牛客网Java刷题知识点之字符流缓冲区、BufferedWriter、BufferedReader、BufferedReader-readLine方法原理、自定义MyBufferedReader-read方法、自定义MyBufferedReader-readLine方法
不多说,直接上干货!
把提高效率的动作,封装成一个对象。即把缓冲区封装成一个对象。
就是在一个类里封装一个数组,能对流锁操作数据进行缓存。
什么是字符流缓冲区?
善于使用字符流缓冲区,减轻负担,提高下效率。
其实啊,无非是将源中数据,存储到自定义数组里,进行缓存。并对数组操作,从而提高效率。
即BufferedReader 比 FileReader要增强。
BufferedWriter 比 FileWriter要增强。
什么情况下需要使用字符流缓冲区?
先从一个例子,来由浅入深的
为了提高写入的效率,需引入字符流的缓冲区。
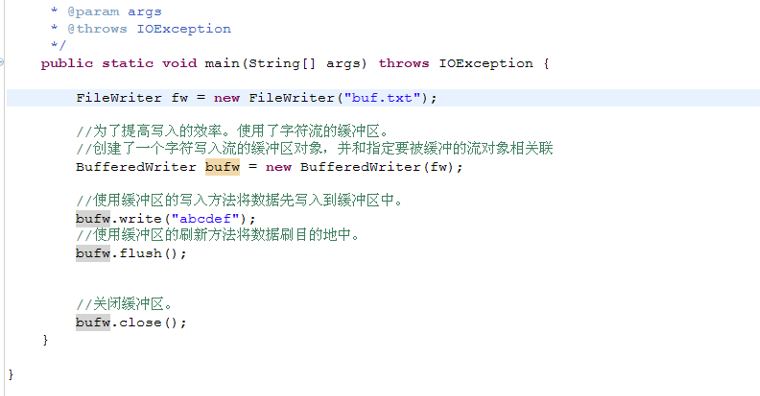
BufferedWriterDemo.java
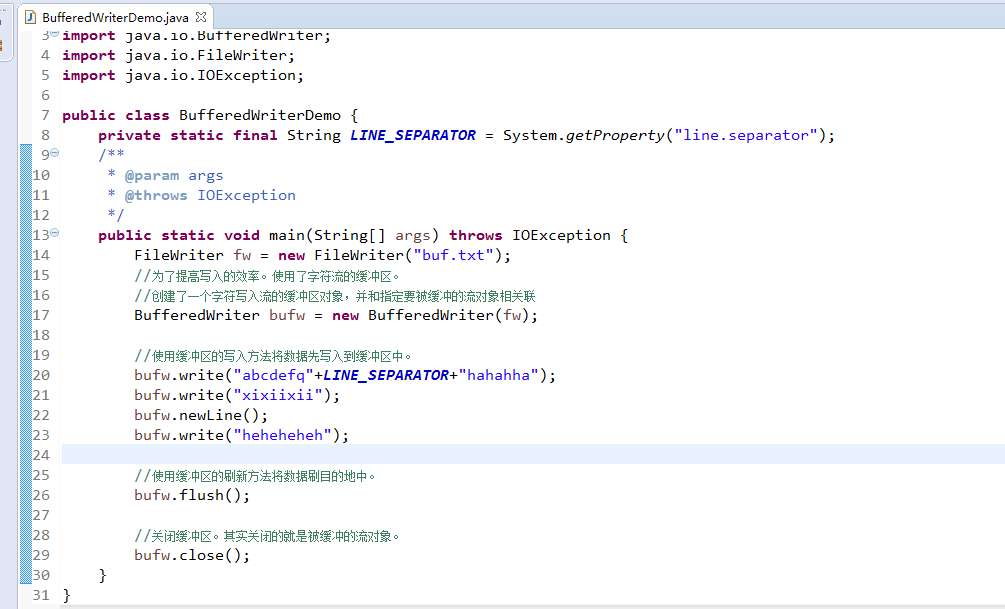
package zhouls.bigdata.DataFeatureSelection.test; import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException; public class BufferedWriterDemo {
private static final String LINE_SEPARATOR = System.getProperty("line.separator");
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
FileWriter fw = new FileWriter("buf.txt");
//为了提高写入的效率。使用了字符流的缓冲区。
//创建了一个字符写入流的缓冲区对象,并和指定要被缓冲的流对象相关联
BufferedWriter bufw = new BufferedWriter(fw); //使用缓冲区的写入方法将数据先写入到缓冲区中。
bufw.write("abcdefq"+LINE_SEPARATOR+"hahahha");
bufw.write("xixiixii");
bufw.newLine();
bufw.write("heheheheh"); //使用缓冲区的刷新方法将数据刷目的地中。
bufw.flush(); //关闭缓冲区。其实关闭的就是被缓冲的流对象。
bufw.close();
}
}
由fw变成bufw
同样,为了读取的效率,引入字符流缓冲区。
BufferedReaderDemo.java
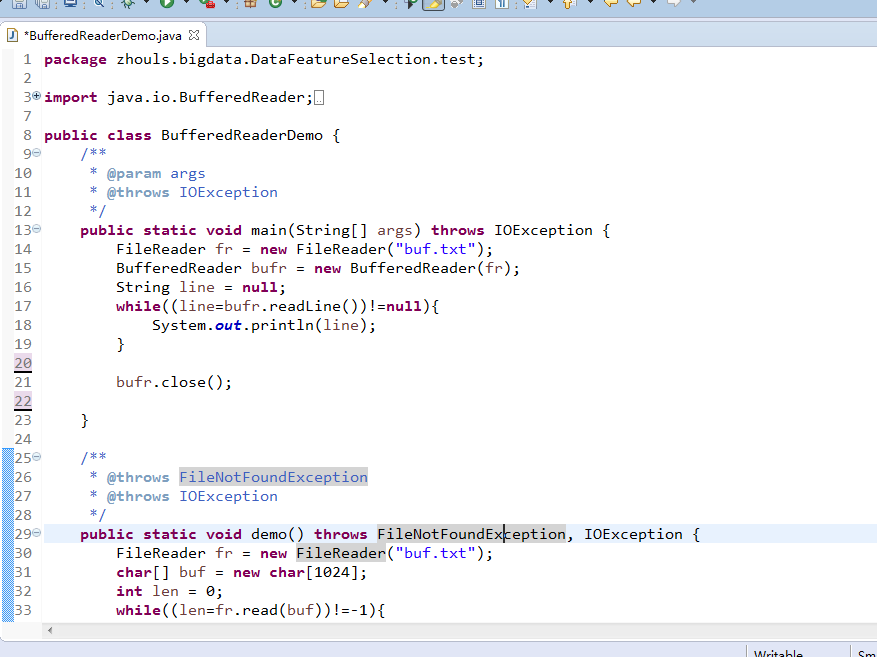
package zhouls.bigdata.DataFeatureSelection.test; import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException; public class BufferedReaderDemo {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
FileReader fr = new FileReader("buf.txt");
BufferedReader bufr = new BufferedReader(fr);
String line = null;
while((line=bufr.readLine())!=null){
System.out.println(line);
} bufr.close(); } /**
* @throws FileNotFoundException
* @throws IOException
*/
public static void demo() throws FileNotFoundException, IOException {
FileReader fr = new FileReader("buf.txt");
char[] buf = new char[];
int len = ;
while((len=fr.read(buf))!=-){
System.out.println(new String(buf,,len));
}
fr.close();
}
}
BufferedReader-readLine方法原理
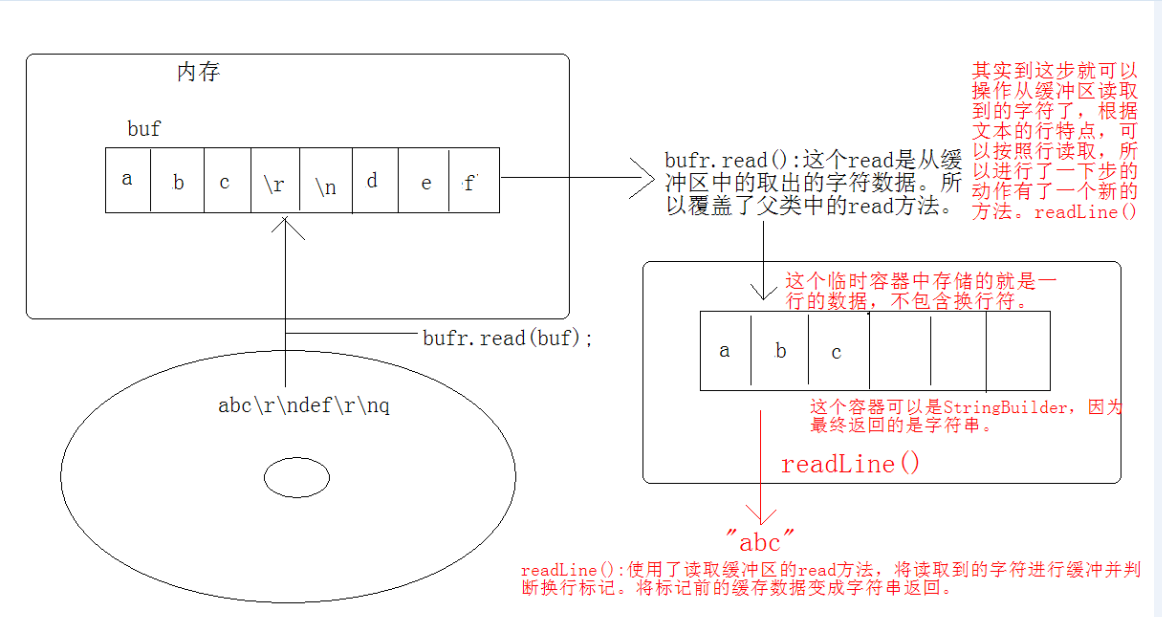
自定义MyBufferedReader-read方法和自定义MyBufferedReader-readLine方法
MyBufferedReader.java
其实啊,无非是将源中数据,存储到自定义数组里,进行缓存。并对数组操作,从而提高效率。
即BufferedReader 比 FileReader要增强。
BufferedWriter 比 FileWriter要增强。
package zhouls.bigdata.DataFeatureSelection.test; import java.io.FileReader;
import java.io.IOException;
import java.io.Reader; /**
* 自定义的读取缓冲区。其实就是模拟一个BufferedReader.
*
* 分析:
* 缓冲区中无非就是封装了一个数组,
* 并对外提供了更多的方法对数组进行访问。
* 其实这些方法最终操作的都是数组的角标。
*
* 缓冲的原理:
* 其实就是从源中获取一批数据装进缓冲区中。
* 在从缓冲区中不断的取出一个一个数据。
*
* 在此次取完后,在从源中继续取一批数据进缓冲区。
* 当源中的数据取光时,用-1作为结束标记。
*
* @author Administrator
*/ public class MyBufferedReader extends Reader {
private Reader r; //定义一个数组作为缓冲区。
private char[] buf = new char[]; //定义一个指针用于操作这个数组中的元素。当操作到最后一个元素后,指针应该归零。
private int pos = ; //定义一个计数器用于记录缓冲区中的数据个数。 当该数据减到0,就从源中继续获取数据到缓冲区中。
private int count = ; MyBufferedReader(Reader r){
this.r = r;
} /**
* 该方法从缓冲区中一次取一个字符。
* @return
* @throws IOException
*/
public int myRead() throws IOException{
if(count==){
count = r.read(buf);
pos = ;
}
if(count<)
return -;
char ch = buf[pos++];
count--;
return ch; /*
//1,从源中获取一批数据到缓冲区中。需要先做判断,只有计数器为0时,才需要从源中获取数据。
if(count==0){
count = r.read(buf); if(count<0)
return -1; //每次获取数据到缓冲区后,角标归零.
pos = 0;
char ch = buf[pos]; pos++;
count--; return ch; }else if(count>0){ char ch = buf[pos]; pos++;
count--; return ch; }*/
} public String myReadLine() throws IOException{
StringBuilder sb = new StringBuilder();
int ch = ;
while((ch = myRead())!=-){
if(ch=='\r')
continue;
if(ch=='\n')
return sb.toString();
//将从缓冲区中读到的字符,存储到缓存行数据的缓冲区中。
sb.append((char)ch);
}
if(sb.length()!=)
return sb.toString();
return null;
} public void myClose() throws IOException {
r.close();
} public int read(char[] cbuf, int off, int len) throws IOException { return ;
} public void close() throws IOException {
}
}
MyBufferedReaderDemo.java
package zhouls.bigdata.DataFeatureSelection.test; import java.io.FileReader;
import java.io.IOException;
import java.util.Collections;
import java.util.HashMap; public class MyBufferedReaderDemo {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
FileReader fr = new FileReader("buf.txt");
MyBufferedReader bufr = new MyBufferedReader(fr);
String line = null;
while((line=bufr.myReadLine())!=null){
System.out.println(line);
}
bufr.myClose();
Collections.reverseOrder();
HashMap map = null;
map.values();
}
}
牛客网Java刷题知识点之字符流缓冲区、BufferedWriter、BufferedReader、BufferedReader-readLine方法原理、自定义MyBufferedReader-read方法、自定义MyBufferedReader-readLine方法的更多相关文章
- 牛客网Java刷题知识点之为什么HashMap和HashSet区别
不多说,直接上干货! HashMap 和 HashSet的区别是Java面试中最常被问到的问题.如果没有涉及到Collection框架以及多线程的面试,可以说是不完整.而Collection框架的 ...
- 牛客网Java刷题知识点之为什么HashMap不支持线程的同步,不是线程安全的?如何实现HashMap的同步?
不多说,直接上干货! 这篇我是从整体出发去写的. 牛客网Java刷题知识点之Java 集合框架的构成.集合框架中的迭代器Iterator.集合框架中的集合接口Collection(List和Set). ...
- 牛客网Java刷题知识点之Map的两种取值方式keySet和entrySet、HashMap 、Hashtable、TreeMap、LinkedHashMap、ConcurrentHashMap 、WeakHashMap
不多说,直接上干货! 这篇我是从整体出发去写的. 牛客网Java刷题知识点之Java 集合框架的构成.集合框架中的迭代器Iterator.集合框架中的集合接口Collection(List和Set). ...
- 牛客网Java刷题知识点之ArrayList 、LinkedList 、Vector 的底层实现和区别
不多说,直接上干货! 这篇我是从整体出发去写的. 牛客网Java刷题知识点之Java 集合框架的构成.集合框架中的迭代器Iterator.集合框架中的集合接口Collection(List和Set). ...
- 牛客网Java刷题知识点之垃圾回收算法过程、哪些内存需要回收、被标记需要清除对象的自我救赎、对象将根据存活的时间被分为:年轻代、年老代(Old Generation)、永久代、垃圾回收器的分类
不多说,直接上干货! 首先,大家要搞清楚,java里的内存是怎么分配的.详细见 牛客网Java刷题知识点之内存的划分(寄存器.本地方法区.方法区.栈内存和堆内存) 哪些内存需要回收 其实,一般是对堆内 ...
- 牛客网Java刷题知识点之HashMap的实现原理、HashMap的存储结构、HashMap在JDK1.6、JDK1.7、JDK1.8之间的差异以及带来的性能影响
不多说,直接上干货! 福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 ...
- 牛客网Java刷题知识点之UDP协议是否支持HTTP和HTTPS协议?为什么?TCP协议支持吗?
不多说,直接上干货! 福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 ...
- 牛客网Java刷题知识点之TCP、UDP、TCP和UDP的区别、socket、TCP编程的客户端一般步骤、TCP编程的服务器端一般步骤、UDP编程的客户端一般步骤、UDP编程的服务器端一般步骤
福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 Java全栈大联盟 ...
- 牛客网Java刷题知识点之Java 集合框架的构成、集合框架中的迭代器Iterator、集合框架中的集合接口Collection(List和Set)、集合框架中的Map集合
不多说,直接上干货! 集合框架中包含了大量集合接口.这些接口的实现类和操作它们的算法. 集合容器因为内部的数据结构不同,有多种具体容器. 不断的向上抽取,就形成了集合框架. Map是一次添加一对元素. ...
随机推荐
- widget自定义控件【android.view.InflateException: Binary XML file line #2: Error inflating class...】
此错误比较难定位,场景是这样的:在一个widget中使用了自定义控件,始终会报 android.view.InflateException: Binary XML file line #2: Erro ...
- 2015年第六届蓝桥杯省赛试题(JavaA组)
1.结果填空 (满分3分)2.结果填空 (满分5分)3.结果填空 (满分9分)4.代码填空 (满分11分)5.代码填空 (满分13分)6.结果填空 (满分17分)7.结果填空 (满分21分)8.程序设 ...
- Locust学习总结分享
简介: Locust是一个用于可扩展的,分布式的,性能测试的,开源的,用Python编写框架/工具,它非常容易使用,也非常好学.它的主要思想就是模拟一群用户将访问你的网站.每个用户的行为由你编写的py ...
- fopen_s()
原型:errno_t fopen_s( FILE** pFile, const char *filename, const char *mode ); 例子: char *filePath=&q ...
- JAVA环境的JAVA_HOME, PATH 和CLASS_PATH设置
Windows下JAVA用到的环境变量主要有3个,JAVA_HOME.CLASSPATH.PATH.下面逐个分析. 简单来讲, 1.path是os用 classpath java用 JAVA_HOME ...
- poj3167(kmp)
题目链接: http://poj.org/problem?id=3167 题意: 给出两串数字 s1, s2, 求主串 s1 中的 s2 匹配数并输出每个匹配的开头位置. 区间 [l, r] 是 s2 ...
- 关于Login failed. The login is from an untrusted domain and cannot be used with Windows authentication.的问题
远程连接数据库的问题 connectionString="Data Source =IP; Initial Catalog=movies;User ID=sa;Password=1qaz2w ...
- 洛谷P1894 [USACO4.2]完美的牛栏The Perfect Stall
题目描述 农夫约翰上个星期刚刚建好了他的新牛棚,他使用了最新的挤奶技术.不幸的是,由于工程问题,每个牛栏都不一样.第一个星期,农夫约翰随便地让奶牛们进入牛栏,但是问题很快地显露出来:每头奶牛都只愿意在 ...
- springboot整合mybatis,redis,代码(三)
一 说明 接着上篇讲述redis缓存配置的用法: 二 正文 首先要使用缓存就必须要开开启缓存,第二步是需要开redis-server 下载redis包之后,点击图中两个都可以开启redis 怎么看是否 ...
- main.obj:-1: error: LNK2001: 无法解析的外部符号 "public: virtual struct QMetaObject const * __thiscall CustomButton::metaObject(void)const " (?metaObject@CustomButton@@UBEPBUQMetaObject@@XZ)
QTCreator 运行时报错 main.obj:-1: error: LNK2001: 无法解析的外部符号 "public: virtual struct QMetaObject cons ...