使用FreeSurfer进行脑区分割
FreeSurfer 是美国哈佛-麻省理工卫生科学与技术部和马萨诸塞州总医院共同开发的一款磁共振数据处理软件包,是基于 Linux 平台的全免费开源软件。FreeSurfer 能完成对高分辨率的 MRI 图像进行分割、配准及三维重建,其处理过程主要包含去头骨、B1 偏差场校正、体数据配准、灰白质分割、面数据配准等。FreeSurfer 可以方便地处理大脑 MRI 图像,并生成高精度的灰、白质分割面和灰质、脑脊液分割面,根据这两个表面可以计算任何位置的皮质厚度及其他面数据特征如皮质 外表面积、曲率、灰质体积等,这些参数可以映射到通过白质膨胀算法得到的大脑皮质表面上直观显示。另外,FreeSurfer 还具有特征的组间差异分析及结果的可视化功能。
在 FreeSurfer 软件中,运行“recon -all”命令后,会在 surf 文件夹下生成 . white、. sphere、. inflated 等网格点文件。每一个文件里面都存储了大脑皮质表面网格点的三维坐标及相邻顶点构成的三角面片信息,需要注意的是 FreeSurfer 采用的是 RAS 坐标系,其意义为 R:right,X 轴正方向;A:anterior,Y 轴正方向;S:superior,Z 轴正方向。
FreeSurfer 也会在 surf 文件夹下生成基于曲面的形态特征数据,不同的特征采用不同的文件后缀名,如皮质厚度( . thickness )、雅可比度量(. jacobian. white)、脑沟( . sulc )、曲率(. curv)、外表面积(. area)、体积(. volume)等面数据文件,其坐标索引号与 Mesh 网格序号一致。
FreeSurfer 在图像处理过程中依据 Destrieux 分区法对脑区进行标签划分。该分区方法将大脑皮质表面划分为 75 个脑区,其分区结构主要为各脑回和脑沟,分区依据为曲率的大小,其脑回区域只包括脑膜表面的部分,而隐藏在下面的部分则被划分为脑沟区域。其分区文件为 label 文件夹下的 *h.aparc.a2009s.annot 文件,该文件夹下还有对应的部分 Broadmann 分区文件(*. label)。
过程中可以使用以下命令来调用recon-all函数来进行脑区分割。该命令使用的文件类型为 mgz, nii, nii.gz。当当前的文件格式为其它格式时,可使用命令mri_convert * *.nii来进行格式转换。
$> export SUBJECTS_DIR=<path to subject directory> # SUBJECTS_DIR变量为存储数据的目录
$> recon-all -i sample-001.nii.gz -s bert -all (creates a folder called bert in SUBJECTS_DIR)
该操作是十分耗时的,进行一例nii数据的脑区分割需要8小时左右,具体时间视配置有所改变。在完成分割之后,即可通过可视化软件如FreeView来进行结果查看。这里,我们的目标是使用python来获取各个脑区的Mask,首先,看一下各个脑区对应的索引,该数据保存在$FREESURFER_HOME/FreeSurferColorLUT.txt:
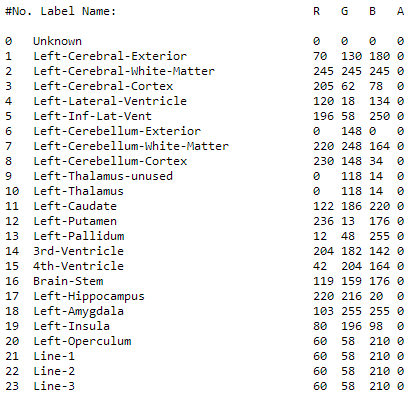
以下,我们假设保存的文件路径为bert。则,皮层下体积统计信息保存在bert/stats/aseg.stats中。统计信息包括 Index(在统计信息中的序号),SegId(对应的脑区索引),NVoxels(分割的体素数量),StrutName(在LUT中的名字),Mean/StdDev/Min/Max/Range: ROI的强度统计
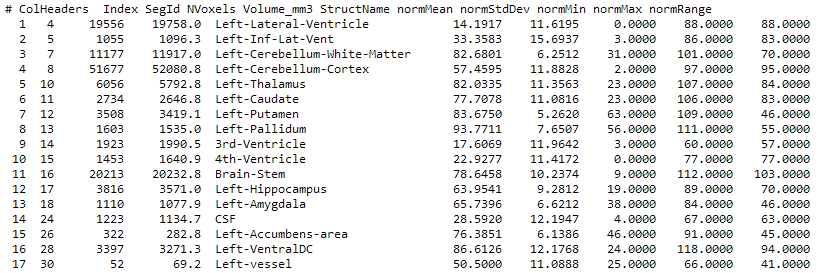
FreeSurfer使用了多种皮质层分割方法。使用Desikan/Killiany Atlas可分为35个脑区,数据保存在bert/label/*h.aparc.annot中。使用Destrieux Atlas时,可分割出58个脑区,保存在bert/label/*h.aparc.a2009s.annot文件中。两中方法分割的统计信息保存在bert/stats中如:*h.aparc.stats和*h.aparc.a2009s.stats。MRI数据分别保存为bert/mri/aparc.DKTatlas+aseg.mgz 以及bert/mri/aparc.a2009s+aseg.mgz,除此之外还有一个bert/mri/aparc+aseg.mgz。
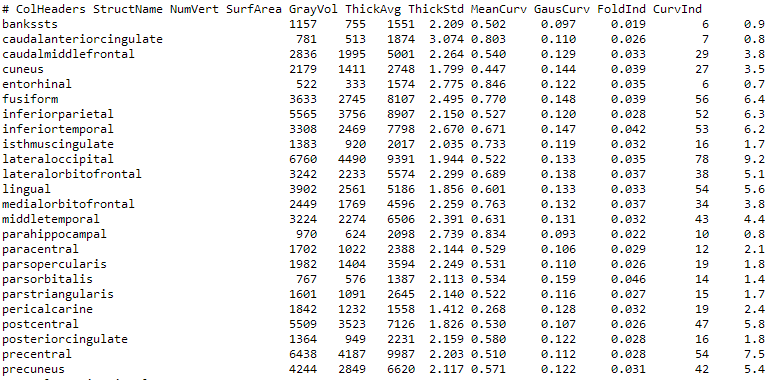
统计信息表现为下图,StructName表示结构名,NumVert表示结构中包含的顶点数,SurfArea表示表面积,GrayVol表示灰质体积,ThickAvg/ThickStd表示结构厚度的均值与标准差,MeanCurv表示平均曲率,GausCurv表示平均高斯曲率,FoldInd表示折叠指数,CurvInd表示曲率指数。
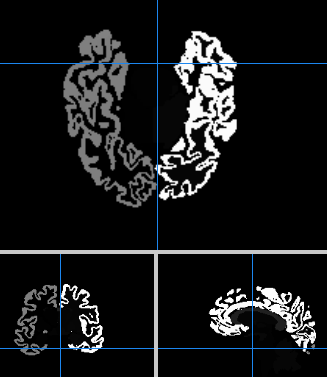
最终的分割数据保存在bert/mri/aseg.mgz中,比如使用命令mri_extract_label aseg.mgz 17 53 hippo_mask.mgz可以将海马区的数据给提取出来,其中17,53分别为左右海马区。
提取的结果文件如:

参考文献
医学图像处理:Ubuntu16.04安装freesurfer教程
Working with FreeSurfer Regions-of-Interest (ROIs):与感兴趣的区域(ROI)的工作规律.
FreeSurfer-Introduction
基于FreeSurfer面数据的网格点脑分区定位及其可视化
FreeSurfer 拾遗
使用FreeSurfer进行脑区分割的更多相关文章
- niftynet Demo分析 -- brain_parcellation
brain_parcellation 论文详细介绍 通过从脑部MR图像中分割155个神经结构来验证该网络学习3D表示的效率 目标:设计一个高分辨率和紧凑的网络架构来分割体积图像中的精细结构 特点:大多 ...
- 对于利用ica进行fmri激活区识别的理解
首先,ica是一种探索性的方法,属于数据驱动的范畴. ica计算量很大,一般都是离线式计算. ica基于的猜想是,世界是加性的.在我们所研究的脑科学中,所采集到的BOLD信号,是由一些源信号所构成,更 ...
- Sci Adv | 上科大水雯箐/胡霁/钟桂生脑蛋白质组学研究揭示抑郁行为的新调控因子
大脑是生物体内结构和功能最复杂的组织.近年来蓬勃发展的脑蛋白组学研究是绘制大脑功能分子图谱.全面理解大脑生理病理机制的必经途径.跨膜蛋白家族在突触信号传递和神经可塑性调节中扮演重要角色,许多跨膜蛋白与 ...
- AD分类论文研读(1)
转移性学习对阿尔茨海默病分类的研究 原文链接 摘要 将cv用于研究需要大量的训练图片,同时需要对深层网络的体系结构进行仔细优化.该研究尝试用转移学习来解决这些问题,使用从大基准数据集组成的自然图像得到 ...
- Dictionary Learning(字典学习、稀疏表示以及其他)
第一部分 字典学习以及稀疏表示的概要 字典学习(Dictionary Learning)和稀疏表示(Sparse Representation)在学术界的正式称谓应该是稀疏字典学习(Sparse Di ...
- MySQL底层索引剖析
1:Mysql索引是什么 mysql索引: 是一种帮助mysql高效的获取数据的数据结构,这些数据结构以某种方式引用数据,这种结构就是索引.可简单理解为排好序的快速查找数据结构.如果要查“mysql” ...
- MySQL常见面试题
1. 主键 超键 候选键 外键 主 键: 数据库表中对储存数据对象予以唯一和完整标识的数据列或属性的组合.一个数据列只能有一个主键,且主键的取值不能缺失,即不能为空值(Null). 超 键: 在关系中 ...
- 【转】MySQL索引背后的数据结构及算法原理
摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BT ...
- [转]MySQL索引背后的数据结构及算法原理
摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BT ...
随机推荐
- XDocument常用属性
XDocument常用属性: 1) BaseUri 获取此 XObject 的基 URI. (继承自 XObject.) 2) Declaration 获取或设置此文档的 XML 声明. 3) Doc ...
- PreparedStatement 防止sql注入 练习
使用的数据库 MariaDB 10.5.4版本 端口1054 数据库为jt_db,表 为user 数据库的建表和插入相关数据代码: create table user( id int pr ...
- 0ctf_2016 _Web_unserialize
0x01 拿到题目第一件事是进行目录扫描,看看都有哪些目录,结果如下: 不少,首先有源码,我们直接下载下来,因为有源码去分析比什么都没有更容易分析出漏洞所在. 通过这个知道,它一共有这么几个页面,首页 ...
- HTML5提高
HTML5提高 前言 我个人觉得,当你学会了一些最基本的标签其实是够用的,但是在很多网页中可以发现很多新的标签.这个时候不知道它是干嘛的实际上心里是非常没底的,所以在这里我打算写一篇HTML5提高的文 ...
- Python2爬取学生名单
背景: 学校的网站可以根据学号查学生姓名和成绩(三年后的补充:借助sql注入漏洞跳过密码,但是该网站现在已经被弃用了),所以我希望通过Python的爬虫得到年级所有同学的学号与姓名对应表. 实现: 首 ...
- bzoj2132圈地计划
bzoj2132圈地计划 题意: 一块土地可以纵横划分为N×M块小区域.于第i行第j列的区域,建造商业区将得到Aij收益,建造工业区将得到Bij收益.而如果区域(i,j)相邻(相邻是指两个格子有公共边 ...
- C#生成Excel文档(EPPlus)
1.公式计算 worksheet.Cells["D2:D5"].Formula = "B2*C2";//这是乘法的公式,意思是第二列乘以第三列的值赋值给第四列, ...
- Ethical Hacking - NETWORK PENETRATION TESTING(6)
Creating a fake access point (honeypot) Fake access points can be handy in many scenarios, one examp ...
- IDEA 编译 Jmeter 5.0
IDEA 编译 Jmeter 5.0 1.下载源码后解压,我这边下载的是最新的『apache-jmeter-5.0_src.tar』,解压. 2.解压后 修改下列两个文件 eclipse.classp ...
- 【Python学习笔记二】开始学习啦!如何在IDEA中新建python文件
1.新建module 2.选择本地安装的python 3.右键新建的module,创建python file就可以开始编程了 4.有时候回出现无法识别python内建函数的问题,就是运行没 ...