hive 存储格式及压缩
-- 设置参数
set hivevar:target_db_name=db_dw;
use ${hivevar:target_db_name}; -- 创建textfile表
create table file_format_textfile
row format delimited fields terminated by '\001'
stored as textfile
as
select * from smple_table; -- 测试各种压缩的orc表
create table file_format_orc_zlib
row format delimited fields terminated by '\001'
stored as orc tblproperties ("orc.compress"="ZLIB")
as
select * from file_format_textfile
; create table file_format_orc_snappy
row format delimited fields terminated by '\001'
stored as orc tblproperties ("orc.compress"="SNAPPY")
as
select * from file_format_orc_zlib
; create table file_format_orc_none
row format delimited fields terminated by '\001'
stored as orc tblproperties ("orc.compress"="NONE")
as
select * from file_format_orc_zlib
; create table file_format_orc_default
row format delimited fields terminated by '\001'
stored as orc
as
select * from file_format_orc_zlib
; -- 测试各种压缩的parquet表
create table file_format_parquet_zlib
row format delimited fields terminated by '\001'
stored as parquet tblproperties ("parquet.compress"="ZLIB")
as
select * from file_format_orc_zlib
; create table file_format_parquet_snappy
row format delimited fields terminated by '\001'
stored as parquet tblproperties ("parquet.compress"="SNAPPY")
as
select * from file_format_orc_zlib
; create table file_format_parquet_none
row format delimited fields terminated by '\001'
stored as parquet tblproperties ("parquet.compress"="NONE")
as
select * from file_format_orc_zlib
; create table file_format_parquet_default
row format delimited fields terminated by '\001'
stored as parquet
as
select * from file_format_orc_zlib
; -- 测试各种压缩的rcfile表(可能参数没生效,各种压缩后大小一致)
create table file_format_rcfile_zlib
row format delimited fields terminated by '\001'
stored as rcfile tblproperties ("rcfile.compress"="ZLIB")
as
select * from file_format_orc_zlib
; create table file_format_rcfile_snappy
row format delimited fields terminated by '\001'
stored as rcfile tblproperties ("rcfile.compress"="SNAPPY")
as
select * from file_format_orc_zlib
; create table file_format_rcfile_none
row format delimited fields terminated by '\001'
stored as rcfile tblproperties ("rcfile.compress"="NONE")
as
select * from file_format_orc_zlib
; create table file_format_rcfile_default
row format delimited fields terminated by '\001'
stored as rcfile
as
select * from file_format_orc_zlib
;
-- 查看各种压缩下的格式大小
dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_textfile; dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_orc_zlib;
dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_orc_snappy;
dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_orc_none;
dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_orc_default; dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_parquet_zlib;
dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_parquet_snappy;
dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_parquet_none;
dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_parquet_default; dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_rcfile_zlib;
dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_rcfile_snappy;
dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_rcfile_none;
dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_rcfile_default;
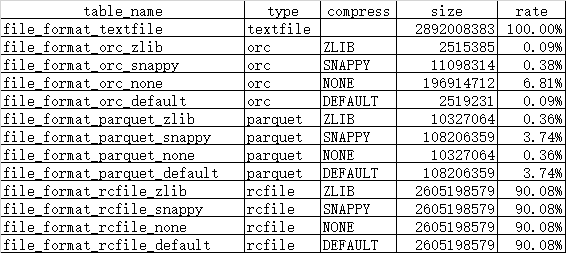
-- 统计数据,原文件见文件中的附件
hive 存储格式及压缩的更多相关文章
- Hive存储格式之RCFile详解,RCFile的过去现在和未来
我在整理Hive的存储格式和压缩格式,本来打算一篇发出来,结果其中一小节就有很多内容,于是打算写成Hive存储格式和压缩格式系列. 本节主要讲一下Hive存储格式最早的典型的列式存储格式RCFile. ...
- Hive存储格式之ORC File详解,什么是ORC File
目录 概述 文件存储结构 Stripe Index Data Row Data Stripe Footer 两个补充名词 Row Group Stream File Footer 条纹信息 列统计 元 ...
- Hadoop、Hive【LZO压缩配置和使用】
目录 一.编译 二.相关配置 三.为LZO文件创建索引 四.Hive为LZO文件建立索引 1.hive创建的lzo压缩的分区表 2.给.lzo压缩文件建立索引index 3.读取Lzo文件的注意事项( ...
- Hive性能调优(一)----文件存储格式及压缩方式选择
合理使用文件存储格式 建表时,尽量使用 orc.parquet 这些列式存储格式,因为列式存储的表,每一列的数据在物理上是存储在一起的,Hive查询时会只遍历需要列数据,大大减少处理的数据量. 采用合 ...
- hive 存储格式对比
Apache Hive支持Apache Hadoop中使用的几种熟悉的文件格式,如TextFile,RCFile,SequenceFile,AVRO,ORC和Parquet格式. Cloudera I ...
- Hive(十一)【压缩、存储】
目录 一.Hadoop的压缩配置 1.MR支持的压缩编码 2.压缩参数配置 3.开启Mapper输出阶段压缩 4.开启Reduceer输出阶段 二.文件存储 1.列式存储和行式存储 2.TextFil ...
- hive 存储格式
hive有textFile,SequenceFile,RCFile三种文件格式. textfile为默认格式,建表时不指定默认为这个格式,导入数据时会直接把数据文件拷贝到hdfs上不进行处理. Seq ...
- hive表的存储格式; ORC格式的使用
hive表的源文件存储格式有几类: 1.TEXTFILE 默认格式,建表时不指定默认为这个格式,导入数据时会直接把数据文件拷贝到hdfs上不进行处理.源文件可以直接通过hadoop fs -cat 查 ...
- Hive文件存储格式和hive数据压缩
一.存储格式行存储和列存储 二.Hive文件存储格式 三.创建语句和压缩 一.存储格式行存储和列存储 行存储可以理解为一条记录存储一行,通过条件能够查询一整行数据. 列存储,以字段聚集存储,可以理解为 ...
随机推荐
- [xdoj1007]易碎的鸟蛋(dp)
解题思路:f[n,m]表示n层楼.m个鸡蛋时所需要的最小次数,则 转移方程为:f[n,m] = min{ 1+max(f[i-1,m-1], f[n-i,m]) | i=1..n }初始条件:f[i, ...
- Ros学习topic——小海龟
ROS Topics 1.rqt_graph:创建一个显示当前系统运行情况的动态图形 安装 $ sudo apt-get install ros-<distro>-rqt $ sudo a ...
- Opengl创建几何实体——四棱锥和立方体
//#include <gl\glut.h>#include <GL\glut.h>#include <iostream> using namespace std; ...
- ubuntu16.04安装labelme
1.安装Anaconda 下载 官方下载地址:https://www.continuum.io/downloads 所有安装包地址:https://repo.continuum.io/archive/ ...
- C++ 结构体的构造函数和析构函数
在C++中除了类中可以有构造函数和析构函数外,结构体中也可以包含构造函数和析构函数,这是因为结构体和类基本雷同,唯一区别是,类中成员变量默认为私有,而结构体中则为公有.注意,C++中的结构体是可以有析 ...
- JavaPersistenceWithHibernate第二版笔记-第六章-Mapping inheritance-004Table per class hierarchy(@Inheritance..SINGLE_TABLE)、@DiscriminatorColumn、@DiscriminatorValue、@DiscriminatorFormula)
一.结构 You can map an entire class hierarchy to a single table. This table includes columns for all pr ...
- RowGame TopCoder - 10664
传送门 分析 首先不难想到O(k)做法,即dpi表示进行了几次,但复杂度明显爆炸,所以思考更优做法.我们发现数字个数很小,仅为可怜的50,所以从这里找突破口.我们发现每次可以在一个固定区域内进行刷分活 ...
- java 使用simpleDateFormat格式化日期 时间.RP
首先了解一下格式化日志的所有表示. 时间日期标识符: yyyy:年 MM:月 dd:日 hh:1~12小时制(1-12) HH:24小时制(0-23) mm:分 ss:秒 S:毫秒 E:星期几 D:一 ...
- SDUT 2107 图的深度遍历
图的深度遍历 Time Limit: 1000MS Memory Limit: 65536KB Submit Statistic Problem Description 请定一个无向图,顶点编号从0到 ...
- MacBook Pro (13 英寸, 2012 年中)安装win7系统
准备: windows7 ISO镜像 16G或更大U盘(提前备份,需要格式化) Apple 官方提供的 windows7驱动程序 详细步骤: 1.打开Bootcamp,选择前两个选择点击继续,选择下载 ...