Solr全文检索框架
概述:
什么是Solr?
Solr是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务.Solr可以独立运行在Jetty.tomcat.webLogic.webShell等这些Servlet容器中.
全文检索服务(也叫做全文搜索): 服务 是War包.
ES框架 也是基于Lucene,Lucene(是工具包 jar)
服务器: Tomcat Jetty(内嵌服务器) 免费的(私企)
WebLogic(Oracle)政府 Oracle
WebShell(IBM) 收费的 DB2
内嵌服务器和外部的服务器
Tomcat(外部) /webapps/war
War/lib/jetty.jar(内嵌) 稳定性差了点. 测试环境下使用.
1.开发环境 (软件开发工程师) jetty
2.测试环境 (测试工程师) 黑盒 白盒 (既能够测试功能,又能测试代码质量) jetty
3.生产环境 (线上运营) 京东,淘宝 等可以开始卖货了. tomcat
使用Solr进行创建索引和搜索索引的实现方法很简单,如下:
客户端: PHP C++ .NET JAVA
服务端:(War) 在tomcat上运行, 安装jdk, HTTP协议
要使用Solr的两步:
1. 安装服务端(服务端+索引库)
2.java写客户端(java代码可以写客户端,浏览器也可以充当客户端)
Solr的java客户端:
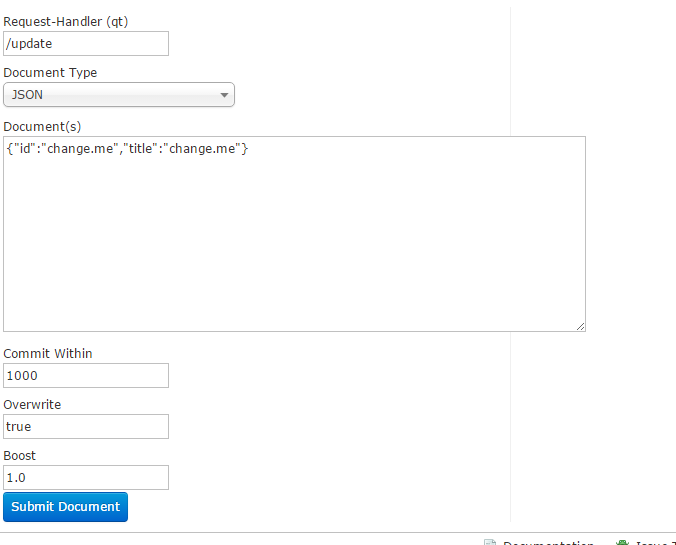
1.创建索引(包含了删,加,改): java客户端以POST方式,发送xml格式字符串给服务端, 服务端返回xml格式字符串.
2.搜索索引: java客户端Get方式 发送json或者xml 返回值json或者xml
后台管理中心(浏览器打开界面) 管理索引
删除
添加
修改
查询
(上面的统称为管理)
创建索引:客户端(可以是浏览器可以是java程序)用POST方法向Solr服务器发送一个描述Field及其内容的XML文档,Solr服务器根据xml文档添加,删除,更新索引.
搜索索引:客户端(可以是浏览器可以是JAVA程序)用GET方法向Solr服务器发送请求,然后对Solr服务器返回XML.json等格式的查询结果进行解析.Solr不提供构建页面UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况.
Solr是一个可以独立运行的搜索服务器,使用solr进行全文检索服务的话,只需要通过http请求访问该服务器即可.
Solr和Lucene的区别?
Lucene是一个开放源代码的全文检索引擎工具包,它是一个完整的全文检索应用.Lucene仅提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene为基础构建全文检索应用.
Solr的目标是打造一款企业级的搜索引擎系统,它是基于Lucene一个搜索引擎服务.可以独立运行,通过Solr可以非常快速的构建企业的搜索引擎,通过Solr也可以高效的完成站内搜索功能.
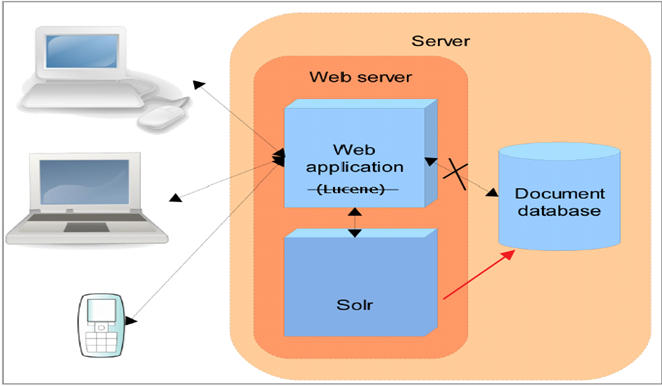
原来的方式,是直接通过web服务器,然后通过Lucene直接使用索引库,但是如果不使用Lucnene的时候,就直接使用Solr来连接索引库.
相对来说Lucene的速度更快,
简单的说 :
1.Lucene 是工具包 是jar包
2.Solr是索引引擎服务 War
3.Solr是基于Lucene(底层是由Lucene写的)
4.上面二个软件都是Apache公司由java写的
在Solr的后端界面

在Solr的集群的时候,会有Master(主人) Slave(奴隶)
Solr基于Lucene
ID域 必须有 不可重复 字符串类型(中文 正数)
名称域
描述域
价格域
路径域
有事务 提交事务
1.主动提交
2.自动提交,提前设置提交时间 毫秒
Overwrite
当ID相同时,可以进行覆盖
Boost 相关度
什么是相关度?
相关度 = 词出现的次数*Boost
相关度越高,在查询的时候,越靠前.
Solr全文检索框架的更多相关文章
- Haystack全文检索框架
一.什么是Haystack Haystack是django的开源全文搜索框架(全文检索不同于特定字段的模糊查询,使用全文检索的效率更高 ),该框架支持Solr,Elasticsearch,Whoosh ...
- 全文检索框架---Lucene
一.什么是全文检索 1.数据分类 我们生活中的数据总体分为两种:结构化数据和非结构化数据. 结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等. 非结构化数据:指不定长或无固定格式 ...
- SOLR (全文检索)
SOLR (全文检索) http://sinykk.iteye.com/ 1. 什么是SOLR 官方网站 http://wiki.apache.org/solr http://wiki.apach ...
- Haystack--基于Django的全文检索框架
好文章转载自:https://suguangti.cnblogs.com/p/11167097.html 阅读目录 1.什么是Haystack 2.安装 3.配置 4.处理数据 创建索引 5.设置视图 ...
- Haystack Python全文检索框架
Haystack 1.什么是Haystack Haystack是django的开源全文搜索框架(全文检索不同于特定字段的模糊查询,使用全文检索的效率更高 ),该框架支持Solr,Elasticsear ...
- solr全文检索原理及solr5.5.0 Windows部署
文章原理链接:http://blog.csdn.net/xiaoyu411502/article/details/44803859 自己稍微总结:全文检索主要有两个过程:创建索引,搜索索引 创建索引: ...
- Lucene全文检索框架
1.什么时Lucene? 是一个全文搜索框架,而不是应用产品,他只是一种工具让你能实现某些产品,并不像www.baidu.com拿来就能用 是apache组织的一个用java实现的全文搜索引擎的开源项 ...
- solr全文检索基本原理
场景:小时候我们都使用过新华字典,妈妈叫你翻开第38页,找到“坑爹”所在的位置,此时你会怎么查呢?毫无疑问,你的眼睛会从38页的第一个字开始从头至尾地扫描,直到找到“坑爹”二字为止.这种搜索方法叫做顺 ...
- solr全文检索实现原理
本文转自:https://blog.csdn.net/u014209975/article/details/53263642 https://blog.csdn.net/lihang_1994/ ...
随机推荐
- Redis 主从配置(Windows版)
安装从库 1.复制一份 Redis 文件,当做从库. 2.修改从库文件中 redis.windows.conf 的端口号. 3.安装服务,需要重新设置名称.然后去服务中,开启“redis6380”(此 ...
- Linux下的搜索查找命令的详解(which)
我们经常在linux要查找某个文件,但不知道放在哪里了,可以使用下面的一些命令来搜索: which 查看可执行文件的位置. whereis 查看文件的位置. locate 配合数据库查看文件 ...
- Apache kylin进阶——元数据篇
一.Apache kylin元数据的存储 Apache kylin的元数据包括 立方体描述(cube description),立方体实例(cube instances)项目(project).作业( ...
- Javascript 异步处理与计时跳转
实现计时跳转的代码: <html lang="en"> <head> <meta charset="UTF-8"> < ...
- python os module
os 模块提供了非常丰富的方法用来处理文件和目录.常用的方法如下表所示: 序号 ...
- CSS div 高度满屏
方法一: 通过JQuery,获取窗体的高度,设置给对应的div.代码如下 ht = $(document.body).height(); $(); 缺点:由于浏览器是先解析css,后执行JS,导致页面 ...
- elk-插件(head、X-pack)(五)
一.修改ES配置,允许REST跨源操作ES服务器,添加以下2个配置,并重启ES. http.cors.enabled: true #如果启用了 HTTP 端口,那么此属性会指定是否允许跨源 REST ...
- 计算属性和监听,computed,watch
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- js设计模式(四)---迭代器模式
定义: 迭代器模式是指提供一种方法,顺序访问一个聚合对象中的各个元素,而又不需要暴露该对象的内部表示,迭代器模式可以把迭代的过程从业务逻辑中分离出来,使用迭代器模式,即使不关心对象的内部构造,也可以按 ...
- 补充:ajax post 方式请求
1. 什么是ajax Ajax: asynchronous javascript and xml (异步js和xml) 其是可以与服务器进行(异步/同步)交互的技术之一. ajax的语言载体是j ...