java基础知识 + 常见面试题
准备校招面试之Java篇
一. Java SE 部分
1.1 Java基础
1. 请你解释Object若不重写hashCode()的话,hashCode()如何计算出来的?
Object 的 hashcode 方法是本地方法,也就是用 c 语言或 c++ 实现的,该方法直接返回对象的 内存地址。
2. 请你解释为什么重写equals还要重写hashcode?
- HashMap中,如果要比较key是否相等,要同时使用这两个函数!因为自定义的类的hashcode()方法继承于Object类,其hashcode码为默认的内存地址,这样即便有相同含义的两个对象,比较也是不相等的。
- HashMap中的比较key是这样的,先求出key的hashcode(),比较其值是否相等,若相等再比较equals(),若相等则认为他们是相等的。若equals()不相等则认为他们不相等。
- 如果只重写hashcode()不重写equals()方法,当比较equals()时只是看他们是否为同一对象(即进行内存地址的比较),所以必定要两个方法一起重写。
- HashMap用来判断key是否相等的方法,其实是调用了HashSet判断加入元素是否相等。重载hashCode()是为了对同一个key,能得到相同的HashCode,这样HashMap就可以定位到我们指定的key上。
- 重载equals()是为了向HashMap表明当前对象和key上所保存的对象是相等的,这样我们才真正地获得了这个key所对应的这个键值对。
1.2 关键字
1.3 面向对象
1.4 集合
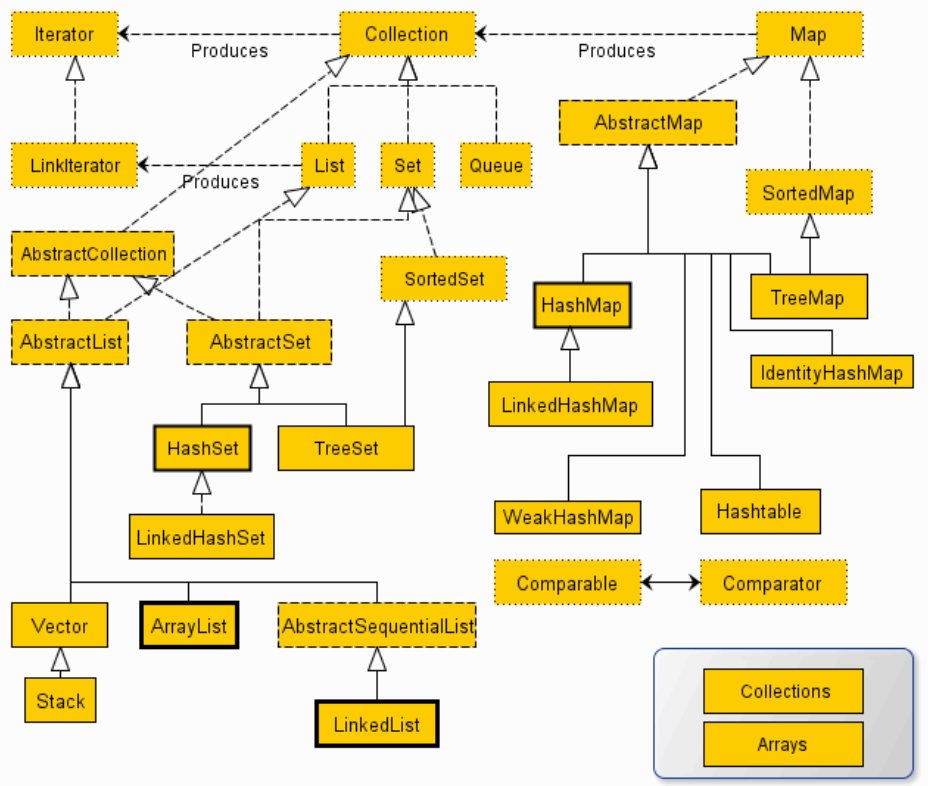
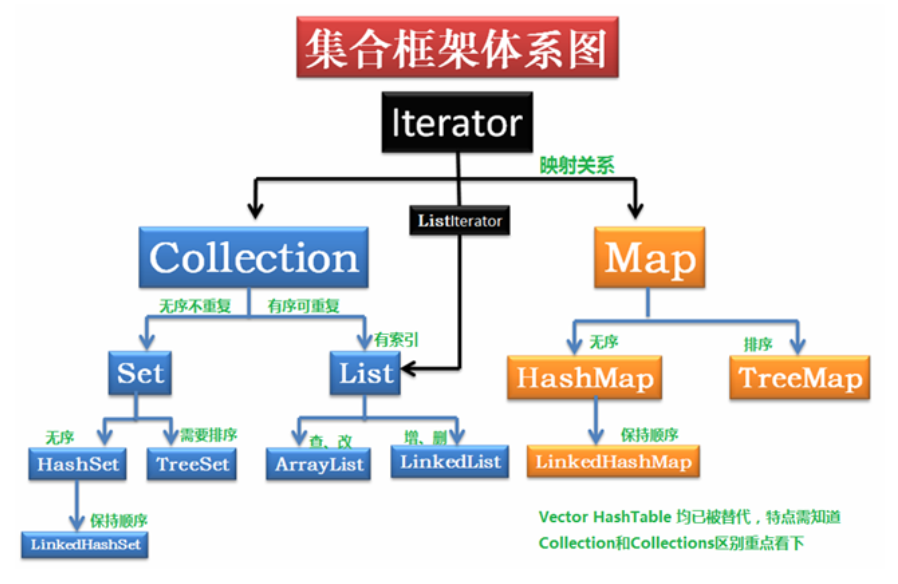
- 请说明Collection 和 Collections的区别。
- Collection是集合类的上级接口,继承与他的接口主要有Set 和List.
- Collections是针对集合类的一个帮助类,他提供一系列静态方法实现对各种集合的搜索、排序、线程安全化等操作。
1.5 JDK
1.6 反射
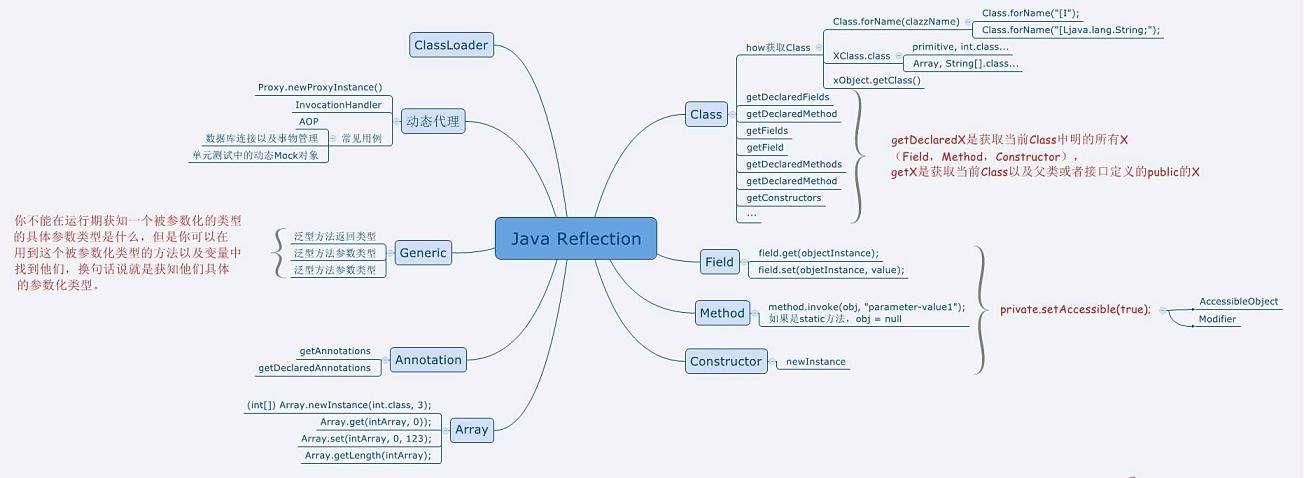
反射机制介绍
JAVA 反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为 java 语言的反射机制。
获取 Class 对象的两种方式
如果我们动态获取到这些信息,我们需要依靠 Class 对象。Class 类对象将一个类的方法、变量等信息告诉运行的程序。Java 提供了两种方式获取 Class 对象:
1.知道具体类的情况下可以使用:
Class alunbarClass = TargetObject.class;
但是我们一般是不知道具体类的,基本都是通过遍历包下面的类来获取 Class 对象
2.通过 Class.forName()传入类的路径获取:
Class alunbarClass1 = Class.forName("cn.javaguide.TargetObject");
代码实例
简单用代码演示一下反射的一些操作!
1.创建一个我们要使用反射操作的类 TargetObject:
package cn.javaguide;
public class TargetObject {
private String value;
public TargetObject() {
value = "JavaGuide";
}
public void publicMethod(String s) {
System.out.println("I love " + s);
}
private void privateMethod() {
System.out.println("value is " + value);
}
}
2.使用反射操作这个类的方法以及参数
package cn.javaguide;
import java.lang.reflect.Field;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
public class Main {
public static void main(String[] args) throws ClassNotFoundException, NoSuchMethodException, IllegalAccessException, InstantiationException, InvocationTargetException, NoSuchFieldException {
/**
* 获取TargetObject类的Class对象并且创建TargetObject类实例
*/
Class<?> tagetClass = Class.forName("cn.javaguide.TargetObject");
TargetObject targetObject = (TargetObject) tagetClass.newInstance();
/**
* 获取所有类中所有定义的方法
*/
Method[] methods = tagetClass.getDeclaredMethods();
for (Method method : methods) {
System.out.println(method.getName());
}
/**
* 获取指定方法并调用
*/
Method publicMethod = tagetClass.getDeclaredMethod("publicMethod",
String.class);
publicMethod.invoke(targetObject, "JavaGuide");
/**
* 获取指定参数并对参数进行修改
*/
Field field = tagetClass.getDeclaredField("value");
//为了对类中的参数进行修改我们取消安全检查
field.setAccessible(true);
field.set(targetObject, "JavaGuide");
/**
* 调用 private 方法
*/
Method privateMethod = tagetClass.getDeclaredMethod("privateMethod");
//为了调用private方法我们取消安全检查
privateMethod.setAccessible(true);
privateMethod.invoke(targetObject);
}
}
输出内容:
publicMethod
privateMethod
I love JavaGuide
value is JavaGuide
注意 : 有读者提到上面代码运行会抛出 ClassNotFoundException 异常,具体原因是你没有下面把这段代码的包名替换成自己创建的 TargetObject 所在的包 。
Class<?> tagetClass = Class.forName("cn.javaguide.TargetObject");
静态编译和动态编译
- 静态编译: 在编译时确定类型,绑定对象
- 动态编译: 运行时确定类型,绑定对象
反射机制优缺点
- 优点: 运行期类型的判断,动态加载类,提高代码灵活度。
- 缺点: 1,性能瓶颈:反射相当于一系列解释操作,通知 JVM 要做的事情,性能比直接的 java 代码要慢很多。2,安全问题,让我们可以动态操作改变类的属性同时也增加了类的安全隐患。
反射的应用场景
反射是框架设计的灵魂。
在我们平时的项目开发过程中,基本上很少会直接使用到反射机制,但这不能说明反射机制没有用,实际上有很多设计、开发都与反射机制有关,例如模块化的开发,通过反射去调用对应的字节码;动态代理设计模式也采用了反射机制,还有我们日常使用的 Spring/Hibernate 等框架也大量使用到了反射机制。
举例:
- 我们在使用 JDBC 连接数据库时使用
Class.forName()通过反射加载数据库的驱动程序; - Spring 框架的 IOC(动态加载管理 Bean)创建对象以及 AOP(动态代理)功能都和反射有联系;
- 动态配置实例的属性;
- ......
1. 反射机制:
- 在运行时加载、探知、使用编译时未知的类。
- 程序在运行状态中,可以动态加载一个只有名称的类,对于任意一个已加载的类,都能够知道这个类的所有属性和方法;
- 对于任意一个对象,都能够调用它的任意一个方法和属性;
Class c=Class forName("com. bjsxt test User");返回一个Class对象- 加载完类之后,在堆内存中,就产生了一个Cass类型的对象(一个类只有一个class对象),这个对象就包含了完整的类的结构信息我们可以通过这个对象看到类的结构。这个对象就像一面镜子,透过这个镜子看到类的结构,所以,我们形象的称之为:反射。
- 如果多次执行forName 等加载类的方法,类只会被加载一次;一个类只会形成一个Class对象,无论执行多少次加载类的方法,获得的Class 都是一样的。
2. 反射的优点:
- 可扩展性:应用程序可以利用全限定名创建可扩展对象的实例,来使用来自外部的用户自定义类。
- 类浏览器和可视化开发环境:一个类浏览器需要可以枚举类的成员。可视化开发环境(如DE)可以从利用反射中可用的类型信息中受益,以帮助程序员编写正确的代码。
- 调试器和测试工具:调试器需要能够检査一个类里的私有成员。测试工具可以利用反射来自动地调用类里定义的可被发现的A定义,以确保一组测试中有较高的代码覆盖率。
3. 反射的缺点:
- 尽管反射非常强大,但也不能滥用。如果一个功能可以不用反射完成,那么最好就不用。在我们使用反射技术时,下面几条内容应该牢记于心。
- 性能开销:反射涉及了动态类型的解析,所以JVM无法对这些代码进行优化。因此,反射操作的效率要比那些非反射操作低得多。我们应该避免在经常被执行的代码或对性能要求很高的程序中使用反射。
- 安全限制:使用反射技术要求程序必须在一个没有安全限制的环境中运行。如果一个程序必须在有安全限制的环境中运行,如 Applet,那么这就是个问题了
- 内部暴露:由于反射允许代码执行_些在正常情况下不被允许的操作(比如访冋私有的属性和方法),所以使用反射可能会导致意料之外的副作用,这可能导致代码功能失调并破坏可移植性。反射代码破坏了抽象性,因此当平台发生改变的时候,代码的行为就有可能也随着变化
4. 反射面试相关:
- 请说明一下JAVA中反射的实现过程和作用分别是什么?
JAVA语言编译之后会生成一个.class文件,反射就是通过字节码文件找到某一个类、类中的方法以及属性等。反射的实现主要借助以下四个类:Class:类的对象,Constructor:类的构造方法,Field:类中的属性对象,Method:类中的方法对象。
作用:反射机制指的是程序在运行时能够获取自身的信息。在JAVA中,只要给定类的名字,那么就可以通过反射机制来获取类的所有信息。
1.7 IO/NIO/AIO
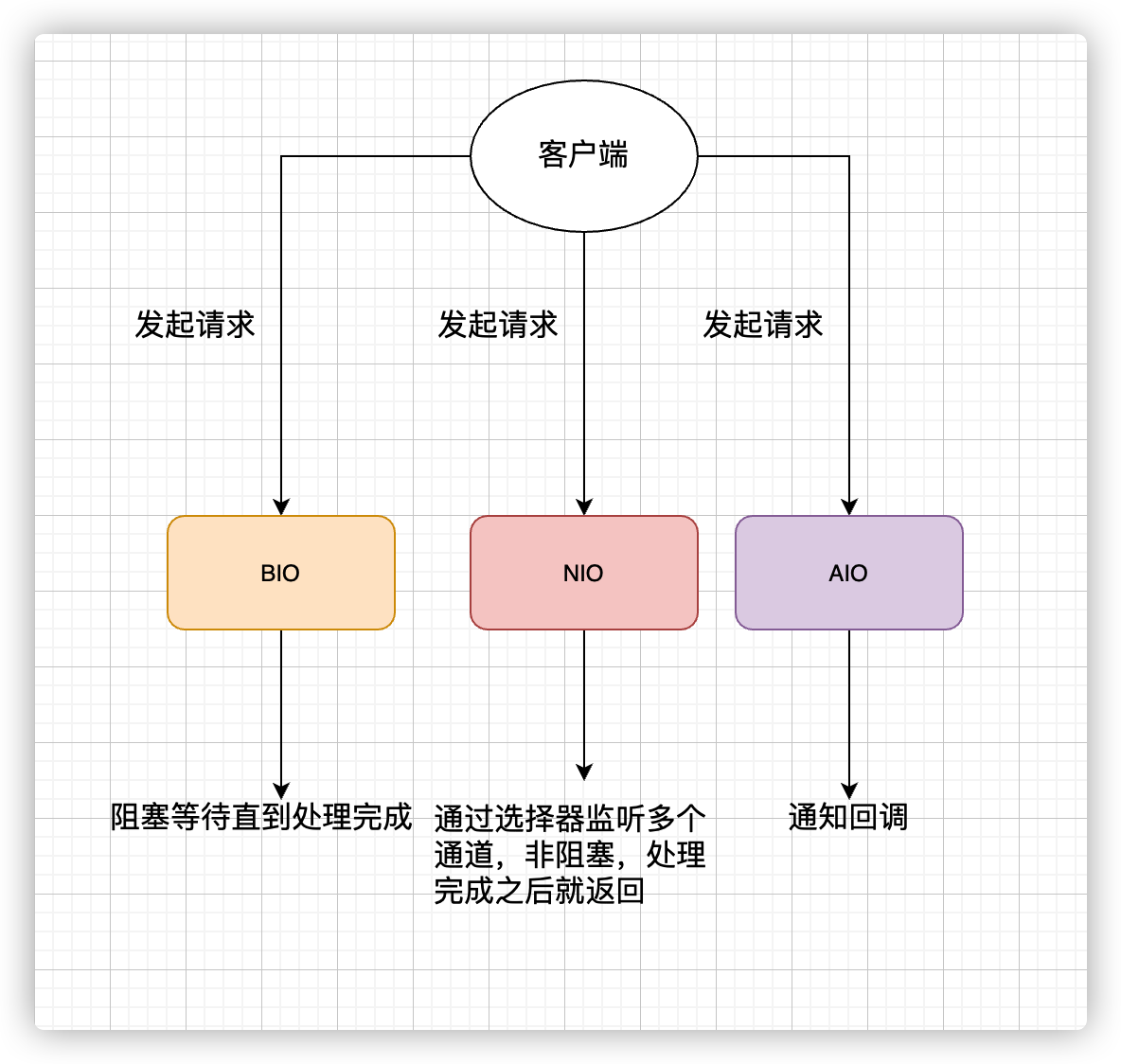
- BIO (Blocking I/O): 同步阻塞 I/O 模式,数据的读取写入必须阻塞在一个线程内等待其完成。在客户端连接数量不高的情况下,是没问题的。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
- NIO (Non-blocking/New I/O): NIO 是一种同步非阻塞的 I/O 模型,于 Java 1.4 中引入,对应 java.nio 包,提供了 Channel , Selector,Buffer 等抽象。NIO 中的 N 可以理解为 Non-blocking,不单纯是 New。它支持面向缓冲的,基于通道的 I/O 操作方法。 NIO 提供了与传统 BIO 模型中的
Socket和ServerSocket相对应的SocketChannel和ServerSocketChannel两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞两种模式。对于高负载、高并发的(网络)应用,应使用 NIO 的非阻塞模式来开发 - AIO (Asynchronous I/O): AIO 也就是 NIO 2。在 Java 7 中引入了 NIO 的改进版 NIO 2,它是异步非阻塞的 IO 模型。异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。AIO 是异步 IO 的缩写,虽然 NIO 在网络操作中,提供了非阻塞的方法,但是 NIO 的 IO 行为还是同步的。对于 NIO 来说,我们的业务线程是在 IO 操作准备好时,得到通知,接着就由这个线程自行进行 IO 操作,IO 操作本身是同步的。查阅网上相关资料,我发现就目前来说 AIO 的应用还不是很广泛,Netty 之前也尝试使用过 AIO,不过又放弃了。
1、阻塞与非阻塞
阻塞与非阻塞是描述进程在访问某个资源时,数据是否准备就绪的的一种处理方式。当数据没有准备就绪时:
- 阻塞:线程持续等待资源中数据准备完成,直到返回响应结果。
- 非阻塞:线程直接返回结果,不会持续等待资源准备数据结束后才响应结果。
2、同步与异步
- 同步与异步是指访问数据的机制,同步一般指主动请求并等待IO操作完成的方式。
- 异步则指主动请求数据后便可以继续处理其它任务,随后等待IO操作完毕的通知。
老王烧开水:
1、普通水壶煮水,站在旁边,主动的看水开了没有?同步的阻塞
2、普通水壶煮水,去干点别的事,每过一段时间去看看水开了没有,水没开就走人。 同步非阻塞
3、响水壶煮水,站在旁边,不会每过一段时间主动看水开了没有。如果水开了,水壶自动通知他。 异步阻塞
4、响水壶煮水,去干点别的事,如果水开了,水壶自动通知他。异步非阻塞
3、NIO模型
NIO(JDK1.4)模型是一种同步非阻塞IO,主要有三大核心部分:Channel(通道),Buffer(缓冲区), Selector(多路复用器)。传统IO基于字节流和字符流进行操作,而NIO基于Channel和Buffer(缓冲区)进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。Selector(多路复用器)用于监听多个通道的事件(比如:连接打开,数据到达)。因此,单个线程可以监听多个数据通道。
NIO和传统IO(一下简称IO)之间第一个最大的区别是,IO是面向流的,NIO是面向缓冲区的。 Java IO面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方。此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。NIO的缓冲导向方法略有不同。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。但是,还需要检查是否该缓冲区中包含所有您需要处理的数据。而且,需确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
IO的各种流是阻塞的。这意味着,当一个线程调用read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。 NIO的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取。而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。 非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。 线程通常将非阻塞IO的空闲时间用于在其它通道上执行IO操作,所以一个单独的线程现在可以管理多个输入和输出通道(channel)。
NIO优点:
通过Channel注册到Selector上的状态来实现一种客户端与服务端的通信。
Channel中数据的读取是通过Buffer , 一种非阻塞的读取方式。
Selector 多路复用器 单线程模型, 线程的资源开销相对比较小。
1.8 HashMap解读和源码分析:
HashMap存储数据是根据键值对存储数据的,并且存储多个数据时,数据的键不能相同,如果相同该键之前对应的值将被覆盖。注意如果想要保证HashMap能够正确的存储数据,请确保作为键的类,已经正确覆写了equals()方法。HashMap存储数据的位置与添加数据的键的hashCode()返回值有关。所以在将元素使用 HashMap 存储的时候请确保你已经按照要求重写了hashCode()方法。这里说有关系代表最终的存储位置不一定就是hashCode的返回值。HashMap最多只允许一条存储数据的键为 null,可允许多条数据的值为 null。HashMap存储数据的顺序是不确定的,并且可能会因为扩容导致元素存储位置改变。因此遍历顺序是不确定的。HashMap是线程不安全的,如果需要再多线程的情况下使用可以用Collections.synchronizedMap(Map map)方法使HashMap具有线程安全的能力,或者使用ConcurrentHashMap。

1. 了解底层如何存储数据的
JDK 1.7 之前的存储结构
通过上篇文章搞懂 Java equals 和 hashCode 方法 我们以及对 hash 表有所了解,我们了解到及时 hashCode() 方法已经写得很完美了,终究还是有可能导致 「hash碰撞」的,
HashMap作为使用 hash 值来决定元素存储位置的集合也是需要处理 hash 冲突的。在1.7之前JDK采用「拉链法」来存储数据,即数组和链表结合的方式:
「拉链法」用专业点的名词来说叫做链地址法。简单来说,就是数组加链表的结合。在每个数组元素上存储的都是一个链表。
我们之前说到不同的 key 可能经过 hash 运算可能会得到相同的地址,但是一个数组单位上只能存放一个元素,采用链地址法以后,如果遇到相同的 hash 值的 key 的时候,我们可以将它放到作为数组元素的链表上。待我们去取元素的时候通过 hash 运算的结果找到这个链表,再在链表中找到与 key 相同的节点,就能找到 key 相应的值了。
JDK1.7中新添加进来的元素总是放在数组相应的角标位置,而原来处于该角标的位置的节点作为 next 节点放到新节点的后边。稍后通过源码分析我们也能看到这一点。
JDK1.8中的存储结构。
对于 JDK1.8 之后的
HashMap底层在解决哈希冲突的时候,就不单单是使用数组加上单链表的组合了,因为当处理如果 hash 值冲突较多的情况下,链表的长度就会越来越长,此时通过单链表来寻找对应 Key 对应的 Value 的时候就会使得时间复杂度达到 O(n),因此在 JDK1.8 之后,在链表新增节点导致链表长度超过TREEIFY_THRESHOLD = 8的时候,就会在添加元素的同时将原来的单链表转化为红黑树。对数据结构很在行的读者应该,知道红黑树是一种易于增删改查的二叉树,他对与数据的查询的时间复杂度是
O(logn)级别,所以利用红黑树的特点就可以更高效的对HashMap中的元素进行操作。
JDK1.8 对于HashMap 底层存储结构优化在于:当链表新增节点导致链表长度超过8的时候,就会将原有的链表转为红黑树来存储数据。
2. HashMap 的几个主要方法
关于 HashMap 源码中分析的文章一般都会提及几个重要的概念:
重要参数
- 哈希桶(buckets):在 HashMap 的注释里使用哈希桶来形象的表示数组中每个地址位置。注意这里并不是数组本身,数组是装哈希桶的,他可以被称为哈希表。
- 初始容量(initial capacity) : 这个很容易理解,就是哈希表中哈希桶初始的数量。如果我们没有通过构造方法修改这个容量值默认为
DEFAULT_INITIAL_CAPACITY = 1<<4即16。值得注意的是为了保证 HashMap 添加和查找的高效性,HashMap的容量总是 2^n 的形式。 - 加载因子(load factor):加载因子是哈希表(散列表)在其容量自动增加之前被允许获得的最大数量的度量。当哈希表中的条目数量超过负载因子和当前容量的乘积时,散列表就会被重新映射(即重建内部数据结构),重新创建的散列表容量大约是之前散列表哈希桶数量的两倍。默认加载因子(0.75)在时间和空间成本之间提供了良好的折衷。加载因子过大会导致很容易链表过长,加载因子很小又容易导致频繁的扩容。所以不要轻易试着去改变这个默认值。
- 扩容阈值(threshold):其实在说加载因子的时候已经提到了扩容阈值了,扩容阈值 = 哈希表容量 * 加载因子。哈希表的键值对总数 = 所有哈希桶中所有链表节点数的加和,扩容阈值比较的是是键值对的个数而不是哈希表的数组中有多少个位置被占了。
- 树化阀值(TREEIFY_THRESHOLD) :这个参数概念是在 JDK1.8后加入的,它的含义代表一个哈希桶中的节点个数大于该值(默认为8)的时候将会被转为红黑树行存储结构。
- 非树化阀值(UNTREEIFY_THRESHOLD): 与树化阈值相对应,表示当一个已经转化为树形存储结构的哈希桶中节点数量小于该值(默认为 6)的时候将再次改为单链表的格式存储。导致这种操作的原因可能有删除节点或者扩容。
- 最小树化容量(MIN_TREEIFY_CAPACITY): 经过上边的介绍我们只知道,当链表的节点数超过8的时候就会转化为树化存储,其实对于转化还有一个要求就是哈希表的数量超过最小树化容量的要求(默认要求是 64),且为了避免进行扩容、树形化选择的冲突,这个值不能小于 4 * TREEIFY_THRESHOLD);在达到该有求之前优先选择扩容。扩容因为容量的变化可能会使单链表的长度改变。
与这个几个概念对应的在 HashMap 中几个常亮量,由于上边的介绍比较详细了,下边仅列出几个变量的声明:
/*默认初始容量*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/*最大存储容量*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/*默认加载因子*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/*默认树化阈值*/
static final int TREEIFY_THRESHOLD = 8;
/*默认非树化阈值*/
static final int UNTREEIFY_THRESHOLD = 6;
/*默认最小树化容量*/
static final int MIN_TREEIFY_CAPACITY = 64;
对应的还有几个全局变量:
// 扩容阈值 = 容量 x 加载因子
int threshold;
//存储哈希桶的数组,哈希桶中装的是一个单链表或一颗红黑树,长度一定是 2^n
transient Node<K,V>[] table;
// HashMap中存储的键值对的数量注意这里是键值对的个数而不是数组的长度
transient int size;
//所有键值对的Set集合 区分于 table 可以调用 entrySet()得到该集合
transient Set<Map.Entry<K,V>> entrySet;
//操作数记录 为了多线程操作时 Fast-fail 机制
transient int modCount;
基本存储单元
HashMap 在 JDK 1.7 中只有 Entry 一种存储单元,而在 JDK1.8 中由于有了红黑树的存在,就多了一种存储单元,而 Entry 也随之应景的改为名为 Node。我们先来看下单链表节点的表示方法 :
/**
* 内部类 Node 实现基类的内部接口 Map.Entry<K,V>
*
*/
static class Node<K,V> implements Map.Entry<K,V> {
//此值是在数组索引位置
final int hash;
//节点的键
final K key;
//节点的值
V value;
//单链表中下一个节点
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
//节点的 hashCode 值通过 key 的哈希值和 value 的哈希值异或得到,没发现在源码中中有用到。
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
//更新相同 key 对应的 Value 值
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
//equals 方法,键值同时相同才节点才相同
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
对于JDK1.8 新增的红黑树节点,这里不做展开叙述,有兴趣的朋友可以查看 HashMap 在 JDK 1.8 后新增的红黑树结构这篇文章来了解一下 JDK1.8对于红黑树的操作。
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
·········
}
HashMap 构造方法
HashMap 构造方法一共有三个:
- 可以指定期望初始容量和加载因子的构造函数,有了这两个值,我们就可以算出上边说到的
threshold加载因子。其中加载因子不可以小于0,并没有规定不可以大于 1,但是不能等于无穷.
大家可能疑惑
Float.isNaN()其实 NaN 就是 not a number 的缩写,我们知道在运算 1/0 的时候回抛出异常,但是如果我们的除数指定为浮点数 1/0.0f 的时候就不会抛出异常了。计算器运算出的结果可以当做一个极值也就是无穷大,无穷大不是个数所以 1/0.0f 返回结果是 Infinity 无穷,使用 Float.isNaN()判断将会返回 true。
public HashMap(int initialCapacity, float loadFactor) {
// 指定期望初始容量小于0将会抛出非法参数异常
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
// 期望初始容量不可以大于最大值 2^30 实际上我们也不会用到这么大的容量
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// 加载因子必须大于0 不能为无穷大
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;//初始化全局加载因子变量
this.threshold = tableSizeFor(initialCapacity);//根据初始容量计算计算扩容阈值
}
咦?不是说好扩容阈值 = 哈希表容量 * 加载因子么?为什么还要用到下边这个方法呢?我们之前说了参数 initialCapacity 只是期望容量,不知道大家发现没我们这个构造函数并没有初始化 Node[] table ,事实上真正指定哈希表容量总是在第一次添加元素的时候,这点和 ArrayList 的机制有所不同。等我们说到扩容机制的时候我们就可以看到相关代码了。
//根据期望容量返回一个 >= cap 的扩容阈值,并且这个阈值一定是 2^n
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
//经过上述面的 或和位移 运算, n 最终各位都是1
//最终结果 +1 也就保证了返回的肯定是 2^n
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
- 只指定初始容量的构造函数
这个就比较简单了,将指定的期望初容量和默认加载因子传递给两个参数构造方法。这里就不在赘述。
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
- 无参数构造函数
这也是我们最常用的一个构造函数,该方法初始化了加载因子为默认值,并没有调动其他的构造方法,跟我们之前说的一样,哈希表的大小以及其他参数都会在第一调用扩容函数的初始化为默认值。
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
- 传入一个 Map 集合的构造参数
该方法解释起来就比较麻烦了,因为他在初始化的时候就涉及了添加元素,扩容这两大重要的方法。这里先把它挂起来,紧接着我们讲完了扩容机制再回来看就好了。
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
3. HashMap 是如何确定元素存储位置的?
在分析 HashMap 添加元素的方法之前,我们需要先来了解下,如何确定元素在 HashMap 中的位置的。我们知道 HashMap 底层是哈希表,哈希表依靠 hash 值去确定元素存储位置。HashMap 在 JDK 1.7 和 JDK1.8中采用的 hash 方法并不是完全相同。我们现在看下
JDK 1.7 中 hash 方法的实现:
这里提出一个概念扰动函数,我们知道Map 文中存放键值对的位置由键的 hash 值决定,但是键的 hashCode 函数返回值不一定满足哈希表长度的要求,所以在存储元素之前需要对 key 的 hash 值进行一步扰动处理。下面我们JDK1.7 中的扰动函数:
//4次位运算 + 5次异或运算
//这种算法可以防止低位不变,高位变化时,造成的 hash 冲突
static final int hash(Object k) {
int h = 0;
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
JDK1.8 中 hash 函数的实现
JDK1.8中再次优化了这个哈希函数,把 key 的 hashCode 方法返回值右移16位,即丢弃低16位,高16位全为0 ,然后再和 hashCode 返回值做异或运算,即高 16 位与低 16 位进行异或运算,这么做可以在数组 table 的 length 比较小的时候,也能保证考虑到高低Bit都参与到 hash 的计算中,同时不会有太大的开销,扰动处理次数也从 4次位运算 + 5次异或运算 降低到 1次位运算 + 1次异或运算
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
进过上述的扰动函数只是得到了合适的 hash 值,但是还没有确定在 Node[] 数组中的角标,在 JDK1.7中存在一个函数,JDK1.8中虽然没有但是只是把这步运算放到了 put 函数中。我们就看下这个函数实现:
static int indexFor(int h, int length) {
return h & (length-1); // 取模运算
}
为了让 hash 值能够对应到现有数组中的位置,我们上篇文章讲到一个方法为 取模运算,即 hash % length,得到结果作为角标位置。但是 HashMap 就厉害了,连这一步取模运算的都优化了。我们需要知道一个计算机对于2进制的运算是要快于10进制的,取模算是10进制的运算了,而位与运算就要更高效一些了。
我们知道 HashMap 底层数组的长度总是 2^n ,转为二进制总是 1000 即1后边多个0的情况。此时一个数与 2^n 取模,等价于 一个数与 2^n - 1做位与运算。而 JDK 中就使用h & (length-1) 运算替代了对 length取模。我们根据图片来看一个具体的例子:

小结
通过上边的分析我们可以到如下结论:
- 在存储元素之前,HashMap 会对 key 的 hashCode 返回值做进一步扰动函数处理,1.7 中扰动函数使用了 4次位运算 + 5次异或运算,1.8 中降低到 1次位运算 + 1次异或运算
- 扰动处理后的 hash 与 哈希表数组length -1 做位与运算得到最终元素储存的哈希桶角标位置。
4. HashMap 是如何添加元素以及处理哈希冲突的?
敲黑板了,重点来了。对于理解 HashMap 源码一方面要了解存储的数据结构,另一方面也要了解具体是如何添加元素的。下面我们就来看下 put(K key, V value) 函数。
// 可以看到具体的添加行为在 putVal 方法中进行
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
对于 putVal 前三个参数很好理解,第4个参数 onlyIfAbsent 表示只有当对应 key 的位置为空的时候替换元素,一般传 false,在 JDK1.8中新增方法 public V putIfAbsent(K key, V value) 传 true,第 5 个参数 evict 如果是 false。那么表示是在初始化时调用的:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//如果是第一添加元素 table = null 则需要扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;// n 表示扩容后数组的长度
// i = (n - 1) & hash 即上边讲得元素存储在 map 中的数组角标计算
// 如果对应数组没有元素没发生 hash 碰撞 则直接赋值给数组中 index 位置
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {// 发生 hash 碰撞了
Node<K,V> e; K k;
//如果对应位置有已经有元素了 且 key 是相同的则覆盖元素
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)//如果添加当前节点已经为红黑树,则需要转为红黑树中的节点
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {// hash 值计算出的数组索引相同,但 key 并不同的时候,
// 循环整个单链表
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {//遍历到尾部
// 创建新的节点,拼接到链表尾部
p.next = newNode(hash, key, value, null);
// 如果添加后 bitCount 大于等于树化阈值后进行哈希桶树化操作
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//如果遍历过程中找到链表中有个节点的key与当前要插入元素的 key 相同,此时 e 所指的节点为需要替换 Value 的节点,并结束循环
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
//移动指针
p = e;
}
}
//如果循环完后 e!=null 代表需要替换e所指节点 Value
if (e != null) { // existing mapping for key
V oldValue = e.value//保存原来的 Value 作为返回值
// onlyIfAbsent 一般为 false 所以替换原来的 Value
if (!onlyIfAbsent || oldValue == null)
e.value = value;
//这个方法在 HashMap 中是空实现,在 LinkedHashMap 中有关系
afterNodeAccess(e);
return oldValue;
}
}
//操作数增加
++modCount;
//如果 size 大于扩容阈值则表示需要扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
由于添加元素中设计逻辑有点复杂,这里引用一张图来说明,理解

添加元素过程:
- 如果
Node[] table表为 null ,则表示是第一次添加元素,讲构造函数也提到了,及时构造函数指定了期望初始容量,在第一次添加元素的时候也为空。这时候需要进行首次扩容过程。 - 计算对应的键值对在 table 表中的索引位置,通过
i = (n - 1) & hash获得。 - 判断索引位置是否有元素如果没有元素则直接插入到数组中。如果有元素且key 相同,则覆盖 value 值,这里判断是用的 equals 这就表示要正确的存储元素,就必须按照业务要求覆写 key 的 equals 方法,上篇文章我们也提及到了该方法重要性。
- 如果索引位置的 key 不相同,则需要遍历单链表,如果遍历过如果有与 key 相同的节点,则保存索引,替换 Value;如果没有相同节点,则在但单链表尾部插入新节点。这里操作与1.7不同,1.7新来的节点总是在数组索引位置,而之前的元素作为下个节点拼接到新节点尾部。
- 如果插入节点后链表的长度大于树化阈值,则需要将单链表转为红黑树。
- 成功插入节点后,判断键值对个数是否大于扩容阈值,如果大于了则需要再次扩容。至此整个插入元素过程结束。
5. HashMap 扩容机制是怎样的?
在上边说明 HashMap 的 putVal 方法时候,多次提到了扩容函数,扩容函数也是我们理解 HashMap 源码的重中之重。所以再次敲黑板~
final Node<K,V>[] resize() {
// oldTab 指向旧的 table 表
Node<K,V>[] oldTab = table;
// oldCap 代表扩容前 table 表的数组长度,oldTab 第一次添加元素的时候为 null
int oldCap = (oldTab == null) ? 0 : oldTab.length;
// 旧的扩容阈值
int oldThr = threshold;
// 初始化新的阈值和容量
int newCap, newThr = 0;
// 如果 oldCap > 0 则会将新容量扩大到原来的2倍,扩容阈值也将扩大到原来阈值的两倍
if (oldCap > 0) {
// 如果旧的容量已经达到最大容量 2^30 那么就不在继续扩容直接返回,将扩容阈值设置到 Integer.MAX_VALUE,并不代表不能装新元素,只是数组长度将不会变化
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}//新容量扩大到原来的2倍,扩容阈值也将扩大到原来阈值的两倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
//oldThr 不为空,代表我们使用带参数的构造方法指定了加载因子并计算了
//初始阈值 会将扩容阈值 赋值给初始容量这里不再是期望容量,
//但是 >= 指定的期望容量
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else {
// 空参数构造会走这里初始化容量,和扩容阈值 分别是 16 和 12
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
//如果新的扩容阈值是0,对应的是当前 table 为空,但是有阈值的情况
if (newThr == 0) {
//计算新的扩容阈值
float ft = (float)newCap * loadFactor;
// 如果新的容量不大于 2^30 且 ft 不大于 2^30 的时候赋值给 newThr
//否则 使用 Integer.MAX_VALUE
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
//更新全局扩容阈值
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
//使用新的容量创建新的哈希表的数组
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
//如果老的数组不为空将进行重新插入操作否则直接返回
if (oldTab != null) {
//遍历老数组中每个位置的链表或者红黑树重新计算节点位置,插入新数组
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;//用来存储对应数组位置链表头节点
//如果当前数组位置存在元素
if ((e = oldTab[j]) != null) {
// 释放原来数组中的对应的空间
oldTab[j] = null;
// 如果链表只有一个节点,
//则使用新的数组长度计算节点位于新数组中的角标并插入
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)//如果当前节点为红黑树则需要进一步确定树中节点位于新数组中的位置。
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
//因为扩容是容量翻倍,
//原链表上的每个节点 现在可能存放在原来的下标,即low位,
//或者扩容后的下标,即high位
//低位链表的头结点、尾节点
Node<K,V> loHead = null, loTail = null;
//高位链表的头节点、尾节点
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;//用来存放原链表中的节点
do {
next = e.next;
// 利用哈希值 & 旧的容量,可以得到哈希值去模后,
//是大于等于 oldCap 还是小于 oldCap,
//等于 0 代表小于 oldCap,应该存放在低位,
//否则存放在高位(稍后有图片说明)
if ((e.hash & oldCap) == 0) {
//给头尾节点指针赋值
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}//高位也是相同的逻辑
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}//循环直到链表结束
} while ((e = next) != null);
//将低位链表存放在原index处,
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
//将高位链表存放在新index处
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
return newTab;
}
相信大家看到扩容的整个函数后对扩容机制应该有所了解了,整体分为两部分:
1. 寻找扩容后数组的大小以及新的扩容阈值,2. 将原有哈希表拷贝到新的哈希表中。
第一部分没的说,但是第二部分我看的有点懵逼了,但是踩在巨人的肩膀上总是比较容易的,美团的大佬们早就写过一些有关 HashMap 的源码分析文章,给了我很大的帮助。在文章的最后我会放出参考链接。下面说下我的理解 :
JDK 1.8 不像 JDK1.7中会重新计算每个节点在新哈希表中的位置,而是通过 (e.hash & oldCap) == 0是否等于0 就可以得出原来链表中的节点在新哈希表的位置。为什么可以这样高效的得出新位置呢?
因为扩容是容量翻倍,所以原链表上的每个节点,可能存放新哈希表中在原来的下标位置, 或者扩容后的原位置偏移量为 oldCap 的位置上,下边举个例子 图片和叙述来自 https://tech.meituan.com/java-hashmap.html:
图(a)表示扩容前的key1和key2两种key确定索引位置的示例,图(b)表示扩容后key1和key2两种key确定索引位置的示例,其中hash1是key1对应的哈希与高位运算结果。

元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化:

所以在 JDK1.8 中扩容后,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap
另外还需要注意的一点是 HashMap 在 1.7的时候扩容后,链表的节点顺序会倒置,1.8则不会出现这种情况。
HashMap 其他添加元素的方法
上边将构造函数的时候埋了个坑即使用:
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
构造函数构建 HashMap 的时候,在这个方法里,除了赋值了默认的加载因子,并没有调用其他构造方法,而是通过批量添加元素的方法 putMapEntries 来构造了 HashMap。该方法为私有方法,真正批量添加的方法为putAll
public void putAll(Map<? extends K, ? extends V> m) {
putMapEntries(m, true);
}
//同样第二参数代表是否初次创建 table
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
//如果哈希表为空则初始化参数扩容阈值
if (table == null) { // pre-size
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
if (t > threshold)
threshold = tableSizeFor(t);
}
else if (s > threshold)//构造方法没有计算 threshold 默认为0 所以会走扩容函数
resize();
//将参数中的 map 键值对一次添加到 HashMap 中
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
JDK1.8 中还新增了一个添加方法,该方法调用 putVal 且第4个参数传了 true,代表只有哈希表中对应的key 的位置上元素为空的时候添加成功,否则返回原来 key 对应的 Value 值。
@Override
public V putIfAbsent(K key, V value) {
return putVal(hash(key), key, value, true, true);
}
6. HashMap 查询元素
分析了完了 put 函数后,接下来让我们看下 get 函数,当然有 put 函数计算键值对在哈希表中位置的索引方法分析的铺垫后,get 方法就显得很容容易了。
- 根据键值对的 key 去获取对应的 Value
public V get(Object key) {
Node<K,V> e;
//通过 getNode寻找 key 对应的 Value 如果没找到,或者找到的结果为 null 就会返回null 否则会返回对应的 Value
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
//现根据 key 的 hash 值去找到对应的链表或者红黑树
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 如果第一个节点就是那么直接返回
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
//如果 对应的位置为红黑树调用红黑树的方法去寻找节点
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
//遍历单链表找到对应的 key 和 Value
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
- JDK 1.8新增 get 方法,在寻找 key 对应 Value 的时候如果没找大则返回指定默认值
@Override
public V getOrDefault(Object key, V defaultValue) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? defaultValue : e.value;
}
7. HashMap 的删操作
HashMap 没有 set 方法,如果想要修改对应 key 映射的 Value ,只需要再次调用 put 方法就可以了。我们来看下如何移除 HashMap 中对应的节点的方法:
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
@Override
public boolean remove(Object key, Object value) {
//这里传入了value 同时matchValue为true
return removeNode(hash(key), key, value, true, true) != null;
}
这里有两个参数需要我们提起注意:
- matchValue 如果这个值为 true 则表示只有当 Value 与第三个参数 Value 相同的时候才删除对一个的节点
- movable 这个参数在红黑树中先删除节点时候使用 true 表示删除并其他数中的节点。
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
//判断哈希表是否为空,长度是否大于0 对应的位置上是否有元素
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
// node 用来存放要移除的节点, e 表示下个节点 k ,v 每个节点的键值
Node<K,V> node = null, e; K k; V v;
//如果第一个节点就是我们要找的直接赋值给 node
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
// 遍历红黑树找到对应的节点
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
//遍历对应的链表找到对应的节点
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
// 如果找到了节点
// !matchValue 是否不删除节点
// (v = node.value) == value ||
(value != null && value.equals(v))) 节点值是否相同,
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
//删除节点
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
8. HashMap 的迭代器
我们都只我们知道 Map 和 Set 有多重迭代方式,对于 Map 遍历方式这里不展开说了,因为我们要分析迭代器的源码所以这里就给出一个使用迭代器遍历的方法:
public void test(){
Map<String, Integer> map = new HashMap<>();
...
Set<Map.Entry<String, Integer>> entrySet = map.entrySet();
//通过迭代器:先获得 key-value 对(Entry)的Iterator,再循环遍历
Iterator iter1 = entrySet.iterator();
while (iter1.hasNext()) {
// 遍历时,需先获取entry,再分别获取key、value
Map.Entry entry = (Map.Entry) iter1.next();
System.out.print((String) entry.getKey());
System.out.println((Integer) entry.getValue());
}
}
通过上述遍历过程我们可以使用 map.entrySet() 获取之前我们最初提及的 entrySet
public Set<Map.Entry<K,V>> entrySet() {
Set<Map.Entry<K,V>> es;
return (es = entrySet) == null ? (entrySet = new EntrySet()) : es;
}
// 我们来看下 EntrySet 是一个 set 存储的元素是 Map 的键值对
final class EntrySet extends AbstractSet<Map.Entry<K,V>> {
// size 放回 Map 中键值对个数
public final int size() { return size; }
//清除键值对
public final void clear() { HashMap.this.clear(); }
// 获取迭代器
public final Iterator<Map.Entry<K,V>> iterator() {
return new EntryIterator();
}
//通过 getNode 方法获取对一个及对应 key 对应的节点 这里必须传入
// Map.Entry 键值对类型的对象 否则直接返回 false
public final boolean contains(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<?,?> e = (Map.Entry<?,?>) o;
Object key = e.getKey();
Node<K,V> candidate = getNode(hash(key), key);
return candidate != null && candidate.equals(e);
}
// 滴啊用之前讲得 removeNode 方法 删除节点
public final boolean remove(Object o) {
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>) o;
Object key = e.getKey();
Object value = e.getValue();
return removeNode(hash(key), key, value, true, true) != null;
}
return false;
}
...
}
//EntryIterator 继承自 HashIterator
final class EntryIterator extends HashIterator
implements Iterator<Map.Entry<K,V>> {
// 这里可能是因为大家使用适配器的习惯添加了这个 next 方法
public final Map.Entry<K,V> next() { return nextNode(); }
}
abstract class HashIterator {
Node<K,V> next; // next entry to return
Node<K,V> current; // current entry
int expectedModCount; // for fast-fail
int index; // current slot
HashIterator() {
//初始化操作数 Fast-fail
expectedModCount = modCount;
// 将 Map 中的哈希表赋值给 t
Node<K,V>[] t = table;
current = next = null;
index = 0;
//从table 第一个不为空的 index 开始获取 entry
if (t != null && size > 0) { // advance to first entry
do {} while (index < t.length && (next = t[index++]) == null);
}
}
public final boolean hasNext() {
return next != null;
}
final Node<K,V> nextNode() {
Node<K,V>[] t;
Node<K,V> e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
//如果当前链表节点遍历完了,则取哈希桶下一个不为null的链表头
if ((next = (current = e).next) == null && (t = table) != null) {
do {} while (index < t.length && (next = t[index++]) == null);
}
return e;
}
//这里还是调用 removeNode 函数不在赘述
public final void remove() {
Node<K,V> p = current;
if (p == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
current = null;
K key = p.key;
removeNode(hash(key), key, null, false, false);
expectedModCount = modCount;
}
}
除了 EntryIterator 以外还有 KeyIterator 和 ValueIterator 也都继承了HashIterator 也代表了 HashMap 的三种不同的迭代器遍历方式。
final class KeyIterator extends HashIterator
implements Iterator<K> {
public final K next() { return nextNode().key; }
}
final class ValueIterator extends HashIterator
implements Iterator<V> {
public final V next() { return nextNode().value; }
}
可以看出无论哪种迭代器都是通过,遍历 table 表来获取下个节点,来遍历的,遍历过程可以理解为一种深度优先遍历,即优先遍历链表节点(或者红黑树),然后在遍历其他数组位置。
9. HashMap与HashTable 的区别
面试的时候面试官总是问完 HashMap 后会问 HashTable 其实 HashTable 也算是比较古老的类了。翻看 HashTable 的源码可以发现有如下区别:
HashMap是线程不安全的,HashTable是线程安全的。HashMap允许 key 和 Vale 是 null,但是只允许一个 key 为 null,且这个元素存放在哈希表 0 角标位置。HashTable不允许key、value 是 nullHashMap内部使用hash(Object key)扰动函数对 key 的hashCode进行扰动后作为hash值。HashTable是直接使用 key 的hashCode()返回值作为 hash 值。HashMap默认容量为 2^4 且容量一定是 2^n ;HashTable默认容量是11,不一定是 2^nHashTable取哈希桶下标是直接用模运算,扩容时新容量是原来的2倍+1。HashMap在扩容的时候是原来的两倍,且哈希桶的下标使用 &运算代替了取模。
10. JDK 1.8 在扩容和解决哈希冲突上对 HashMap 源码做了哪些改动?有什么好处?
11. 当两个对象的hashcode相同会发生什么?
hashcode相同,说明两个对象HashMap数组的同一位置上,接着HashMap会遍历链表中的每个元素,通过key的equals方法来判断是否为同一个key,如果是同一个key,则新的value会覆盖旧的value,并且返回旧的value。如果不是同一个key,则存储在该位置上的链表的链头
12. 如果两个键的hashcode相同,你如何获取值对象?
遍历HashMap链表中的每个元素,并对每个key进行hash计算,最后通过get方法获取其对应的值对象
13. 你了解重新调整HashMap大小存在什么问题吗?
当多线程的情况下,可能产生条件竞争。当重新调整HashMap大小的时候,确实存在条件竞争,如果两个线程都发现HashMap需要重新调整大小了,它们会同时试着调整大小。在调整大小的过程中,存储在链表中的元素的次序会反过来,因为移动到新的数组位置的时候,HashMap并不会将元素放在LinkedList的尾部,而是放在头部,这是为了避免尾部遍历(tail traversing)。如果条件竞争发生了,那么就死循环了
14. HashMap和TreeMap结构?HashMap为什么要树化?线程安全吗?怎么使之安全?
TreeMap 的实现就是红黑树数据结构,也就说是一棵自平衡的排序二叉树,这样就可以保证当需要快速检索指定节点。
红黑树的插入、删除、遍历时间复杂度都为O(logN),所以性能上低于哈希表。但是哈希表无法提供键值对的有序输出,红黑树因为是排序插入的,可以按照键的值的大小有序输出。
红黑树性质:
性质1:每个节点要么是红色,要么是黑色。
性质2:根节点永远是黑色的。
性质3:所有的叶节点都是空节点(即 null),并且是黑色的。
性质4:每个红色节点的两个子节点都是黑色。(从每个叶子到根的路径上不会有两个连续的红色节点)
性质5:从任一节点到其子树中每个叶子节点的路径都包含相同数量的黑色节点。
15. HashMap的容量为2^n的原因是:
对key的hash取余效率更高。因为当length是2的n次方的时候: hash % length == hash & (length - 1)。位运算的效率比直接取余的效率会高很多。
扩容resize()的时候,原来哈希表中,有接近一半的节点的下标是不变的,而另外的一半的下标为 原来的length + 原来的下标。具体要看hash值对应扩容后的某一位是0还是1.
1.9 CurrentHashMap的实现以及与HashMap的区别:
ConcurrentHashMap与HashMap等的区别
- HashMap
我们知道HashMap是线程不安全的,在多线程环境下,使用Hashmap进行put操作会引起死循环,导致CPU利用率接近100%,所以在并发情况下不能使用HashMap。
- HashTable
HashTable和HashMap的实现原理几乎一样,差别无非是
HashTable不允许key和value为null,HashTable是线程安全的但是HashTable线程安全的策略实现代价却太大了,简单粗暴,get/put所有相关操作都是synchronized的,这相当于给整个哈希表加了一把大锁。
多线程访问时候,只要有一个线程访问或操作该对象,那其他线程只能阻塞,相当于将所有的操作串行化,在竞争激烈的并发场景中性能就会非常差。
- ConcurrentHashMap
主要就是为了应对hashmap在并发环境下不安全而诞生的,ConcurrentHashMap的设计与实现非常精巧,大量的利用了volatile,final,CAS等lock-free技术来减少锁竞争对于性能的影响。
我们都知道Map一般都是数组+链表结构(JDK1.8该为数组+红黑树)。
- ConcurrentHashMap避免了对全局加锁改成了局部加锁操作,这样就极大地提高了并发环境下的操作速度,由于ConcurrentHashMap在JDK1.7和1.8中的实现非常不同,接下来我们谈谈JDK在1.7和1.8中的区别。
JDK1.7版本的CurrentHashMap的实现原理
在JDK1.7中ConcurrentHashMap采用了数组+Segment+分段锁的方式实现。
- Segment(分段锁)
ConcurrentHashMap中的分段锁称为Segment,它即类似于HashMap的结构,即内部拥有一个Entry数组,数组中的每个元素又是一个链表,同时又是一个ReentrantLock(Segment继承了ReentrantLock)。
- 内部结构
- ConcurrentHashMap使用分段锁技术,将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问,能够实现真正的并发访问。
- 如下图是ConcurrentHashMap的内部结构图:
- 从上面的结构我们可以了解到,ConcurrentHashMap定位一个元素的过程需要进行两次Hash操作。第一次Hash定位到Segment,第二次Hash定位到元素所在的链表的头部。
- 该结构的优劣势
坏处
这一种结构的带来的副作用是Hash的过程要比普通的HashMap要长
好处
写操作的时候可以只对元素所在的Segment进行加锁即可,不会影响到其他的Segment,这样,在最理想的情况下,ConcurrentHashMap可以最高同时支持Segment数量大小的写操作(刚好这些写操作都非常平均地分布在所有的Segment上)。
所以,通过这一种结构,ConcurrentHashMap的并发能力可以大大的提高。
JDK1.8版本的CurrentHashMap的实现原理
JDK8中ConcurrentHashMap参考了JDK8 HashMap的实现,采用了数组+链表+红黑树的实现方式来设计,内部大量采用CAS操作,这里我简要介绍下CAS。
CAS是compare and swap的缩写,即我们所说的比较交换。cas是一种基于锁的操作,而且是乐观锁。在java中锁分为乐观锁和悲观锁。悲观锁是将资源锁住,等一个之前获得锁的线程释放锁之后,下一个线程才可以访问。而乐观锁采取了一种宽泛的态度,通过某种方式不加锁来处理资源,比如通过给记录加version来获取数据,性能较悲观锁有很大的提高。
CAS 操作包含三个操作数 —— 内存位置(V)、预期原值(A)和新值(B)。如果内存地址里面的值和A的值是一样的,那么就将内存里面的值更新成B。
CAS是通过无限循环来获取数据的,若果在第一轮循环中,a线程获取地址里面的值被b线程修改了,那么a线程需要自旋,到下次循环才有可能机会执行。
JDK8中彻底放弃了Segment转而采用的是Node,其设计思想也不再是JDK1.7中的分段锁思想。
Node:保存key,value及key的hash值的数据结构。其中value和next都用volatile修饰,保证并发的可见性。
Java8 ConcurrentHashMap结构基本上和Java8的HashMap一样,不过保证线程安全性。
在JDK8中ConcurrentHashMap的结构,由于引入了红黑树,使得ConcurrentHashMap的实现非常复杂,我们都知道,红黑树是一种性能非常好的二叉查找树,其查找性能为O(logN),但是其实现过程也非常复杂,而且可读性也非常差,DougLea的思维能力确实不是一般人能比的,早期完全采用链表结构时Map的查找时间复杂度为O(N),JDK8中ConcurrentHashMap在链表的长度大于某个阈值的时候会将链表转换成红黑树进一步提高其查找性能。
总结
其实可以看出JDK1.8版本的ConcurrentHashMap的数据结构已经接近HashMap,相对而言,ConcurrentHashMap只是增加了同步的操作来控制并发,从JDK1.7版本的ReentrantLock+Segment+HashEntry,到JDK1.8版本中synchronized+CAS+HashEntry+红黑树。
数据结构:取消了Segment分段锁的数据结构,取而代之的是数组+链表+红黑树的结构。
保证线程安全机制:JDK1.7采用segment的分段锁机制实现线程安全,其中segment继承自ReentrantLock。JDK1.8采用CAS+Synchronized保证线程安全。
锁的粒度:原来是对需要进行数据操作的Segment加锁,现调整为对每个数组元素加锁(Node)。
链表转化为红黑树:定位结点的hash算法简化会带来弊端,Hash冲突加剧,因此在链表节点数量大于8时,会将链表转化为红黑树进行存储。
查询时间复杂度:从原来的遍历链表O(n),变成遍历红黑树O(logN)。
二. Java8的新特性
Java 8 Tutorial
欢迎阅读我对Java 8的介绍。本教程将逐步指导您完成所有新语言功能。 在简短的代码示例的基础上,您将学习如何使用默认接口方法,lambda表达式,方法引用和可重复注释。 在本文的最后,您将熟悉最新的 API 更改,如流,函数式接口(Functional Interfaces),Map 类的扩展和新的 Date API。 没有大段枯燥的文字,只有一堆注释的代码片段。
接口的默认方法(Default Methods for Interfaces)
Java 8使我们能够通过使用 default 关键字向接口添加非抽象方法实现。 此功能也称为虚拟扩展方法。
第一个例子:
interface Formula{
double calculate(int a);
default double sqrt(int a) {
return Math.sqrt(a);
}
}
Formula 接口中除了抽象方法计算接口公式还定义了默认方法 sqrt。 实现该接口的类只需要实现抽象方法 calculate。 默认方法sqrt 可以直接使用。当然你也可以直接通过接口创建对象,然后实现接口中的默认方法就可以了,我们通过代码演示一下这种方式。
public class Main {
public static void main(String[] args) {
// 通过匿名内部类方式访问接口
Formula formula = new Formula() {
@Override
public double calculate(int a) {
return sqrt(a * 100);
}
};
System.out.println(formula.calculate(100)); // 100.0
System.out.println(formula.sqrt(16)); // 4.0
}
}
formula 是作为匿名对象实现的。该代码非常容易理解,6行代码实现了计算 sqrt(a * 100)。在下一节中,我们将会看到在 Java 8 中实现单个方法对象有一种更好更方便的方法。
译者注: 不管是抽象类还是接口,都可以通过匿名内部类的方式访问。不能通过抽象类或者接口直接创建对象。对于上面通过匿名内部类方式访问接口,我们可以这样理解:一个内部类实现了接口里的抽象方法并且返回一个内部类对象,之后我们让接口的引用来指向这个对象。
Lambda表达式(Lambda expressions)
首先看看在老版本的Java中是如何排列字符串的:
List<String> names = Arrays.asList("peter", "anna", "mike", "xenia");
Collections.sort(names, new Comparator<String>() {
@Override
public int compare(String a, String b) {
return b.compareTo(a);
}
});
只需要给静态方法 Collections.sort 传入一个 List 对象以及一个比较器来按指定顺序排列。通常做法都是创建一个匿名的比较器对象然后将其传递给 sort 方法。
在Java 8 中你就没必要使用这种传统的匿名对象的方式了,Java 8提供了更简洁的语法,lambda表达式:
Collections.sort(names, (String a, String b) -> {
return b.compareTo(a);
});
可以看出,代码变得更段且更具有可读性,但是实际上还可以写得更短:
Collections.sort(names, (String a, String b) -> b.compareTo(a));
对于函数体只有一行代码的,你可以去掉大括号{}以及return关键字,但是你还可以写得更短点:
names.sort((a, b) -> b.compareTo(a));
List 类本身就有一个 sort 方法。并且Java编译器可以自动推导出参数类型,所以你可以不用再写一次类型。接下来我们看看lambda表达式还有什么其他用法。
函数式接口(Functional Interfaces)
译者注: 原文对这部分解释不太清楚,故做了修改!
Java 语言设计者们投入了大量精力来思考如何使现有的函数友好地支持Lambda。最终采取的方法是:增加函数式接口的概念。“函数式接口”是指仅仅只包含一个抽象方法,但是可以有多个非抽象方法(也就是上面提到的默认方法)的接口。 像这样的接口,可以被隐式转换为lambda表达式。java.lang.Runnable 与 java.util.concurrent.Callable 是函数式接口最典型的两个例子。Java 8增加了一种特殊的注解@FunctionalInterface,但是这个注解通常不是必须的(某些情况建议使用),只要接口只包含一个抽象方法,虚拟机会自动判断该接口为函数式接口。一般建议在接口上使用@FunctionalInterface 注解进行声明,这样的话,编译器如果发现你标注了这个注解的接口有多于一个抽象方法的时候会报错的,如下图所示
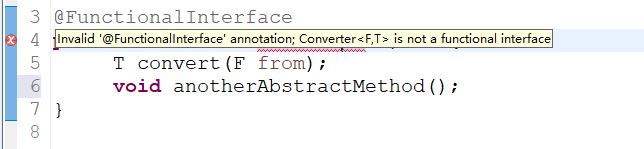
示例:
@FunctionalInterface
public interface Converter<F, T> {
T convert(F from);
}
// TODO 将数字字符串转换为整数类型
Converter<String, Integer> converter = (from) -> Integer.valueOf(from);
Integer converted = converter.convert("123");
System.out.println(converted.getClass()); //class java.lang.Integer
译者注: 大部分函数式接口都不用我们自己写,Java8都给我们实现好了,这些接口都在java.util.function包里。
方法和构造函数引用(Method and Constructor References)
前一节中的代码还可以通过静态方法引用来表示:
Converter<String, Integer> converter = Integer::valueOf;
Integer converted = converter.convert("123");
System.out.println(converted.getClass()); //class java.lang.Integer
Java 8允许您通过::关键字传递方法或构造函数的引用。 上面的示例显示了如何引用静态方法。 但我们也可以引用对象方法:
class Something {
String startsWith(String s) {
return String.valueOf(s.charAt(0));
}
}
Something something = new Something();
Converter<String, String> converter = something::startsWith;
String converted = converter.convert("Java");
System.out.println(converted); // "J"
接下来看看构造函数是如何使用::关键字来引用的,首先我们定义一个包含多个构造函数的简单类:
class Person {
String firstName;
String lastName;
Person() {}
Person(String firstName, String lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
}
接下来我们指定一个用来创建Person对象的对象工厂接口:
interface PersonFactory<P extends Person> {
P create(String firstName, String lastName);
}
这里我们使用构造函数引用来将他们关联起来,而不是手动实现一个完整的工厂:
PersonFactory<Person> personFactory = Person::new;
Person person = personFactory.create("Peter", "Parker");
我们只需要使用 Person::new 来获取Person类构造函数的引用,Java编译器会自动根据PersonFactory.create方法的参数类型来选择合适的构造函数。
Lamda 表达式作用域(Lambda Scopes)
访问局部变量
我们可以直接在 lambda 表达式中访问外部的局部变量:
final int num = 1;
Converter<Integer, String> stringConverter =
(from) -> String.valueOf(from + num);
stringConverter.convert(2); // 3
但是和匿名对象不同的是,这里的变量num可以不用声明为final,该代码同样正确:
int num = 1;
Converter<Integer, String> stringConverter =
(from) -> String.valueOf(from + num);
stringConverter.convert(2); // 3
不过这里的 num 必须不可被后面的代码修改(即隐性的具有final的语义),例如下面的就无法编译:
int num = 1;
Converter<Integer, String> stringConverter =
(from) -> String.valueOf(from + num);
num = 3;//在lambda表达式中试图修改num同样是不允许的。
访问字段和静态变量
与局部变量相比,我们对lambda表达式中的实例字段和静态变量都有读写访问权限。 该行为和匿名对象是一致的。
class Lambda4 {
static int outerStaticNum;
int outerNum;
void testScopes() {
Converter<Integer, String> stringConverter1 = (from) -> {
outerNum = 23;
return String.valueOf(from);
};
Converter<Integer, String> stringConverter2 = (from) -> {
outerStaticNum = 72;
return String.valueOf(from);
};
}
}
访问默认接口方法
还记得第一节中的 formula 示例吗? Formula 接口定义了一个默认方法sqrt,可以从包含匿名对象的每个 formula 实例访问该方法。 这不适用于lambda表达式。
无法从 lambda 表达式中访问默认方法,故以下代码无法编译:
Formula formula = (a) -> sqrt(a * 100);
内置函数式接口(Built-in Functional Interfaces)
JDK 1.8 API包含许多内置函数式接口。 其中一些借口在老版本的 Java 中是比较常见的比如: Comparator 或Runnable,这些接口都增加了@FunctionalInterface注解以便能用在 lambda 表达式上。
但是 Java 8 API 同样还提供了很多全新的函数式接口来让你的编程工作更加方便,有一些接口是来自 Google Guava 库里的,即便你对这些很熟悉了,还是有必要看看这些是如何扩展到lambda上使用的。
Predicate
Predicate 接口是只有一个参数的返回布尔类型值的 断言型 接口。该接口包含多种默认方法来将 Predicate 组合成其他复杂的逻辑(比如:与,或,非):
译者注: Predicate 接口源码如下
package java.util.function;
import java.util.Objects;
@FunctionalInterface
public interface Predicate<T> {
// 该方法是接受一个传入类型,返回一个布尔值.此方法应用于判断.
boolean test(T t);
//and方法与关系型运算符"&&"相似,两边都成立才返回true
default Predicate<T> and(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) -> test(t) && other.test(t);
}
// 与关系运算符"!"相似,对判断进行取反
default Predicate<T> negate() {
return (t) -> !test(t);
}
//or方法与关系型运算符"||"相似,两边只要有一个成立就返回true
default Predicate<T> or(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) -> test(t) || other.test(t);
}
// 该方法接收一个Object对象,返回一个Predicate类型.此方法用于判断第一个test的方法与第二个test方法相同(equal).
static <T> Predicate<T> isEqual(Object targetRef) {
return (null == targetRef)
? Objects::isNull
: object -> targetRef.equals(object);
}
示例:
Predicate<String> predicate = (s) -> s.length() > 0;
predicate.test("foo"); // true
predicate.negate().test("foo"); // false
Predicate<Boolean> nonNull = Objects::nonNull;
Predicate<Boolean> isNull = Objects::isNull;
Predicate<String> isEmpty = String::isEmpty;
Predicate<String> isNotEmpty = isEmpty.negate();
Function
Function 接口接受一个参数并生成结果。默认方法可用于将多个函数链接在一起(compose, andThen):
译者注: Function 接口源码如下
package java.util.function;
import java.util.Objects;
@FunctionalInterface
public interface Function<T, R> {
//将Function对象应用到输入的参数上,然后返回计算结果。
R apply(T t);
//将两个Function整合,并返回一个能够执行两个Function对象功能的Function对象。
default <V> Function<V, R> compose(Function<? super V, ? extends T> before) {
Objects.requireNonNull(before);
return (V v) -> apply(before.apply(v));
}
//
default <V> Function<T, V> andThen(Function<? super R, ? extends V> after) {
Objects.requireNonNull(after);
return (T t) -> after.apply(apply(t));
}
static <T> Function<T, T> identity() {
return t -> t;
}
}
Function<String, Integer> toInteger = Integer::valueOf;
Function<String, String> backToString = toInteger.andThen(String::valueOf);
backToString.apply("123"); // "123"
Supplier
Supplier 接口产生给定泛型类型的结果。 与 Function 接口不同,Supplier 接口不接受参数。
Supplier<Person> personSupplier = Person::new;
personSupplier.get(); // new Person
Consumer
Consumer 接口表示要对单个输入参数执行的操作。
Consumer<Person> greeter = (p) -> System.out.println("Hello, " + p.firstName);
greeter.accept(new Person("Luke", "Skywalker"));
Comparator
Comparator 是老Java中的经典接口, Java 8在此之上添加了多种默认方法:
Comparator<Person> comparator = (p1, p2) -> p1.firstName.compareTo(p2.firstName);
Person p1 = new Person("John", "Doe");
Person p2 = new Person("Alice", "Wonderland");
comparator.compare(p1, p2); // > 0
comparator.reversed().compare(p1, p2); // < 0
Optional
Optional不是函数式接口,而是用于防止 NullPointerException 的漂亮工具。这是下一节的一个重要概念,让我们快速了解一下Optional的工作原理。
Optional 是一个简单的容器,其值可能是null或者不是null。在Java 8之前一般某个函数应该返回非空对象但是有时却什么也没有返回,而在Java 8中,你应该返回 Optional 而不是 null。
译者注:示例中每个方法的作用已经添加。
//of():为非null的值创建一个Optional
Optional<String> optional = Optional.of("bam");
// isPresent(): 如果值存在返回true,否则返回false
optional.isPresent(); // true
//get():如果Optional有值则将其返回,否则抛出NoSuchElementException
optional.get(); // "bam"
//orElse():如果有值则将其返回,否则返回指定的其它值
optional.orElse("fallback"); // "bam"
//ifPresent():如果Optional实例有值则为其调用consumer,否则不做处理
optional.ifPresent((s) -> System.out.println(s.charAt(0))); // "b"
推荐阅读:[Java8]如何正确使用Optional
Streams(流)
java.util.Stream 表示能应用在一组元素上一次执行的操作序列。Stream 操作分为中间操作或者最终操作两种,最终操作返回一特定类型的计算结果,而中间操作返回Stream本身,这样你就可以将多个操作依次串起来。Stream 的创建需要指定一个数据源,比如 java.util.Collection 的子类,List 或者 Set, Map 不支持。Stream 的操作可以串行执行或者并行执行。
首先看看Stream是怎么用,首先创建实例代码的用到的数据List:
List<String> stringList = new ArrayList<>();
stringList.add("ddd2");
stringList.add("aaa2");
stringList.add("bbb1");
stringList.add("aaa1");
stringList.add("bbb3");
stringList.add("ccc");
stringList.add("bbb2");
stringList.add("ddd1");
Java 8扩展了集合类,可以通过 Collection.stream() 或者 Collection.parallelStream() 来创建一个Stream。下面几节将详细解释常用的Stream操作:
Filter(过滤)
过滤通过一个predicate接口来过滤并只保留符合条件的元素,该操作属于中间操作,所以我们可以在过滤后的结果来应用其他Stream操作(比如forEach)。forEach需要一个函数来对过滤后的元素依次执行。forEach是一个最终操作,所以我们不能在forEach之后来执行其他Stream操作。
// 测试 Filter(过滤)
stringList
.stream()
.filter((s) -> s.startsWith("a"))
.forEach(System.out::println);//aaa2 aaa1
forEach 是为 Lambda 而设计的,保持了最紧凑的风格。而且 Lambda 表达式本身是可以重用的,非常方便。
Sorted(排序)
排序是一个 中间操作,返回的是排序好后的 Stream。如果你不指定一个自定义的 Comparator 则会使用默认排序。
// 测试 Sort (排序)
stringList
.stream()
.sorted()
.filter((s) -> s.startsWith("a"))
.forEach(System.out::println);// aaa1 aaa2
需要注意的是,排序只创建了一个排列好后的Stream,而不会影响原有的数据源,排序之后原数据stringCollection是不会被修改的:
System.out.println(stringList);// ddd2, aaa2, bbb1, aaa1, bbb3, ccc, bbb2, ddd1
Map(映射)
中间操作 map 会将元素根据指定的 Function 接口来依次将元素转成另外的对象。
下面的示例展示了将字符串转换为大写字符串。你也可以通过map来将对象转换成其他类型,map返回的Stream类型是根据你map传递进去的函数的返回值决定的。
// 测试 Map 操作
stringList
.stream()
.map(String::toUpperCase)
.sorted((a, b) -> b.compareTo(a))
.forEach(System.out::println);// "DDD2", "DDD1", "CCC", "BBB3", "BBB2", "AAA2", "AAA1"
Match(匹配)-最终操作
Stream提供了多种匹配操作,允许检测指定的Predicate是否匹配整个Stream。所有的匹配操作都是 最终操作 ,并返回一个 boolean 类型的值。
// 测试 Match (匹配)操作
boolean anyStartsWithA =
stringList
.stream()
.anyMatch((s) -> s.startsWith("a"));
System.out.println(anyStartsWithA); // true
boolean allStartsWithA =
stringList
.stream()
.allMatch((s) -> s.startsWith("a"));
System.out.println(allStartsWithA); // false
boolean noneStartsWithZ =
stringList
.stream()
.noneMatch((s) -> s.startsWith("z"));
System.out.println(noneStartsWithZ); // true
Count(计数)-最终操作
计数是一个 最终操作,返回Stream中元素的个数,返回值类型是 long。
//测试 Count (计数)操作
long startsWithB =
stringList
.stream()
.filter((s) -> s.startsWith("b"))
.count();
System.out.println(startsWithB); // 3
Reduce(规约)-最终操作
这是一个 最终操作 ,允许通过指定的函数来讲stream中的多个元素规约为一个元素,规约后的结果是通过Optional 接口表示的:
//测试 Reduce (规约)操作
Optional<String> reduced =
stringList
.stream()
.sorted()
.reduce((s1, s2) -> s1 + "#" + s2);
reduced.ifPresent(System.out::println);//aaa1#aaa2#bbb1#bbb2#bbb3#ccc#ddd1#ddd2
译者注: 这个方法的主要作用是把 Stream 元素组合起来。它提供一个起始值(种子),然后依照运算规则(BinaryOperator),和前面 Stream 的第一个、第二个、第 n 个元素组合。从这个意义上说,字符串拼接、数值的 sum、min、max、average 都是特殊的 reduce。例如 Stream 的 sum 就相当于Integer sum = integers.reduce(0, (a, b) -> a+b);也有没有起始值的情况,这时会把 Stream 的前面两个元素组合起来,返回的是 Optional。
// 字符串连接,concat = "ABCD"
String concat = Stream.of("A", "B", "C", "D").reduce("", String::concat);
// 求最小值,minValue = -3.0
double minValue = Stream.of(-1.5, 1.0, -3.0, -2.0).reduce(Double.MAX_VALUE, Double::min);
// 求和,sumValue = 10, 有起始值
int sumValue = Stream.of(1, 2, 3, 4).reduce(0, Integer::sum);
// 求和,sumValue = 10, 无起始值
sumValue = Stream.of(1, 2, 3, 4).reduce(Integer::sum).get();
// 过滤,字符串连接,concat = "ace"
concat = Stream.of("a", "B", "c", "D", "e", "F").
filter(x -> x.compareTo("Z") > 0).
reduce("", String::concat);
上面代码例如第一个示例的 reduce(),第一个参数(空白字符)即为起始值,第二个参数(String::concat)为 BinaryOperator。这类有起始值的 reduce() 都返回具体的对象。而对于第四个示例没有起始值的 reduce(),由于可能没有足够的元素,返回的是 Optional,请留意这个区别。更多内容查看: IBM:Java 8 中的 Streams API 详解
Parallel Streams(并行流)
前面提到过Stream有串行和并行两种,串行Stream上的操作是在一个线程中依次完成,而并行Stream则是在多个线程上同时执行。
下面的例子展示了是如何通过并行Stream来提升性能:
首先我们创建一个没有重复元素的大表:
int max = 1000000;
List<String> values = new ArrayList<>(max);
for (int i = 0; i < max; i++) {
UUID uuid = UUID.randomUUID();
values.add(uuid.toString());
}
我们分别用串行和并行两种方式对其进行排序,最后看看所用时间的对比。
Sequential Sort(串行排序)
//串行排序
long t0 = System.nanoTime();
long count = values.stream().sorted().count();
System.out.println(count);
long t1 = System.nanoTime();
long millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0);
System.out.println(String.format("sequential sort took: %d ms", millis));
//结果
1000000
sequential sort took: 709 ms//串行排序所用的时间
Parallel Sort(并行排序)
//并行排序
long t0 = System.nanoTime();
long count = values.parallelStream().sorted().count();
System.out.println(count);
long t1 = System.nanoTime();
long millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0);
System.out.println(String.format("parallel sort took: %d ms", millis));
//结果
1000000
parallel sort took: 475 ms//串行排序所用的时间
上面两个代码几乎是一样的,但是并行版的快了 50% 左右,唯一需要做的改动就是将 stream() 改为parallelStream()。
Maps
前面提到过,Map 类型不支持 streams,不过Map提供了一些新的有用的方法来处理一些日常任务。Map接口本身没有可用的 stream()方法,但是你可以在键,值上创建专门的流或者通过 map.keySet().stream(),map.values().stream()和map.entrySet().stream()。
此外,Maps 支持各种新的和有用的方法来执行常见任务。
Map<Integer, String> map = new HashMap<>();
for (int i = 0; i < 10; i++) {
map.putIfAbsent(i, "val" + i);
}
map.forEach((id, val) -> System.out.println(val));//val0 val1 val2 val3 val4 val5 val6 val7 val8 val9
putIfAbsent 阻止我们在null检查时写入额外的代码;forEach接受一个 consumer 来对 map 中的每个元素操作。
此示例显示如何使用函数在 map 上计算代码:
map.computeIfPresent(3, (num, val) -> val + num);
map.get(3); // val33
map.computeIfPresent(9, (num, val) -> null);
map.containsKey(9); // false
map.computeIfAbsent(23, num -> "val" + num);
map.containsKey(23); // true
map.computeIfAbsent(3, num -> "bam");
map.get(3); // val33
接下来展示如何在Map里删除一个键值全都匹配的项:
map.remove(3, "val3");
map.get(3); // val33
map.remove(3, "val33");
map.get(3); // null
另外一个有用的方法:
map.getOrDefault(42, "not found"); // not found
对Map的元素做合并也变得很容易了:
map.merge(9, "val9", (value, newValue) -> value.concat(newValue));
map.get(9); // val9
map.merge(9, "concat", (value, newValue) -> value.concat(newValue));
map.get(9); // val9concat
Merge 做的事情是如果键名不存在则插入,否则则对原键对应的值做合并操作并重新插入到map中。
Date API(日期相关API)
Java 8在 java.time 包下包含一个全新的日期和时间API。新的Date API与Joda-Time库相似,但它们不一样。以下示例涵盖了此新 API 的最重要部分。译者对这部分内容参考相关书籍做了大部分修改。
译者注(总结):
- Clock 类提供了访问当前日期和时间的方法,Clock 是时区敏感的,可以用来取代
System.currentTimeMillis()来获取当前的微秒数。某一个特定的时间点也可以使用Instant类来表示,Instant类也可以用来创建旧版本的java.util.Date对象。 - 在新API中时区使用 ZoneId 来表示。时区可以很方便的使用静态方法of来获取到。 抽象类
ZoneId(在java.time包中)表示一个区域标识符。 它有一个名为getAvailableZoneIds的静态方法,它返回所有区域标识符。 - jdk1.8中新增了 LocalDate 与 LocalDateTime等类来解决日期处理方法,同时引入了一个新的类DateTimeFormatter 来解决日期格式化问题。可以使用Instant代替 Date,LocalDateTime代替 Calendar,DateTimeFormatter 代替 SimpleDateFormat。
Clock
Clock 类提供了访问当前日期和时间的方法,Clock 是时区敏感的,可以用来取代 System.currentTimeMillis() 来获取当前的微秒数。某一个特定的时间点也可以使用 Instant 类来表示,Instant 类也可以用来创建旧版本的java.util.Date 对象。
Clock clock = Clock.systemDefaultZone();
long millis = clock.millis();
System.out.println(millis);//1552379579043
Instant instant = clock.instant();
System.out.println(instant);
Date legacyDate = Date.from(instant); //2019-03-12T08:46:42.588Z
System.out.println(legacyDate);//Tue Mar 12 16:32:59 CST 2019
Timezones(时区)
在新API中时区使用 ZoneId 来表示。时区可以很方便的使用静态方法of来获取到。 抽象类ZoneId(在java.time包中)表示一个区域标识符。 它有一个名为getAvailableZoneIds的静态方法,它返回所有区域标识符。
//输出所有区域标识符
System.out.println(ZoneId.getAvailableZoneIds());
ZoneId zone1 = ZoneId.of("Europe/Berlin");
ZoneId zone2 = ZoneId.of("Brazil/East");
System.out.println(zone1.getRules());// ZoneRules[currentStandardOffset=+01:00]
System.out.println(zone2.getRules());// ZoneRules[currentStandardOffset=-03:00]
LocalTime(本地时间)
LocalTime 定义了一个没有时区信息的时间,例如 晚上10点或者 17:30:15。下面的例子使用前面代码创建的时区创建了两个本地时间。之后比较时间并以小时和分钟为单位计算两个时间的时间差:
LocalTime now1 = LocalTime.now(zone1);
LocalTime now2 = LocalTime.now(zone2);
System.out.println(now1.isBefore(now2)); // false
long hoursBetween = ChronoUnit.HOURS.between(now1, now2);
long minutesBetween = ChronoUnit.MINUTES.between(now1, now2);
System.out.println(hoursBetween); // -3
System.out.println(minutesBetween); // -239
LocalTime 提供了多种工厂方法来简化对象的创建,包括解析时间字符串.
LocalTime late = LocalTime.of(23, 59, 59);
System.out.println(late); // 23:59:59
DateTimeFormatter germanFormatter =
DateTimeFormatter
.ofLocalizedTime(FormatStyle.SHORT)
.withLocale(Locale.GERMAN);
LocalTime leetTime = LocalTime.parse("13:37", germanFormatter);
System.out.println(leetTime); // 13:37
LocalDate(本地日期)
LocalDate 表示了一个确切的日期,比如 2014-03-11。该对象值是不可变的,用起来和LocalTime基本一致。下面的例子展示了如何给Date对象加减天/月/年。另外要注意的是这些对象是不可变的,操作返回的总是一个新实例。
LocalDate today = LocalDate.now();//获取现在的日期
System.out.println("今天的日期: "+today);//2019-03-12
LocalDate tomorrow = today.plus(1, ChronoUnit.DAYS);
System.out.println("明天的日期: "+tomorrow);//2019-03-13
LocalDate yesterday = tomorrow.minusDays(2);
System.out.println("昨天的日期: "+yesterday);//2019-03-11
LocalDate independenceDay = LocalDate.of(2019, Month.MARCH, 12);
DayOfWeek dayOfWeek = independenceDay.getDayOfWeek();
System.out.println("今天是周几:"+dayOfWeek);//TUESDAY
从字符串解析一个 LocalDate 类型和解析 LocalTime 一样简单,下面是使用 DateTimeFormatter 解析字符串的例子:
String str1 = "2014==04==12 01时06分09秒";
// 根据需要解析的日期、时间字符串定义解析所用的格式器
DateTimeFormatter fomatter1 = DateTimeFormatter
.ofPattern("yyyy==MM==dd HH时mm分ss秒");
LocalDateTime dt1 = LocalDateTime.parse(str1, fomatter1);
System.out.println(dt1); // 输出 2014-04-12T01:06:09
String str2 = "2014$$$四月$$$13 20小时";
DateTimeFormatter fomatter2 = DateTimeFormatter
.ofPattern("yyy$$$MMM$$$dd HH小时");
LocalDateTime dt2 = LocalDateTime.parse(str2, fomatter2);
System.out.println(dt2); // 输出 2014-04-13T20:00
再来看一个使用 DateTimeFormatter 格式化日期的示例
LocalDateTime rightNow=LocalDateTime.now();
String date=DateTimeFormatter.ISO_LOCAL_DATE_TIME.format(rightNow);
System.out.println(date);//2019-03-12T16:26:48.29
DateTimeFormatter formatter=DateTimeFormatter.ofPattern("YYYY-MM-dd HH:mm:ss");
System.out.println(formatter.format(rightNow));//2019-03-12 16:26:48
LocalDateTime(本地日期时间)
LocalDateTime 同时表示了时间和日期,相当于前两节内容合并到一个对象上了。LocalDateTime 和 LocalTime还有 LocalDate 一样,都是不可变的。LocalDateTime 提供了一些能访问具体字段的方法。
LocalDateTime sylvester = LocalDateTime.of(2014, Month.DECEMBER, 31, 23, 59, 59);
DayOfWeek dayOfWeek = sylvester.getDayOfWeek();
System.out.println(dayOfWeek); // WEDNESDAY
Month month = sylvester.getMonth();
System.out.println(month); // DECEMBER
long minuteOfDay = sylvester.getLong(ChronoField.MINUTE_OF_DAY);
System.out.println(minuteOfDay); // 1439
只要附加上时区信息,就可以将其转换为一个时间点Instant对象,Instant时间点对象可以很容易的转换为老式的java.util.Date。
Instant instant = sylvester
.atZone(ZoneId.systemDefault())
.toInstant();
Date legacyDate = Date.from(instant);
System.out.println(legacyDate); // Wed Dec 31 23:59:59 CET 2014
格式化LocalDateTime和格式化时间和日期一样的,除了使用预定义好的格式外,我们也可以自己定义格式:
DateTimeFormatter formatter =
DateTimeFormatter
.ofPattern("MMM dd, yyyy - HH:mm");
LocalDateTime parsed = LocalDateTime.parse("Nov 03, 2014 - 07:13", formatter);
String string = formatter.format(parsed);
System.out.println(string); // Nov 03, 2014 - 07:13
和java.text.NumberFormat不一样的是新版的DateTimeFormatter是不可变的,所以它是线程安全的。 关于时间日期格式的详细信息在这里。
Annotations(注解)
在Java 8中支持多重注解了,先看个例子来理解一下是什么意思。 首先定义一个包装类Hints注解用来放置一组具体的Hint注解:
@interface Hints {
Hint[] value();
}
@Repeatable(Hints.class)
@interface Hint {
String value();
}
Java 8允许我们把同一个类型的注解使用多次,只需要给该注解标注一下@Repeatable即可。
例 1: 使用包装类当容器来存多个注解(老方法)
@Hints({@Hint("hint1"), @Hint("hint2")})
class Person {}
例 2:使用多重注解(新方法)
@Hint("hint1")
@Hint("hint2")
class Person {}
第二个例子里java编译器会隐性的帮你定义好@Hints注解,了解这一点有助于你用反射来获取这些信息:
Hint hint = Person.class.getAnnotation(Hint.class);
System.out.println(hint); // null
Hints hints1 = Person.class.getAnnotation(Hints.class);
System.out.println(hints1.value().length); // 2
Hint[] hints2 = Person.class.getAnnotationsByType(Hint.class);
System.out.println(hints2.length); // 2
即便我们没有在 Person类上定义 @Hints注解,我们还是可以通过 getAnnotation(Hints.class) 来获取 @Hints注解,更加方便的方法是使用 getAnnotationsByType 可以直接获取到所有的@Hint注解。 另外Java 8的注解还增加到两种新的target上了:
@Target({ElementType.TYPE_PARAMETER, ElementType.TYPE_USE})
@interface MyAnnotation {}
三. Java9-14新特性
Java9
发布于 2017 年 9 月 21 日 。作为 Java8 之后 3 年半才发布的新版本,Java 9 带 来了很多重大的变化其中最重要的改动是 Java 平台模块系统的引入,其他还有诸如集合、Stream 流
Java 平台模块系统
Java 平台模块系统,也就是 Project Jigsaw,把模块化开发实践引入到了 Java 平台中。在引入了模块系统之后,JDK 被重新组织成 94 个模块。Java 应用可以通过新增的 jlink 工具,创建出只包含所依赖的 JDK 模块的自定义运行时镜像。这样可以极大的减少 Java 运行时环境的大小。
Java 9 模块的重要特征是在其工件(artifact)的根目录中包含了一个描述模块的 module-info.class 文 件。 工件的格式可以是传统的 JAR 文件或是 Java 9 新增的 JMOD 文件。
Jshell
jshell 是 Java 9 新增的一个实用工具。为 Java 提供了类似于 Python 的实时命令行交互工具。
在 Jshell 中可以直接输入表达式并查看其执行结果
集合、Stream 和 Optional
- 增加 了
List.of()、Set.of()、Map.of()和Map.ofEntries()等工厂方法来创建不可变集合,比如List.of("Java", "C++");、Map.of("Java", 1, "C++", 2);(这部分内容有点参考 Guava 的味道) Stream中增加了新的方法ofNullable、dropWhile、takeWhile和iterate方法。Collectors中增加了新的方法filtering和flatMappingOptional类中新增了ifPresentOrElse、or和stream等方法
进程 API
Java 9 增加了 ProcessHandle 接口,可以对原生进程进行管理,尤其适合于管理长时间运行的进程
平台日志 API 和服务
Java 9 允许为 JDK 和应用配置同样的日志实现。新增了 System.LoggerFinder 用来管理 JDK 使 用的日志记录器实现。JVM 在运行时只有一个系统范围的 LoggerFinder 实例。
我们可以通过添加自己的 System.LoggerFinder 实现来让 JDK 和应用使用 SLF4J 等其他日志记录框架。
反应式流 ( Reactive Streams )
- 在 Java9 中的
java.util.concurrent.Flow类中新增了反应式流规范的核心接口 - Flow 中包含了
Flow.Publisher、Flow.Subscriber、Flow.Subscription和Flow.Processor等 4 个核心接口。Java 9 还提供了SubmissionPublisher作为Flow.Publisher的一个实现。
变量句柄
- 变量句柄是一个变量或一组变量的引用,包括静态域,非静态域,数组元素和堆外数据结构中的组成部分等
- 变量句柄的含义类似于已有的方法句柄
MethodHandle - 由 Java 类
java.lang.invoke.VarHandle来表示,可以使用类java.lang.invoke.MethodHandles.Lookup中的静态工厂方法来创建VarHandle对 象
改进方法句柄(Method Handle)
- 方法句柄从 Java7 开始引入,Java9 在类
java.lang.invoke.MethodHandles中新增了更多的静态方法来创建不同类型的方法句柄
其它新特性
- 接口私有方法 :Java 9 允许在接口中使用私有方法
- try-with-resources 增强 :在 try-with-resources 语句中可以使用 effectively-final 变量(什么是 effectively-final 变量,见这篇文章 http://ilkinulas.github.io/programming/java/2016/03/27/effectively-final-java.html)
- 类
CompletableFuture中增加了几个新的方法(completeAsync,orTimeout等) - Nashorn 引擎的增强 :Nashorn 从 Java8 开始引入的 JavaScript 引擎,Java9 对 Nashorn 做了些增强,实现了一些 ES6 的新特性
- I/O 流的新特性 :增加了新的方法来读取和复制 InputStream 中包含的数据
- 改进应用的安全性能 :Java 9 新增了 4 个 SHA- 3 哈希算法,SHA3-224、SHA3-256、SHA3-384 和 S HA3-512
- ......
Java10
发布于 2018 年 3 月 20 日,最知名的特性应该是 var 关键字(局部变量类型推断)的引入了,其他还有垃圾收集器改善、GC 改进、性能提升、线程管控等一批新特性
var 关键字
- 介绍 :提供了 var 关键字声明局部变量:
var list = new ArrayList(); // ArrayList - 局限性 :只能用于带有构造器的局部变量和 for 循环中
Guide 哥:实际上 Lombok 早就体用了一个类似的关键字,使用它可以简化代码,但是可能会降低程序的易读性、可维护性。一般情况下,我个人都不太推荐使用。
不可变集合
list,set,map 提供了静态方法copyOf()返回入参集合的一个不可变拷贝(以下为 JDK 的源码)
static <E> List<E> copyOf(Collection<? extends E> coll) {
return ImmutableCollections.listCopy(coll);
}
java.util.stream.Collectors中新增了静态方法,用于将流中的元素收集为不可变的集合
Optional
- 新增了
orElseThrow()方法来在没有值时抛出异常
并行全垃圾回收器 G1
从 Java9 开始 G1 就了默认的垃圾回收器,G1 是以一种低延时的垃圾回收器来设计的,旨在避免进行 Full GC,但是 Java9 的 G1 的 FullGC 依然是使用单线程去完成标记清除算法,这可能会导致垃圾回收期在无法回收内存的时候触发 Full GC。
为了最大限度地减少 Full GC 造成的应用停顿的影响,从 Java10 开始,G1 的 FullGC 改为并行的标记清除算法,同时会使用与年轻代回收和混合回收相同的并行工作线程数量,从而减少了 Full GC 的发生,以带来更好的性能提升、更大的吞吐量。
应用程序类数据共享
在 Java 5 中就已经引入了类数据共享机制 (Class Data Sharing,简称 CDS),允许将一组类预处理为共享归档文件,以便在运行时能够进行内存映射以减少 Java 程序的启动时间,当多个 Java 虚拟机(JVM)共享相同的归档文件时,还可以减少动态内存的占用量,同时减少多个虚拟机在同一个物理或虚拟的机器上运行时的资源占用
Java 10 在现有的 CDS 功能基础上再次拓展,以允许应用类放置在共享存档中。CDS 特性在原来的 bootstrap 类基础之上,扩展加入了应用类的 CDS (Application Class-Data Sharing) 支持。其原理为:在启动时记录加载类的过程,写入到文本文件中,再次启动时直接读取此启动文本并加载。设想如果应用环境没有大的变化,启动速度就会得到提升
其他特性
- 线程-局部管控:Java 10 中线程管控引入 JVM 安全点的概念,将允许在不运行全局 JVM 安全点的情况下实现线程回调,由线程本身或者 JVM 线程来执行,同时保持线程处于阻塞状态,这种方式使得停止单个线程变成可能,而不是只能启用或停止所有线程
- 备用存储装置上的堆分配:Java 10 中将使得 JVM 能够使用适用于不同类型的存储机制的堆,在可选内存设备上进行堆内存分配
- 统一的垃圾回收接口:Java 10 中,hotspot/gc 代码实现方面,引入一个干净的 GC 接口,改进不同 GC 源代码的隔离性,多个 GC 之间共享的实现细节代码应该存在于辅助类中。统一垃圾回收接口的主要原因是:让垃圾回收器(GC)这部分代码更加整洁,便于新人上手开发,便于后续排查相关问题。
Java11
Java11 于 2018 年 9 月 25 日正式发布,这是很重要的一个版本!Java 11 和 2017 年 9 月份发布的 Java 9 以及 2018 年 3 月份发布的 Java 10 相比,其最大的区别就是:在长期支持(Long-Term-Support)方面,Oracle 表示会对 Java 11 提供大力支持,这一支持将会持续至 2026 年 9 月。这是据 Java 8 以后支持的首个长期版本。

字符串加强
Java 11 增加了一系列的字符串处理方法,如以下所示。
Guide 哥:说白点就是多了层封装,JDK 开发组的人没少看市面上常见的工具类框架啊!
//判断字符串是否为空
" ".isBlank();//true
//去除字符串首尾空格
" Java ".strip();// "Java"
//去除字符串首部空格
" Java ".stripLeading(); // "Java "
//去除字符串尾部空格
" Java ".stripTrailing(); // " Java"
//重复字符串多少次
"Java".repeat(3); // "JavaJavaJava"
//返回由行终止符分隔的字符串集合。
"A\nB\nC".lines().count(); // 3
"A\nB\nC".lines().collect(Collectors.toList());
ZGC:可伸缩低延迟垃圾收集器
ZGC 即 Z Garbage Collector,是一个可伸缩的、低延迟的垃圾收集器。
ZGC 主要为了满足如下目标进行设计:
- GC 停顿时间不超过 10ms
- 即能处理几百 MB 的小堆,也能处理几个 TB 的大堆
- 应用吞吐能力不会下降超过 15%(与 G1 回收算法相比)
- 方便在此基础上引入新的 GC 特性和利用 colord
- 针以及 Load barriers 优化奠定基础
- 当前只支持 Linux/x64 位平台
ZGC 目前 处在实验阶段,只支持 Linux/x64 平台
标准 HTTP Client 升级
Java 11 对 Java 9 中引入并在 Java 10 中进行了更新的 Http Client API 进行了标准化,在前两个版本中进行孵化的同时,Http Client 几乎被完全重写,并且现在完全支持异步非阻塞。
并且,Java11 中,Http Client 的包名由 jdk.incubator.http 改为java.net.http,该 API 通过 CompleteableFuture 提供非阻塞请求和响应语义。
使用起来也很简单,如下:
var request = HttpRequest.newBuilder()
.uri(URI.create("https://javastack.cn"))
.GET()
.build();
var client = HttpClient.newHttpClient();
// 同步
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
System.out.println(response.body());
// 异步
client.sendAsync(request, HttpResponse.BodyHandlers.ofString())
.thenApply(HttpResponse::body)
.thenAccept(System.out::println);
简化启动单个源代码文件的方法
- 增强了 Java 启动器,使其能够运行单一文件的 Java 源代码。此功能允许使用 Java 解释器直接执行 Java 源代码。源代码在内存中编译,然后由解释器执行。唯一的约束在于所有相关的类必须定义在同一个 Java 文件中
- 对于 Java 初学者并希望尝试简单程序的人特别有用,并且能和 jshell 一起使用
- 一定能程度上增强了使用 Java 来写脚本程序的能力
用于 Lambda 参数的局部变量语法
- 从 Java 10 开始,便引入了局部变量类型推断这一关键特性。类型推断允许使用关键字 var 作为局部变量的类型而不是实际类型,编译器根据分配给变量的值推断出类型
- Java 10 中对 var 关键字存在几个限制
- 只能用于局部变量上
- 声明时必须初始化
- 不能用作方法参数
- 不能在 Lambda 表达式中使用
- Java11 开始允许开发者在 Lambda 表达式中使用 var 进行参数声明
其他特性
- 新的垃圾回收器 Epsilon,一个完全消极的 GC 实现,分配有限的内存资源,最大限度的降低内存占用和内存吞吐延迟时间
- 低开销的 Heap Profiling:Java 11 中提供一种低开销的 Java 堆分配采样方法,能够得到堆分配的 Java 对象信息,并且能够通过 JVMTI 访问堆信息
- TLS1.3 协议:Java 11 中包含了传输层安全性(TLS)1.3 规范(RFC 8446)的实现,替换了之前版本中包含的 TLS,包括 TLS 1.2,同时还改进了其他 TLS 功能,例如 OCSP 装订扩展(RFC 6066,RFC 6961),以及会话散列和扩展主密钥扩展(RFC 7627),在安全性和性能方面也做了很多提升
- 飞行记录器:飞行记录器之前是商业版 JDK 的一项分析工具,但在 Java 11 中,其代码被包含到公开代码库中,这样所有人都能使用该功能了
Java12
增强 Switch
传统的 switch 语法存在容易漏写 break 的问题,而且从代码整洁性层面来看,多个 break 本质也是一种重复
Java12 提供了 swtich 表达式,使用类似 lambda 语法条件匹配成功后的执行块,不需要多写 break
作为预览特性加入,需要在
javac编译和java运行时增加参数--enable-previewswitch (day) {
case MONDAY, FRIDAY, SUNDAY -> System.out.println(6);
case TUESDAY -> System.out.println(7);
case THURSDAY, SATURDAY -> System.out.println(8);
case WEDNESDAY -> System.out.println(9);
}
数字格式化工具类
NumberFormat新增了对复杂的数字进行格式化的支持NumberFormat fmt = NumberFormat.getCompactNumberInstance(Locale.US, NumberFormat.Style.SHORT);
String result = fmt.format(1000);
System.out.println(result); // 输出为 1K,计算工资是多少K更方便了。。。
Shenandoah GC
- Redhat 主导开发的 Pauseless GC 实现,主要目标是 99.9% 的暂停小于 10ms,暂停与堆大小无关等
- 和 Java11 开源的 ZGC 相比(需要升级到 JDK11 才能使用),Shenandoah GC 有稳定的 JDK8u 版本,在 Java8 占据主要市场份额的今天有更大的可落地性
G1 收集器提升
- Java12 为默认的垃圾收集器 G1 带来了两项更新:
- 可中止的混合收集集合:JEP344 的实现,为了达到用户提供的停顿时间目标,JEP 344 通过把要被回收的区域集(混合收集集合)拆分为强制和可选部分,使 G1 垃圾回收器能中止垃圾回收过程。 G1 可以中止可选部分的回收以达到停顿时间目标
- 及时返回未使用的已分配内存:JEP346 的实现,增强 G1 GC,以便在空闲时自动将 Java 堆内存返回给操作系统
Java13
引入 yield 关键字到 Switch 中
Switch表达式中就多了一个关键字用于跳出Switch块的关键字yield,主要用于返回一个值yield和return的区别在于:return会直接跳出当前循环或者方法,而yield只会跳出当前Switch块,同时在使用yield时,需要有default条件private static String descLanguage(String name) {
return switch (name) {
case "Java": yield "object-oriented, platform independent and secured";
case "Ruby": yield "a programmer's best friend";
default: yield name +" is a good language";
};
}
文本块
解决 Java 定义多行字符串时只能通过换行转义或者换行连接符来变通支持的问题,引入三重双引号来定义多行文本
两个
"""中间的任何内容都会被解释为字符串的一部分,包括换行符String json ="{\n" +
" \"name\":\"mkyong\",\n" +
" \"age\":38\n" +
"}\n"; // 未支持文本块之前
String json = """
{
"name":"mkyong",
"age":38
}
""";
增强 ZGC 释放未使用内存
- 在 Java 11 中是实验性的引入的 ZGC 在实际的使用中存在未能主动将未使用的内存释放给操作系统的问题
- ZGC 堆由一组称为 ZPages 的堆区域组成。在 GC 周期中清空 ZPages 区域时,它们将被释放并返回到页面缓存 ZPageCache 中,此缓存中的 ZPages 按最近最少使用(LRU)的顺序,并按照大小进行组织
- 在 Java 13 中,ZGC 将向操作系统返回被标识为长时间未使用的页面,这样它们将可以被其他进程重用
SocketAPI 重构
- Java 13 为 Socket API 带来了新的底层实现方法,并且在 Java 13 中是默认使用新的 Socket 实现,使其易于发现并在排除问题同时增加可维护性
动态应用程序类-数据共享
- Java 13 中对 Java 10 中引入的 应用程序类数据共享进行了进一步的简化、改进和扩展,即:允许在 Java 应用程序执行结束时动态进行类归档,具体能够被归档的类包括:所有已被加载,但不属于默认基层 CDS 的应用程序类和引用类库中的类
Java14
record 关键字
简化数据类的定义方式,使用 record 代替 class 定义的类,只需要声明属性,就可以在获得属性的访问方法,以及 toString,hashCode,equals 方法
类似于使用 Class 定义类,同时使用了 lomobok 插件,并打上了
@Getter,@ToString,@EqualsAndHashCode注解作为预览特性引入
/**
* 这个类具有两个特征
* 1. 所有成员属性都是final
* 2. 全部方法由构造方法,和两个成员属性访问器组成(共三个)
* 那么这种类就很适合使用record来声明
*/
final class Rectangle implements Shape {
final double length;
final double width; public Rectangle(double length, double width) {
this.length = length;
this.width = width;
} double length() { return length; }
double width() { return width; }
}
/**
* 1. 使用record声明的类会自动拥有上面类中的三个方法
* 2. 在这基础上还附赠了equals(),hashCode()方法以及toString()方法
* 3. toString方法中包括所有成员属性的字符串表示形式及其名称
*/
record Rectangle(float length, float width) { }
空指针异常精准提示
通过 JVM 参数中添加
-XX:+ShowCodeDetailsInExceptionMessages,可以在空指针异常中获取更为详细的调用信息,更快的定位和解决问题a.b.c.i = 99; // 假设这段代码会发生空指针
Exception in thread "main" java.lang.NullPointerException:
Cannot read field 'c' because 'a.b' is null.
at Prog.main(Prog.java:5) // 增加参数后提示的异常中很明确的告知了哪里为空导致
switch 的增强终于转正
- JDK12 引入的 switch(预览特性)在 JDK14 变为正式版本,不需要增加参数来启用,直接在 JDK14 中就能使用
- 主要是用
->来替代以前的:+break;另外就是提供了 yield 来在 block 中返回值
Before Java 14
switch (day) {
case MONDAY:
case FRIDAY:
case SUNDAY:
System.out.println(6);
break;
case TUESDAY:
System.out.println(7);
break;
case THURSDAY:
case SATURDAY:
System.out.println(8);
break;
case WEDNESDAY:
System.out.println(9);
break;
}
Java 14 enhancements
switch (day) {
case MONDAY, FRIDAY, SUNDAY -> System.out.println(6);
case TUESDAY -> System.out.println(7);
case THURSDAY, SATURDAY -> System.out.println(8);
case WEDNESDAY -> System.out.println(9);
}
instanceof 增强
- instanceof 主要在类型强转前探测对象的具体类型,然后执行具体的强转
- 新版的 instanceof 可以在判断的是否属于具体的类型同时完成转换
Object obj = "我是字符串";
if(obj instanceof String str){
System.out.println(str);
}
其他特性
- 从 Java11 引入的 ZGC 作为继 G1 过后的下一代 GC 算法,从支持 Linux 平台到 Java14 开始支持 MacOS 和 Window(个人感觉是终于可以在日常开发工具中先体验下 ZGC 的效果了,虽然其实 G1 也够用)
- 移除了 CMS 垃圾收集器(功成而退)
- 新增了 jpackage 工具,标配将应用打成 jar 包外,还支持不同平台的特性包,比如 linux 下的
deb和rpm,window 平台下的msi和exe
总结
关于预览特性
- 先贴一段 oracle 官网原文:
This is a preview feature, which is a feature whose design, specification, and implementation are complete, but is not permanent, which means that the feature may exist in a different form or not at all in future JDK releases. To compile and run code that contains preview features, you must specify additional command-line options. - 这是一个预览功能,该功能的设计,规格和实现是完整的,但不是永久性的,这意味着该功能可能以其他形式存在或在将来的 JDK 版本中根本不存在。 要编译和运行包含预览功能的代码,必须指定其他命令行选项。
- 就以
switch的增强为例子,从 Java12 中推出,到 Java13 中将继续增强,直到 Java14 才正式转正进入 JDK 可以放心使用,不用考虑后续 JDK 版本对其的改动或修改 - 一方面可以看出 JDK 作为标准平台在增加新特性的严谨态度,另一方面个人认为是对于预览特性应该采取审慎使用的态度。特性的设计和实现容易,但是其实际价值依然需要在使用中去验证
JVM 虚拟机优化
- 每次 Java 版本的发布都伴随着对 JVM 虚拟机的优化,包括对现有垃圾回收算法的改进,引入新的垃圾回收算法,移除老旧的不再适用于今天的垃圾回收算法等
- 整体优化的方向是高效,低时延的垃圾回收表现
- 对于日常的应用开发者可能比较关注新的语法特性,但是从一个公司角度来说,在考虑是否升级 Java 平台时更加考虑的是JVM 运行时的提升
参考信息
- IBM Developer Java9 https://www.ibm.com/developerworks/cn/java/the-new-features-of-Java-9/
- Guide to Java10 https://www.baeldung.com/java-10-overview
- Java 10 新特性介绍https://www.ibm.com/developerworks/cn/java/the-new-features-of-Java-10/index.html
- IBM Devloper Java11 https://www.ibm.com/developerworks/cn/java/the-new-features-of-Java-11/index.html
- Java 11 – Features and Comparison: https://www.geeksforgeeks.org/java-11-features-and-comparison/
- Oracle Java12 ReleaseNote https://www.oracle.com/technetwork/java/javase/12all-relnotes-5211423.html#NewFeature
- Oracle Java13 ReleaseNote https://www.oracle.com/technetwork/java/javase/13all-relnotes-5461743.html#NewFeature
- New Java13 Features https://www.baeldung.com/java-13-new-features
- Java13 新特性概述 https://www.ibm.com/developerworks/cn/java/the-new-features-of-Java-13/index.html
- Oracle Java14 record https://docs.oracle.com/en/java/javase/14/language/records.html
- java14-features https://www.techgeeknext.com/java/java14-features
java基础知识 + 常见面试题的更多相关文章
- Java基础知识常见面试题汇总第一篇
[Java面试题系列]:Java基础知识常见面试题汇总 第一篇 文中面试题从茫茫网海中精心筛选,如有错误,欢迎指正! 1.前言 参加过社招的同学都了解,进入一家公司面试开发岗位时,填写完个人信息后 ...
- 【Java面试题系列】:Java基础知识常见面试题汇总 第一篇
文中面试题从茫茫网海中精心筛选,如有错误,欢迎指正! 1.前言 参加过社招的同学都了解,进入一家公司面试开发岗位时,填写完个人信息后,一般都会让先做一份笔试题,然后公司会根据笔试题的回答结果,确定 ...
- 【Java面试题系列】:Java基础知识常见面试题汇总 第二篇
文中面试题从茫茫网海中精心筛选,如有错误,欢迎指正! 第一篇链接:[Java面试题系列]:Java基础知识常见面试题汇总 第一篇 1.JDK,JRE,JVM三者之间的联系和区别 你是否考虑过我们写的x ...
- php 基础知识 常见面试题
1.echo.print_r.print.var_dump之间的区别 * echo.print是php语句,var_dump和print_r是函数 * echo 输出一个或多个字符串,中间以逗号隔开, ...
- 【搞定 Java 并发面试】面试最常问的 Java 并发进阶常见面试题总结!
本文为 SnailClimb 的原创,目前已经收录自我开源的 JavaGuide 中(61.5 k Star![Java学习+面试指南] 一份涵盖大部分Java程序员所需要掌握的核心知识.觉得内容不错 ...
- Java集合框架常见面试题
点击关注公众号及时获取笔主最新更新文章,并可免费领取本文档配套的<Java面试突击>以及Java工程师必备学习资源. 剖析面试最常见问题之Java基础知识 说说List,Set,Map三者 ...
- 2019年Java后端工程师常见面试题和感想
来新公司有5个月了,从第二个月开始就参与公司后端工程师的面试工作了,包括校招在内,面试超过100个(包括40个校招的终面)应聘者了,应聘者中有超过10年的技术经理,有6年以上的高级开发,有3到5年的中 ...
- Java 并发进阶常见面试题总结
声明:本文内容完全来自网络,转自GitHub->JavaGuide(https://github.com/Snailclimb/JavaGuide),致谢 1. synchronize ...
- 全网阅读过20k的Java集合框架常见面试题总结!
本文为 SnailClimb 的原创,目前已经收录自我开源的 JavaGuide 中(61.5 k Star![Java学习+面试指南] 一份涵盖大部分Java程序员所需要掌握的核心知识.欢迎 Sta ...
随机推荐
- Codeforces Global Round 4 B. WOW Factor (前缀和,数学)
题意:找出序列中有多少子序列是\(wow\),但是\(w\)只能用\(vv\)来表示. 题解:我们分别记录连续的\(v\)和\(o\)的个数,用\(v1\)和\(v2\)存,这里要注意前导\(o\)不 ...
- Educational Codeforces Round 91 (Rated for Div. 2) C. Create The Teams (模拟)
题意:有\(n\)个队员,每个队友都有一个能力值,构造队伍,要求队伍人数*队伍中最低能力值不小于\(x\),求能构造的最大队伍数. 题解:大水题,排个序,倒着模拟就行了. 代码: int t; int ...
- (数据科学学习手札106)Python+Dash快速web应用开发——回调交互篇(下)
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 这是我的系列教程Python+Dash快速web ...
- web 存储方式汇总:Cookies,Session, Web SQL; Web Storage(LocalStorage ,SessionStorage),IndexedDB,Application Cache,Cache Storage
1 1 1 web 存储方式汇总: 旧的方式: Cookies; Session; Web SQL; 新的方式 HTML5 : Web Storage(LocalStorage ,SessionSto ...
- CSS3 优先级
CSS3 优先级 https://developer.mozilla.org/zh-CN/docs/Web/CSS/Specificity 优先级 在本文章中 概念 优先级是如何计算的? 选择器 ...
- UIKit and SwiftUI
UIKit and SwiftUI Live Preview Try Again or Resume refs xgqfrms 2012-2020 www.cnblogs.com 发布文章使用:只允许 ...
- Nuxt.js SSR Optimizing Tips
Nuxt.js SSR Optimizing Tips 性能优化 FP 首次绘制时间 FCP 首次渲染时间 FMP 首屏渲染时间 FI refs https://vueschool.io/articl ...
- CSS style color all in one
CSS style color all in one https://developer.mozilla.org/en-US/docs/Web/CSS/color_value /* Hexadecim ...
- website SEO all in one
website SEO all in one SEO 指标量化 https://www.similarweb.com/zh/top-websites/ demo https://www.similar ...
- Redux Middleware All in One
Redux Middleware All in One https://redux.js.org/advanced/middleware https://redux.js.org/api/applym ...