JDK学习---深入理解java中的LinkedList
本文参考资料:
1、《大话数据结构》
2、http://blog.csdn.net/jzhf2012/article/details/8540543
3、http://blog.csdn.net/jzhf2012/article/details/8540410
4、http://www.cnblogs.com/ITtangtang/p/3948610.html
5、http://blog.csdn.net/zw0283/article/details/51132161
本来在分析完HashSet、HashMap之后,我想紧跟着分析TreeMap以及TreeSet的,但是当我读过源码以后,我就放弃了这个想法。并不是源码有多难,而是TreeMap涉及到的数据结构中的树结构,而我之前一直分析的都是线性结构,而且ArrayList、LinkedList也是线性结构,并且还没有分析。因此,我还是决定按部就班的进行,先把线性表全部分析完了,再去分析TreeMap。
ArrayList底层源码基本逻辑结构很简单,在《JDK学习---深入理解java中的String》一文中基本已经分析完毕,唯一不同的是String的底层数组不可变,而在ArrayList的底层Object[] 数组中,允许数组增、删、该操作,并且支持数组的动态扩容,这些东西不难,相信读者能很轻松搞明白这些知识,我就不再说明了。
本文我将重点的说明一下LinkedList知识点,而LinkedList的底层是一个双向链表结构,因此我会在解析源码之前,穿插一些双向链表的知识,然后结合代码进行分析。我不喜欢很空洞的单独去说数据结构,一是因为本人水平有限说不清楚,二是因为我觉得理论需要结合代码,这样分析更加的直观一些。如果读者想要仔细的了解数据结构的知识,可以去找一些书籍详细研读。
双向链表
《JDK学习---深入理解java中的String》一文介绍了数据结构的大体架构,《JDK学习---深入理解java中的HashMap、HashSet底层实现》介绍了线性表的单链表。
本文将继续介绍数据结构的双向链表。
双向链表:在单链表的每个节点中,再设置一个指向其前前驱节点的指针域 【DP】
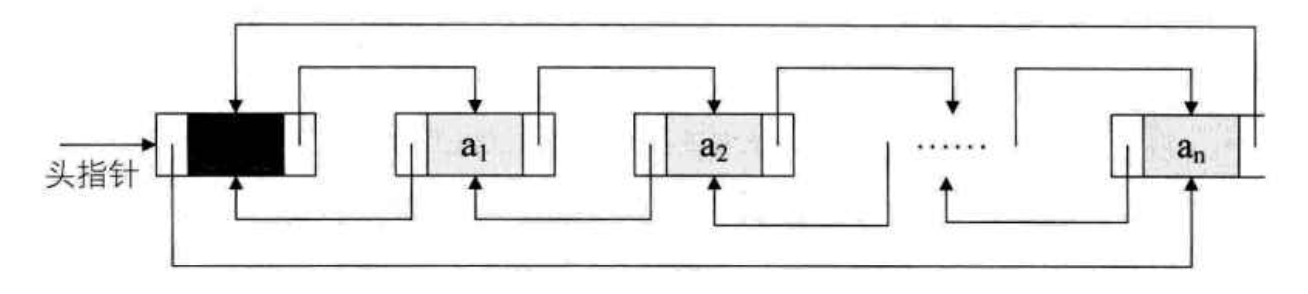
既然是双向链表,那么对于链表中的某一个节点(p),它的后继的前驱,以及前驱的后继,其实都是这个节点本身:
p->next->prior = p = p->next-prior
双链表的插入操作并不复杂,但是顺序很重要,千万不能写错。
假设,我们现在有一个节点s,它存储的元素为e,现在要将节点s插入到节点p和p->next之间,需要严格的遵守插入的先后顺序,如下图:
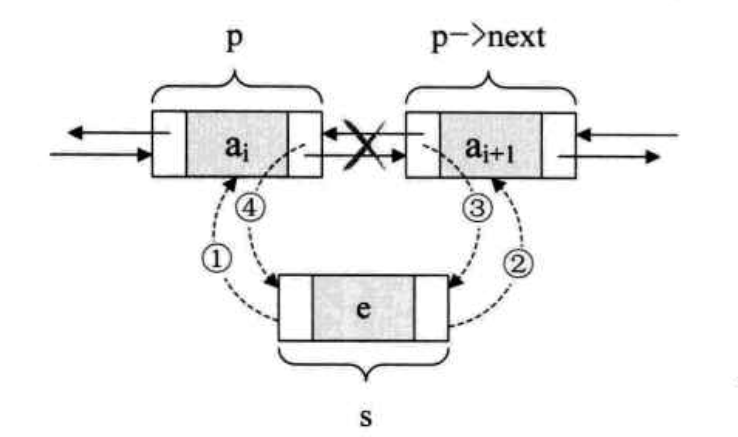
s -> prior = p; //把p赋值给s的前驱,如图中1
s -> next = p -> next; //把p -> next 赋值给s的后继,如图中2
p -> next -> prior = s; //把s 赋值给 p->next的前驱 ,如图中3
p -> next =s; //把s 赋值给p 的后继,如图中4
关键在于它们的顺序,由于第2、3步都用到了p->next , 如果第4步先执行,则会使得p->next提前变成了s,使得插入工作完成不了。口诀是:先搞定s的前驱和后继,再搞定后继的前驱,最后解决前节点的后继。
如果插入操作理解了,那么删除操作也就简单了。
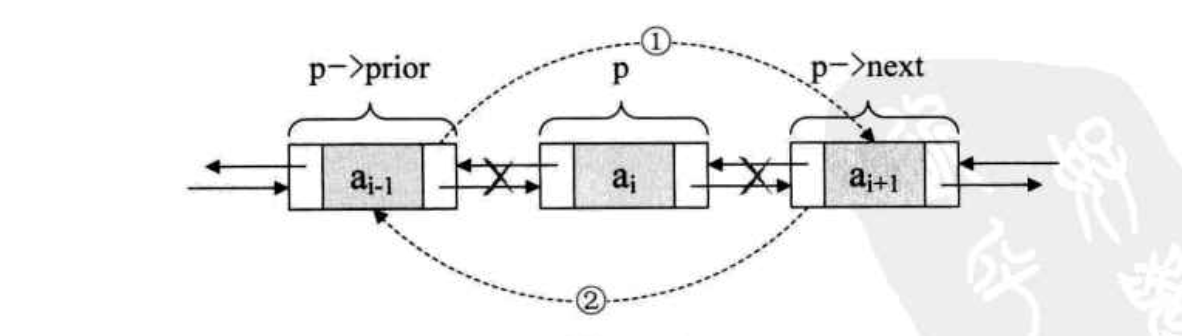
p ->prior -> next = p -> next; //把p ->next赋值给p->prior的后继,如图中1
p ->next -> prior = p ->prior; //把 p ->prior赋值给p ->next 的前驱,如图中2
free(p); //释放节点p
总结:双向链表对于单链表而言,增、删操作要复杂一些,毕竟多了一个prior指针域,所以操作需要格外小心。另外,由于每个节点都需要记录两份指针,空间相对而言也占用略多一些。不过,由于它良好的对称性,使得对某个节点的增、删操作带来了方便。说白了,就是用空间换时间。
LinkedList中的双向链表:
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
//节点元素
Node(Node<E> prev, E element, Node<E> next) {
//当前节点的值
this.item = element;
//当前节点的后继指针
this.next = next;
//当前节点的前驱指针
this.prev = prev;
}
}
链表的节点插入操作:
说实话,当我介绍完上面的双链表信息以后,我感觉我已经把LinkedList介绍完了,因为LinkedList的底层源码确实太简单了,或者说是太规矩了,规矩到完完全全的遵守链表的插入和删除操作的思路,一点点变化都没有,甚至比使用单链表+数组实现的HashMap还要简单。可能我说再多,都不如代码来的实在,下面进行代码分析:
add(E e) 方法:
public boolean add(E e) {
linkLast(e);
return true;
}
这个方法没有逻辑判断,只是简单的调用linkLast(e)方法,下面继续跟进
void linkLast(E e) {
final Node<E> l = last;
//构造需要插入链表的节点元素,因为此方法是固定往链表尾部追加节点,因此每个将要插入的节点都不存后继节点,或者说后继节点都为null;
//此处在创建节点的时候,只是制定了当前节点的前驱以及当前节点的值域,因为后继节点为null,可以不指定后继指针域
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
//此处判断第一个节点是否存在,不存在的话直接将当前节点指定为头节点。如果存在,则将当前将要插入的节点指定给前一个节点的后继。因此是追加,这里可以省略当前节点的后继节点持有当前节点的指针
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
add(int index, E element)方法:这个方法算能够体现出双链表节点的插入功能。
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
//这个地方在上面的方法已经分析过了,比较特殊,就不再次分析了
linkLast(element);
else
linkBefore(element, node(index));
}
接下来跟进到linkBefore(element, node(index))方法中:
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
我们假设这个链表很长,我们正常的在中间插入一个节点,也就是正常的双向链表节点插入功能。还记得口诀吗?口诀是:先搞定s的前驱和后继,再搞定后继的前驱,最后解决前节点的后继。
下面根据口诀,我们对linkBefore(E e, Node<E> succ)进行解析: succ节点现在的位置,就是我们需要插入的位置,也就是说要在succ节点和它的前一个节点succ->prev中间插入当前节点信息E e。
先搞定s的前驱和后继,此通过final Node<E> newNode = new Node<>(pred, e, succ)生成的newNode不就相当于之前口诀中的s吗,而且pred和succ不就是s的前驱和后继嘛。
再搞定后继的前驱,最后解决前节点的后继 : 此处不就是通过上面的succ.prev = newNode; 以及 后面的 pred.next = newNode; 来完成的嘛。
再次强调,这样分析,上面的黄色字体已经进行了假设了,即:这个链表很长,我们正常的在中间插入一个节点,也就是正常的双向链表节点插入功能
链表的节点替换set(int index, E element) 方法:这个方法比较简单
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
链表的节点删除remove(Object o)方法:
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
//我想说明这个分支,因为链表的节点删除,肯定是要模拟正常的情况,Object o这个参数正常存在
//在这个地方,我也是有疑问的。如果链表长度为1000,而我们的o放在第998的位置上,如果是这样的话,for需要迭代998次,我完全看不出来它的删除性能高在哪里。如果非要说性能高,
//那只能勉强说还是节省了移动节点的时间吧
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
看完这个方法,好像并没有直接操作链表,下面看看unlink(Object)方法:
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
//关注此处,将前一个节点的后继直接指定当前节点的后一个节点
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
//关注此处,将当前节点的后一个节点的前驱,指向当前节点的前一个节点。这两次完全按照双链表的节点删除操作
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
下面再来看看LinkedList的查询方法:
get(int index)方法:
public E get(int index) {
//此处是判断给定的index下标是否合法
checkElementIndex(index);
return node(index).item;
}
跟进node(index)方法:
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
仔细分析一下此方法,无论是if分支,还是else分支,都涉及到了for循环进行迭代,直至找到满足条件的index位置为止,这样的话如果数据量比较大,性能肯定会比较低下。而ArrayList则是直接从底层数组中拿,不需要做任何的遍历,性能明显高很多。
再看看Iterator()方法:
public Iterator<E> iterator() {
return listIterator();
}
跟进:
public ListIterator<E> listIterator() {
return listIterator(0);
}
再跟进:
public ListIterator<E> listIterator(final int index) {
rangeCheckForAdd(index);
return new ListItr(index);
}
继续跟进ListItr类:
private class ListItr extends Itr implements ListIterator<E> {
继续跟进Itr:
public E next() {
checkForComodification();
try {
int i = cursor;
E next = get(i);
lastRet = i;
cursor = i + 1;
return next;
} catch (IndexOutOfBoundsException e) {
checkForComodification();
throw new NoSuchElementException();
}
}
最终我们发现,如果要是对LinkedList类进行迭代,最终还是调用的get()方法,而这个方法我们在上面已经分析过了,性能比ArrayList的get方法要低很多,因此LinkedList的Iterator()方法性能不高。
总结:
1、通过代码我们看到,所有的插入方法,替换方法以及删除方法,都是直接对节点的前驱与后继进行直接操作,根本没有涉及到移动节点让出位置的情况,这个比线性表的顺序存储结构性能要高;不过需要说明的是,链表的性能要体现在数据量上面,比如我们总共就10个节点元素,那么使用ArrayList与LinkedList的性能可能根本没有区别。
2、查询方面:ArrayList的get方法是直接到底层数组中去拿值,而LinkedList的get方法则每次都需要对链表进行遍历,尽管遍历的过程中已经采用了算法进行优化,但是效率依旧还是很低。
3、ArrayList的iterator底层依旧是自己的get()方法,而LinkedList的iterator方法底层也是自己的get()方法。而ArrayList的get方法性能比LinkedList的get方法性能高,因此,ArrayList的Iterator方法比LinkedList的iterator方法性能要高。整体来说,ArrayList的查询性能就是比LinkedList的查询性能高
JDK学习---深入理解java中的LinkedList的更多相关文章
- JDK学习---深入理解java中的HashMap、HashSet底层实现
本文参考资料: 1.<大话数据结构> 2.http://www.cnblogs.com/dassmeta/p/5338955.html 3.http://www.cnblogs.com/d ...
- JDK学习---深入理解java中的String
本文参考资料: 1.<深入理解jvm虚拟机> 2.<大话数据结构>.<大话设计模式> 3.http://www.cnblogs.com/ITtangtang/p/3 ...
- map和flatmap的区别+理解、学习与使用 Java 中的 Optional
转自:map和flatmap的区别 对于stream, 两者的输入都是stream的每一个元素,map的输出对应一个元素,必然是一个元素(null也是要返回),flatmap是0或者多个元素(为n ...
- [译]线程生命周期-理解Java中的线程状态
线程生命周期-理解Java中的线程状态 在多线程编程环境下,理解线程生命周期和线程状态非常重要. 在上一篇教程中,我们已经学习了如何创建java线程:实现Runnable接口或者成为Thread的子类 ...
- 深入理解Java中的不可变对象
深入理解Java中的不可变对象 不可变对象想必大部分朋友都不陌生,大家在平时写代码的过程中100%会使用到不可变对象,比如最常见的String对象.包装器对象等,那么到底为何Java语言要这么设计,真 ...
- 深入理解Java中配置环境变量
深入理解Java中配置环境变量 配置的目的: 本来只在安装JDK的bin目下能运行java.exe,javac.exe,jar.exe,javadoc.exe等Java开发工具包命令,我们现在想让在所 ...
- 【Java】深入理解Java中的spi机制
深入理解Java中的spi机制 SPI全名为Service Provider Interface是JDK内置的一种服务提供发现机制,是Java提供的一套用来被第三方实现或者扩展的API,它可以用来启用 ...
- 深入理解Java 中SPI 制
深入理解Java 中SPI 制 概述 SPI(Service Provider Interface),是JDK内置的一种服务提供发现机制,可以用来启用框架扩展和替换组件,主要是被框架的开发人员使用,比 ...
- 如何理解Java中的自动拆箱和自动装箱?
小伟刚毕业时面的第一家公司就被面试官给问住了... 如何理解Java中的自动拆箱和自动装箱? 自动拆箱?自动装箱?什么鬼,听都没听过啊,这...这..知识盲区... 回到家后小伟赶紧查资料,我透,这不 ...
随机推荐
- 硬盘的基础知识-SSD
硬盘有三类:HDD(机械硬盘),SSD(固态硬盘),HHD(混合硬盘) 原理: HDD:磁性碟片 SSD: 闪存颗粒 HHD:磁性碟片的基础上加上了闪存颗粒. 这里对HDD,HHD不加说明,只对SSD ...
- HttpClient4.x工具获取如何使用
HttpClient4.x工具可以让我们输入url,就可以请求某个页面(个人感觉挺实用的,特别是封装在代码中) 首先我们需要在maven工程中添加依赖 <dependency> ...
- Hibernate课程 初探一对多映射4-2 cascade级联属性
1 级联属性:hibernate一方和多方设置关联关系,当一方发生相应修改时(见下表),多方不用进行显式修改,也能进行相应修改. 级联在一方和多方xml中都可以设置 属性值 含义和作用 all 对 ...
- css的三个特性 背景透明设置
关于行内元素(补充一点) 行内元素只能容纳文本或其他行内元素.(a特殊a里面可以放块级元素) 例子: 关于行高tip: 选择器的嵌套层级不应大于3级,位置靠后的限定条件应尽可能的精确. 属性定义必须另 ...
- Windows环境下搭建Linux虚拟机
下载VMware workstation 和 CentOs 或者 redHat .Ubuntu
- SharePoint 2010 网络上的开发经验和资源
sharepoint 集成 Exchange 基于OWA方式获取Exchange中未读邮件 http://www.cnblogs.com/jinho/archive/2011/09/17/21798 ...
- Request processing failed; nested exception is org.apache.ibatis.binding.BindingException: Invalid b
Request processing failed; nested exception is org.apache.ibatis.binding.BindingException: Invalid b ...
- PHP:如果正确加载js、css、images等静态文件
日常中,我们想要把一些静态页面放在框架上或者是进行转移时,那么静态页面上的原url加载js.css.images都会失效,那么我们应该怎么进行修改捏? 现在仓鼠做个笔记哈 这里有几个注意项: 1.路径 ...
- 如何在CRM WebClient UI里使用HANA Live Report
1. 使用业务角色ANALYTICSPRO登录SAP CRM WebClient UI: 点击新建按钮创建一个新的HANA live report: 类型选择SHL: 弹出窗口,维护report的名称 ...
- 【转载】#437 - Access Interface Members through an Interface Variable
Onece a class implementation a particular interface, you can interact with the members of the interf ...