Andrew NG 自动化所演讲(20140707):DeepLearning Overview and Trends
以下内容转载于 网友 Fiona Duan,感谢作者分享 (原作的图片显示有问题,所以我从别处找了一些附上,小伙伴们可以看看)。最近越来越觉得人工智能,深度学习是一个很好的发展方向,应该也是未来科技的关键核心。
隆重分享,中科院自动化所录制的视频:http://pan.baidu.com/s/1c0vjEIc
(英文的,没有中文字幕,考听力了)
7月7日,笔者有幸在中科院自动化所现场听取了Andrew Ng以《Deep Learning:Overview and Trends》的精彩演讲。现将Andrew演讲内容整理出来,希望对大家有所帮助。演讲中,Andrew主和大家分享了深度学习为何产生和发展成果,展望了未来发展趋势,以及百度在人工智能上的使命。现场录音包括Andrew演讲内容和会后现场问答,希望对大家有帮助~

演讲录音链接:http://pan.baidu.com/s/1ntHRSxV
PS: 英文好的小伙伴,可以听听,有Andrew的八卦喔!~~
特别说明:本文不是Andrew的演讲实录,只是笔者记录下来的内容;此外,由于全程英文和笔者技术水平有限,有不准确或遗漏之处,还请见谅。
深度学习为何产生?
一直以来,在人工智能领域,我们试图达到获得大量数据、做出优秀产品和赢得广大用户三者之间的良性循环,但传统的机器学习算法表现并不够好,良性循环也未能实现。

深度学习相比于传统方法有很多优势,如下面这个很直观的图,随着训练量的提高,传统方法遇到了瓶颈,但深度学习的效果却蓬勃发展,不断提高。

深度学习有哪些发展?
当年在斯坦福大学,我和我的团队曾经有一个想法,让机器人去识别咖啡杯。但机器人看到的东西和人完全不一样,我们会看到一个具体的杯子,但机器能看到的只有数据,这也是计算机视觉(computer vision)难点所在,那就是要搞明白这些数字代表了什么。
过去我们的研究主要集中在三个领域。第一个是计算机视觉,目的是发现物体特征,然后描绘这种特征。第二个是语音识别(speech recognition),比如对机器说:“请找到我的咖啡杯”,机器就会识别这句话的意思。第三个是文本识别,这个有助于我们更好的应用,比如机器翻译、网络搜索等。
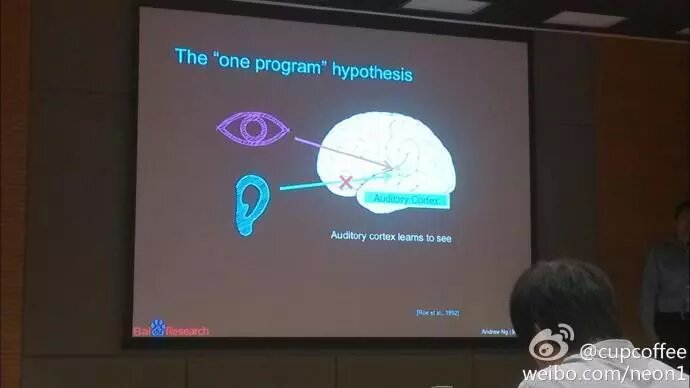
很长一段时间,我们设计了大量program,也发了一些paper,但研究没有什么突破性进展。直到大概七年前,我和我的学生突然有一个想法:人脑中大部分感知器是一个非常简单的计算过程。
而对于人脑的研究也表明,这个“one program”的假设是有可能的。我们可以从大脑如何听、如何看开始,去了解大脑的神经元如何工作,并进而为深度学习提供理论依据。

有了这个依据,我们开始从有标记数据(tagged data)中学习,也就是有监督学习(supervised learning)。在给机器看了50000张咖啡杯图片后,我们让机器人在斯坦福计算机系办公楼里找咖啡杯,效果非常好。进一步研究后,我们认识到bigger is better,即特征越多,实验效果越好。
于是,我就开始寻找谁拥有更多的计算资源,于是找到了谷歌,开始了谷歌大脑这个项目,并建立了当时世界最大的神经网络,达到10亿个神经元。而我们的研究也推动了谷歌产品的发展,提升了用户的体验,比如谷歌地图,以及语音识别方面的应用。
谷歌在硅谷确实很牛,但相比于谷歌,百度能够更迅速地把深度学习技术应用到更多的产品中,比如最值得骄傲的是百度图像搜索,准确度已超过谷歌,此外还有百度语音识别,广告预估等。
过去很多深度学习的成功,很大原因是利用了有标记数据。像百度、谷歌、Facebook这些公司,拥有海量的有标记数据,相较于其他技术,深度学习更适合利用这些数据并获得好的表现。
但这并不是深度学习发展的唯一方向,想想宝宝是如何学习的?他们并不是从有标记数据中获得认知,即使是最最深沉地爱着自己孩子的父母,也不会找出5万个咖啡杯的照片指认给自己的孩子看,来让他认识什么是咖啡杯的。另外一点,标记数据可能存在用完的问题。所以大家认为使用未标记数据来学习,会是未来的发展方向。
实际上,人类大脑如何处理图片的过程就是visual cortex寻找图片中Lines/edges的过程,而每一个visual cortex的神经元就是一个Model。

基于生物学中visual cortex的工作原理,发现人脑处理的过程是:像素->边缘->对象部分->对象模型。深度学习的过程是反向的。深度学习就是找到小patch再将其进行组合,就得到了上一层的特征(feature),递归地向上学习特征( feature)。在不同对象(object)上做训练是,所得的边缘(edge)是非常相似的,但对象部分(object parts)和模型(models) 就会完全不同。
(笔者:讲到这里,Andrew秀出了他的演讲中唯一的一个公式,还和大家开玩笑的说道,I hope you can enjoy it. 由于笔者的水平,这段听的不太明白,就把公式贴出来,大家自己琢磨吧。)

我们曾使用Youtube视频作为未标记数据,让机器自主学习。这个过程中我们发现人脸在视频中出现的频率非常高,神经网络可以学习如何认出人脸。但令人惊喜的是,机器通过自学辨别出了猫脸。

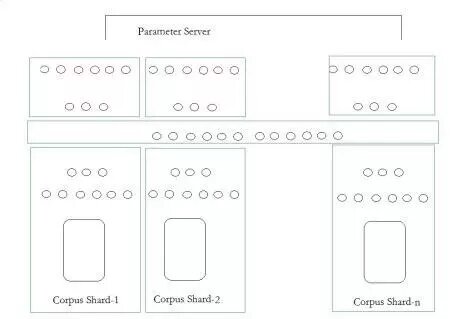
当时我作报告时,经常会有人过来对我说:深度学习听起来真的很酷,但如果没有造价昂贵的16000个 CPU,我们还能在深度学习上有所进展么?所以我和Adam、Bryan(两周前刚刚加盟百度)就致力于寻找到更便宜的研发方法。后来我们决定用GPU(Graphic Processing Unit)替代CPU,降低造价。于是,具有100亿个节点的神经元网络便出现了。
深度学习未来去向何方?
我认为0-2年内仍以标记数据为主导发展方向,之后的3-5年,标记数据和未标记数据将共同发展。但关于深度学习的未来更长远的发展,我认为将会更依赖于无标记的数据,因为这与人类和动物认知世界的过程更为类似。

具体地说,在计算机视觉方面,预计在6年内,我认为深度学习将会颠覆现有的所有方法。

在语音识别方面,目前还处于起步阶段,未来将会有爆发式增长。语音识别和语音合成会在近几年产生巨大的影响。语义理解方面,发展的过程将会是从单词的理解到一个句子,再到文章理解(document representation)。推荐系统和广告方面,百度做的很好,有效提高了广告表现。机器人方面,未来将会出现真正的智能机器人。

此外,就是对获取数据的创新。现在的很多研究都是基于海量数据,未来或许我们可以通过某种传感器训练摄像头来捕捉更多的数据。我甚至想和朋友在空闲的时间里,成立一个国际数据获取大会(conference of data acquisition),很遗憾,我没有这个时间。而未来的挑战将会集中在规模化和算法这两方面。
百度研究院的使命
创立coursera时,我的愿望是让每个人可以平等地获得学习的机会。如今,谁能助我成就人工智能的梦想呢?最终我选择了百度。

之所以选择百度,我看到了百度拥有大数据和强大的计算能力;有敏捷的机构,能快速地调配资源去需要的地方,也能够将技术快速落地,比如GPU的落地;同时,我被我所遇到的人所折服,比如Robin、王劲、余凯和张潼。
我相信未来百度研究院将研发出最棒的工具和技术,构建最佳的员工职业发展之路,努力打造一个最好的环境来吸引优秀工程师和研究人员加入我们,成就未来深度学习领域的英雄(future hero of Deep Learning)。
Andrew NG 自动化所演讲(20140707):DeepLearning Overview and Trends的更多相关文章
- 2014-7 Andrew Ng 自动化所报告听后感
原文:http://blog.sina.com.cn/s/blog_593af2a70102uwhl.html 一早出发,8点20就赶到现场, 人越聚越多,Ng提前几分钟到达现场,掌声一片. N ...
- 百度首席科学家 Andrew Ng谈深度学习的挑战和未来(转载)
转载:http://www.csdn.net/article/2014-07-10/2820600 人工智能被认为是下一个互联网大事件,当下,谷歌.微软.百度等知名的高科技公司争相投入资源,占领深度学 ...
- 斯坦福大学Andrew Ng教授主讲的《机器学习》公开课观后感[转]
近日,在网易公开课视频网站上看完了<机器学习>课程视频,现做个学后感,也叫观后感吧. 学习时间 从2013年7月26日星期五开始,在网易公开课视频网站上,观看由斯坦福大学Andrew Ng ...
- matlab基础教程——根据Andrew Ng的machine learning整理
matlab基础教程--根据Andrew Ng的machine learning整理 基本运算 算数运算 逻辑运算 格式化输出 小数位全局修改 向量和矩阵运算 矩阵操作 申明一个矩阵或向量 快速建立一 ...
- 机器学习笔记(一)- from Andrew Ng的教学视频
最近算是一段空闲期,不想荒废,记得之前有收藏一个机器学习的链接Andrew Ng的网易公开课,其中的overfiting部分做组会报告时涉及到了,这几天有时间决定把这部课程学完,好歹算是有个粗浅的认识 ...
- Andrew Ng机器学习入门——线性回归
本人从2017年起,开始涉猎机器学习.作为入门,首先学习的是斯坦福大学Andrew Ng(吴恩达)教授的Coursera课程 2 单变量线性回归 线性回归属于监督学习(Supervise Learni ...
- Andrew Ng机器学习课程笔记(五)之应用机器学习的建议
Andrew Ng机器学习课程笔记(五)之 应用机器学习的建议 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7368472.h ...
- Andrew Ng机器学习课程笔记--week1(机器学习介绍及线性回归)
title: Andrew Ng机器学习课程笔记--week1(机器学习介绍及线性回归) tags: 机器学习, 学习笔记 grammar_cjkRuby: true --- 之前看过一遍,但是总是模 ...
- Andrew Ng机器学习课程笔记--汇总
笔记总结,各章节主要内容已总结在标题之中 Andrew Ng机器学习课程笔记–week1(机器学习简介&线性回归模型) Andrew Ng机器学习课程笔记--week2(多元线性回归& ...
随机推荐
- SAP 权限层次
此文可是没有维护过权限的人对权限有一个整体的认知,转来加以记忆. 一是系统权限 主要是对模块为单位的权限划分,具体就是用户对该模块可见不可见,能不能对该模块进行再授权的操作.表现在用户界面就是用户登录 ...
- 乐字节Java8核心特性之Optional类
大家好啊,上次小乐给大家介绍了Java8最最重要的一个特性——Stream流,点击可以回顾哦. Optional<T>类(java.util.Optional)是一个容器类,代表一个值存在 ...
- maven包依赖问题排除
今天新引入一个包后,运行报如下错误: Exception in thread "main" java.lang.NoClassDefFoundError: scala/Produc ...
- 洛谷 P1547 Out of Hay (最小生成树)
嗯... 题目链接:https://www.luogu.org/problemnew/show/P1547 思路: 嗯...既然题中已经说了是最小生成树,那么是需要在最小生成树的模板上稍作修改即可.要 ...
- 使用navicat把一个数据库的表导入到另外一个数据库
第一步:右击数据库名,选择数据传输 第二步:全选要导的数据库表 第三步:选择目标中的数据库,然后开始就可以了
- IE8浏览器总是无响应或卡死崩溃怎么办
IE8浏览器总是无响应或卡死崩溃怎么办 2016-05-11 11:22:31 来源:百度经验 作者:qq675495787 编辑:Jimmy51 我要投稿 IE在打开某些网页的时候经常崩溃或无响应, ...
- Clion下载安装使用教程(Win+MinGW)
Clion Jetbrains旗下产品之一,主要用来开发C/C++,软件相比VS来说轻巧很多 一.Clion下载(Crack...) 链接:https://www.bicfic.com/ 你懂的,全英 ...
- svn地址迁移
关于svn设置如下: 1. 点击如果所示[Relocate]: 2. 会弹出两个框:一个让你输入用户名密码:一个是svn地址: 3. 先把svn地址改一下,然后输入用户名密码,点确定.就ok啦!
- (转)CentOS 7常见的基础命令和配置
CentOS 7常见的基础命令和配置 原文:http://blog.51cto.com/hujiangtao/1973566 管理服务 命令格式:systemctl COMMAND name.serv ...
- 基于C#编程语言的Mysql常用操作
一.开始需要先将C#中与mysql相关的引用添加进来 using MySql.Data.MySqlClient; 二.创建一个database MySqlConnection m_conn = new ...