正则化--L2正则化
请查看以下泛化曲线,该曲线显示的是训练集和验证集相对于训练迭代次数的损失。
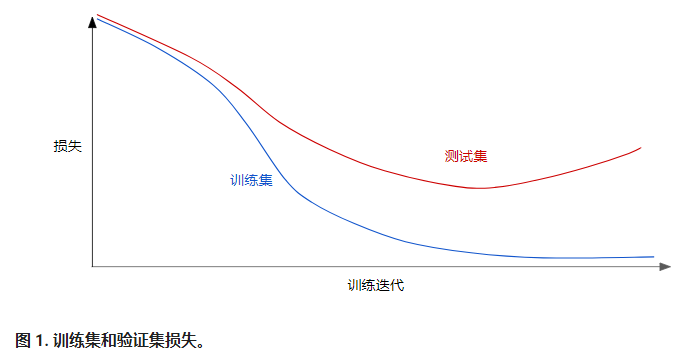
图 1 显示的是某个模型的训练损失逐渐减少,但验证损失最终增加。换言之,该泛化曲线显示该模型与训练集中的数据过拟合。根据奥卡姆剃刀定律,或许我们可以通过降低复杂模型的复杂度来防止过拟合,这种原则称为正则化。
也就是说,并非只是以最小化损失(经验风险最小化)为目标:
而是以最小化损失和复杂度为目标,这称为结构风险最小化:
现在,我们的训练优化算法是一个由两项内容组成的函数:一个是损失项,用于衡量模型与数据的拟合度,另一个是正则化项,用于衡量模型复杂度。
机器学习速成课程重点介绍了两种衡量模型复杂度的常见方式(这两种方式有些相关):
- 将模型复杂度作为模型中所有特征的权重的函数。
- 将模型复杂度作为具有非零权重的特征总数的函数。
如果模型复杂度是权重的函数,则特征权重的绝对值越高,模型就越复杂。
我们可以使用 L2 正则化公式来量化复杂度,该公式将正则化项定义为所有特征权重的平方和:
在这个公式中,接近于 0 的权重对模型复杂度几乎没有影响,而离群值权重则可能会产生巨大的影响。
L2 正则化项为 26.915:
\[w_1^2 + w_2^2 + {w_3^2} + w_4^2 + w_5^2 + w_6^2\]
\[= 0.2^2 + 0.5^2 + {5^2} + 1^2 + 0.25^2 + 0.75^2\]
\[= 0.04 + 0.25 + {25} + 1 + 0.0625 + 0.5625\]
\[= 26.915\]
```
但是w3的平方值为25,几乎贡献了全部的复杂度。所有 5 个其他权重的平方和对 L2 正则化项的贡献仅为 1.915。
引用
正则化--L2正则化的更多相关文章
- L1 与 L2 正则化
参考这篇文章: https://baijiahao.baidu.com/s?id=1621054167310242353&wfr=spider&for=pc https://blog. ...
- TensorFlow L2正则化
TensorFlow L2正则化 L2正则化在机器学习和深度学习非常常用,在TensorFlow中使用L2正则化非常方便,仅需将下面的运算结果加到损失函数后面即可 reg = tf.contrib.l ...
- L1和L2正则化(转载)
[深度学习]L1正则化和L2正则化 在机器学习中,我们非常关心模型的预测能力,即模型在新数据上的表现,而不希望过拟合现象的的发生,我们通常使用正则化(regularization)技术来防止过拟合情况 ...
- L1与L2正则化
目录 过拟合 结构风险最小化原理 正则化 L2正则化 L1正则化 L1与L2正则化 参考链接 过拟合 机器学习中,如果参数过多.模型过于复杂,容易造成过拟合. 结构风险最小化原理 在经验风险最小化(训 ...
- L0,L1,L2正则化浅析
在机器学习的概念中,我们经常听到L0,L1,L2正则化,本文对这几种正则化做简单总结. 1.概念 L0正则化的值是模型参数中非零参数的个数. L1正则化表示各个参数绝对值之和. L2正则化标识各个参数 ...
- 【深度学习】L1正则化和L2正则化
在机器学习中,我们非常关心模型的预测能力,即模型在新数据上的表现,而不希望过拟合现象的的发生,我们通常使用正则化(regularization)技术来防止过拟合情况.正则化是机器学习中通过显式的控制模 ...
- L1正则化比L2正则化更易获得稀疏解的原因
我们知道L1正则化和L2正则化都可以用于降低过拟合的风险,但是L1正则化还会带来一个额外的好处:它比L2正则化更容易获得稀疏解,也就是说它求得的w权重向量具有更少的非零分量. 为了理解这一点我们看一个 ...
- TensorFlow之DNN(三):神经网络的正则化方法(Dropout、L2正则化、早停和数据增强)
这一篇博客整理用TensorFlow实现神经网络正则化的内容. 深层神经网络往往具有数十万乃至数百万的参数,可以进行非常复杂的特征变换,具有强大的学习能力,因此容易在训练集上过拟合.缓解神经网络的过拟 ...
- 4.机器学习——统计学习三要素与最大似然估计、最大后验概率估计及L1、L2正则化
1.前言 之前我一直对于“最大似然估计”犯迷糊,今天在看了陶轻松.忆臻.nebulaf91等人的博客以及李航老师的<统计学习方法>后,豁然开朗,于是在此记下一些心得体会. “最大似然估计” ...
随机推荐
- 解决/usr/lib/libstdc++.so.6: version `GLIBCXX_3.4.17' not found问题
在项目中使用第三方动态库时,出现异常:/usr/lib64/libstdc++.so.6: version `GLIBCXX_3.4.17' not found 查看系统库时,发现确实没有对应的版本: ...
- hdu 5063(思路题-反向操作数组)
Operation the Sequence Time Limit: 3000/1500 MS (Java/Others) Memory Limit: 32768/32768 K (Java/O ...
- C#中使用aria2c进行下载并显示进度条
正则表达式的生成网站: http://www.txt2re.com/index-csharp.php3 Aria2c下载地址: https://github.com/aria2/aria2/relea ...
- [BZOJ1070][SCOI2007]修车 费用流
1070: [SCOI2007]修车 Time Limit: 1 Sec Memory Limit: 128 MBSubmit: 6209 Solved: 2641[Submit][Status] ...
- ACM中的正则表达式
layout: post title: ACM中的正则表达式 author: "luowentaoaa" catalog: true mathjax: true tags: - 正 ...
- JSP(待更新)
1.概念: 所谓JSP就是在HTML中嵌入大量的java代码而已.
- PHP数组输出三种形式 PHP打印数组
PHP数组输出三种形式 PHP打印数组 $bbbb=array("11"=>"aaa","22"=>"bbb&qu ...
- 如何获取Class的所有方法
// 取得所有方法 Method[] hideMethod =Activity.class.getMethods(); int i = 0; for (; i < hideMethod.leng ...
- Winform 遍历 ListBox中的所有项
foreach(DataRowView row in listBox.Items ) { MessageBox.Show(row["displayMember"].ToString ...
- JAVA常见算法题(二十二)
package com.xiaowu.demo; //利用递归方法求5!. public class Demo22 { public static void main(String[] args) { ...