论文笔记:Concept Mask: Large-Scale Segmentation from Semantic Concepts
Concept Mask: Large-Scale Segmentation from Semantic Concepts
2018-08-21 11:16:07
Paper:https://arxiv.org/pdf/1808.06032.pdf
本文做了这么一件事:给定一张图片以及概念名词,输出其对应的分割结果,如下图所示:
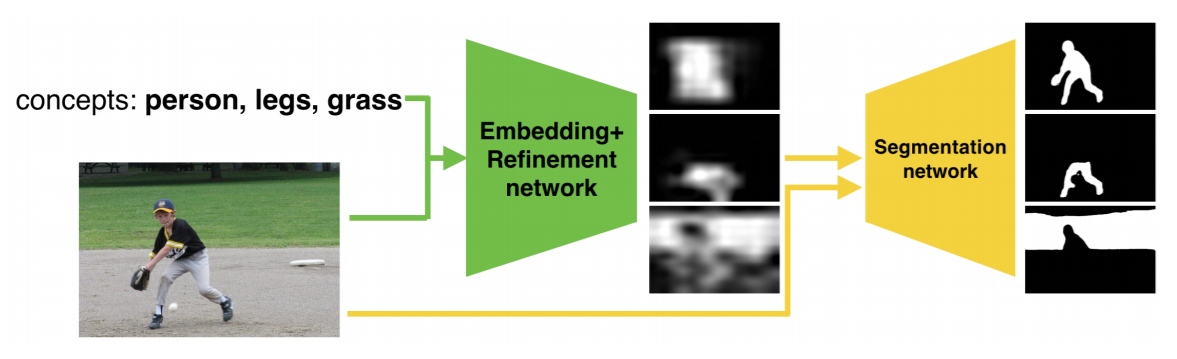
具体来说,这个流程大致可以分为如下几个部分:
1. Embedding Network 来学习视觉特征和语义概念之间的对应关系;此时,我们可以得到一个粗糙的 attention map;
2. 优化模块,在上一步骤的基础上,利用 BBox 的标注信息,得到高质量的 attention maps;
3. A label agnostic segmentation network,在 COCO-80 分割数据集上进行有监督的训练。这个网络将上述得到的 coarse attention maps,以及原图作为输入,得到最终概念级别的分割结果;
总体的流程图如下:
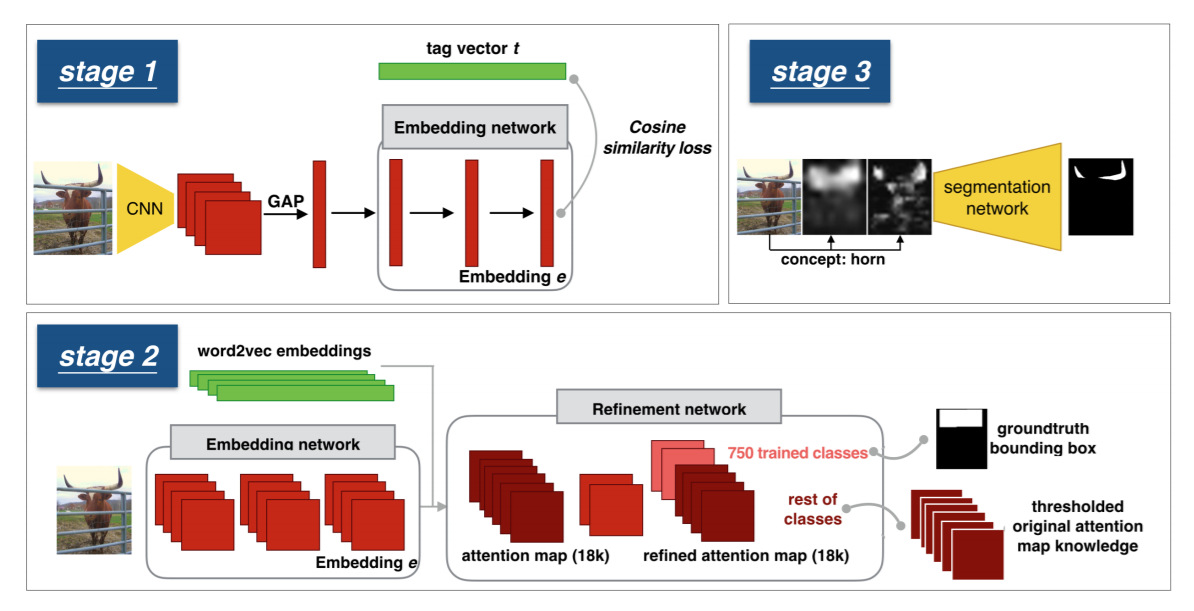
下面分别详细的介绍下对应的每一个模块:
1. Embedding Network:
作者在 Stock-18K dataset 上进行了训练,该数据集包含 6 million images,每一个图像都对应有标注的 tags,有 18K vocabulary。
Word Embedding
有了 tag 的信息,第一步就是将其映射为 vector,与通常直接用 pre-trained Word embedding 的方法不同,本文采用的是:point-wise mutual information (PMI) 来学习我们自己的 Word embedding。当一张图像有多个对应的 label 时,作者采用了常规的 加权平均的方法,得到一个统一的表达,称为:“soft topic embedding”。
Joint Word-Image Embedding
作者用余弦相似性 loss 函数来衡量,visual embedding 与 soft topic word vector 之间的距离:
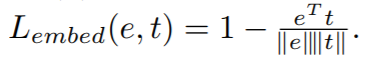
Attention Map
作者用一个全卷机的网络结构,将输入的图像,转换为对应的 attention map;然后计算每一个位置上,图像和单词描述之间的相似度:
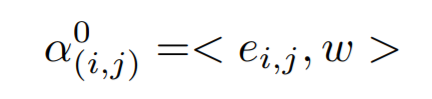
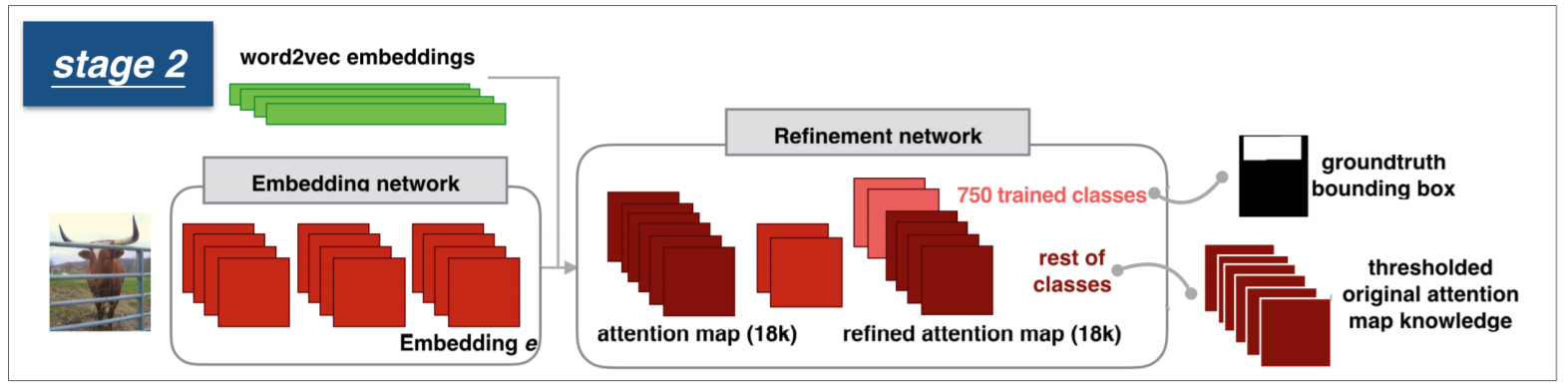
2. Attention Map Refinement
虽然上述过程得到了初始的 attention maps,但是由于缺乏 空间信息的标注,使得该 attention map 非常的粗糙;
Multi-task Training
作者采用了 二元交叉熵损失函数来度量所输出的 maps 和 GT maps 之间的差距:

Spatial Discrimination Loss
作者给出了不采用 softmax loss,而用 binary cross entropy loss 的原因:there are many concepts whose masks are overlapping with each other. 但是,仍然有一些概念,几乎从来不会重合。为了充分利用这种关系,作者提出了一种辅助的 loss 函数,来判断这些空间上不重合的概念,即:spatial discriminatives loss。
特别的,我们统计训练数据中,相互重叠的概念对:
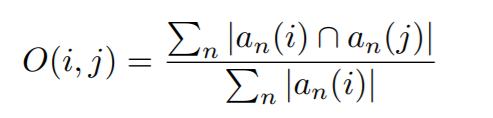
有了这个重叠比例矩阵 O(i, j),那么,我们可以用一个概念 i 的训练样本当做 非重合概念 j 的 negative training example,即:
for a particular location in the image, the output for concept j should be 0 if the ground-truth for concept i is 1.
为了软化这个约束,作者进一步根据重合度,进行了辅助 loss 的加权,权重的计算方法如下:
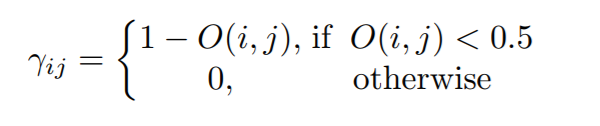
3. Label Agnostic Segmentation Network
为了得到更加精细化的分割结果,像素级的标注信息是必不可少的。所以,这里,作者将上述过程中得到的 coarse maps 以及 原始图像都作为分割网络的输入,然后得到最终精细化的分割结果。
Experiments:


论文笔记:Concept Mask: Large-Scale Segmentation from Semantic Concepts的更多相关文章
- 论文笔记之:Large Scale Distributed Semi-Supervised Learning Using Streaming Approximation
Large Scale Distributed Semi-Supervised Learning Using Streaming Approximation Google 2016.10.06 官方 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 17—Large Scale Machine Learning 大规模机器学习
Lecture17 Large Scale Machine Learning大规模机器学习 17.1 大型数据集的学习 Learning With Large Datasets 如果有一个低方差的模型 ...
- 论文笔记:Mask R-CNN
之前在一次组会上,师弟诉苦说他用 UNet 处理一个病灶分割的任务,但效果极差,我看了他的数据后发现,那些病灶区域比起整张图而言非常的小,而 UNet 采用的损失函数通常是逐像素的分类损失,如此一来, ...
- 论文笔记:Dynamic Multimodal Instance Segmentation Guided by Natural Language Queries
Dynamic Multimodal Instance Segmentation Guided by Natural Language Queries 2018-09-18 09:58:50 Pape ...
- 论文笔记:Capsules for Object Segmentation
Capsules for Object Segmentation 2018-04-16 21:49:14 Introduction: ----
- [论文笔记][半监督语义分割]Universal Semi-Supervised Semantic Segmentation
论文原文原文地址 Motivations 传统的训练方式需要针对不同 domain 的数据分别设计模型,十分繁琐(deploy costs) 语义分割数据集标注十分昂贵,费时费力 Contributi ...
- 论文笔记系列-Auto-DeepLab:Hierarchical Neural Architecture Search for Semantic Image Segmentation
Pytorch实现代码:https://github.com/MenghaoGuo/AutoDeeplab 创新点 cell-level and network-level search 以往的NAS ...
- 大规模视觉识别挑战赛ILSVRC2015各团队结果和方法 Large Scale Visual Recognition Challenge 2015
Large Scale Visual Recognition Challenge 2015 (ILSVRC2015) Legend: Yellow background = winner in thi ...
- 论文笔记之:Natural Language Object Retrieval
论文笔记之:Natural Language Object Retrieval 2017-07-10 16:50:43 本文旨在通过给定的文本描述,在图像中去实现物体的定位和识别.大致流程图如下 ...
随机推荐
- mybatis09--自连接一对多查询
查询导师 下面的所有 老师的信息! 创建实体类 和对应的数据库 /** *导师的实体类 */ public class Teacher { private Integer id; private St ...
- java爬取网站信息和url实例
https://blog.csdn.net/weixin_38409425/article/details/78616688(出自此為博主) 具體代碼如下: import java.io.Buffer ...
- vue里的样式添加之类名改动 和style改动
类名下有不同样式,通过增加或者减少类名,来增加或减少样式. v-bind:class = {类名:变量,类名:变量...} 变量为布尔值,如果是true则类名添加,反正类名不添加到该元素身上 v-b ...
- PAT甲级1026 Table Tennis【模拟好题】
题目:https://pintia.cn/problem-sets/994805342720868352/problems/994805472333250560 题意: 有k张乒乓球桌,有的是vip桌 ...
- Golang中mac地址+时间戳加入rand.Seed()产生随机数
记录一下用mac地址+local时间作为seed来产生随机数 // 首先记录一下rand.Seed()怎么用 // 官方说明,传入int64数据为Seed func (r *Rand) Seed(se ...
- Vue事件总线(eventBus)$on()会多次触发解决办法
项目中使用了事件总线eventBus来进行两个组件间的通信, 使用方法是是建立eventBus.js文件,暴露一个空的Vue实例,如下: import Vue from 'vue'export def ...
- 手机连接wamp网页
1.改变wamp的put online 状态 Right click Wampmanager -> WAMPSetting -> Menu Item: Online/Offline
- jquery网页倒计时效果,秒杀
function FreshTime(){ var endtime=new Date('2019-4-12 18:00:00');//结束时间 var nowtime = new Date();//当 ...
- 深度学习基础(一)LeNet_Gradient-Based Learning Applied to Document Recognition
作者:Yann LeCun,Leon Botton, Yoshua Bengio,and Patrick Haffner 这篇论文内容较多,这里只对部分内容进行记录: 以下是对论文原文的翻译: 在传统 ...
- 点击图片img提交form表单
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/stri ...