们运维人员来编写的,而开发人员代码仓库里的 Dockerfile 是最简单的,基本上只有代码拷贝的过程和一些必传的变量,具体可以参考以下示例:
## 这是运维人员维护的 Dockerfile 示例
## 本示例仅做参考
FROM alpine:3.8
MAINTAINER yunwei <yunwei@36kr.com>
WORKDIR /www
RUN mv /etc/apk/repositories /etc/apk/repositories.bak \
&& echo "http://mirrors.aliyun.com/alpine/v3.8/main/" >> /etc/apk/repositories \
&& apk update && apk upgrade
RUN apk --no-cache add ca-certificates wget && \
wget -q -O /etc/apk/keys/sgerrand.rsa.pub https://alpine-pkgs.sgerrand.com/sgerrand.rsa.pub && \
wget https://github.com/sgerrand/alpine-pkg-glibc/releases/download/2.29-r0/glibc-2.29-r0.apk && \
apk add glibc-2.29-r0.apk && rm -f glibc-2.29-r0.apk
RUN apk add -U --no-cache \
bash \
sudo \
tzdata \
drill \
iputils \
curl \
busybox-extras \
&& rm -rf /var/cache/apk/* \
&& ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
COPY java-jar/jdk1.8.0_131 /usr/local/jdk1.8.0_131
ENV TZ="Asia/Shanghai"
ENV JAVA_HOME=/usr/local/jdk1.8.0_131
ENV CLASSPATH=$JAVA_HOME/bin
ENV PATH=.:$JAVA_HOME/bin:$PATH
ENV JAVA_OPTS="-server -Xms1024m -Xmx1024m"
CMD java -jar $JAVA_OPTS -Dserver.port=8080 server.jar
=======================================
## 这是开发人员维护的 Dockerfile 的示例
FROM harbor.36kr.com/java:v1.1.1
MAINTAINER developer <developer@36kr.com>
ADD web.jar ./server.jar
可以看到,开发人员所维护的 Dockerfile 可以说相当简单了,这大大的降低了开发人员维护的难度。
另外,因为构建产物的大小,很大程度上决定了部署时间的长短,所以我们使用了号称最小的镜像——alpine,alpine 有很多的优点:
体积小
有包管理器、有丰富的依赖
大厂的支持,包含 Docker 公司在内的多家大厂官方使用
但是他有一个缺点,alpine 上并没有 glibc 库,他所使用的是一个 musl libc 的小体积替代版,但是 Java 是必须依赖的 glibc 的,不过早就有大神了解了这点,在 GitHub 上已经提供了预编译的 glibc 库,名字为alpine-pkg-glibc,装上这个库就可以完美支持 Java,同时还能够保持体积很小。
Rancher 的高可用性
安装 Rancher 的方式有两种:单节点安装和高可用集群安装。一般单节点安装仅适用于测试或者 demo 环境,所以要正式投入使用的话,还是推荐高可用集群的安装方式。
我们一开始测试环境就使用了单节点安装的方式,后来因为 Rancher Server 那台机器出现过一次重启,就导致了测试环境故障,虽然备份了,但是还是丢失了少量数据,最后我们测试环境也采用了 HA 高可用部署,整个架构如下图所示。
Rancher Server 我是采用的 RKE 安装,并且为了防止阿里云出现区域性的故障,我们将 Rancher Server 的三台机器,部署在了两个可用区,Rancher Server-001、003 在北京的 H 区、Rancher Server-002 在北京的 G 区。
负载均衡,我们采用的是阿里云的 SLB,也是采购的主备型实例,防止单点故障,因为 Rancher 必须使用 SSL 证书,我们也有自己的域名证书,为了方便在 SLB 上进行 SSL 证书的维护,我们使用的是 7 层协议,在 SLB 上做的 SSL 终止,Rancher Server 的架构图可以参考下图:
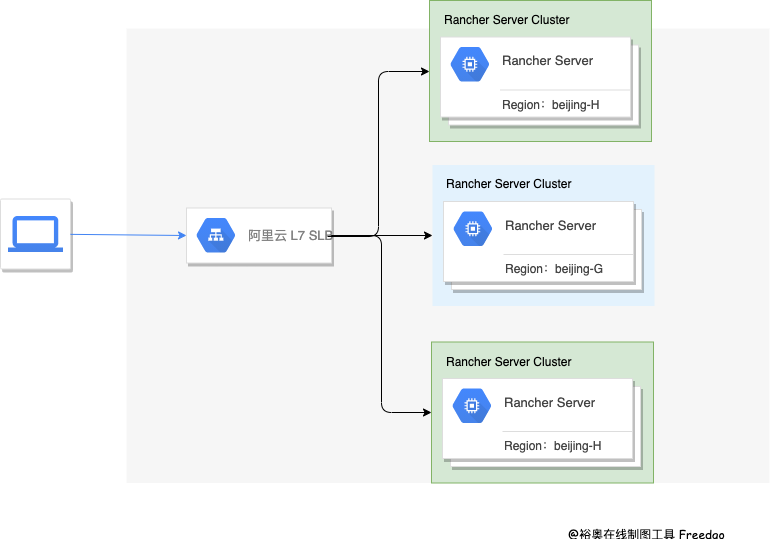
下游集群,也就是用来承载业务的 K8s 集群,我们也是一半一半,在阿里云的两个可用区进行部署的,需要注意的是,为了保证两个区的网络时延 <= 15 ms,这就完成了一个高可用的灾备架构。
备份方面,我们也使用了阿里云 ECS 快照 + ETCD S3 协议备份到了阿里云的 OSS 对象存储两种方案,确保出现故障后,能够及时恢复服务。
部署的详细教程可以参考Rancher 官方文档。
容器的运维
容器的运维,这里主要指容器的日志收集和容器监控,容器监控方面呢,Rancher 自带了 Prometheus 和 Grafana,而且和 Rancher 的 UI 有一些整合,就非常的方便,所以监控方面我就不展开讲了,我主要说一说日志收集。
在 K8s 里,日志的收集相比传统的物理机、虚机等方式要复杂一些,因为 K8s 所提供的是动态的环境,像绑定 hostpath 这种方式是不适用的,我们可以通过以下这个表格直观的对比一下:

可以看到,K8s 需要采集的日志种类比较多,而容器化的部署方式,在单机器内的应用数是很高的,而且都是动态的,所以传统的采集方式是不适用于 K8s 的。
目前 K8s 的采集方式大体可以分为两种,被动采集和主动推送。
主动推送一般有 DockerEngine 和 业务直写两种方式:DockerEngine 是 Docker 的 LogDriver 原生自带的,一般只能收集 STDOUT、一般不建议使用;而业务直写,则需要在应用里集成日志收集的 SDK,通过 SDK 直接发送到收集端,日志不需要落盘,也不需要部署Agent,但是业务会和 SDK 强绑定,灵活性偏低,建议对于日志量较大,或者对日志有定制化要求的场景使用。
被动推送是采用部署日志收集 Agent 进行采集的,有两种方式,一种是 Daemonset 每个机器节点上部署一个 Agent,还有一种 Sidecar,每个 Pod 以 Sidecar 的形式部署一个 Agent。
Sidecar 部署方式比较消耗资源,相当于每个 Pod 都有一个 agent,但是这种方式 灵活性以及隔离性较强,适合大型的 K8s 集群或者作为 PaaS 平台为业务方提供服务的群使用,Daemonset 部署方式,资源消耗较小,适合功能单一、业务不多的集群。
结合我们自身的场景,属于小规模集群,并且业务也不算多,我们选择了 Daemonset 的部署方式,在测试环境,我们经过调研选择了阿里开源的一个日志收集组件log-pilot GitHub 地址是:github.com/AliyunContainerService/log-pilot ,通过结合 Elasticsearch、Kibana 等算是一个不错的 K8s 日志解决方案。
因为我们的服务器都在阿里云上,我们运维人员比较少只有2位,没有精力再去维护一个大型的分布式存储集群,所以我们的业务日志选择存储在了阿里云的日志服务,所以在生产环境,我们的 K8s 也使用了阿里云日志服务,目前单日日志 6亿+ 没有任何问题。
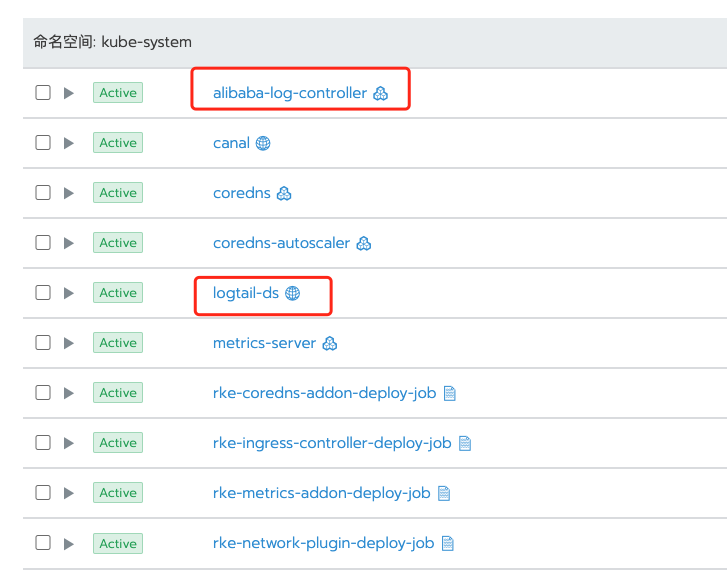
使用阿里云收集日志呢,你需要开通阿里云的日志服务,然后安装 Logtail 日志组件 alibaba-log-controller Helm,这个在官方文档里有安装脚本,我把文档链接贴在下面,在安装组件的过程中会自动创建aliyunlogconfigs CRD,部署alibaba-log-controller的Deployment,最后以 DaemonSet 模式安装 Logtail。然后你就可以在控制台,接入你想要收集的日志了。安装完以后是这样的:
Logtail支持采集容器内产生的文本日志,并附加容器的相关元数据信息一起上传到日志服务。Kubernetes文件采集具备以下功能特点:
只需配置容器内的日志路径,无需关心该路径到宿主机的映射
支持通过Label指定采集的容器
支持通过Label排除特定容器
支持通过环境变量指定采集的容器
支持通过环境变量指定排除的容器
支持多行日志(例如java stack日志)
支持Docker容器数据自动打标签
支持Kubernetes容器数据自动打标签
如果你想了解更多,可以查看阿里云日志服务的官方文档:
https://help.aliyun.com/document_detail/157317.html?spm=a2c4g.11186623.6.621.193c25f44oLO1V
容器的多租户隔离
我这里所讲的,主要指的是企业内部用户的多租户隔离,而不是指的 SaaS、KaaS 服务模型的多租户隔离。
在权限方面,因为我司对于权限的管控较严格,而 Rancher 恰好提供了非常方便的基于 集群、项目、命名空间等多个粒度的权限控制,并且支持我司基于 OpenLDAP 的认证协议,非常便于管理,我可以给不同项目组的开发、测试人员开通相对应的 集群/项目/命名空间的权限。
比如下图,我可以给集群添加用户、也可以给某个 Project 添加用户,并且可以指定几个不同的角色,甚至可以自定义角色。
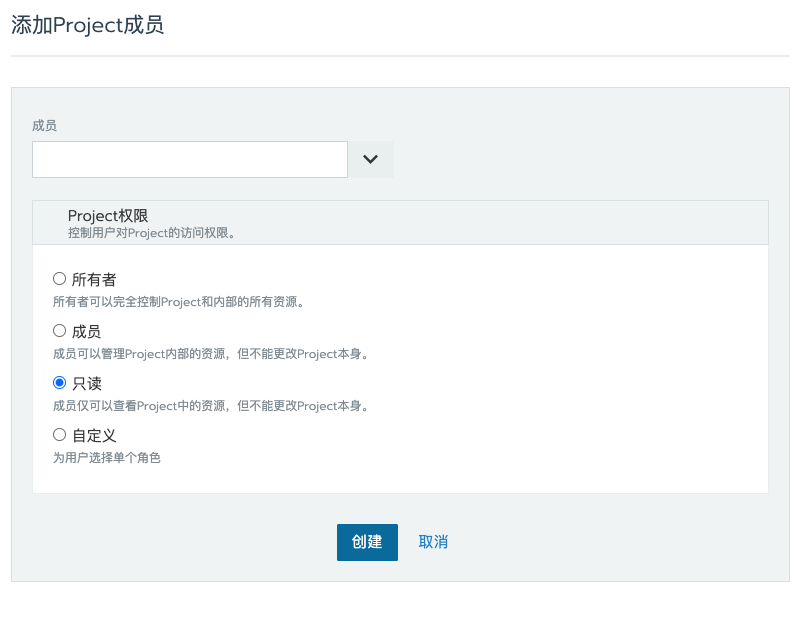
比如场景1:我可以给 项目组长,分配开发环境集群->项目1 所有者(Owner)权限,然后项目组长可以自由控制给本项目添加他的成员,并分配相应权限。
场景2:我可以给 测试经理,分配测试集群的所有者(Owner)权限,由测试经理来分配,谁来负责哪个项目的测试部署,以及开发人员只能查看日志等。
在资源方面,一定要进行容器的资源配额设置,如果不设置资源限额,一旦某一个应用出现了性能问题,将会影响整个 node 节点上的所有应用,K8s 会将出现问题的应用调度到其他 node 上,如果你的资源不够,将会出现整个系统的瘫痪,导致雪崩。
Java 应用的资源配额限制也有一个坑,因为默认 Java 是通过 /proc/meminfo 来获取内存信息的,默认 JVM 会使用系统内存的 25% 作为 Max Heap Size,但是容器内的/proc/meminfo是宿主机只读模式挂载到容器里的,所以采取默认值是行不通的,会导致应用超过容器限制的内存配额后被OOM,而健康检查又将服务重启,造成应用不断的重启。
那是不是通过手动参数设置 JVM 内存 = 容器内存限额呢?不行!因为 JVM消耗的内存不仅仅是 Heap,因为 JVM 也是一个应用,它需要额外的空间去完成它的工作,你需要配置的限额应该是 Metaspace + Threads + heap + JVM 进程运行所需内存 + 其他数据 关于这块,因为涉及到的内容较多,就不进行展开,感兴趣的同学可以自己去搜索 一下。
总 结
因为我们的业务场景并不复杂,所以我们的容器化之路,其实走的也相对来讲蛮顺畅的,我们的运维人员很少,只有 2 位,所以我们也没有太多的时间精力去维护太多的自建系统,我们使用了很多的阿里云产品,包括 Rancher,他很方便的部署方式,友好的 UI,包括集成好的监控等等,在容器化之路上给了我们很大的信心。
我们使用构建两层镜像的方式,降低了开发人员的学习复杂度。使用了小体积镜像 alpine + 预编译 glibc 减小了镜像体积。提高了部署的时间,在架构上,我们采用了阿里云双区机房的灾备的架构,以及完备的备份方案。使用 Daemonset 部署的日志收集组件,收集到阿里云日志服务,支撑我们 6亿/日的日志系统。Rancher 还提供给了我们深度集成的监控系统、多租户隔离等。还有我们自己踩坑 踩出来的资源配额设置。
其实容器化并不复杂,如果没有 K8s,我们需要自己构建健康监测系统、发版系统、维护不同的主机环境,不能细粒度的进行资源划分,不能更有效的利用计算资源,运维的工作主要是什么?在我看来其实就是 节约成本、提高效率。虚拟化、自动化、智能化、高性能、高可用、高并发 等等,这些无一不是围绕着成本和效率这两个词,而 K8s 其实已经帮我们都做好了,而像 Rancher 这种编排平台又帮我们降低了 K8s 的学习复杂度,所以你要做的就是加入 K8s,好了,到这里这次的分享就结束了。感谢~
社区QA
Q1:K8S在生产环境的高可用存储方案有推荐吗?
A1:存储方案没有标准答案,我们主要使用阿里云,所以用的是阿里云的块存储,比较常见的方案还有 Ceph、GlusterFS、Portworx、OpenEBS 等,他们各有优劣,需结合自己的业务需求进行选择
Q2:灰度发布,Kubernetes网络流量可以通过服务网格分流实现网络层面的分发,但是涉及到应用大版本的更新时候,涉及到数据库结构的变更的时候,如何实现灰度发布?
A2:没有遇到过这个场景,不过提供一个思路,可以准备两套数据库,网络分流也可以分流到不通数据库,具体需要你自己验证一下是否可行
要分清楚这是两层,一层是逻辑层,一层是数据层,不能混为一谈
Q3:Pipeline是用什么做的?Pipeline下,如何处理同一个分支,需要并行测试多个版本的场景?我用Rancher的Pipeline,局限性比较大,就是同一个分支无法并行多套进行测试。命名空间在使用,但是同一个分支下,命名空间是写在.rancher.yml下的,所以无法区分,Rancher的Pipeline不能在外面注入变量进行区分。
A3:Rancher 的 Pipline 目前还是有一些不够灵活,我们使用的是自建 Jenkins 做 Pipeline 的,并行测试,可以用命名空间等隔离策略进行隔离,或者准备多套测试环境
Q4: 你们运维的Dockerfile和开发的Dockerfile是怎么合并的?
A4:开发的 Dockerfile 是 From 运维的 Dockerfile
Q5:你们k8s的漏洞扫描用的什么工具?一般什么级别的镜像漏洞需要进行修复?
A5:暂时没有使用漏扫工具,我们主要根据 Rancher 企业服务通知的修复建议进行修复
Q6: 就是比如说从外网,通过service ip能够登陆并且管理容器。想实现这一步必须通过将service ip暴露出来,然后这个service ip怎么暴露出来?麻烦解答一下。
A6:如果需求是管理容器,其实可以使用 Rancher 的用户权限控制,让某一用户拥有某一容器的权限,暴露 service ip 到公网,让用户管理容器是无法实现的
Q6 : 好的,谢谢,我还有一点不明白,这个service ip有什么办法能让他暴露出来呢?你意思是说让不同的用户通过rancher平台去管理不同的容器吗?麻烦再给解答一下,谢谢。
A6:可以使用 NodePort 暴露,通过 Node ip 和 端口进行访问,或者使用 公有云的负载均衡产品
Q6 : 我不是这个意思,我是想把service ip暴露出来,不只单单想通过集群内部访问。
A6:service ip 本来就是 K8s 内部的,暴露不了,只能转发
Q7: 为何没有放在3个可用区,如果可用区H挂掉,是否会导致集群不可访问?
A7:3个可用区当然也是可以的,Rancher HA 架构,只要有一个 Server 可用就没有关系
Q8:请教下你们多套开发测试环境的pipeline是怎么样的流程呢 (差异化)?有使用helm template吗,方便讲解下更多细节么?
A8:目前是通过 Jenkins 部署参数,部署的时候可以选择 命名空间、环境标识、分支等,通过 sed 修改 template
Q9:请问你们的devops流是怎样的呢?一个环境对应一个docker镜像,还是说test pre prd共用一个docker镜像呢?如果是一个docker镜像共用test pre prd的话是怎么做的呢(比如不同环境的配置以及开发的协‘同开发流)?
A9:我们是用的同一个镜像,部署时通过选择不同的环境标识参数,程序会自动注入不同环境的配置,需要开发进行一些相应的配置修改
Q10:不大懂容器的资源限制该如何配置,自己配置了感觉不起作用
A10:Rancher 可以在项目、命名空间、Pod 三个粒度进行设置,优先级相反
国内最具影响力科技创投媒体36Kr的容器化之路的更多相关文章
- AMS 新闻视频广告的云原生容器化之路
作者 卓晓光,腾讯广告高级开发工程师,负责新闻视频广告整体后台架构设计,有十余年高性能高可用海量后台服务开发和实践经验.目前正带领团队完成云原生技术栈的全面转型. 吴文祺,腾讯广告开发工程师,负责新闻 ...
- 案例 | 腾讯广告 AMS 的容器化之路
作者 张煜,15年加入腾讯并从事腾讯广告维护工作.20年开始引导腾讯广告技术团队接入公司的TKEx-teg,从业务的日常痛点并结合腾讯云原生特性来完善腾讯广告自有的容器化解决方案 项目背景 腾讯广告承 ...
- 成本降低40%、资源利用率提高20%的 AI 应用产品云原生容器化之路
作者 郭云龙,腾讯云高级工程师,目前就职于 CSIG 云产品三部-AI 应用产品中心,现负责中心后台业务框架开发. 导语 为了满足 AI 能力在公有云 SaaS 场景下,服务和模型需要快速迭代交付的需 ...
- 容器化之路Docker网络核心知识小结,理清楚了吗?
Docker网络是容器化中最难理解的一点也是整个容器化中最容易出问题又难以排查的地方,加上使用Kubernets后大部分人即使是专业运维如果没有扎实的网络知识也很难定位容器网络问题,因此这里就容器网络 ...
- 用户案例 | 腾讯小视频&转码平台云原生容器化之路
作者 李汇波,腾讯业务运维高级工程师,目前就职于TEG 云架构平台部 技术运营与质量中心,现负责微信.QQ社交类业务的视频转码运维. 摘要 随着短视频兴起和快速发展,对于视频转码处理的需求也越来越多. ...
- 最佳案例 | QQ 相册云原生容器化之路
关于我们 更多关于云原生的案例和知识,可关注同名[腾讯云原生]公众号~ 福利: ①公众号后台回复[手册],可获得<腾讯云原生路线图手册>&<腾讯云原生最佳实践>~ ②公 ...
- 最佳案例 | 游戏知几 AI 助手的云原生容器化之路
作者 张路,运营开发专家工程师,现负责游戏知几 AI 助手后台架构设计和优化工作. 游戏知几 随着业务不断的拓展,游戏知几AI智能问答机器人业务已经覆盖了自研游戏.二方.海外的多款游戏.游戏知几研发团 ...
- 回客科技 面试的 实现ioc 容器用到的技术,简述BeanFactory的实现原理,大搜车面试的 spring 怎么实现的依赖注入(DI)
前言:这几天的面试,感觉自己对spring 的整个掌握还是很薄弱.所以需要继续加强. 这里说明一下spring的这几个面试题,但是实际的感觉还是不对的,这种问题我认为需要真正读了spring的源码后说 ...
- 在Docker Hub上你可以很轻松下载到大量已经容器化的应用镜像,即拉即用——daocloud国内镜像加速
Docker之所以这么吸引人,除了它的新颖的技术外,围绕官方Registry(Docker Hub)的生态圈也是相当吸引人眼球的地方. 在Docker Hub上你可以很轻松下载到大量已经容器化的应用镜 ...
随机推荐
- springmvc表单标签库的使用
springmvc中可以使用表单标签库,支持数据绑定,用来将用户输入绑定到领域模型. 例子来源<Servlet.JSP和SpringMVC学习指南> 项目代码 关键代码及说明 bean对象 ...
- JQuery ajax request及Java服务端乱码问题及设置
今天花了半天功夫才搞定2个乱码问题 1. 原先一直用form提交,现在改作JQuery ajax 提交,发现乱码. 2. window.location url中含有中文提交后,乱码. 第一个问题: ...
- Python高级语法-私有属性-with上下文管理器(4.7.3)
@ 目录 1.说明 2.代码 关于作者 1.说明 上下文管理器 这里使用with open操作文件,让文件对象实现了自动释放资源.我们也能自定义上下文管理器,通过__enter__()和__exit_ ...
- 2020 .NET 开发者峰会顺利在苏州落幕,相关数据很喜人以及线上直播回看汇总
在2019年上海中国.NET开发者大会的基础上,2020年12月19-20日 继续以"开源.共享.创新" 为主题的第二届中国 .NET 开发者峰会(.NET Conf China ...
- python初学者-商品折扣问题
x = int(input("x=")) if x < 1600 : #如果x小于1600,y等于0 y = 0 #没有折扣 print("应付款:",x ...
- 2021韩顺平图解Linux课程(全面升级)基础篇
第1章 Linux 开山篇-内容介绍 本套 Linux 课程内容 Linux 主要应用领域:服务器 第2章 Linux 基础篇-Linux 入门 Linux 之父 Linus Torvalds Git ...
- Jenkins 持续集成实现 Android 自动化打包
打 debug 包流程: git pull 分支最新代码 Android Studio:Build - Generate Signed APK 从 IDE 里可以看到,实际上该操作是执行了 assem ...
- flowable获取上级主管
//主管 Dept managerDept = deptUserUtil.getManagerDept(bean.getCreateDept(),bean.getCreateUser()); //上级 ...
- [转载]Mybatis Generator最完整配置详解
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE generatorConfiguration ...
- 企业集群架构-03-NFS
NFS 目录 NFS NFS基本概述 NFS应用场景 NFS实现原理 NFS总结 NFS服务端安装 环境准备 服务端安装NFS 服务端NFS配置 服务端开机自启 服务端验证配置 NFS客户端挂载卸载 ...