HBase 笔记3
数据模型
Namespace 表命名空间: 多个表分到一个组进行统一的管理,需要用到表命名空间
表命名空间主要是对表分组,对不同组进行不同环境设定,如配额管理 安全管理
保留表空间: HBase中有2个保留表空间是预先定义
HBase 系统表空间,用于HBase内部表
default: 哪些没有定义表空间的表都被分配到这个下面
Table 表:由一个或多个列族组成
Row 行:一行包含多个列,这些列通过列族分类
ColumnFamily 列族:列族是多个列的集合
Column Qualifier列: 多个列组成一行,列可以随意定义的,一个行中的列不限名字,不限数量,只限定列族
cell 单元格: 一个列中可以存储多个版本的数据,每个版本称为一个单元格cell
Timestamp 时间戳:也可以称为版本号
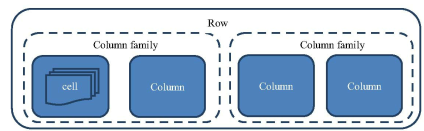
HBase存储数据
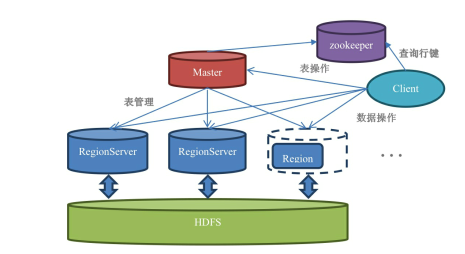
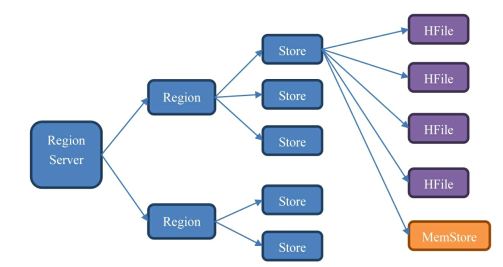
Master: 负责启动的时候分配Region到具体的Region Server,执行各种管理操作,如Region的分割和合并
RegionServer:一个Region Server上存在一个或多个Region,就是多个Region的集合
Region: 表的一部分数据,HBase是一个自动分片的数据库,一个Region相当于关系型数据库中分区表的一个分区,每个region都有其实起始rowkey和结束rowkey
HDFS:Hadoop一部分,HBASE与HDFS交互,HDFS是真正承载数据库的载体
Zookeeper:第三方组件,不属于HBase。client需要读取的元数据表hbase:meta位置存在zookeeper上
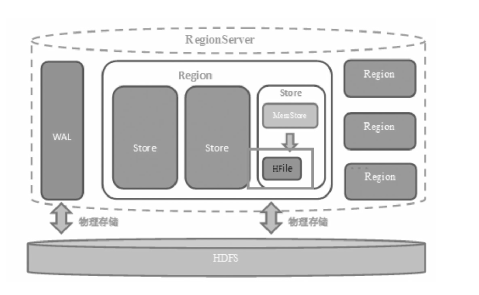
当操作到达Region时,HBase会把操作写入WAL(预写日志)中,同时数据存在基于内存的Memstore里,待达到一定数据量,刷写flush 到最终存储HFile内
故障恢复时,使用WAL可以恢复数据
Store:每个region中包含多个Store实例,一个Store对应一个列组的数据
memstore: 由于HDFS上文件不可修改, 数据会在memstore中整理成LSM树(顺序存储),之后刷写到HFile中,提高读取效率
读取数据时先读取blockcache,再读取HFile+memstore
WAL 预写日志是解决宕机之后的恢复问题
数据到达Region时先写入WAL,然后再加载到memstore中,WAL中数据存储再HDFS上,不会丢失
关闭/打开WAL

异步的同步WAL

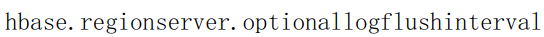 HBase间隔多久会把操作从内存写入WAL,默认1s
HBase间隔多久会把操作从内存写入WAL,默认1s
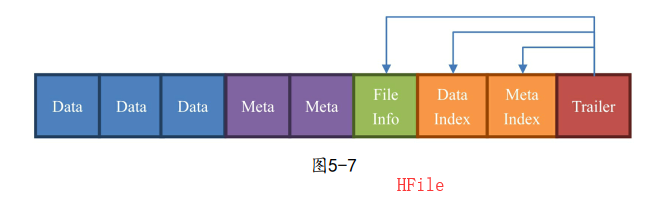
HFile由一个一个块组成,再HBase中一个块默认64KB,由列族上BLOCKSIZE属性定义
Data:数据块 存储HBase表中的数据
Meta: 元数据快 存储该HFile文件的元数据信息
FileInfo 文件信息,时HFile的必要组成部分,存储这个文件的信息,如最后一个Key,平均Key的长度
DataIndex 存储Data块索引信息的块文件么就是Data块的偏移值
MetaIndex : 存储Meta块索引信息的块文件
Trailer 必选,存储FileInfo DataIndex MetaIndex 块的偏移值'

Data数据块的第一位存储的是块的类型,后面存储的是多个keyvalue键值对,也就是单元格cell的实现类
cell是一个接口,keyvalue是实现类

Row 行键 CF 列族 Col 列 TimeStamp 时间戳
增删改查真面目:
HBase的增删改查实际都是新增操作:
新增单元格时,HBase在HDFS上新增一条数据
修改一个单元格时,HBase在HDFS上又新增一条数据,只是版本号比之前的大
删除一个单元格时,HBase还是新增数据,只是数据没有value,类型为delete,并打上墓碑标记
数据真正删除时是HFile合并时,忽略墓碑标记的数据,完成删除
数据写入

数据发出的第一时间被写入WAL,随后数据会立即被放入memstore中整理,最后当memstore太大达到阈值后,Flush到存储在硬盘上的HFile文件
数据读取
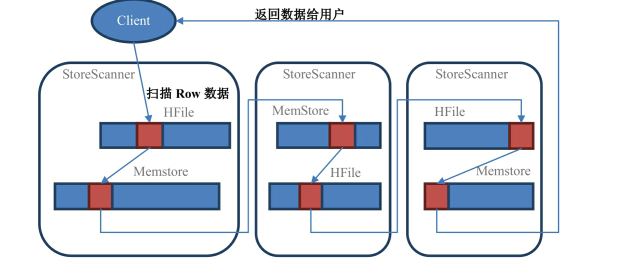
HBase 的scan操作会读取行键中的所有值,这样才能确定返回哪些数据(数据和墓碑标记不是存放在一起的)
在Scan时store会创建store scanner实例把么么store和hfile结合起来扫描,storescanner打开时,会先定位起始行键startRow上,开始往下扫描
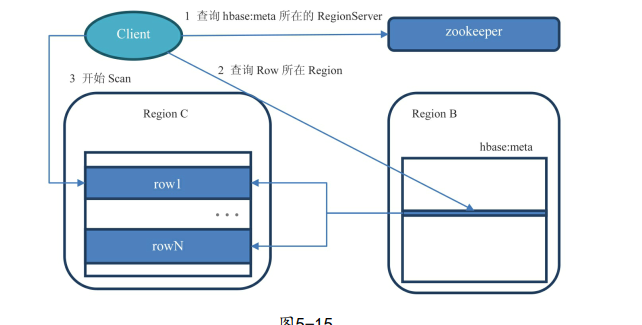
Region定位:

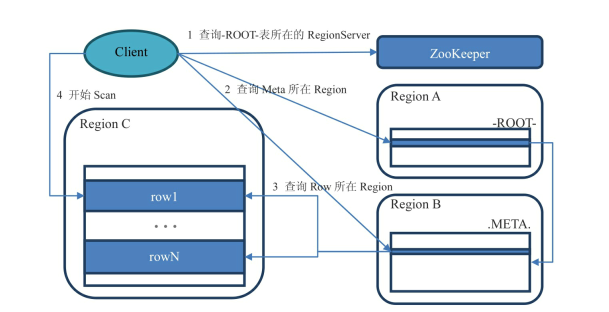
.META 元数据表,存储了所有的Region信息,一行记录就是一个Region,记录了Region的起始行,结束行,和该Region的连接信息,这样client可以通过这个来判断需要的数据在哪个region上
-ROOT- 存储.META.的表的表 ,即存储了.Meta.在什么Region上的信息
1)用户通过查找zookeeper上的/hbase/root-region-server节点获取-ROOT-表在哪个Region Server上
2)访问-ROOt-表,看数据在哪个.Meta.表上,这个表在哪个Region Server上
3)访问.Meta.表查询行键在哪个region里
4)连接具体数据所在的Region Server上,使用scan遍历row
从0.96版本之后,三层查询架构改成二层,-ROOT-去掉,.Meta.表所在的region server信息存储在ZK中的/hbase/meta-region-server中,再后来引入namespace,.Meta.表修改为hbase:meta
HBase 笔记3的更多相关文章
- HBase笔记:对HBase原理的简单理解
早些时候学习hadoop的技术,我一直对里面两项技术倍感困惑,一个是zookeeper,一个就是Hbase了.现在有机会专职做大数据相关的项目,终于看到了HBase实战的项目,也因此有机会搞懂Hbas ...
- Hbase笔记——RowKey设计
一).什么情况下使用Hbase 1)传统数据库无法承载高速插入.大量读取. 2)Hbase适合海量,但同时也是简单的操作. 3)成熟的数据分析主题,查询模式确立不轻易改变. 二).现实场景 1.电商浏 ...
- HBase笔记--自定义filter
自定义filter需要继承的类:FilterBase 类里面的方法调用顺序 方法名 作用 1 boolean filterRowKey(Cell cell) 根据row key过滤row.如果需要 ...
- HBase笔记--filter的使用
HBASE过滤器介绍: 所有的过滤器都在服务端生效,叫做谓语下推(predicate push down),这样可以保证被过滤掉的数据不会被传送到客户端. 注意: 基于字符串的比较器,如 ...
- HBase笔记--编程实战
HBase总结:http://blog.csdn.net/lifuxiangcaohui/article/details/39997205 (very good) Spark使用Java读取hbas ...
- HBase笔记--安装及启动过程中的问题
1.使用hbase shell的时候运行命令执行失败 例如:在shell下执行 status,失败. 可能的原因:节点之间的时间差距过大 解决方法调整两个节点的时间,使二者一致,这里用了个比较笨的方法 ...
- HBase笔记6 过滤器
过滤器 过滤器是GET或者SCAN时过滤结果用的,相当于SQL的where语句 HBase中的过滤器创建后会被序列化,然后分发到各个region server中,region server会还原过滤器 ...
- HBase笔记5(诊断)
阻塞急救: RegionServer内存设置太小: 解决方案: 设置Region Server的内存要在conf/hbase-env.sh中添加export HBASE_REGIONSERVER_OP ...
- HBase笔记4(调优)
Master/Region Server调优 JVM调优 默认的RegionServer内存是1G,而Memstore默认占40%,即400M,实在是太小了,可以通过HBASE_HEAPSIZE参数修 ...
随机推荐
- HBuilder打包React单页面,Android返回功能
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <meta name ...
- MySQL 千万 级数据量根据(索引)优化 查询 速度
一.索引的作用 索引通俗来讲就相当于书的目录,当我们根据条件查询的时候,没有索引,便需要全表扫描,数据量少还可以,一旦数据量超过百万甚至千万,一条查询sql执行往往需要几十秒甚至更多,5秒以上就已经让 ...
- vue+node+mongodb前后端分离博客系统
感悟 历时两个多月,终于利用工作之余完成了这个项目的1.0版本,为什么要写这个项目?其实基于vuejs+nodejs构建的开源博客系统有很多,但是大多数不支持服务端渲染,也不支持动态标题,只是做到了前 ...
- 这样使用 GPU 渲染 CSS 动画(转)
大多数人知道现代网络浏览器使用GPU来渲染部分网页,特别是具有动画的部分. 例如,使用transform属性的CSS动画看起来比使用left和top属性的动画更平滑. 但是如果你问,“我如何从GPU获 ...
- thinkcmf 忘记后台登陆密码的解决办法
thinkcmf 忘记密码 或者 密码错误 如何修改后台登陆密码? 直接在后台登陆控制器里输入 dump(cmf_password('123456')); 参考文件路径 app\admin\contr ...
- Linux下的搜索查找命令的详解(locate)
3.locate locate 让使用者可以很快速的搜寻档案系统内是否有指定的档案.其方法是先建立一个包括系统内所有档案名称及路径的数据库,之后当寻找时就只需查询这个数据库,而不必实际深入档案系统之中 ...
- Apache kylin进阶——元数据篇
一.Apache kylin元数据的存储 Apache kylin的元数据包括 立方体描述(cube description),立方体实例(cube instances)项目(project).作业( ...
- 剑指offer——python【第31题】整数1出现的次数
题目描述 求出1~13的整数中1出现的次数,并算出100~1300的整数中1出现的次数?为此他特别数了一下1~13中包含1的数字有1.10.11.12.13因此共出现6次,但是对于后面问题他就没辙了. ...
- Python学习之旅(十九)
Python基础知识(18):面向对象高级编程(Ⅰ) 使用__slots__:限制实例的属性,只允许实例对类添加某些属性 (1)实例可以随意添加属性 (2)某个实例绑定的方法对另一个实例不起作用 (3 ...
- Linux 命令 which whereis locate find
which: 查询某指令的完整路径 $ which [-a] command -a: 将所有在PATH目录中可以找到的指令均列出. 注意:只搜索PATH下的路径. whereis: 只搜索几个特定目录 ...