docker 日志方案
docker logs默认会显示命令的标准输出(STDOUT)和标准错误(STDERR)。下面使用echo.sh和Dockerfile创建一个名为echo.v1的镜像,echo.sh会一直输出”hello“
[root@ docker]# cat echo.sh
#!/bin/sh
while true;do echo hello;sleep ;done
[root@ docker]# cat Dockerfile
FROM busybox:latest
WORKDIR /home
COPY echo.sh /home
CMD [ "sh", "-c", "/home/echo.sh" ]
# chmod echo.sh
# docker build -t echo:v1 .
运行上述镜像,在对于的容器进程目录下可以看到该进程打开个4个文件,其中fd为10的即是运行的shell 脚本,
# ps -ef|grep echo
root : pts/ :: /bin/sh /home/echo.sh
root : pts/ :: grep --color=auto echo
[root@ docker]# cd /proc//fd
[root@ fd]# ll
lrwx------. root root Jan : -> /dev/pts/
lrwx------. root root Jan : -> /dev/pts/
lr-x------. root root Jan : -> /home/echo.sh
lrwx------. root root Jan : -> /dev/pts/
执行docker logs -f CONTAINER_ID 跟踪容器输出,fd为1的文件为docker logs记录的输出,可以直接导入一个自定义的字符串,如echo ”你好“ > 1,可以在docker log日志中看到如下输出
hello
hello
你好
hello
docker支持多种插件,可以在docker启动时通过命令行传递log driver,也可以通过配置docker的daemon.json文件来设置dockerd的log driver。docker默认使用json-file的log driver,使用如下命令查看当前系统的log driver
# docker info --format '{{.LoggingDriver}}'
json-file
下面使用journald来作为log driver
# docker run -itd --log-driver=journald echo:v1
8a8c828fa673c0bea8005d3f53e50b2112b4c8682d7e04100affeba25ebd588c
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
8a8c828fa673 echo:v1 "sh -c /home/echo.sh" minutes ago Up minutes vibrant_curie
# journalctl CONTAINER_NAME=vibrant_curie --all
在journalctl中可以看到有如下log日志,8a8c828fa673就是上述容器的ID
-- Logs begin at Fri -- :: CST, end at Mon -- :: CST. --
Jan :: . 8a8c828fa673[]: hello
Jan :: . 8a8c828fa673[]: hello
...
同时使用docker inspect查看该容器配置,可以看到log driver变为了journald,
"LogConfig": {
"Type": "journald",
"Config": {}
},
生产中一般使用日志收集工具来对服务日志进行收集和解析,下面介绍使用fluentd来采集日志,fluentd支持多种插件,支持多种日志的输入输出方式,插件使用方式可以参考官网。下载官方镜像
docker pull fluent/fluentd
首先创建一个fluentd的配置文件,该配置文件用于接收远端日志,并打印到标准输出
# cat fluentd.conf
<source>
@type forward
</source> <match *>
@type stdout
</match>
创建2个docker images,echo:v1和echo:v2,内容如下
# cat echo.sh ---echo:v1
#!/bin/sh
while true;do
echo "docker1 -> 11111"
echo "docker1,this is docker1"
echo "docker1,12132*)("
sleep
done
# cat echo.sh ----echo:v2
#!/bin/sh
while true;do
echo "docker2 -> 11111"
echo "docker2,this is docker1"
echo "docker2,12132*)("
sleep
done
首先启动fluentd,然后启动echo:v1,fluentd使用本地配置文件/home/fluentd/fluentd.conf替换默认配置文件,fluentd-address用于指定fluentd的地址,更多选项参见fluentd logging driver
# docker run -it --rm -p : -v /home/fluentd/fluentd.conf:/fluentd/etc/fluentd.conf -e FLUENTD_CONF=fluentd.conf fluent/fluentd:latest
# docker run --rm --name=docker1 --log-driver=fluentd --log-opt tag="{{.Name}}" --log-opt fluentd-address=192.168.80.189: echo:v1
fluentd默认绑定地址为0.0.0.0,即接收本机所有接口IP的数据,绑定端口为指定的端口24224,fluentd启动时有如下输出
[info]: # listening port port= bind="0.0.0.0"
在fluentd界面上可以看到echo:v1重定向过来的输出,下面加粗的docker1为容器启动时设置的tag值,docker支持tag模板,可以参考Customize log driver output
-- ::24.000000000 + docker1: {"container_name":"/docker1","source":"stdout","log":"docker1 -> 11111","container_id":"74c0af9defd10d33db0e197f0dd3af382a5c06a858f06bdd2f0f49e43bf0a25e"}
-- ::24.000000000 + docker1: {"container_id":"74c0af9defd10d33db0e197f0dd3af382a5c06a858f06bdd2f0f49e43bf0a25e","container_name":"/docker1","source":"stdout","log":"docker1,this is docker1"}
-- ::24.000000000 + docker1: {"container_id":"74c0af9defd10d33db0e197f0dd3af382a5c06a858f06bdd2f0f49e43bf0a25e","container_name":"/docker1","source":"stdout","log":"docker1,12132*)("}
上述场景中,如果fluentd没有启动,echo:v1也会启动失败,可以在容器启动时使用fluentd-async-connect来避免因fluentd退出或未启动而导致容器异常,如下图,当fluentd未启动也不会导致容器启动失败
docker run --rm --name=docker1 --log-driver=fluentd --log-opt tag="docker1.{{.Name}}" --log-opt fluentd-async-connect=true --log-opt fluentd-address=192.168.80.189: echo:v1
上述场景输出直接重定向到标准输出,也可以使用插件重定向到文件,fluentd使用如下配置文件,日志文件会重定向到/home/fluent目录下,match用于匹配echo:v1的输出(tag="docker1.{{.Name}}"),这样就可以过滤掉echo:v2的输出
# cat fluentd.conf
<source>
@type forward
</source> <match docker1.*>
@type file
path /home/fluent/
</match>
使用如下方式启动fluentd
# docker run -it --rm -p : -v /home/fluentd/fluentd.conf:/fluentd/etc/fluentd.conf -v /home/fluent:/home/fluent -e FLUENTD_CONF=fluentd.conf fluent/fluentd:latest
在/home/fluent下面可以看到有生成的日志文件
# ll
total
-rw-r--r--. charlie charlie Jan : buffer.b58095399160f67b3b56a8f76791e3f1a.log
-rw-r--r--. charlie charlie Jan : buffer.b58095399160f67b3b56a8f76791e3f1a.log.meta
上述展示了使用fluentd的标准输出来显示docker logs以及使用file来持久化日志。生产中一般使用elasticsearch作为日志的存储和搜索引擎,使用kibana为log日志提供显示界面。可以在这里获取各个版本的elasticsearch和kibana镜像以及使用文档,本次使用6.5版本的elasticsearch和kibana。注:启动elasticsearch时需要设置sysctl -w vm.max_map_count=262144
fluentd使用elasticsearch时需要在镜像中安装elasticsearch的plugin,也可以直接下载包含elasticsearch plugin的docker镜像,如果没有k8s.gcr.io/fluentd-elasticsearch的访问权限,可以pull这里的镜像。
使用docker-compose来启动elasticsearch,kibana和fluentd,文件结构如下
# ll
-rw-r--r--. root root Jan : docker-compose.yml
-rw-r--r--. root root Jan : elasticsearch.yml
-rw-r--r--. root root Jan : fluentd.conf
-rw-r--r--. root root Jan : kibana.yml
centos上docker-compose的安装可以参见这里。docker-compose.yml以及各组件的配置如下。它们共同部署在同一个bridge esnet上,同时注意kibana.yml和fluentd.yml中使用elasticsearch的service名字作为host。kibana的所有配置可以参见kibana.yml
# cat docker-compose.yml
version: ''
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:6.5.
container_name: elasticsearch
environment:
- http.host=0.0.0.0
- transport.host=0.0.0.0
- "ES_JAVA_OPTS=-Xms1g -Xmx1g"
volumes:
- esdata:/usr/share/elasticsearch/data
- ./elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
ports:
- :
- :
networks:
- esnet
ulimits:
memlock:
soft: -
hard: -
nofile:
soft:
hard:
mem_limit: 2g
cap_add:
- IPC_LOCK kibana:
image: docker.elastic.co/kibana/kibana:6.5.
depends_on:
- elasticsearch
container_name: kibana
environment:
- SERVER_HOST=0.0.0.0
volumes:
- ./kibana.yml:/usr/share/kibana/config/kibana.yml
ports:
- :
networks:
- esnet flunted:
image: fluentd-elasticsearch:v2.4.0
depends_on:
- elasticsearch
container_name: flunted
environment:
- FLUENTD_CONF=fluentd.conf
volumes:
- ./fluentd.conf:/etc/fluent/fluent.conf
ports:
- :
networks:
- esnet volumes:
esdata:
driver: local
networks:
esnet:
# cat elasticsearch.yml
cluster.name: "chimeo-docker-cluster"
node.name: "chimeo-docker-single-node"
network.host: 0.0.0.0
# cat kibana.yml
#kibana is served by a back end server. This setting specifies the port to use.
server.port: # Specifies the address to which the Kibana server will bind. IP addresses and host names are both valid values.
# The default is 'localhost', which usually means remote machines will not be able to connect.
# To allow connections from remote users, set this parameter to a non-loopback address.
server.host: "localhost" # The Kibana server's name. This is used for display purposes.
server.name: "charlie" # The URLs of the Elasticsearch instances to use for all your queries.
elasticsearch.url: "http://elasticsearch:9200" # Kibana uses an index in Elasticsearch to store saved searches, visualizations and
# dashboards. Kibana creates a new index if the index doesn't already exist.
kibana.index: ".kibana" # Time in milliseconds to wait for Elasticsearch to respond to pings. Defaults to the value of
# the elasticsearch.requestTimeout setting.
elasticsearch.pingTimeout: # Time in milliseconds to wait for responses from the back end or Elasticsearch. This value
# must be a positive integer.
elasticsearch.requestTimeout: # Time in milliseconds to wait for Elasticsearch at Kibana startup before retrying.
elasticsearch.startupTimeout: # Set the interval in milliseconds to sample system and process performance
# metrics. Minimum is 100ms. Defaults to .
ops.interval:
# cat fluentd.conf
<source>
@type forward
</source> <match **>
@type elasticsearch
log_level info
include_tag_key true
host elasticsearch
port
logstash_format true
chunk_limit_size 10M
flush_interval 5s
max_retry_wait
disable_retry_limit
num_threads
</match>
使用如下命令启动即可
# docker-compose up
启动一个使用fluentd的容器。注:测试过程中可以不加fluentd-async-connect=true,可以判定该容器是否能连接到fluentd
docker run -it --rm --name=docker1 --log-driver=fluentd --log-opt tag="fluent.{{.Name}}" --log-opt fluentd-async-connect=true --log-opt fluentd-address=127.0.0.1: echo:v1
打开本地浏览器,输入kibana的默认url:http://localhost:5601,创建index后就可以看到echo:v1容器的打印日志
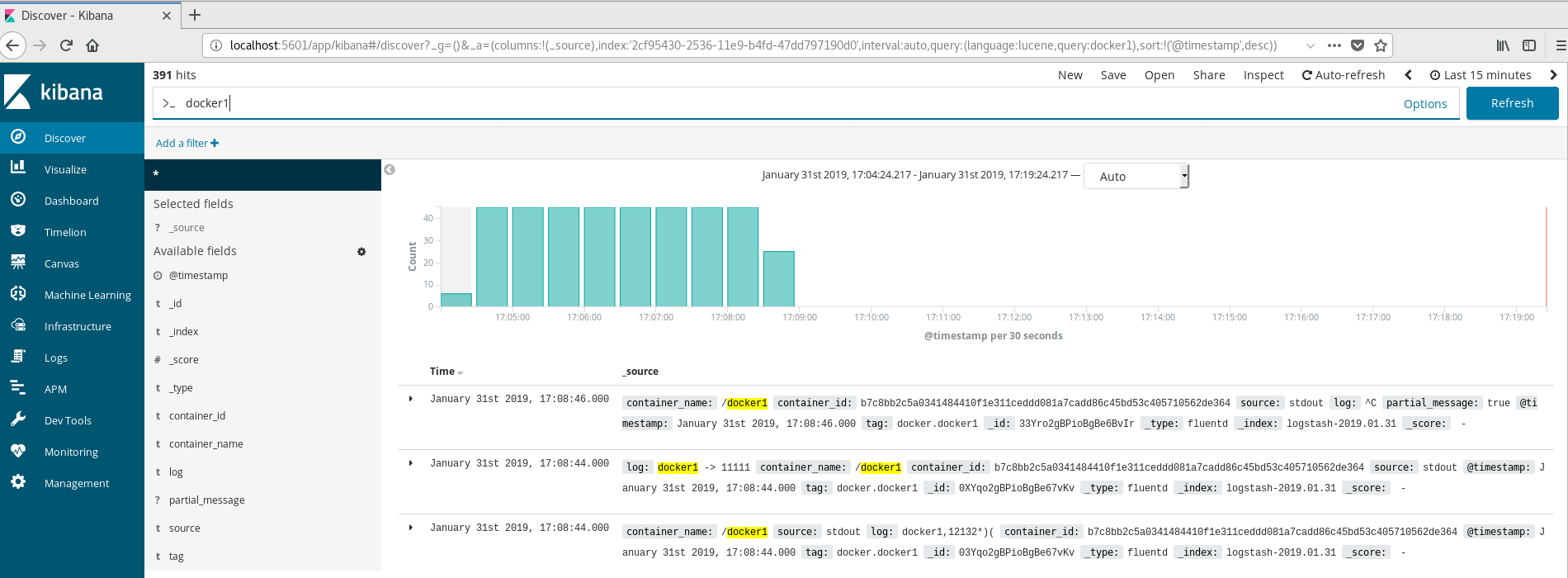
在使用到kubernetes时,fluentd一般以DaemonSet方式部署到每个node节点,采集node节点的log日志。也可以以sidecar的方式采集同pod的容器服务的日志。更多参见Logging Architecture
TIPS:
- fluentd给elasticsearch推送数据是以chunk为单位的,如果chunk过大可能导致elasticsearch因为payload过大而无法接收,需要设置chunk_limit_size大小,参考Fluentd-ElasticSearch配置
- 生产中fluentd直接发送日志到elasticsearch,可能会因为es没能及时读取日志而导致fluentd中缓存的日志爆满,建议在fluentd和es之间使用kafka进行日志缓存
参考:
https://stackoverflow.com/questions/44002643/how-to-use-the-official-docker-elasticsearch-container
docker 日志方案的更多相关文章
- Docker日志收集最佳实践
传统日志处理 说到日志,我们以前处理日志的方式如下: · 日志写到本机磁盘上 · 通常仅用于排查线上问题,很少用于数据分析 ·需要时登录到机器上,用grep.awk等工具分析 那么,这种方式有什么缺点 ...
- docker 日志管理
高效的监控和日志管理对保持生产系统持续稳定地运行以及排查问题至关重要. 在微服务架构中,由于容器的数量众多以及快速变化的特性使得记录日志和监控变得越来越重要.考虑到容器短暂和不固定的生命周期,当我们需 ...
- Kubernetes 集群日志 和 EFK 架构日志方案
目录 第一部分:Kubernetes 日志 Kubernetes Logging 是如何工作的 Kubernetes Pod 日志存储位置 Kubelet Logs Kubernetes 容器日志格式 ...
- Docker 日志管理最佳实践
开源Linux 回复"读书",挑选书籍资料~ Docker-CE Server Version: 18.09.6 Storage Driver: overlay2 Kernel V ...
- Java中几种日志方案
.本文记录Java中几种常用的日志解决方案 0x01 Log4j .这应该是一个比较老牌的日志方案了,配置也比较简单,步骤如下 1)添加对应依赖,比如 Gradle 中 dependencies { ...
- Kubernetes审计日志方案
前言 当前Kubernetes(K8S)已经成为事实上的容器编排标准,大家关注的重点也不再是最新发布的功能.稳定性提升等,正如Kubernetes项目创始人和维护者谈到,Kubernetes已经不再是 ...
- Docker 日志都在哪里?怎么收集?
https://www.cnblogs.com/YatHo/p/7866029.html 日志分两类,一类是 Docker 引擎日志:另一类是 容器日志. Docker 引擎日志 Docker 引擎日 ...
- docker 日志分析
日志分两类,一类是 Docker 引擎日志:另一类是 容器日志. Docker 引擎日志 Docker 引擎日志 一般是交给了 Upstart(Ubuntu 14.04) 或者 systemd (Ce ...
- docker日志引擎说明
docker原生支持众多的日志引擎,适用于各种不同的应用场景,本篇文档对其作一个简单的说明. Docker日志引擎说明 docker支持的日志引擎如下: none:关闭docker的回显日志, doc ...
随机推荐
- [Algorithm]Algorithm章1 排序算法
1.冒泡排序-相邻交换 (1)算法描述 冒泡排序是一种简单的排序算法.它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来.走访数列的工作是重复地进行直到没有再需要交换,也 ...
- [uboot] (第四章)uboot流程——uboot编译流程
http://blog.csdn.net/ooonebook/article/details/53000893 以下例子都以project X项目tiny210(s5pv210平台,armv7架构)为 ...
- selenium实现淘宝的商品爬取
一.问题 本次利用selenium自动化测试,完成对淘宝的爬取,这样可以避免一些反爬的措施,也是一种爬虫常用的手段.本次实战的难点: 1.如何利用selenium绕过淘宝的登录界面 2.获取淘宝的页面 ...
- SAS 输入与输出格式
SAS 输入与输出格式 一.认识SAS中的数据格式 SAS 中的格式有: 数字型 字符型 日期型 1.其中数字型的格式有一下集中表示方式: 整型数值:321 浮点数值:321.123 带逗号的数值:1 ...
- 2019.02.19 bzoj2655: calc(生成函数+拉格朗日插值)
传送门 题意简述:问有多少数列满足如下条件: 所有数在[1,A][1,A][1,A]之间. 没有相同的数 数列长度为nnn 一个数列的贡献是所有数之积,问所有满足条件的数列的贡献之和. A≤1e9,n ...
- 源码管理工具Git-windows平台使用Gitblit搭建Git服务器
原文地址:https://blog.csdn.net/smellmine/article/details/52139299 搭建Git服务器,请参照上面链接. 注意: 第十二步:以Windows Se ...
- php流程控制
return 例子一: <?php function add($a,$b){ echo "echo"; return $a+$b; //return 一般用于function ...
- $q的基本用法
angularjs的http是异步的没有同步,一般都会遇到一个场景,会把异步请求的参数作为条件执行下一个函数,之前一直在看其他人的博客理论太多看了很久才看懂 http({ method:'post', ...
- Docker环境安装与配置
Docker 简介 Docker使用Go语言编写的 安装Docker推荐LInux内核在3.10上 在2.6内核下运行较卡(CentOS 7.X以上内核是3.10) Docker 安装 安装yum-u ...
- git cmd 命令在已有的仓库重新添加新的文件夹
正确步骤: 1. git init //初始化仓库 git add .(文件name) //添加文件到本地仓库 git commit -m “first commit” //添加文件描述信息 git ...