1、Broker配置
<ignore_js_op>

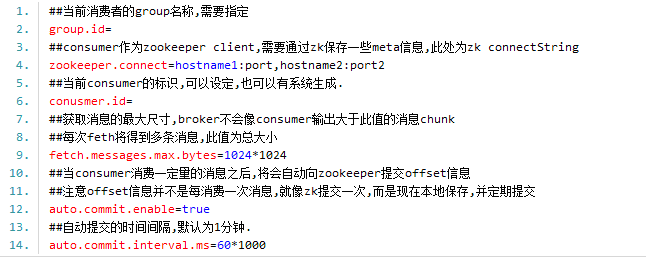
2.Consumer主要配置
<ignore_js_op>
3.Producer主要配置
<ignore_js_op>

以上是关于kafka一些基础说明,在其中我们知道如果要kafka正常运行,必须配置zookeeper,否则无论是kafka集群还是
客户端的生存者和消费者都无法正常的工作的,以下是对zookeeper进行一些简单的介绍:
五、zookeeper集群
zookeeper是一个为分布式应用提供一致性服务的软件,它是开源的Hadoop项目的一个子项目,并根据google发表的一篇论文来实现的。zookeeper为分布式系统提供了高笑且易于使用的协同服务,它可以为分布式应用提供相当多的服务,诸如统一命名服务,配置管理,状态同步和组服务等。zookeeper接口简单,我们不必过多地纠结在分布式系统
编程难于处理的同步和一致性问题上,你可以使用zookeeper提供的现成(off-the-shelf)服务来实现来实现分布式系统额配置管理,组管理,Leader选举等功能。
zookeeper集群的安装,准备三台服务器server1:192.168.0.1,server2:192.168.0.2,
server3:192.168.0.3.
1)下载zookeeper
2)安装zookeeper
a)解压
tar -zxvf zookeeper-3.4.5.tar.gz
解压完成后在目录~下会发现多出一个目录zookeeper-3.4.5,重新命令为zookeeper
b)配置
将conf/zoo_sample.cfg拷贝一份命名为zoo.cfg,也放在conf目录下。然后按照如下值修改其中的配置:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/home/wwb/zookeeper /data
dataLogDir=/home/wwb/zookeeper/logs
# the port at which the clients will connect
clientPort=2181
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=192.168.0.1:3888:4888
server.2=192.168.0.2:3888:4888
server.3=192.168.0.3:3888:4888
tickTime:这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
dataDir:顾名思义就是 Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。
clientPort:这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
initLimit:这个配置项是用来配置 Zookeeper 接受
客户端(这里所说的客户端不是用户连接 Zookeeper 服务器的客户端,而是 Zookeeper 服务器集群中连接到 Leader 的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过 5个心跳的时间(也就是 tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 5*2000=10 秒
syncLimit:这个配置项标识 Leader 与Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是2*2000=4 秒
server.A=B:C:D:其中 A 是一个数字,表示这个是第几号服务器;B 是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号
注意:dataDir,dataLogDir中的wwb是当前登录用户名,data,logs目录开始是不存在,需要使用mkdir命令创建相应的目录。并且在该目录下创建文件myid,serve1,server2,server3该文件内容分别为1,2,3。
针对服务器server2,server3可以将server1复制到相应的目录,不过需要注意dataDir,dataLogDir目录,并且文件myid内容分别为2,3
3)依次启动
server1,server2,server3的zookeeper.
/home/wwb/zookeeper/bin/zkServer.sh start,出现类似以下内容
JMX enabled by default
Using config: /home/wwb/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
4) 测试zookeeper是否正常工作,在server1上执行以下命令
/home/wwb/zookeeper/bin/zkCli.sh -server192.168.0.2:2181,出现类似以下内容
JLine support is enabled
2013-11-27 19:59:40,560 - INFO [main-SendThread(localhost.localdomain:2181):ClientCnxn$SendThread@736]- Session establishmentcomplete on
server localhost.localdomain/127.0.0.1:2181, sessionid = 0x1429cdb49220000, negotiatedtimeout = 30000
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[zk: 127.0.0.1:2181(CONNECTED) 0] [root@localhostzookeeper2]#
即代表集群构建成功了,如果出现错误那应该是第三部时没有启动好集群,
运行,先利用
ps aux | grep zookeeper查看是否有相应的进程的,没有话,说明集群启动出现问题,可以在每个服务器上使用
./home/wwb/zookeeper/bin/zkServer.sh stop。再依次使用./home/wwb/zookeeper/binzkServer.sh start,这时在执行4一般是没有问题,如果还是有问题,那么先stop再到bin的上级目录执行./bin/zkServer.shstart试试。
注意:zookeeper集群时,zookeeper要求半数以上的机器可用,zookeeper才能提供服务。
六、kafka集群
(利用上面server1,server2,server3,下面以server1为实例)
2)解压 tar -zxvf kafka-0.8.0-beta1-src.tgz,产生文件夹kafka-0.8.0-beta1-src更改为kafka01
3)配置
修改kafka01/config/
server.properties,其中broker.id,log.dirs,zookeeper.connect必须根据实际情况进行修改,其他项根据需要自行斟酌。大致如下:
broker.id=1
port=9091
num.network.threads=2
num.io.threads=2
socket.send.buffer.bytes=1048576
socket.receive.buffer.bytes=1048576
socket.request.max.bytes=104857600
log.dir=./logs
num.partitions=2
log.flush.interval.messages=10000
log.flush.interval.ms=1000
log.retention.hours=168
#log.retention.bytes=1073741824
log.segment.bytes=536870912
num.replica.fetchers=2
log.cleanup.interval.mins=10
zookeeper.connect=192.168.0.1:2181,192.168.0.2:2182,192.168.0.3:2183
zookeeper.connection.timeout.ms=1000000
kafka.metrics.polling.interval.secs=5
kafka.metrics.reporters=kafka.metrics.KafkaCSVMetricsReporter
kafka.csv.metrics.dir=/tmp/kafka_metrics
kafka.csv.metrics.reporter.enabled=false
4)初始化因为kafka用scala语言编写,因此运行kafka需要首先准备scala相关环境。
> cd kafka01
> ./sbt update
> ./sbt package
> ./sbt assembly-package-dependency
在第二个命令时可能需要一定时间,由于要下载更新一些依赖包。所以请大家 耐心点。
5) 启动kafka01
>JMX_PORT=9997 bin/kafka-
server-start.sh config/server.properties &
a)kafka02操作步骤与kafka01雷同,不同的地方如下
修改kafka02/config/server.properties
broker.id=2
port=9092
##其他配置和kafka-0保持一致
启动kafka02
JMX_PORT=9998 bin/kafka-server-start.shconfig/server.properties &
b)kafka03操作步骤与kafka01雷同,不同的地方如下
修改kafka03/config/server.properties
broker.id=3
port=9093
##其他配置和kafka-0保持一致
启动kafka02
JMX_PORT=9999 bin/kafka-
server-start.shconfig/server.properties &
6)创建Topic(包含一个分区,三个副本)
>bin/kafka-create-topic.sh--zookeeper 192.168.0.1:2181 --replica 3 --partition 1 --topicmy-replicated-topic
7)查看topic情况
>bin/kafka-list-top.sh --zookeeper 192.168.0.1:2181
topic: my-replicated-topic partition: 0 leader: 1 replicas: 1,2,0 isr: 1,2,0
8)创建发送者
>bin/kafka-console-producer.sh--broker-list 192.168.0.1:9091 --topic my-replicated-topic
my test message1
my test message2
^C
9)创建消费者
>bin/kafka-console-consumer.sh --zookeeper127.0.0.1:2181 --from-beginning --topic my-replicated-topic
...
my test message1
my test message2
^C
10)杀掉server1上的broker
>pkill -9 -f config/
server.properties
11)查看topic
>bin/kafka-list-top.sh --zookeeper192.168.0.1:2181
topic: my-replicated-topic partition: 0 leader: 1 replicas: 1,2,0 isr: 1,2,0
发现topic还正常的存在
11)创建消费者,看是否能查询到消息
>bin/kafka-console-consumer.sh --zookeeper192.168.0.1:2181 --from-beginning --topic my-replicated-topic
...
my test message 1
my test message 2
^C
说明一切都是正常的。
OK,以上就是对Kafka个人的理解,不对之处请大家及时指出。
补充说明:
1、public Map<String, List<KafkaStream<byte[], byte[]>>> createMessageStreams(Map<String, Integer> topicCountMap),其中该方法的参数Map的key为topic名称,value为topic对应的分区数,譬如说如果在kafka中不存在相应的topic时,则会创建一个topic,分区数为value,如果存在的话,该处的value则不起什么作用
2、关于生产者向指定的分区发送数据,通过设置partitioner.class的属性来指定向那个分区发送数据,如果自己指定必须编写相应的程序,默认是kafka.producer.DefaultPartitioner,分区程序是基于散列的键。
3、在多个消费者读取同一个topic的数据,为了保证每个消费者读取数据的唯一性,必须将这些消费者group_id定义为同一个值,这样就构建了一个类似队列的数据结构,如果定义不同,则类似一种广播结构的。
4、在consumerapi中,参数
设计到数字部分,类似Map<String,Integer>,
numStream,指的都是在topic不存在的时,会创建一个topic,并且分区个数为Integer,numStream,注意如果数字大于broker的配置中num.partitions属性,会以num.partitions为依据创建分区个数的。
5、producerapi,调用send时,如果不存在topic,也会创建topic,在该方法中没有提供分区个数的参数,在这里分区个数是由服务端broker的配置中num.partitions属性决定的
- kafka系列七、kafka核心配置
一.producer核心配置 1.acks :发送应答(默认值:1) 生产者在考虑完成请求之前要求leader收到的确认的数量.这控制了发送的记录的持久性.允许以下设置: acks=0:设置为0,则生 ...
- Kafka broker配置介绍 (四)
这部分内容对了解系统和提高软件性能都有很大的帮助,kafka官网上也给出了比较详细的配置详单,但是我们还是直接从代码来看broker到底有哪些配置需要我们去了解的,配置都有英文注释,所以每一部分是干什 ...
- kafka 相关配置
kafka主要配置包括三类:broker configuration,producer configuration and consumer configuration. Broker Config ...
- Kafka动态配置实现原理解析
问题导读 Apache Kafka在全球各个领域各大公司获得广泛使用,得益于它强大的功能和不断完善的生态.其中Kafka动态配置是一个比较高频好用的功能,下面我们就来一探究竟. 动态配置是如何设计的? ...
- 一、kafka 安装配置
Kafka是什么 Kafka最初是由LinkedIn公司采用Scala语言开发的一个分布式.多分区.多副本且基于ZooKeeper协调的内部基础设置,现已捐献给Apache基金会.Kafka是一个流平 ...
- SpringCloudStream(RabbitMQ&Kafka)&Spring-Kafka配置使用
目录 是什么 解决问题 使用方式 创建生产者项目 pom yml 生产消息方法 接口 实现 创建消费者项目 pom yml 接收消息方法 重复消费 消费者yml 持久化 消费者负载个性配置(预拉取) ...
- Kafka之配置信息
Kafka之配置信息 一.Broker配置信息 属性 默认值 描述 broker.id 必填参数,broker的唯一标识 log.dirs /tmp/kafka-logs Kafka数据存放的目录 ...
- 从0开始搭建SQL Server AlwaysOn 第三篇(配置AlwaysOn)
从0开始搭建SQL Server AlwaysOn 第三篇(配置AlwaysOn) 第一篇http://www.cnblogs.com/lyhabc/p/4678330.html第二篇http://w ...
- LVS三种模式配置及优点缺点比较
目录: LVS三种模式配置 LVS 三种工作模式的优缺点比较 LVS三种模式配置 LVS三种(LVS-DR,LVS-NAT,LVS-TUN)模式的简要配置 LVS是什么: http://www.lin ...
- Spring使用jdbcJdbcTemplate和三种方法配置数据源
三种方法配置数据源 1.需要引入jar包:spring-jdbc-4.3.2.RELEASE.jar <!-- spring内置,springJdbc,配置数据源 --> <bean ...
随机推荐
- Js格式化json字符串
var formatJson = function(json, options) { var reg = null, formatted = '', pad = 0, PADDING = ' '; / ...
- PAT 天梯赛 L2-007. 家庭房产 【并查集】
题目链接 https://www.patest.cn/contests/gplt/L2-007 思路 将一个家庭里的所有人都并进去 然后最后查找的时候 找到所有同一个家庭的人,计算出人数,人均房产套数 ...
- 美团offer
首先说明我是OP岗,RD的可能没有参考意义.本人985渣本一枚,非计算机.网络相关专业.不得不说美团的面试官给我的感觉很好,首先他们都比较极客,都是各个方向的大牛.虽然根据面试流程必须问我一些与我方向 ...
- html编辑器的调用
<html><head> <metahttp-equiv="Content-type"content="text/html; cha ...
- XShell 连接虚拟机中的服务器 失败 、连接中断(Connection closed by foreign host.)
在使用XShell连接虚拟机中的服务器时,报以下错误并断开连接,之前连接还是挺稳定的,忽然就这样了 Last login: Thu Aug :: from 192.168.1.102 [root@no ...
- UOJ278 【UTR #2】题目排列顺序
本文作者:ljh2000 作者博客:http://www.cnblogs.com/ljh2000-jump/转载请注明出处,侵权必究,保留最终解释权! 题目链接: http://uoj.ac/co ...
- QQ.PC管家进程
1.家里的笔记本 WIn7x64 C:\Program Files (x86)\Tencent\QQPCMgr\12.10.19266.225\QMDL.exeC:\Program Files (x8 ...
- Codeforces 358D Dima and Hares:dp【只考虑相邻元素】
题目链接:http://codeforces.com/problemset/problem/358/D 题意: 有n个物品A[i]摆成一排,你要按照某一个顺序将它们全部取走. 其中,取走A[i]的收益 ...
- 造成segmentation fault的可能原因分析
一 造成segment fault,产生core dump的可能原因 1.内存访问越界 a) 由于使用错误的下标,导致数组访问越界 b) 搜索字符串时,依靠字符串结束符来判断字符串是否结束,但是字符串 ...
- jenkins-小知识点
如果想停止jenkins运行 控制面板-服务-查看本地服务-选中jenkins 1.启动类型改为手动 2.改为禁止 使用的时候,每次都改一下状态