Oracle 11g streams部署
环境
| 源服务器 | 目标服务器 | |
| 系统版本 | CentOS Linux release 7.3.1611 (Core) | CentOS Linux release 7.3.1611 (Core) |
| 主机名 | sht-sgmhadoopdn-02 | sht-sgmhadoopdn-03 |
| 数据库版本 | EE 11.2.0.4.0 | EE 11.2.0.4.0 |
| dbname | FINMART | FINMART |
| global_name | FINMART1 | FINMART2 |
Streams流复制技术介绍
Streams通过logmnr(日志挖掘)技术从oracle的log中解析出数据,然后传递到目标库并应用,从而将源库的数据复制到目标库。在Stream 环境下,复制的起点数据库叫作Source Database, 复制的终点数据库叫作Target Database。 在这两个数据库上都要创建一个队列,其中的Source Database上的是发送队列,而Target Database上的是接收队列。
数据库的所有操作都会被记录在日志中。 配好Stream环境后, 在Source Database上会有一个捕获进程(Capture Process), 该进程利用Logminer技术从日志中提取DDL,DML语句,这些语句用一种特殊的格式表达,叫作逻辑变更记录(Logical Change Record, LCR). 一个LCR对应一个原子的行变更,因此源数据库上的一个DML语句,可能对应若干个LCR记录。 这些LCR会保存到Sourece Database的本地发送队列中。然后传播进程(Propagation Process)把这些记录通过网络发送到Target Database的接收队列。 在Target Database上会有一个应用进程(Apply Process), 这个进程从本地的接收队列中取出LCR记录,然后在本地应用,实现数据同步 。
整个的复制过程可以分成三个步骤:捕获(capture),传播(propagation)和应用(apply),利用高级队列(advance queue)来将这三个步骤的数据串起来,通过在步骤中定义不同的规则(rule)来控制需要复制的数据。复制可以基于全库,基于表空间,基于用户或者基于表,提供了相当大的灵活性。
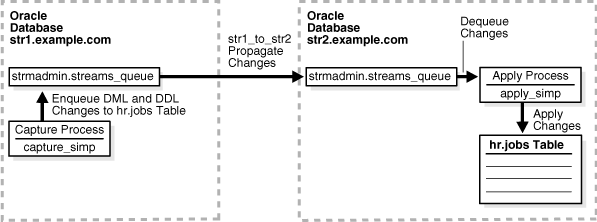
如下图所示,通过oracle streams技术在两个数据库之间复制一张数据表,在源服务器str1.example.com上capture进程在hr的schema中捕捉 jobs表的DDL和DML语句并记录到发送队列(QUEUE)中,propagation进程将这些变更传播到目标服务器 str2.example.com的接收队列中,apply进程负责将这些变更应用到目标数据库中。
本次计划实现目标:
假定目标数据库目前是正常运行状态,将源库中have用户的schema实时同步到目标库上,即用户级别的复制。
1.环境准备
1.1 源库和目标库均修改为归档模式
源库
SQL> archive log list;
Database log mode Archive Mode
Automatic archival Enabled
Archive destination /arch/oradata/FINMART
Oldest online log sequence 80
Next log sequence to archive 83
Current log sequence 83
目标库
SQL> archive log list;
Database log mode Archive Mode
Automatic archival Enabled
Archive destination /arch/oradata/FINMART
Oldest online log sequence 1
Next log sequence to archive 1
Current log sequence 1
1.2 修改源库和目标库的参数
源库
SQL> alter system set aq_tm_processes=2 scope=both;
SQL> alter system set global_names=true scope=both;
SQL> alter system set job_queue_processes=10 scope=both;
SQL> alter system set streams_pool_size=200M scope=both;
SQL> alter system set open_links=4 scope=spfile;
SQL> alter database rename GLOBAL_NAME to "FINMART1";
- job_queue_processes 决定了job作业能够使用的总进程数
- aq_tm_processes 该参数决定了数据库启动时Qnnn进程的数量,负责监视高级队列和负责队列传播(propagation)
- streams_pool_size 手动指定srteams池的大小
- open_links 每个session最多允许的dblink数量
- global_names streams必须要设置该参数为true,当GLOBAL_NAMES参数设置为TRUE时,创建DBLINK的名称必须与被连接库的GLOBAL_NAME一致。
注意:如果源库和目标库的dbname相同,说明源库和目标库的global_name也相同,这时需要将源库和目标库的global_name修改为不一致,否则创建db link会报错
目标库
SQL> alter system set aq_tm_processes=2 scope=both;
SQL> alter system set global_names=true scope=both;
SQL> alter system set job_queue_processes=10 scope=both;
SQL> alter system set streams_pool_size=200M scope=both;
SQL> alter system set open_links=4 scope=spfile;
SQL> alter database rename GLOBAL_NAME to "FINMART2";
1.3 在源库和目标库创建srteams管理用户和测试用户
SQL> create tablespace streams_tbs datafile '/db01/oradata/FINMART/streams_tbs01.dbf' size 100m reuse autoextend on maxsize unlimited;
SQL> create user strmadmin identified by strmadmin default tablespace streams_tbs quota unlimited on streams_tbs;
SQL> grant dba to strmadmin;
SQL> exec DBMS_STREAMS_AUTH.GRANT_ADMIN_PRIVILEGE('strmadmin');
SQL> create tablespace dave_tbs datafile '/db01/oradata/FINMART/dave_tbs01.dbf' size 100M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED;
SQL> create user dave identified by dave default tablespace dave_tbs quota unlimited on dave_tbs;
SQL> create table dave.tb1(id int primary key,name varchar2(40),value varchar2(40));
SQL> insert into dave.tb1(id,name,value) values('','birthday','');
SQL> commit;
1.4 在源库和目标库创建tnsnames
FINMART1 =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = sht-sgmhadoopdn-02)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = FINMART)
)
) FINMART2 =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = sht-sgmhadoopdn-03)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = FINMART)
)
)
1.5 在源库和目标库创建db link
源库
SQL> connect strmadmin/strmadmin@finmart1
SQL> create database link finmart2 connect to strmadmin identified by strmadmin using 'finmart2';
SQL> select * from global_name@finmart2; GLOBAL_NAME
--------------------------------------------------------------------------------
FINMART2
目标库
SQL> connect strmadmin/strmadmin@finmart2
SQL> create database link finmart1 connect to strmadmin identified by strmadmin using 'finmart1';
SQL> select * from global_name@finmart1; GLOBAL_NAME
--------------------------------------------------------------------------------
FINMART1
注意:database link名称必须是目标库的global_name名称
1.6 在数据库上启动追加日志
附加日志(supplemental log)可以指示数据库在日志中添加额外信息到日志流中,以支持基于日志的工具,如逻辑standby、streams、GoldenGate、LogMiner。可以在数据库和表上设置。
SQL> alter database add supplemental log data;
2. 在源库上创建发送队列
SQL> BEGIN
2 DBMS_STREAMS_ADM.SET_UP_QUEUE(
3 queue_table => 'SOURCE_QUEUE_TABLE',
4 queue_name => 'SOURCE_QUEUE',
5 queue_user => 'strmadmin');
6 END;
7 / PL/SQL procedure successfully completed.
- queue_name 队列名称
- queue_table 队列表名
- queue_user 队列所有者
通过数据字典dba_queues、dba_queue_tables查看
column NAME format a40
column QUEUE_TABLE format a20
column OWNER format a20
select NAME,QUEUE_TABLE,OWNER,QUEUE_TYPE from dba_queues where OWNER='STRMADMIN'; NAME QUEUE_TABLE OWNER QUEUE_TYPE
---------------------------------------- -------------------- -------------------- ------------------------------------------------------------
AQ$_SOURCE_QUEUE_TABLE_E SOURCE_QUEUE_TABLE STRMADMIN EXCEPTION_QUEUE
SOURCE_QUEUE SOURCE_QUEUE_TABLE STRMADMIN NORMAL_QUEUE
column OBJECT_TYPE format a20
select OWNER,QUEUE_TABLE,OBJECT_TYPE from dba_queue_tables where owner='STRMADMIN'; OWNER QUEUE_TABLE OBJECT_TYPE
-------------------- -------------------- --------------------
STRMADMIN SOURCE_QUEUE_TABLE SYS.ANYDATA
如果删除发送队列,命令如下
exec dbms_streams_adm.remove_queue(queue_name => 'source_queue',cascade => true,drop_unused_queue_table => true);
select NAME,QUEUE_TABLE,OWNER,QUEUE_TYPE from dba_queues where OWNER='STRMADMIN'; no rows selected
select OWNER,QUEUE_TABLE,OBJECT_TYPE from dba_queue_tables where owner='STRMADMIN'; no rows selected
3. 在目标库上创建接收队列
SQL> BEGIN
2 DBMS_STREAMS_ADM.SET_UP_QUEUE(
3 queue_table => 'TARGET_QUEUE_TABLE',
4 queue_name => 'TARGET_QUEUE',
5 queue_user => 'strmadmin');
6 END;
7 / PL/SQL procedure successfully completed.
select NAME,QUEUE_TABLE,OWNER,QUEUE_TYPE from dba_queues where OWNER='STRMADMIN'; NAME QUEUE_TABLE OWNER QUEUE_TYPE
---------------------------------------- -------------------- -------------------- ------------------------------------------------------------
TARGET_QUEUE TARGET_QUEUE_TABLE STRMADMIN NORMAL_QUEUE
AQ$_TARGET_QUEUE_TABLE_E TARGET_QUEUE_TABLE STRMADMIN EXCEPTION_QUEUE select OWNER,QUEUE_TABLE,OBJECT_TYPE from dba_queue_tables where owner='STRMADMIN'; OWNER QUEUE_TABLE OBJECT_TYPE
-------------------- -------------------- --------------------
STRMADMIN TARGET_QUEUE_TABLE SYS.ANYDATA
4. 在源库上创建capture 进程
SQL> BEGIN
2 DBMS_STREAMS_ADM.ADD_SCHEMA_RULES(
3 schema_name => 'dave',
4 streams_type => 'capture',
5 streams_name => 'capture_stream',
6 queue_name => 'strmadmin.SOURCE_QUEUE',
7 include_dml => true,
8 include_ddl => true,
9 source_database => 'FINMART1',
10 include_tagged_lcr => false,
11 inclusion_rule => true);
12 END;
13 / PL/SQL procedure successfully completed.
column CAPTURE_NAME format a20
column QUEUE_NAME format a20
column QUEUE_OWNER format a20column CAPTURE_USER format a20
column SOURCE_DATABASE format a20
column CAPTURE_TYPE format a20
column START_TIME format a40
select CAPTURE_NAME,QUEUE_NAME,QUEUE_OWNER,CAPTURE_USER,START_SCN,STATUS,SOURCE_DATABASE,CAPTURE_TYPE,START_TIME from dba_capture; CAPTURE_NAME QUEUE_NAME QUEUE_OWNER CAPTURE_USER START_SCN STATUS SOURCE_DATABASE CAPTURE_TYPE START_TIME
-------------------- -------------------- -------------------- -------------------- ---------- ------------------------ -------------------- ------------------------------ ---------------------------------------------------------------------------
CAPTURE_STREAM SOURCE_QUEUE STRMADMIN STRMADMIN 7082908 DISABLED FINMART1 LOCAL 16-SEP-18 06.10.18.000000 PM
column SCHEMA_NAME format a20
select * from dba_capture_prepared_schemas; SCHEMA_NAME TIMESTAMP SUPPLEMENTAL_LOG_DATA_PK SUPPLEMENTAL_LOG_DATA_UI SUPPLEMENTAL_LOG_DATA_FK SUPPLEMENTAL_LOG_DATA_AL
------------------------ --------------- ------------------------ ------------------------ ------------------------ ------------------------
DAVE 16-SEP-18 IMPLICIT IMPLICIT IMPLICIT NO
5.在源库上创建传播进程(Propagation Process)
SQL> BEGIN
2 DBMS_STREAMS_ADM.ADD_SCHEMA_PROPAGATION_RULES(
3 schema_name => 'dave',
4 streams_name => 'source_to_target',
5 source_queue_name => 'strmadmin.SOURCE_QUEUE',
6 destination_queue_name => 'strmadmin.TARGET_QUEUE@FINMART2',
7 include_dml => true,
8 include_ddl => true,
9 source_database => 'FINMART1',
10 inclusion_rule => true,
11 queue_to_queue => true);
12 END;
13 / PL/SQL procedure successfully completed.
column PROPAGATION_NAME format a30
column SOURCE_QUEUE_OWNER format a20
column SOURCE_QUEUE_NAME format a30
column DESTINATION_QUEUE_OWNER format a30
column DESTINATION_QUEUE_NAME format a30
column DESTINATION_DBLINK format a20
column RULE_SET_OWNER format a20
select PROPAGATION_NAME,SOURCE_QUEUE_OWNER,SOURCE_QUEUE_NAME,DESTINATION_QUEUE_OWNER,DESTINATION_QUEUE_NAME,DESTINATION_DBLINK,RULE_SET_OWNER,QUEUE_TO_QUEUE,STATUS from dba_propagation; PROPAGATION_NAME SOURCE_QUEUE_OWNER SOURCE_QUEUE_NAME DESTINATION_QUEUE_OWNER DESTINATION_QUEUE_NAME DESTINATION_DBLINK RULE_SET_OWNER QUEUE_TO_QUEUE STATUS
------------------------------ ------------------------------ ------------------------------ ------------------------------ ------------------------------ -------------------- -------------------- --------------- ------------------------
SOURCE_TO_TARGET STRMADMIN SOURCE_QUEUE STRMADMIN TARGET_QUEUE FINMART2 STRMADMIN TRUE ENABLED
6.修改propagation休眠时间为0,表示实时传播LCR
SQL> BEGIN
2 dbms_aqadm.alter_propagation_schedule(
3 queue_name => 'SOURCE_QUEUE',
4 destination => 'FINMART2',
5 destination_queue => 'TARGET_QUEUE',
6 latency => 0);
7 END;
8 / PL/SQL procedure successfully completed.
7.在目标库创建Apply进程
SQL> BEGIN
2 DBMS_STREAMS_ADM.ADD_SCHEMA_RULES(
3 schema_name => 'dave',
4 streams_type => 'apply',
5 streams_name => 'target_apply_stream',
6 queue_name => 'strmadmin.TARGET_QUEUE',
7 include_dml => true,
8 include_ddl => true,
9 include_tagged_lcr => false,
10 source_database => 'FINMART1',
11 inclusion_rule => true);
12 END;
13 / PL/SQL procedure successfully completed.
column APPLY_NAME format a20
column QUEUE_NAME format a20
column QUEUE_OWNER format a20
column RULE_SET_OWNER format a20
column APPLY_USER format a20
column APPLY_DATABASE_LINK format a20
select APPLY_NAME,QUEUE_NAME,QUEUE_OWNER,APPLY_CAPTURED,RULE_SET_OWNER,APPLY_USER,APPLY_DATABASE_LINK,STATUS from dba_apply; APPLY_NAME QUEUE_NAME QUEUE_OWNER APPLY_CAP RULE_SET_OWNER APPLY_USER APPLY_DATABASE_LINK STATUS
-------------------- -------------------- -------------------- --------- -------------------- -------------------- -------------------- ------------------------
TARGET_APPLY_STREAM TARGET_QUEUE STRMADMIN YES STRMADMIN STRMADMIN DISABLED
8.实例化数目标数据库
源库
exp USERID=dave/dave@finmart1 file=dave.dmp object_consistent=y rows=y
目标库
imp strmadmin/strmadmin@finmart2 file='dave.dmp' ignore=y commit=y log='dave.log' streams_instantiation=y fromuser=dave touser=dave
9. 在目标库上启动apply进程
SQL> BEGIN
2 DBMS_APPLY_ADM.START_APPLY(
3 apply_name => 'target_apply_stream');
4 END;
5 / PL/SQL procedure successfully completed.
select APPLY_NAME,QUEUE_NAME,QUEUE_OWNER,APPLY_CAPTURED,RULE_SET_OWNER,APPLY_USER,APPLY_DATABASE_LINK,STATUS from dba_apply; APPLY_NAME QUEUE_NAME QUEUE_OWNER APPLY_CAP RULE_SET_OWNER APPLY_USER APPLY_DATABASE_LINK STATUS
-------------------- -------------------- -------------------- --------- -------------------- -------------------- -------------------- ------------------------
TARGET_APPLY_STREAM TARGET_QUEUE STRMADMIN YES STRMADMIN STRMADMIN ENABLED
10.在源库上启动capture进程
SQL> BEGIN
2 DBMS_CAPTURE_ADM.START_CAPTURE(
3 capture_name => 'capture_stream');
4 END;
5 / PL/SQL procedure successfully completed.
select CAPTURE_NAME,QUEUE_NAME,QUEUE_OWNER,CAPTURE_USER,START_SCN,STATUS,SOURCE_DATABASE,CAPTURE_TYPE,START_TIME from dba_capture; CAPTURE_NAME QUEUE_NAME QUEUE_OWNER CAPTURE_USER START_SCN STATUS SOURCE_DATABASE CAPTURE_TYPE START_TIME
-------------------- -------------------- -------------------- -------------------- ---------- ------------------------ -------------------- ------------------------------ ---------------------------------------------------------------------------
CAPTURE_STREAM SOURCE_QUEUE STRMADMIN STRMADMIN 7082908 ENABLED FINMART1 LOCAL 16-SEP-18 06.10.18.000000 PM
11.验证DML和DDL
select * from dave.tb1@finmart2;
ID NAME VALUE
---------- ---------------------------------------- ------------------------------------------------------------------------------------------------------------------------
1 birthday 19insert into dave.tb1(id,name,value) values('','sex','female');
1 row created.
commit;
Commit complete.
select * from dave.tb1@finmart2;
ID NAME VALUE
---------- ---------------------------------------- ------------------------------------------------------------------------------------------------------------------------
1 birthday 19
2 sex female
SQL> create table dave.tb2 as select * from dba_objects; Table created. SQL> select count(*) from dave.tb2; COUNT(*)
----------
86453 SQL> select count(*) from dave.tb2@finmart2;
select count(*) from dave.tb2@finmart2
*
ERROR at line 1:
ORA-00942: table or view does not exist
ORA-02063: preceding line from FINMART2 SQL> select count(*) from dave.tb2@finmart2; COUNT(*)
----------
0 SQL> select count(*) from dave.tb2@finmart2; COUNT(*)
----------
86453
Oracle 11g streams部署的更多相关文章
- Centos 下oracle 11g 安装部署及手动建库过程
Oracle 11g 手动建库,在虚拟环境中,不使用DBCA工具进行创建数据库 1.Linux环境的基本配置 2.ip 10.11.30.60 3.Oracle 11g安装过程 ---------- ...
- Linux平台oracle 11g单实例 + ASM存储 安装部署 快速参考
操作环境:Citrix虚拟化环境中申请一个Linux6.4主机(模板)目标:创建单机11g + ASM存储 数据库 1. 主机准备 2. 创建ORACLE 用户和组成员 3. 创建以下目录并赋予对应权 ...
- [转帖]Oracle 11G RAC For Windows 2008 R2部署手册
Oracle 11G RAC For Windows 2008 R2部署手册(亲测,成功实施多次) https://www.cnblogs.com/yhfssp/p/7821593.html 总体规划 ...
- Oracle Grid control 11g及Active DataGuard 11g安装部署
Oracle Grid control 11g及Active DataGuard 11g安装部署(一) 原贴 http://blog.csdn.net/lichangzai/article/detai ...
- Linux平台oracle 11g单实例 安装部署配置 快速参考
1.重建主机的Oracle用户 组 统一规范 uid gid 以保证共享存储挂接或其他需求的权限规范 userdel -r oracle groupadd -g 7 oinstall groupadd ...
- RedHat 6.7 Enterprise x64环境下使用RHCS部署Oracle 11g R2双机双实例HA
环境 软硬件环境 硬件环境: 浪潮英信服务器NF570M3两台,华为OceanStor 18500存储一台,以太网交换机两台,光纤交换机两台. 软件环境: 操作系统:Redhat Enterpris ...
- RedHat 6.7 Enterprise x64环境下使用RHCS部署Oracle 11g R2双机HA
环境 软硬件环境 硬件环境: 浪潮英信服务器NF570M3两台,华为OceanStor 18500存储一台,以太网交换机两台,光纤交换机两台. 软件环境: 操作系统:Redhat Enterprise ...
- 数据库系统入门 | Oracle Linux上部署Oracle 11g服务,并实现SSH远程登录管理
文章目录 写在前面 一.实验内容 二.实验前期准备 1.软件目录 2.准备一些配置文件.脚本文件 三.实验方案(具体步骤) (一)在虚拟机上安装Oracle Linux (二)在Linux上安装Ora ...
- 【Oracle 集群】Oracle 11G RAC教程之集群安装(七)
Oracle 11G RAC集群安装(七) 概述:写下本文档的初衷和动力,来源于上篇的<oracle基本操作手册>.oracle基本操作手册是作者研一假期对oracle基础知识学习的汇总. ...
随机推荐
- Open_stack 有虚拟机端口不通的问题
原因:流量表 解决办法:not修改流量表(容易出错,出错后果更严重):is迁移虚拟机这样会对应生成新的流量表,然后问题就解决了.
- JedisCluster简单使用
项目中因为一些原因需要用到缓存,之前没有接触过,在此做一些简单的使用记录. 1.jedis在项目中依赖 <dependency> <groupId>redis.clients& ...
- aws cloudwatch监控怎么通过钉钉机器人报警
最近在完善海外业务在aws服务的CloudWatchh监控,发现CloudWatch报警通知要通过aws的sns服务,直接支持的通道有短信和邮件,但是我们想推到钉钉群里面的群机器人里面这个就要借助aw ...
- 家庭记账本之微信小程序(六)
Wxss的学习 WXSS(WeiXin Style Sheets)是一套样式语言,用于描述WXML的组件样式. WXSS用来决定WXML的组件应该怎么显示. 为了适应广大的前端开发者,我们的WXSS具 ...
- Django的安装
##pip pip是Python的包管理工具,用于快速安装配置所需要的拓展包,能够很好的解决包之间的依赖关系 当前ubuntu 系统上有两个Python环境,使用pip3 是指定Python3的环境 ...
- 再解炸弹人,dfs&bfs
输入样例: 13 13 3 3##############GG.GGG#GGG.####.#G#G#G#G##.......#..G##G#.###.#G#G##GG.GGG.#.GG##G#.#G# ...
- java项目打包成可运行的jar,main方法带参数
转载 原文地址:http://www.cnblogs.com/neillee/p/6063808.html#commentform 将 java 项目打包成可运行的 jar 包(main 函数带参数) ...
- docker mysql 数据库乱码
创建 mysql 时,需要加上编码,不然会乱码: docker run --name mysql01 -p : -e MYSQL_ROOT_PASSWORD=pwd123 -d mysql:5.5 - ...
- 记录Ok6410 sd 启动uboot
1\参考资料https://github.com/SeanXP/ARM-Tiny6410/tree/master/no-os/sd-no-os/u-boot 2\参考资料https://blog.cs ...
- phpstudy 安装 Apcahe SSL证书 实现https连接
摘自:https://jingyan.baidu.com/article/64d05a022e6b57de54f73b51.html Windows phpstudy安装ssl证书教程. 工具/原料 ...