[原创] hadoop学习笔记:wordcout程序实践
看了官网上的示例:但是给的不是很清楚,这里依托官网给出的示例,加上自己的实践,解析worcount程序的操作
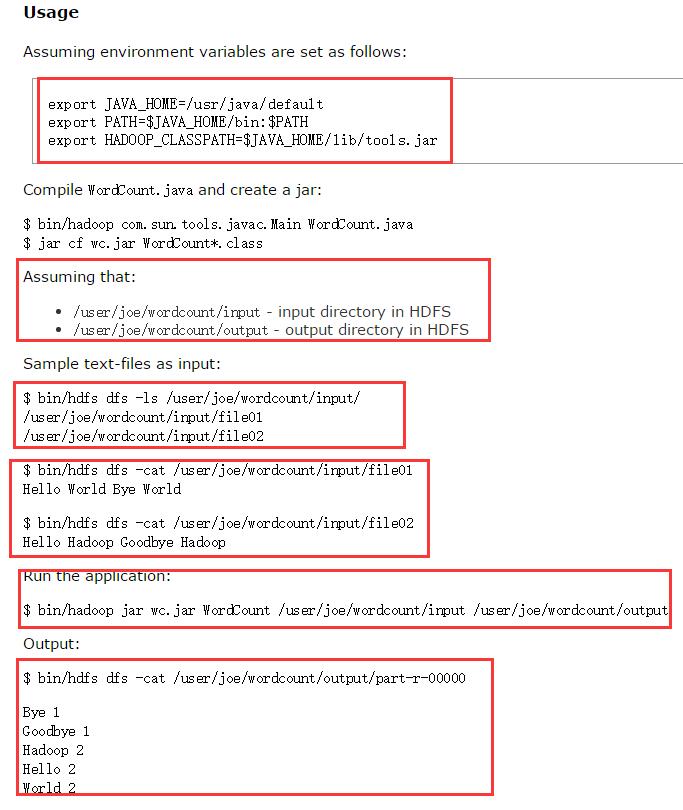
1.首先你的确定你的集群正确安装,并且启动你的集群,应为这个是hadoop2.6.0,所以你的启动以下的守护进程:
$sbin/ ./start-dfs.sh
$sbin/ ./start-yarn.sh
$sbin/ mr-jobhistory-daemon.sh start historyserver
2.在lccal系统上创建两个文件,记住是文件,命名:file01,file02
笔者在/opt/localdata 下创建的file01,file02,内容如下


3.将本地的file01,file02上传至hdfs文件系统,利用命令
首先在hdfs文件系统上创建目录:输入目录 /library/wordcount/input/ 输出目录 /library/wordcount/output/
创建输入目录:$bin/ hdfs dfs -mkdir -P /library/wordcount/input/
创建输出目录:$bin/ hdfs dfs -mkdir -P /library/wordcount/output/
将本地的文件copy到hdfs文件系统
$bin/ hdfs dfs -copyFromLocal /opt/localdata/file01 /library/wordcount/input/
$bin/ hdfs dfs -copyFromLocal /opt/localdata/file02 /library/wordcount/input/
完成之后可以查看文件是否copy过去
$bin/ hdfs dfs -ls /library/wordcount/input/

4.可以运行程序了
进入目录:cd $HADOOP_HOME/share/hadoop/mapreduce
运行命令$ hadoop jar hadoop-mapreduce-examples-2.6.0.jar wordcount /library/wordcount/input/ /library/wordcount/output/rs_wordcount
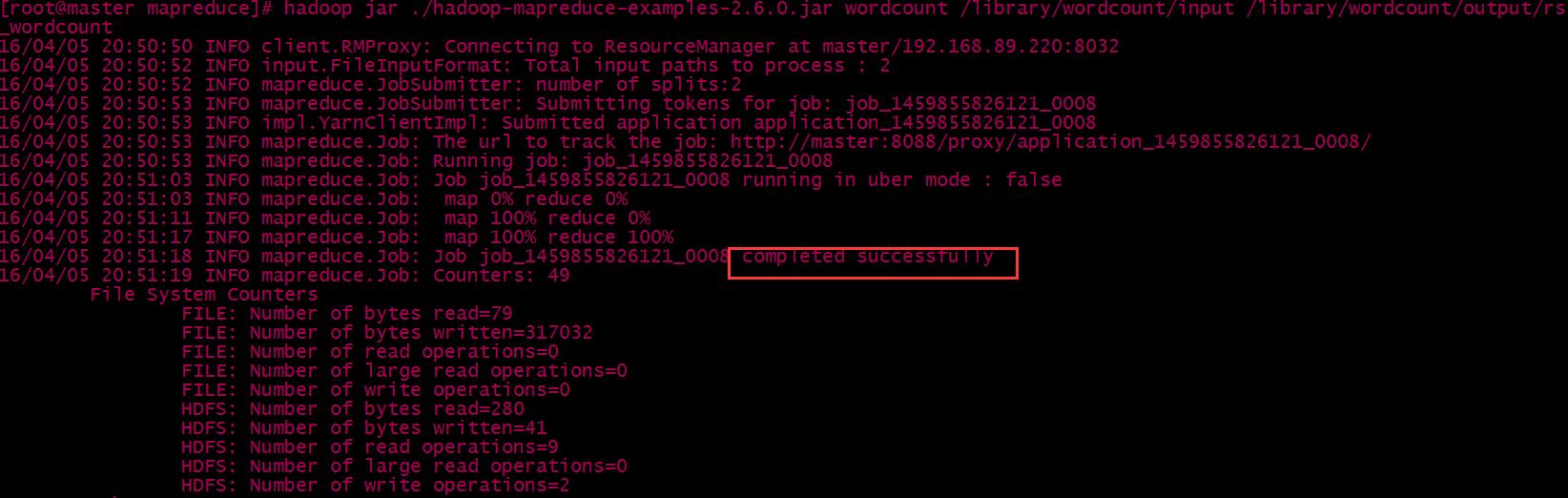
运行成功
5.查看运行结果
①web查看,首先需要设置web的,可以参考我的另外一篇博客http://www.cnblogs.com/jasonHome/p/5303040.html 自行设置
在浏览器输入:master:50070 (笔者将namenode的主机设置为master)
点击utilities ->brows the file system 如下图
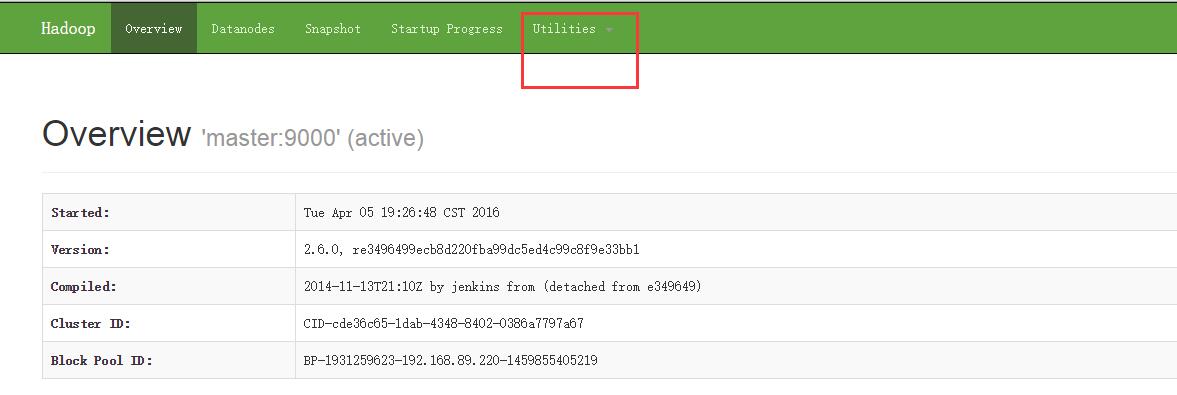
在hdfs文件系统中查看生成的文件结果文件:搜索 /library/wordcount/output/rs_wordcount
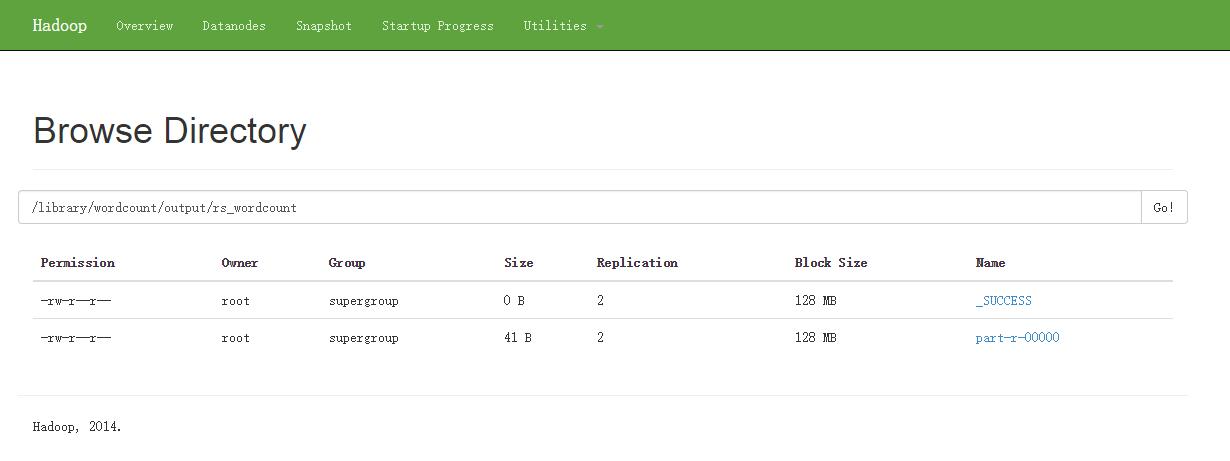
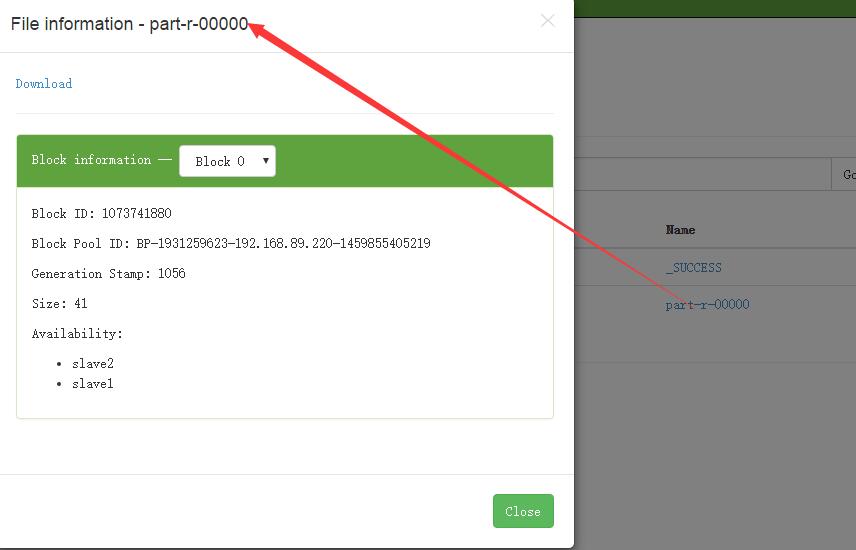
点击part-r-00000,就可以查看了
②可以通过命令行查看:
$ bin/hdfs dfs -cat /library/wordcount/output/part-r-00000
结果如下

补充:还可以通过 master:8088查看集群的情况, master:19888查看历史提交的任务和记录,如下图
master:8088

master:19888

好了,这就是我想和大家分享的,自己琢磨了 ,5个小时左右,如有问题,希望大家指正。
[原创] hadoop学习笔记:wordcout程序实践的更多相关文章
- [原创] hadoop学习笔记:卸载和安装jdk
一,卸载jdk 1.确定jdk版本 #rpm -qa | grep jak 可能的结果: java-1.7.0-openjdk-1.7.0.75-2.5.4.2.el7_0.x86_64 java- ...
- [原创] hadoop学习笔记:hadoopWEB监控
笔者安装单机版本 要想实现hadoopweb页面的监控,需要解决以下几个问题 1.关闭linux的防火墙:#service iptables stop 2.将linuxSE设置为disabled:#v ...
- [原创] hadoop学习笔记:重新格式化HDFS文件系统
所谓的重新格式化HDFS文件系统,实际意味着重新的创建一个HDFS文件系统.也就是说,必须将先前的已经有的文件系统配置删除.如下: 笔者采用的是最小化安装 这个是core-site.xml配置 这个是 ...
- Hadoop学习笔记(6) ——重新认识Hadoop
Hadoop学习笔记(6) ——重新认识Hadoop 之前,我们把hadoop从下载包部署到编写了helloworld,看到了结果.现是得开始稍微更深入地了解hadoop了. Hadoop包含了两大功 ...
- Hadoop学习笔记(5) ——编写HelloWorld(2)
Hadoop学习笔记(5) ——编写HelloWorld(2) 前面我们写了一个Hadoop程序,并让它跑起来了.但想想不对啊,Hadoop不是有两块功能么,DFS和MapReduce.没错,上一节我 ...
- Hadoop学习笔记(7) ——高级编程
Hadoop学习笔记(7) ——高级编程 从前面的学习中,我们了解到了MapReduce整个过程需要经过以下几个步骤: 1.输入(input):将输入数据分成一个个split,并将split进一步拆成 ...
- Hadoop学习笔记(2)
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(2) ——解读Hello World
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(1) ——菜鸟入门
Hadoop学习笔记(1) ——菜鸟入门 Hadoop是什么?先问一下百度吧: [百度百科]一个分布式系统基础架构,由Apache基金会所开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序. ...
随机推荐
- 编程算法 - 求1+2+...+n(构造函数) 代码(C++)
求1+2+...+n(构造函数) 代码(C++) 本文地址: http://blog.csdn.net/caroline_wendy 题目: 求1+2+...+n, 要求不能使用乘除法\for\whi ...
- Android实现一键获取课程成绩dome
欢迎转载但请标明出处:http://blog.csdn.net/android_for_james/article/details/50984493 两周废寝忘食的创作最终成功了,如今拿出来分享一下. ...
- Matlab中使用jython扩展功能
Matlab中面向对象能力并不强,通过使用jython引擎能够对其功能扩展. 1 编辑classpath.txt增加jython.jar 在matlab中输入 which classpath.txt ...
- 解读Unity中的CG编写Shader系列3——表面剔除与剪裁模式
在上一个样例中,我们得到了由mesh组件传递的信息经过数学转换至合适的颜色区间以颜色的形式着色到物体上. 这篇文章将要在此基础上研究片段的擦除(discarding fragments)和前面剪裁.后 ...
- ws 无法热替换的问题
这个坑自己踩过并且第二次就记录一下,因为一直习惯用ws, 使用热部署的时候发现无法自动同步热更新,找了很多方法,具体解决方式如下: webstorm默认保存在临时文件夹,根据下面路径将默认勾选项去除即 ...
- Ubuntu 16.04.5下FFmpeg编译与开发环境搭建
PC环境: Ubuntu 18.04 上面只要安装下面的提示安装即可,基本上不必再下载依赖库的源代码进行编译和安装 编译步骤: 1, 安装相关工具: sudo apt install -y auto ...
- lua学习笔记(六)
(2012-04-12 23:32:35) 转载▼ 函数 定义 function mytest(a,b,c) <函数体> end mytest = function( ...
- centos7 中文输入法设置
安装centos7 后,他有自带的中文输入法安装包找到 applications->systemTools->settings->region&language 2:在 in ...
- go的url解析
对于解析url,是一个常见的场景,下面就来说这个,直接见代码: package main import ( "fmt" "net/url" "stri ...
- UFLDL深度学习笔记 (七)拓扑稀疏编码与矩阵化
UFLDL深度学习笔记 (七)拓扑稀疏编码与矩阵化 主要思路 前面几篇所讲的都是围绕神经网络展开的,一个标志就是激活函数非线性:在前人的研究中,也存在线性激活函数的稀疏编码,该方法试图直接学习数据的特 ...