Linux内核实践之序列文件【转】
转自:http://blog.csdn.net/bullbat/article/details/7407194
版权声明:本文为博主原创文章,未经博主允许不得转载。
作者:bullbat
seq_file机制提供了标准的例程,使得顺序文件的处理好不费力。小的文件系统中的文件,通常用户层是从头到尾读取的,其内容可能是遍历一些数据项创建的。Seq_file机制容许用最小代价实现此类文件,无论名称如何,但顺序文件是可以进行定为操作的,但其实现不怎么高效。顺序访问,即逐个访问读取数据项,显然是首选的访问模式。某个方面具有优势,通常会在其他方面付出代价。
下面我们一步一步来看看怎么编写序列文件的处理程序。对于文件、设备相关驱动程序(其实设备也是文件)的操作,我们都知道需要提供一个struct file_operations的实例。对于这里序列文件的操作,内核中附加提供了一个struct seq_operations结构,该结构很简单:
- struct seq_operations {
- void * (*start) (struct seq_file *m, loff_t *pos);
- void (*stop) (struct seq_file *m, void *v);
- void * (*next) (struct seq_file *m, void *v, loff_t *pos);
- int (*show) (struct seq_file *m, void *v);
- };
start():
主要实现初始化工作,在遍历一个链接对象开始时,调用。返回一个链接对象的偏移或SEQ_START_TOKEN(表征这是所有循环的开始)。出错返回ERR_PTR。
stop():
当所有链接对象遍历结束时调用。主要完成一些清理工作。
next():
用来在遍历中寻找下一个链接对象。返回下一个链接对象或者NULL(遍历结束)。
show():
对遍历对象进行操作的函数。主要是调用seq_printf(), seq_puts()之类的函数,打印出这个对象节点的信息。
由于c语言中任何数据类型的数据块都可以转化为数据块的内存基址(指针)+数据块大小来传递,不难想到基于我们上面提供的函数,将我们操作的数据用于序列文件的读写、定为、释放等操作完全可以通用话。内核也为我们提供了这些用于读写、定位、释放等操作的通用函数。当然这些操作需要数据结构的支持(比如读取当前位置、数据大小等等),这就是在后面我们会看到的struct seq_file结构。由于我们读写的是文件,在内核中必须提供一个struct file_operations结构的实例,我们可以直接用内核为我们提供的上述函数,并且重写file_operatios结构的open方法,用该方法将虚拟文件系统关联到我们处理的序列文件,那么那些通用的读写函数就可以正常工作了。原理基本上是这样的,下面我们看怎么用file_operatios结构的open方法将我们的序列文件关联到虚拟文件系统。在此之前,我们看看序列文件的表示结构struct seq_file:
- struct seq_file {
- char *buf;
- size_t size;
- size_t from;
- size_t count;
- loff_t index;
- loff_t read_pos;
- u64 version;
- struct mutex lock;
- const struct seq_operations *op;
- void *private;
- };
Buf指向一个内存缓冲区,用于构建传输给用户层的数据。Count指定了需要传输到用户层的剩余的字节数。复制操作的起始位置由from指定,而size给出了缓冲区总的字节数。Index是缓冲区的另一个索引。他标记了内核向缓冲区写入下一个新纪录的起始位置。要注意的是,index和from的演变过程是不同的,因为从内核向缓冲区写入数据,与将这些数据复制到用户空间,这两种操作是不同的。
一般情况,对于序列文件,我们的文件操作实例如下:
- static struct file_operations my_operations={
- .open =my_open,
- .read =seq_read,
- .llseek =seq_lseek,
- .release =seq_release,
- };
其中,my_open函数需要我们重写的,也是我们将其用于关联我们的序列文件。其他都是内核为我们实现好的,在后面我们会详细介绍。
- static int my_open(struct inode *inode,struct file *filp)
- {
- return seq_open(filp,&my_seq_operations);
- }
我们这里调用seq_open函数建立这种关联。
- int seq_open(struct file *file, const struct seq_operations *op)
- {
- struct seq_file *p = file->private_data;/*p为seq_file结构实例*/
- if (!p) {
- p = kmalloc(sizeof(*p), GFP_KERNEL);
- if (!p)
- return -ENOMEM;
- file->private_data = p;/*放到file的private_data中*/
- }
- memset(p, 0, sizeof(*p));
- mutex_init(&p->lock);
- p->op = op;/*设置seq_file的operation为op*/
- /*
- * Wrappers around seq_open(e.g. swaps_open) need to be
- * aware of this. If they set f_version themselves, they
- * should call seq_open first and then set f_version.
- */
- file->f_version = 0;
- /*
- * seq_files support lseek() and pread(). They do not implement
- * write() at all, but we clear FMODE_PWRITE here for historical
- * reasons.
- *
- * If a client of seq_files a) implements file.write() and b) wishes to
- * support pwrite() then that client will need to implement its own
- * file.open() which calls seq_open() and then sets FMODE_PWRITE.
- */
- file->f_mode &= ~FMODE_PWRITE;
- return 0;
- }
可以看到,我们的seq_file结构以file的私有数据字段传入虚拟文件系统,同时在open函数中设置了seq_file的操作实例。
我们看下面这个简单的例子:
- #include <linux/init.h>
- #include <linux/module.h>
- #include <linux/kernel.h>
- #include <linux/proc_fs.h>
- #include <linux/seq_file.h>
- #define MAX_SIZE 10
- MODULE_LICENSE("GPL");
- MODULE_AUTHOR("Mike Feng");
- /*用于操作的数据*/
- struct my_data
- {
- int data;
- };
- /*全局变量*/
- struct my_data *md;
- /*数据的申请*/
- struct my_data* my_data_init(void)
- {
- int i;
- md=(struct my_data*)kmalloc(MAX_SIZE*sizeof(struct my_data),GFP_KERNEL);
- for(i=0;i<MAX_SIZE;i++)
- (md+i)->data=i;
- return md;
- }
- /*seq的start函数,仅仅做越界判断然后返回pos*/
- void *my_seq_start(struct seq_file *file,loff_t *pos)
- {
- return (*pos<MAX_SIZE)? pos :NULL;
- }
- /*seq的next函数,仅仅做越界判断然后pos递增*/
- void *my_seq_next(struct seq_file *p,void *v,loff_t *pos)
- {
- (*pos)++;
- if(*pos>=MAX_SIZE)
- return NULL;
- return pos;
- }
- /*seq的show函数,读数据的显示*/
- int my_seq_show(struct seq_file *file,void *v)
- {
- unsigned int i=*(loff_t*)v;
- seq_printf(file,"The %d data is:%d\n",i,(md+i)->data);
- return 0;
- }
- /*seq的stop函数,什么也不做*/
- void my_seq_stop(struct seq_file *file,void *v)
- {
- }
- /*operations of seq_file */
- static const struct seq_operations my_seq_ops={
- .start =my_seq_start,
- .next =my_seq_next,
- .stop =my_seq_stop,
- .show =my_seq_show,
- };
- /*file的open函数,用于seq文件与虚拟文件联系*/
- static int my_open(struct inode *inode,struct file *filp)
- {
- return seq_open(filp,&my_seq_ops);
- }
- /*file操作*/
- static const struct file_operations my_file_ops={
- .open =my_open,
- .read =seq_read,
- .llseek =seq_lseek,
- .release=seq_release,
- .owner =THIS_MODULE,
- };
- static __init int my_seq_init(void)
- {
- struct proc_dir_entry *p;
- my_data_init();
- p=create_proc_entry("my_seq",0,NULL);
- if(p)
- {
- p->proc_fops=&my_file_ops;
- }
- return 0;
- }
- static void my_seq_exit(void)
- {
- remove_proc_entry("my_seq",NULL);
- }
- module_init(my_seq_init);
- module_exit(my_seq_exit);
实验与结果:
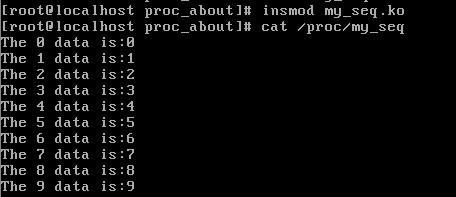
你可能会好奇,上面的结果是怎么得到的。当我们用命令cat /proc/my_seq时,即是读取文件/proc/my_seq,而在我们的程序中,my_seq文件绑定到了我们给定的文件操作(p->proc_fops=&my_file_ops;)。那么很自然想到,他是调用my_file_ops中的.read函数,即seq_read函数,我们看看这个函数在内核中是怎么实现的(<fs/seq_file.c>)。
ssize_t seq_read(struct file *file, char __user *buf, size_t size, loff_t *ppos)
{
struct seq_file *m = (struct seq_file *)file->private_data;
……
/* we need at least one record in buffer */
pos = m->index;
p = m->op->start(m, &pos);
while (1) {
err = PTR_ERR(p);
if (!p || IS_ERR(p))
break;
err = m->op->show(m, p);
if (err < 0)
break;
if (unlikely(err))
m->count = 0;
if (unlikely(!m->count)) {
p = m->op->next(m, p, &pos);
m->index = pos;
continue;
}
if (m->count < m->size)
goto Fill;
m->op->stop(m, p);
kfree(m->buf);
m->buf = kmalloc(m->size <<= 1, GFP_KERNEL);
if (!m->buf)
goto Enomem;
m->count = 0;
m->version = 0;
pos = m->index;
p = m->op->start(m, &pos);
}
m->op->stop(m, p);
m->count = 0;
goto Done;
……
}
该函数代码比较长,我们只看while循环部分,也即循环打印的过程,我们从红色代码部分可以看出程序循环调用seq_file操作的start、show、next、stop函数,直到读完数据。而start返回的值传入了next和stop函数(就是我们的序列文件读指针索引,在next中为void*类型)。
除了上面的描述,内核还为我们提供了一系列辅助函数,比如single_open函数只需要我们重写show函数即可,需要用的话可以查看相关的代码,了解其定义。这里,我们看看对于内核链表组织的数据seq_file是怎么使用的。
程序文件(list_seq.c):
- #include <linux/init.h>
- #include <linux/module.h>
- #include <linux/kernel.h>
- #include <linux/mutex.h>
- #include <linux/proc_fs.h>
- #include <linux/seq_file.h>
- #define N 10
- MODULE_LICENSE("GPL");
- MODULE_AUTHOR("Mike Feng");
- /*对内核链表操作需要加锁*/
- static struct mutex lock;
- static struct list_head head;
- struct my_data
- {
- struct list_head list;
- int value;
- };
- /*链表的插入元素*/
- struct list_head* insert_list(struct list_head *head,int value)
- {
- struct my_data *md=NULL;
- mutex_lock(&lock);
- md=(struct my_data*)kmalloc(sizeof(struct my_data),GFP_KERNEL);
- if(md)
- {
- md->value=value;
- list_add(&md->list,head);
- }
- mutex_unlock(&lock);
- return head;
- }
- /*打印,传入参数v为open函数返回的,链表需要操作的节点*/
- static int list_seq_show(struct seq_file *file,void *v)
- {
- struct list_head *list=(struct list_head*)v;
- struct my_data *md=list_entry(list,struct my_data,list);
- seq_printf(file,"The value of my data is:%d\n",md->value);
- return 0;
- }
- static void *list_seq_start(struct seq_file *file,loff_t *pos)
- {
- /*加锁*/
- mutex_lock(&lock);
- return seq_list_start(&head,*pos);
- }
- static void *list_seq_next(struct seq_file *file,void *v,loff_t *pos)
- {
- return seq_list_next(v,&head,pos);
- }
- static void list_seq_stop(struct seq_file *file,void *v)
- {
- /*解锁*/
- mutex_unlock(&lock);
- }
- static struct seq_operations list_seq_ops=
- {
- .start =list_seq_start,
- .next =list_seq_next,
- .stop =list_seq_stop,
- .show =list_seq_show,
- };
- static int list_seq_open(struct inode *inode,struct file *file)
- {
- return seq_open(file,&list_seq_ops);
- }
- static struct file_operations my_file_ops=
- {
- .open =list_seq_open,
- .read =seq_read,
- .write =seq_write,
- .llseek =seq_lseek,
- .release=seq_release,
- .owner =THIS_MODULE,
- };
- static __init int list_seq_init(void)
- {
- struct proc_dir_entry *entry;
- int i;
- mutex_init(&lock);
- INIT_LIST_HEAD(&head);
- for(i=0;i<N;i++)
- head=*(insert_list(&head,i));
- entry=create_proc_entry("list_seq",0,NULL);
- if(entry)
- entry->proc_fops=&my_file_ops;
- return 0;
- }
- static void list_seq_exit(void)
- {
- struct my_data *md=NULL;
- remove_proc_entry("list_seq",NULL);
- while(!list_empty(&head))
- {
- md=list_entry((&head)->next,struct my_data,list);
- list_del(&md->list);
- kfree(md);
- }
- }
- module_init(list_seq_init);
- module_exit(list_seq_exit);
测试试验结果:
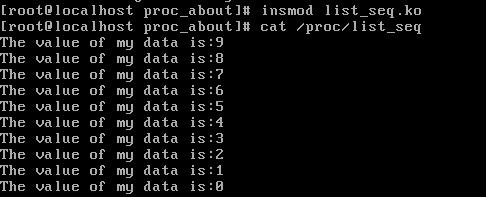
由于内核函数list_add为前插,所以打出的数据为倒序的。
序列文件的实现基于proc文件系统,下一步将对其进行分析学习。
Linux内核实践之序列文件【转】的更多相关文章
- 在windows下解压缩Linux内核源代码出现重复文件原因
在windows下解压缩Linux内核源代码出现重复文件原因 2009年06月30日 13:35 来源:ChinaUnix博客 作者:embededgood 编辑:周荣茂 原因一.因为在Lin ...
- Linux内核 实践二
实践二 内核模块编译 20135307 张嘉琪 一.实验原理 Linux模块是一些可以作为独立程序来编译的函数和数据类型的集合.之所以提供模块机制,是因为Linux本身是一个单内核.单内核由于所有内容 ...
- linux内核驱动中对文件的读写 【转】
本文转载自:http://blog.chinaunix.net/uid-13059007-id-5766941.html 有时候需要在Linux kernel--大多是在需要调试的驱动程序--中读写文 ...
- Linux内核笔记--深入理解文件描述符
内核版本:linux-2.6.11 文件描述符(file descriptor)在Linux编程里随处可见,设备读写.网络通信.进程通信,fd可谓是关键中的关键. 深入理解可以增加我们使用它的信心. ...
- Linux内核访问用户空间文件:get_fs()/set_fs()的使用
测试环境:Ubuntu 14.04+Kernel 4.4.0-31 关键词:KERNEL_DS.USER_DS.get_fs().set_fs().addr_limit.access_ok. 参考代码 ...
- Linux内核0.11 setup文件说明
一.总体功能介绍 这是关于Linux-kernel-0.11中boot文件夹下setup.s源文件的实现功能的总结说明. setup.s是一个操作系统加载程序,它的主要功能是利用BIOS中断读取机器系 ...
- Linux内核0.11 makefile文件说明
# # if you want the ram-disk device, define this to be the # size in blocks. # 如果要使用 RAM 就定义块的大小(注释掉 ...
- Linux内核分析:打开文件描述符实现
在Linux中每一个进程的数据是存储在一个task_struct结构(定义在sched.h中)中的. struct task_struct { volatile long state; /* -1 u ...
- Linux内核0.11 bootsect文件说明
一.总体功能介绍 这是关于Linux-kernel-0.11中boot文件夹下bootsect.s源文件的说明,其中涉及到了一些基础知识可以参考这两篇文章. 操作系统启动过程 软盘相关知识和通过BIO ...
随机推荐
- Leetcode 337. 打家劫舍 III
题目链接 https://leetcode.com/problems/house-robber-iii/description/ 题目描述 在上次打劫完一条街道之后和一圈房屋后,小偷又发现了一个新的可 ...
- 笔记-git-协作开发
笔记-git-协作开发 1. git协作开发 git协作的典型做法是,创建一个git服务器,被多个人操作. 示意图如下: 一般来说协作分为如下几个步骤: 创建一个git裸服务器 (git i ...
- vue 组件间数据传递
父组件向子组件传值 方法一: 子组件想要使用父组件的数据,需要通过子组件的 props 选项来获得父组件传过来的数据. 1.父组件parent.vue中代码: <template> < ...
- storm集群安装部署
安装步骤: 搭建Zookeeper集群: 安装Storm依赖库: 下载并解压Storm发布版本: 修改storm.yaml配置文件: 启动Storm各个后台进程. 1. 搭建Zookeeper集群 这 ...
- CNN:
(1)卷积:对图像元素的矩阵变换,是提取图像特征的方法,多种卷积核可以提取多种特征.一个卷积核覆盖的原始图像的范围叫做感受野(权值共享).一次卷积运算提取的特征往往是局部的,难以提取出比较全局的特征, ...
- windows系统如何查看某个端口被谁占用
1.开始---->运行---->cmd,或者是window+R组合键,调出命令窗口 2.输入命令:netstat -ano,列出所有端口的情况.在列表中我们观察被占用的端口,比如是135, ...
- 手把手教你如何逐步安装OpenStack
[TechTarget中国原创] 尽管OpenStack官方提供的在线安装教程和分步向导能够为管理员提供很大帮助,但是依然存在很多不尽如人意的地方.因此在Ubuntu上安装OpenStack的过程当中 ...
- 为什么要内存对齐 Data alignment: Straighten up and fly right
转载于http://blog.csdn.net/lgouc/article/details/8235471 为了速度和正确性,请对齐你的数据. 概述:对于所有直接操作内存的程序员来说,数据对齐都是很重 ...
- PyCharm 解决有些库(函数)没有代码提示
问题描述: 如图,当输入 im. 没有智能提示第三库相应的函数或其他提示. 解决方案: python是动态强类型语言,IDE无法判断Image.open("panda.png")的 ...
- pdb在python程序中应用
1.什么是pdb? pdb是python提供的调试程序的一种工具. 2.为什么需要pdb模块? 当我们的程序越写越大的时候,我们用print xxx 这种方式打断点,调试,非常不方便,这个时候我们需要 ...