linux c编程:标准IO库
前面介绍对文件进行操作的时候,使用的是open,read,write函数。这一章将要介绍基于流的文件操作方法:fopen,fread,fwrite。这两种方式的区别是什么呢。1种是缓冲文件系统,一种是非缓冲文件系统
缓冲文件系统就是采用fopen,fread,fwrite,fgetc,fputc,fputs等函数进行操作。缓冲文件系统的特点是:在内存开辟一个“缓冲区”,为程序中的每一个文件使用;当执行读文件的操作时,从磁盘文件将数据先读入内存“缓冲区”,装满后再从内存“缓冲区”依此读出需要的数据。执行写文件的操作时,先将数据写入内存“缓冲区”,待内存“缓冲区”装满后再写入文件。由此可以看出,内存“缓冲区”的大小,影响着实际操作外存的次数,内存“缓冲区”越大,则操作外存的次数就少,执行速度就快、效率高。一般来说,文件“缓冲区”的大小随机器 而定。fopen, fclose, fread, fwrite, fgetc, fgets, fputc, fputs, freopen, fseek, ftell, rewind等。
非缓冲系统:
缓冲文件系统是借助文件结构体指针来对文件进行管理,通过文件指针来对文件进行访问,既可以读写字符、字符串、格式化数据,也可以读写二进制数据。非缓冲文件系统依赖于操作系统,通过操作系统的功能对文件进行读写,是系统级的输入输出,它不设文件结构体指针,只能读写二进制文件,但效率高、速度快。
从上面的描述差异可以看出,fopen是c标准函数,具有良好的移植性; 而open是linux系统调用,移植性有限。如果从文件IO的角度来看,非缓冲系统属于低级IO函数,缓冲系统属于高级IO函数。低级和高级的简单区分标准是:谁离系统内核更近。低级文件IO运行在内核态,高级文件IO运行在用户态。
来看下面的代码
#include <stdio.h>
const char *pathname="/home/zhf/test1.txt
void read_file_by_stream(){
FILE *fp;
const char * type="r";
char *string;
int c;
fp=fopen(pathname,type);
c=fgetc(fp);
printf("%c",c);
}
在这里采用了fopen和fgetc函数来读文件打开和读取。
fopen的原型:
FILE *fopen(const char *restrict pathname, const char *restrict type);
打开方式参考如下:
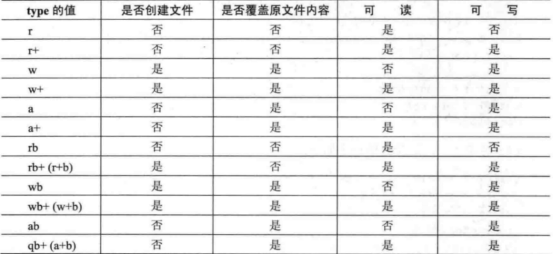
fgetc函数的原型:
int fgetc(FILE *fp); 返回的是读取到的一个字符。返回的是整型
前面的代码只能一次性读取一个字符,那么要读取整个文件的内容就要采集循环的方式了。代码修改如下
void read_file_by_stream(){
FILE *fp;
const char * type="r";
char *string;
int c;
fp=fopen(pathname,type);
if (ferror(fp)){
printf("open file error");
}
while((c=fgetc(fp)) != EOF){
printf("%c",c);
}
fclose(fp);
}
ferror是判断文件在打开的时候是否有错误,如果有则进行提示
c=fgetc(fp)) != EOF: 要判断是否读取到了文件的末尾,则采用和EOF进行比较的方式。 EOF是一个负值,一般为-1,因为fgetc的返回值是将unsigned char转换成int。 如果最高位为1也不会使返回值为负。因此只要fgetc的返回值不是EOF,则表明可以继续往下读取字符。
fgetc一次只能读取一个字符,这样的读取效率太低。是否能够做到一次读取一行的数据呢。 方法是用fgets函数
char *fgets(char *buf,int n,FILE *fp)
#include <stdio.h>
const char *pathname="/home/zhf/test1.txt";
void read_file_by_stream(){
FILE *fp;
const char * type="r";
char buf[100];
char *string;
int c;
fp=fopen(pathname,type);
if (ferror(fp)){
printf("open file error");
}
while(fgets(buf,10,fp) != NULL){
printf("The content is %s",buf);
}
fclose(fp);
}
当返回的指针不会空的时候,读取每行的数据
The content is abcde
The content is kjkl
当然也可以采用gets函数,区别在于无法指定缓冲区的长度,fgets必须指定缓冲区的长度。fgets一直读到下一个换行符为止,但是不超过n-1个字符。对应的输入函数分别是fputc和fputs这里就不再介绍了
前面介绍的fgetc,fgets都只能读取一个或者一行字符。且遇到如果文件中有null字符的时候则会停止。特别是网络操作的时候,会写入各种各样的符号。在这种情况下就需要用到二进制I/O,也就是fread和fwrite函数
fwrite:
- size_t fwrite(const void* buffer, size_t size, size_t count, FILE* stream);
- -- buffer:指向数据块的指针
- -- size:每个数据的大小,单位为Byte(例如:sizeof(int)就是4)
- -- count:数据个数
- -- stream:文件指针
调用格式:fwrite(buf,sizeof(buf),1,fp);成功写入返回值为1(即count)
调用格式:fwrite(buf,1,sizeof(buf),fp);成功写入则返回实际写入的数据个数(单位为Byte)
fread:
- size_t fread(void *buffer, size_t size, size_t count, FILE *stream);
- -- buffer:指向数据块的指针
- -- size:每个数据的大小,单位为Byte(例如:sizeof(int)就是4)
- -- count:数据个数
- -- stream:文件指针
(1) 调用格式:fread(buf,sizeof(buf),1,fp);
读取成功时:当读取的数据量正好是sizeof(buf)个Byte时,返回值为1(即count)
否则返回值为0(读取数据量小于sizeof(buf))
(2)调用格式:fread(buf,1,sizeof(buf),fp);
读取成功返回值为实际读回的数据个数(单位为Byte)
代码如下:
void read_file_by_binary(){
int flag;
FILE *fp;
FILE *fp1;
const char *type="a+";
char buf[20]="it is test\n";
char buffer[200];
fp=fopen(pathname,type);
fwrite(buf,sizeof(buf),1,fp);
fclose(fp);
fp1=fopen(pathname,type);
flag=fread(buffer,1,sizeof(buffer),fp1);
printf("%ld,%d",sizeof(buffer),flag);
printf("%s",buffer);
fclose(fp1);
}
linux c编程:标准IO库的更多相关文章
- UNIX环境高级编程 标准IO库
标准I/O库处理很多细节,使得便于用户使用. 流和 FILE 对象 对于标准I/O库,操作是围绕 流(stream)进行的.当用标准I/O打开或创建一个文件时,我们已使一个流与一个文件相关联. 对于A ...
- 高级UNIX环境编程5 标准IO库
标准IO库都围绕流进进行的 <stdio.h><wchar.h> memccpy 一般用汇编写的 ftell/fseek/ftello/fseeko/fgetpos/fsetp ...
- 18、标准IO库详解及实例
标准IO库是由Dennis Ritchie于1975年左右编写的,它是Mike Lestbain写的可移植IO库的主要修改版本,2010年以后, 标准IO库几乎没有进行什么修改.标准IO库处理了很多细 ...
- [APUE]标准IO库(下)
一.标准IO的效率 对比以下四个程序的用户CPU.系统CPU与时钟时间对比 程序1:系统IO 程序2:标准IO getc版本 程序3:标准IO fgets版本 结果: [注:该表截取自APUE,上表中 ...
- [APUE]标准IO库(上)
一.流和FILE对象 系统IO都是针对文件描述符,当打开一个文件时,即返回一个文件描述符,然后用该文件描述符来进行下面的操作,而对于标准IO库,它们的操作则是围绕流(stream)进行的. 当打开一个 ...
- 文件IO函数和标准IO库的区别
摘自 http://blog.chinaunix.net/uid-26565142-id-3051729.html 1,文件IO函数,在Unix中,有如下5个:open,read,write,lsee ...
- C++ Primer 读书笔记: 第8章 标准IO库
第8章 标准IO库 8.1 面向对象的标准库 1. IO类型在三个独立的头文件中定义:iostream定义读写控制窗口的类型,fstream定义读写已命名文件的类型,而sstream所定义的类型则用于 ...
- c++ primer 学习杂记3【标准IO库】
第8章 标准IO库 发现书中一个错误,中文版p248 流状态的查询和控制,举了一个代码例子: int ival; // read cin and test only for EOF; loop is ...
- 第十三篇:带缓冲的IO( 标准IO库 )
前言 在之前,学习了 read write 这样的不带缓冲IO函数. 而本文将讲解标准IO库中,带缓冲的IO函数. 为什么要有带缓冲IO函数 标准库提供的带缓冲IO函数是为了减少 read 和 wri ...
- C5 标准IO库:APUE 笔记
C5 :标准IO库 在第三章中,所有IO函数都是围绕文件描述符展开,文件描述符用于后续IO操作.由于文件描述符相关的操作是不带缓冲的IO,需要操作者本人指定缓冲区分配.IO长度等,对设备环境要求一定的 ...
随机推荐
- linux命令之------vmstat使用
在linux命令中,vmstat是个经常用到的分析系统性能的命令之一,主要有两个参数:一个是采样频率,一个是采样的次数.如:vmstat 1 3,意思就是每隔1秒采样1次,总共采样3次. 统计次 ...
- 推荐系统学习(2)——基于TF-IDF的改进
使用用户打标签次数*物品打标签次数做乘积的算法尽管简单.可是会造成热门物品推荐的情况.物品标签的权重是物品打过该标签的次数,用户标签的权重是用户使用过该标签的次数.从而导致个性化的推荐减少,而造成热门 ...
- 在UC浏览器打开链接唤醒app,假设没有安装该app,则跳转到appstore下载该应用
在UC浏览器打开链接唤醒app,假设没有安装该app,则跳转到appstore下载该应用 须要在project中设置例如以下: 1.打开project中的myapp-Info.plist文件 2.打开 ...
- 嵌套矩形——DAG上的动态规划
有向无环图(DAG,Directed Acyclic Graph)上的动态规划是学习动态规划的基础.非常多问题都能够转化为DAG上的最长路.最短路或路径计数问题. 题目描写叙述: 有n个矩形,每一个矩 ...
- Java 基础,小数百分比两种方法
public static void main(String[] args) { System.out.println(getPercent(1, 2)); } public static Strin ...
- flex-direction用法解释
语法: flex-direction:row | row-reverse | column | column-reverse 默认值:row 适用于:flex容器 继承性:无 动画性:否 计算值:指定 ...
- ios程序,顶部和底部产生空白——程序不能全屏运行
在开发过程中,遇到过这样的问题,整个程序不能以全屏状态运行,顶部和底部出现空白,如下图所示: 这样的原因是:设置的启动页不合适,设置大小合适的启动页就好了
- asp.net core mvc视频A:笔记1.基本概念介绍
此笔记来自视频教程 MVC本身与三层架构没有联系 使用VS2017新建一个默认的asp.net core mvc网站,认识结构及文件用途.
- sprint3 【每日scrum】 TD助手站立会议第九天
站立会议 组员 昨天 今天 困难 签到 刘铸辉 (组长) 整合原来做过的功能,并做相应的改进,整合其他的功能 团队进入最终的功能测试阶段,准备发布Beta版 在测试阶段BUG太多,不知道如何解决 Y ...
- vi/vim复制粘贴命
1. 选定文本块.使用v进入可视模式,移动光标键选定内容. 2.复制的命令是y,即yank(提起) ,常用的命令如下: y 在使用v模式选定了某一块的时候,复制选定块到缓冲区用: ...