MySQL 进阶之索引
一,索引前传
在了解数据库索引之前,首先有必要了解一下数据库索引的数据结构基础,那么什么样的数据结构可以作为索引呢?
B-tree是最常用的用于索引的数据结构。因为它们是时间复杂度低, 查找、删除、插入操作都可以可以在对数时间内完成。另外一个重要原因存储在B-Tree中的数据是有序的。数据库管理系统(RDBMS)通常决定索引应该用哪些数据结构。但是,在某些情况下,你在创建索引时可以指定索引要使用的数据结构。
B+是一个树数据结构,通常用于数据库和操作系统的文件系统中,B+树的特点是能够保持数据稳定有序,其插入与修改拥有比较稳定的对数时间复杂度,B+树元素自底向上插入,这个和二叉树刚好相反。
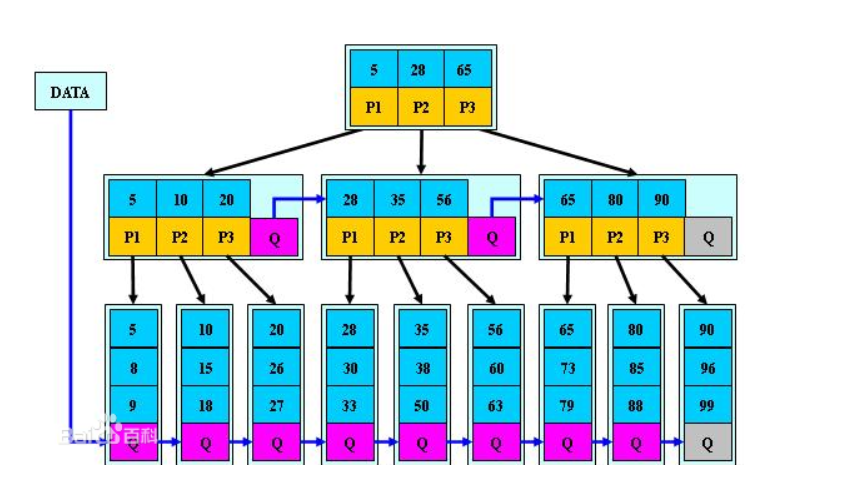
B+tree 是一个n叉树,每个节点有多个叶子节点,一颗B+树包含根节点,内部节点,叶子节点。根节点可能是一个叶子节点,也可能是一个包含两个或两个以上叶子节点的节点。
B+tree的性质:
1.n棵子tree的节点包含n个关键字,不用来保存数据而是保存数据的索引。
2.所有的叶子结点中包含了全部关键字的信息,及指向含这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
3.所有的非终端结点可以看成是索引部分,结点中仅含其子树中的最大(或最小)关键字。
由于B+tree的性质, 它通常被用于数据库和操作系统的文件系统中。NTFS, ReiserFS, NSS, XFS, JFS, ReFS 和BFS等文件系统都在使用B+树作为元数据索引,因为B+ 树的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度(B+ 树元素自底向上插入)。
B+tree结构原型图大概如下(引用):
哈希表索引是怎么工作的?
哈希表是另外一种你可能看到用作索引的数据结构-这些索引通常被称为哈希索引。使用哈希索引的原因是,在寻找值时哈希表效率极高。所以,如果使用哈希索引,对于比较字符串是否相等的查询能够极快的检索出的值。
哈希索引的缺点是什么呢?
哈希表是无顺的数据结构,对于很多类型的查询语句哈希索引都无能为力。举例来说,假如你想要找出所有小于40岁的员工。你怎么使用使用哈希索引进行查询?这不可行,因为哈希表只适合查询键值对-也就是说查询相等的查询(例:like “WHERE name = ‘Jesus’)。哈希表的键值映射也暗示其键的存储是无序的。这就是为什么哈希索引通常不是数据库索引的默认数据结构-因为在作为索引的数据结构时,其不像B-Tree那么灵活
还有什么其他类型的索引?
使用R-Tree作为数据结构的索引通常用来为空间问题提供帮助。例如,一个查询要求“查询出所有距离我两公里之内的星巴克”,如果数据库表使用R- Tree索引,这类查询的效率将会提高。
另一种索引是位图索引(bitmap index), 这类索引适合放在包含布尔值(true 和 false)的列上,但是这些值(表示true或false的值)的许多实例-基本上都是选择性(selectivity)低的列。
二,索引内容
2.1、索引
索引是对数据库表中一列或者多列的值进行排序的一种结构,使用索引可以快速访问数据库表中的特定信息,索引有助于更快的获取信息。索引是表的目录,在查找内容之前可以先在目录中查找索引位置,以此快速定位查询数据。对于索引,会保存在额外的文件中。
索引的一个主要的目的就是加快检索表中数据的方法,也可以协助信息搜寻者能尽快的找到符合限制条件的记录。
2.2、索引种类
- 普通索引:仅加速查询
- 唯一索引:加速查询 + 列值唯一(可以有null)
- 唯一索引是不允许其中任何两行具有相同索引值的索引,当现有数据存在大量的重复的键值的时候,大多数数据库不允许唯一索引与表一起保存,数据库还可能防止添加将表中创建重复键值的新数据。
- 主键索引:加速查询 + 列值唯一 + 表中只有一个(不可以有null)
- 数据库表经常有一列或者多列组合,其值唯一标识表中的每一行,每一列称为表的主键,在数据库关系图中为表定义主键将自动创建主键索引,主键索引是唯一索引的特定类型,该索引要求主键索引的每个值都唯一。
- 组合索引:多列值组成一个索引,
专门用于组合搜索,其效率大于索引合并 - 全文索引:对文本的内容进行分词,进行搜索
——普通索引
-1,创建表 + 索引
create table in1(
nid int not null auto_increment primary key,
name varchar(32) not null,
email varchar(64) not null,
extra text,
index ix_name (name)
)
-2,创建表
create index index_name on table_name(column_name)
-3,删除表
drop index_name on table_name;
-4,查看索引
show index from table_name;
注意:对于创建索引时如果是BLOB 和 TEXT 类型,必须指定length。
create index ix_extra on in1(extra(32));
——唯一索引
-1,创建表 + 唯一索引
create table in1(
nid int not null auto_increment primary key,
name varchar(32) not null,
email varchar(64) not null,
extra text,
unique ix_name (name)
)
-2,创建唯一索引
create unique index 索引名 on 表名(列名)
-3,删除唯一索引
drop unique index 索引名 on 表名
——主键索引
-1,创建表+创建主键
create table in1(
nid int not null auto_increment primary key,
name varchar(32) not null,
email varchar(64) not null,
extra text,
index ix_name (name)
) OR create table in1(
nid int not null auto_increment,
name varchar(32) not null,
email varchar(64) not null,
extra text,
primary key(ni1),
index ix_name (name)
)
-2,创建主键
alter table 表名 add primary key(列名);
-3,删除主键
alter table 表名 drop primary key;
alter table 表名 modify 列名 int, drop primary key;
——组合索引
组合索引是将n个列组合成一个索引
其应用场景为:频繁的同时使用n列来进行查询,如:where n1 = 'alex' and n2 = 666。
-1,创建表
create table in3(
nid int not null auto_increment primary key,
name varchar(32) not null,
email varchar(64) not null,
extra text
)
-2,创建组合索引
create index ix_name_email on in3(name,email);
如上创建组合索引之后,查询:
- name and email -- 使用索引
- name -- 使用索引
- email -- 不使用索引
注意:对于同时搜索n个条件时,组合索引的性能好于多个单一索引合并。
——其他
-1,条件语句(if条件语句例子)
delimiter \\
CREATE PROCEDURE proc_if ()
BEGIN declare i int default 0;
if i = 1 THEN
SELECT 1;
ELSEIF i = 2 THEN
SELECT 2;
ELSE
SELECT 7;
END IF; END\\
delimiter ;
-2,while循环语句
delimiter \\
CREATE PROCEDURE proc_while ()
BEGIN DECLARE num INT ;
SET num = 0 ;
WHILE num < 10 DO
SELECT
num ;
SET num = num + 1 ;
END WHILE ; END\\
delimiter ;
-3,repeat循环语句
delimiter \\
CREATE PROCEDURE proc_repeat ()
BEGIN DECLARE i INT ;
SET i = 0 ;
repeat
select i;
set i = i + 1;
until i >= 5
end repeat; END\\
delimiter ;
-4,loop循环语句
BEGIN
declare i int default 0;
loop_label: loop
set i=i+1;
if i<8 then
iterate loop_label;
end if;
if i>=10 then
leave loop_label;
end if;
select i;
end loop loop_label;
END
-5,动态执行SQL语句
delimiter \\
DROP PROCEDURE IF EXISTS proc_sql \\
CREATE PROCEDURE proc_sql ()
BEGIN
declare p1 int;
set p1 = 11;
set @p1 = p1; PREPARE prod FROM 'select * from tb2 where nid > ?';
EXECUTE prod USING @p1;
DEALLOCATE prepare prod; END\\
delimiter ;
2.3、相关命令
查看表结构
desc 表名 - 查看生成表的SQL
show create table 表名 - 查看索引
show index from 表名 - 查看执行时间
set profiling = 1;
SQL...
show profiles;
2.4、索引的优缺点(使用索引和不使用索引)
- 在设计数据库时,通过创建一个惟一的索引,能够在索引和信息之间形成一对一的映射式的对应关系,增加数据的惟一性特点。
- 能提高数据的搜索及检索速度,符合数据库建立的初衷。
- 能够加快表与表之间的连接速度,这对于提高数据的参考完整性方面具有重要作用。
- 在信息检索过程中,若使用分组及排序子句进行时,通过建立索引能有效的减少检索过程中所需的分组及排序时间,提高检索效率。
- 建立索引之后,在信息查询过程中可以使用优化隐藏器,这对于提高整个信息检索系统的性能具有重要意义。
- 在数据库建立过程中,需花费较多的时间去建立并维护索引,特别是随着数据总量的增加,所花费的时间将不断递增。
- 在数据库中创建的索引需要占用一定的物理存储空间,这其中就包括数据表所占的数据空间以及所创建的每一个索引所占用的物理空间,如果有必要建立起聚簇索引,所占用的空间还将进一步的增加
- 在对表中的数据进行修改时,例如对其进行增加、删除或者是修改操作时,索引还需要进行动态的维护,这给数据库的维护速度带来了一定的麻烦。
由于索引是专门用于加速搜索而生,所以加上索引之后,查询效率会快到飞起来。 # 有索引
mysql> select * from tb1 where name = 'wupeiqi-888';
+-----+-------------+---------------------+----------------------------------+---------------------+
| nid | name | email | radom | ctime |
+-----+-------------+---------------------+----------------------------------+---------------------+
| 255 | tonm | 12474565666@qq.com | cdccccce76a16a90b8a8301d5314204b | 2017-08-03 09:33:35 |
+-----+-------------+---------------------+----------------------------------+---------------------+
1 row in set (0.00 sec) # 无索引
mysql> select * from tb1 where email = 'wupeiqi888@live.com';
+-----+-------------+---------------------+----------------------------------+---------------------+
| nid | name | email | radom | ctime |
+-----+-------------+---------------------+----------------------------------+---------------------+
| 256 | tonm | 12474565666@qq.com | 5312269e76a1clslclscc01d5314204b | 2017-08-03 09:33:35 |
+-----+-------------+---------------------+----------------------------------+---------------------+
1 row in set (1.23 sec)
25、正确使用索引
数据库表中添加索引后确实会让查询速度起飞,但前提必须是正确的使用索引来查询,如果以错误的方式使用,则即使建立索引也会不奏效。
即使建立索引,索引也不会生效:
- like '%xx'
select * from tb1 where name like '%cn';
- 使用函数
select * from tb1 where reverse(name) = 'wupeiqi';
- or
select * from tb1 where nid = 1 or email = 'seven@live.com';
特别的:当or条件中有未建立索引的列才失效,以下会走索引
select * from tb1 where nid = 1 or name = 'seven';
select * from tb1 where nid = 1 or email = 'seven@live.com' and name = 'alex'
- 类型不一致
如果列是字符串类型,传入条件是必须用引号引起来,不然...
select * from tb1 where name = 999;
- !=
select * from tb1 where name != 'alex'
特别的:如果是主键,则还是会走索引
select * from tb1 where nid != 123
- >
select * from tb1 where name > 'alex'
特别的:如果是主键或索引是整数类型,则还是会走索引
select * from tb1 where nid > 123
select * from tb1 where num > 123
- order by
select email from tb1 order by name desc;
当根据索引排序时候,选择的映射如果不是索引,则不走索引
特别的:如果对主键排序,则还是走索引:
select * from tb1 order by nid desc; - 组合索引最左前缀
如果组合索引为:(name,email)
name and email -- 使用索引
name -- 使用索引
email -- 不使用索引
2.6,使用索引注意事项
三,索引后记
3.1把数据库索引类比成什么比较好呢?
一个非常好的类比是把数据库索引看作是书的索引。如果你有一本关于狗的书,你想要找关于‘黄金猎犬’的那部分。当你可以通过在书背的索引找到哪几页有关于‘黄金猎犬’信息的时候,你为什么要翻完正本书 - 这相当于数据库中的全表扫描。同样的,就像一本书的索引包含页码一样,数据库的索引包含了指针,指向你在SQL中想要查询的值所在的行。
3.2使用数据库索引会有什么代价?
那么,使用数据库索引有什么缺点呢?其一,索引会占用空间 - 你的表越大,索引占用的空间越大。其二,性能损失(主要值更新操作),当你在表中添加、删除或者更新行数据的时候, 在索引中也会有相同的操作。
记住:建立在某列(或多列)索引需要保存该列最新的数据。
基本原则是只如果表中某列在查询过程中使用的非常频繁,那就在该列上创建索引。
3.3、limit分页
无论是否有索引,limit分页是一个值得关注的问题
每页显示10条:
当前 118 120, 125 倒序:
大 小
970 7 6 6 5 54 43 32
19 98
下一页: select
*
from
tb1
where
nid < (select nid from (select nid from tb1 where nid < 当前页最小值 order by nid desc limit 每页数据 *【页码-当前页】) A order by A.nid asc limit 1)
order by
nid desc
limit 10; select
*
from
tb1
where
nid < (select nid from (select nid from tb1 where nid < 970 order by nid desc limit 40) A order by A.nid asc limit 1)
order by
nid desc
limit 10; 上一页: select
*
from
tb1
where
nid < (select nid from (select nid from tb1 where nid > 当前页最大值 order by nid asc limit 每页数据 *【当前页-页码】) A order by A.nid asc limit 1)
order by
nid desc
limit 10; select
*
from
tb1
where
nid < (select nid from (select nid from tb1 where nid > 980 order by nid asc limit 20) A order by A.nid desc limit 1)
order by
nid desc
limit 10;
3.4、执行计划
explain + 查询SQL - 用于显示SQL执行信息参数,根据参考信息可以进行SQL优化
mysql> explain select * from tb2;
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| 1 | SIMPLE | tb2 | ALL | NULL | NULL | NULL | NULL | 2 | NULL |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
1 row in set (0.00 sec)
id
查询顺序标识
如:mysql> explain select * from (select nid,name from tb1 where nid < 10) as B;
+----+-------------+------------+-------+---------------+---------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+-------+---------------+---------+---------+------+------+-------------+
| 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 9 | NULL |
| 2 | DERIVED | tb1 | range | PRIMARY | PRIMARY | 8 | NULL | 9 | Using where |
+----+-------------+------------+-------+---------------+---------+---------+------+------+-------------+
特别的:如果使用union连接气值可能为null select_type
查询类型
SIMPLE 简单查询
PRIMARY 最外层查询
SUBQUERY 映射为子查询
DERIVED 子查询
UNION 联合
UNION RESULT 使用联合的结果
...
table
正在访问的表名 type
查询时的访问方式,性能:all < index < range < index_merge < ref_or_null < ref < eq_ref < system/const
ALL 全表扫描,对于数据表从头到尾找一遍
select * from tb1;
特别的:如果有limit限制,则找到之后就不在继续向下扫描
select * from tb1 where email = 'seven@live.com'
select * from tb1 where email = 'seven@live.com' limit 1;
虽然上述两个语句都会进行全表扫描,第二句使用了limit,则找到一个后就不再继续扫描。 INDEX 全索引扫描,对索引从头到尾找一遍
select nid from tb1; RANGE 对索引列进行范围查找
select * from tb1 where name < 'alex';
PS:
between and
in
> >= < <= 操作
注意:!= 和 > 符号 INDEX_MERGE 合并索引,使用多个单列索引搜索
select * from tb1 where name = 'alex' or nid in (11,22,33); REF 根据索引查找一个或多个值
select * from tb1 where name = 'seven'; EQ_REF 连接时使用primary key 或 unique类型
select tb2.nid,tb1.name from tb2 left join tb1 on tb2.nid = tb1.nid; CONST 常量
表最多有一个匹配行,因为仅有一行,在这行的列值可被优化器剩余部分认为是常数,const表很快,因为它们只读取一次。
select nid from tb1 where nid = 2 ; SYSTEM 系统
表仅有一行(=系统表)。这是const联接类型的一个特例。
select * from (select nid from tb1 where nid = 1) as A;
possible_keys
可能使用的索引 key
真实使用的 key_len
MySQL中使用索引字节长度 rows
mysql估计为了找到所需的行而要读取的行数 ------ 只是预估值 extra
该列包含MySQL解决查询的详细信息
“Using index”
此值表示mysql将使用覆盖索引,以避免访问表。不要把覆盖索引和index访问类型弄混了。
“Using where”
这意味着mysql服务器将在存储引擎检索行后再进行过滤,许多where条件里涉及索引中的列,当(并且如果)它读取索引时,就能被存储引擎检验,因此不是所有带where子句的查询都会显示“Using where”。有时“Using where”的出现就是一个暗示:查询可受益于不同的索引。
“Using temporary”
这意味着mysql在对查询结果排序时会使用一个临时表。
“Using filesort”
这意味着mysql会对结果使用一个外部索引排序,而不是按索引次序从表里读取行。mysql有两种文件排序算法,这两种排序方式都可以在内存或者磁盘上完成,explain不会告诉你mysql将使用哪一种文件排序,也不会告诉你排序会在内存里还是磁盘上完成。
“Range checked for each record(index map: N)”
这个意味着没有好用的索引,新的索引将在联接的每一行上重新估算,N是显示在possible_keys列中索引的位图,并且是冗余的。 详细

1)、id列数字越大越先执行,如果说数字一样大,那么就从上往下依次执行,id列为null的就表是这是一个结果集,不需要使用它来进行查询。
3.5、慢日志查询
a、配置MySQL自动记录慢日志
slow_query_log = OFF 是否开启慢日志记录
long_query_time = 2 时间限制,超过此时间,则记录
slow_query_log_file = /usr/slow.log 日志文件
log_queries_not_using_indexes = OFF 为使用索引的搜索是否记录
注:查看当前配置信息:
show variables like '%query%'
修改当前配置:
set global 变量名 = 值
b、查看MySQL慢日志
mysqldumpslow -s at -a /usr/local/var/mysql/MacBook-Pro-3-slow.log
"""
--verbose 版本
--debug 调试
--help 帮助 -v 版本
-d 调试模式
-s ORDER 排序方式
what to sort by (al, at, ar, c, l, r, t), 'at' is default
al: average lock time
ar: average rows sent
at: average query time
c: count
l: lock time
r: rows sent
t: query time
-r 反转顺序,默认文件倒序拍。reverse the sort order (largest last instead of first)
-t NUM 显示前N条just show the top n queries
-a 不要将SQL中数字转换成N,字符串转换成S。don't abstract all numbers to N and strings to 'S'
-n NUM abstract numbers with at least n digits within names
-g PATTERN 正则匹配;grep: only consider stmts that include this string
-h HOSTNAME mysql机器名或者IP;hostname of db server for *-slow.log filename (can be wildcard),
default is '*', i.e. match all
-i NAME name of server instance (if using mysql.server startup script)
-l 总时间中不减去锁定时间;don't subtract lock time from total time
"""
数据库的索引非常重要,基本面试数据库的问题都在索引上,所以这里小编整理出来,一方面为了自己复习,一方面也方便大家。
(关于MySQL的安装,具体见下面博客:http://www.cnblogs.com/wj-1314/p/7573242.html)
(关于MySQL的基础知识,具体见下面博客:http://www.cnblogs.com/wj-1314/p/8343101.html)
(关于MySQL的笔试知识,具体见下面博客:http://www.cnblogs.com/wj-1314/p/7643125.html)
此篇博客主要参考:http://www.cnblogs.com/wupeiqi/articles/5716963.html;http://www.cnblogs.com/xiaoboluo768/p/5400990.html,写在这里主要是为了巩固学习知识,同时希望更多的同学学习。
MySQL 进阶之索引的更多相关文章
- 数据库 MySQL进阶之索引
数据库的索引非常重要,基本面试数据库的问题都在索引上,所以这里小编整理出来,一方面为了自己复习,一方面也方便大家. 一,索引前传 在了解数据库索引之前,首先有必要了解一下数据库索引的数据结构基础,那么 ...
- mysql进阶(二)索引简易教程
Mysql索引简易教程 基本概念 索引是指把你设置为索引的字段A的内容储存在一个独立区间S里,里面只有这个字段的内容.在找查这个与这个字段A的内容时会直接从这个独立区间里查找,而不是去到数据表里查找. ...
- MySQL进阶之索引
一.索引的本质: 数据库查询是数据库的最主要的功能之一,数据库系统的设计者从查询算法的角度对数据库进行了一定的优化. 最基本的顺序查找算法的复杂度为O(n),在数据量很大的时候算法的效率是很低的.虽然 ...
- MySQL进阶篇(03):合理的使用索引结构和查询
本文源码:GitHub·点这里 || GitEE·点这里 一.高性能索引 1.查询性能问题 在MySQL使用的过程中,所谓的性能问题,在大部分的场景下都是指查询的性能,导致查询缓慢的根本原因是数据量的 ...
- mysql进阶(二十七)数据库索引原理
mysql进阶(二十七)数据库索引原理 前言 本文主要是阐述MySQL索引机制,主要是说明存储引擎Innodb. 第一部分主要从数据结构及算法理论层面讨论MySQL数据库索引的数理基础. ...
- mysql进阶(二十六)MySQL 索引类型(初学者必看)
mysql进阶(二十六)MySQL 索引类型(初学者必看) 索引是快速搜索的关键.MySQL 索引的建立对于 MySQL 的高效运行是很重要的.下面介绍几种常见的 MySQL 索引类型. 在数 ...
- Python进阶----索引原理,mysql常见的索引,索引的使用,索引的优化,不能命中索引的情况,explain执行计划,慢查询和慢日志, 多表联查优化
Python进阶----索引原理,mysql常见的索引,索引的使用,索引的优化,不能命中索引的情况,explain执行计划,慢查询和慢日志, 多表联查优化 一丶索引原理 什么是索引: 索引 ...
- MySQL进阶篇(02):索引体系划分,B-Tree结构说明
本文源码:GitHub·点这里 || GitEE·点这里 一.索引简介 1.基本概念 首先要明确索引是什么:索引是一种数据结构,数据结构是计算机存储.组织数据的方式,是指相互之间存在一种或多种特定关系 ...
- mysql进阶(二)之细谈索引、分页与慢日志
索引 1.数据库索引 数据库索引是一种数据结构,可以以额外的写入和存储空间为代价来提高数据库表上的数据检索操作的速度,以维护索引数据结构.索引用于快速定位数据,而无需在每次访问数据库表时搜索数据库表中 ...
随机推荐
- 网络编程初识和socket套接字
网络的产生 不同机器上的程序要通信,才产生了网络:凡是涉及到倆个程序之间通讯的都需要用到网络 软件开发架构 软件开发架构的类型:应用类.web类 应用类:qq.微信.网盘.优酷这一类是属于需要安装的桌 ...
- powershell获取windows子文件夹的大小
$startFolder = "E:\Migration\" $colItems = (Get-ChildItem $startFolder | Where-Object {$_. ...
- Unity、C#读取XML
有如下XML文件: <?xml version="1.0" encoding="UTF-8"?> <DataNode> <prov ...
- Bootstrap方法为页面添加一个弹出框
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- AFNetworking 3.0中调用[AFHTTPSessionManager manager]方法导致内存泄漏的解决办法
在使用AFNetworking3.0框架,使用Instruments检查Leaks时,检测到1000多个内存泄漏的地方,定位到 [AFHTTPSessionManager manager] 语句中,几 ...
- Dynamic Programming | Set 1 (Overlapping Subproblems Property)
动态规划是这样一种算法范式:将复杂问题划分为子问题来求解,并且将子问题的结果保存下来以避免重复计算.如果一个问题拥有以下两种性质,则建议使用动态规划来求解. 1 重叠子问题(Overlapping S ...
- 背水一战 Windows 10 (70) - 控件(控件基类): UIElement - Transform3D(3D变换), Projection(3D投影)
[源码下载] 背水一战 Windows 10 (70) - 控件(控件基类): UIElement - Transform3D(3D变换), Projection(3D投影) 作者:webabcd 介 ...
- Android 使用 HTTPS 问题解决(SSLHandshakeException)
title date categories tags Android 5.0以下TLS1.x SSLHandshakeException 2016-11-30 12:17:02 -0800 Andro ...
- JDBC的使用和SQL注入问题
基本的JDBC使用: package demo; import java.sql.Connection; import java.sql.DriverManager; import java.sql. ...
- Python: Ubuntu 安装numpy,scipy,matplotlib
安装python-dev 安装这个包,以后安装各种python扩展包,可以省很多事情. sudo apt-get install python-dev 使用apt-get 安装 只需要下面的几个命令即 ...