MYSQL与TiDB的执行计划
前言
这里采用了tpc-h一个数据库的数据量来进行查询计划的对比。并借助tpc-h中的22条查询语句进行执行计划分析。
mysql采用的是标准安装,TiDB采用的是单机测试版,这里的性能结果不能说明其性能差异
本文章主要目的是对比Mysql与TiDB在执行sql查询时的差异。
mysql版本5.7 TiDB版本v2.0.0-rc.4
准备阶段
数据导入TiDB后是缺少统计信息的:
SHOW STATS_META
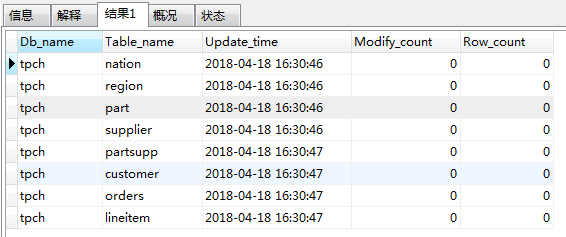
可以手工进行统计信息的刷新
ANALYZE TABLE nation,region,part,supplier,partsupp,customer,orders,lineitem
刷新后再次查看SHOW STATS_META
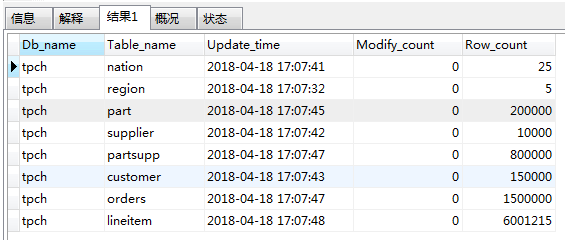
首先选择Q17做为例子,进行查询
select
sum(l_extendedprice) / 7.0 as avg_yearly
from
lineitem,
part
where
p_partkey = l_partkey
and p_brand = 'Brand#23' # 指定品牌。 BRAND=’Brand#MN’ ,M和N是两个字母,代表两个数值,相互独立,取值在1到5之间
and p_container = 'MED BOX' # 指定包装类型。在TPC-H标准指定的范围内随机选择
and l_quantity < (
select
0.2 * avg(l_quantity)
from
lineitem
where
l_partkey = p_partkey
);
表结构
CREATE TABLE IF NOT EXISTS part ( P_PARTKEY INTEGER NOT NULL,
P_NAME VARCHAR(55) NOT NULL,
P_MFGR CHAR(25) NOT NULL,
P_BRAND CHAR(10) NOT NULL,
P_TYPE VARCHAR(25) NOT NULL,
P_SIZE INTEGER NOT NULL,
P_CONTAINER CHAR(10) NOT NULL,
P_RETAILPRICE DECIMAL(15,2) NOT NULL,
P_COMMENT VARCHAR(23) NOT NULL,
PRIMARY KEY (P_PARTKEY)); CREATE TABLE IF NOT EXISTS lineitem ( L_ORDERKEY INTEGER NOT NULL,
L_PARTKEY INTEGER NOT NULL,
L_SUPPKEY INTEGER NOT NULL,
L_LINENUMBER INTEGER NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR(1) NOT NULL,
L_LINESTATUS CHAR(1) NOT NULL,
L_SHIPDATE DATE NOT NULL,
L_COMMITDATE DATE NOT NULL,
L_RECEIPTDATE DATE NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL,
PRIMARY KEY (L_ORDERKEY,L_LINENUMBER),
CONSTRAINT FOREIGN KEY LINEITEM_FK1 (L_ORDERKEY) references orders(O_ORDERKEY),
CONSTRAINT FOREIGN KEY LINEITEM_FK2 (L_PARTKEY,L_SUPPKEY) references partsupp(PS_PARTKEY, PS_SUPPKEY));
part表是20万 ,而lineitem是600万,mysql在建立约束时,会自动创建一个索引LINEITEM_FK2(L_PARTKEY, L_SUPPKEY),而TiDB则不会
mysql的查询时间大概是1秒左右,TiDB的查询时间大概是30秒。
mysql的执行计划:

mysql首先对part表进行了查询,由于经过where的处理20万数据已经被过滤到几百条了。再与lineitem关联,最后再处理子查询。
查询过程中借用索引,所以大大加快了查询速度。
TiDB的执行计划
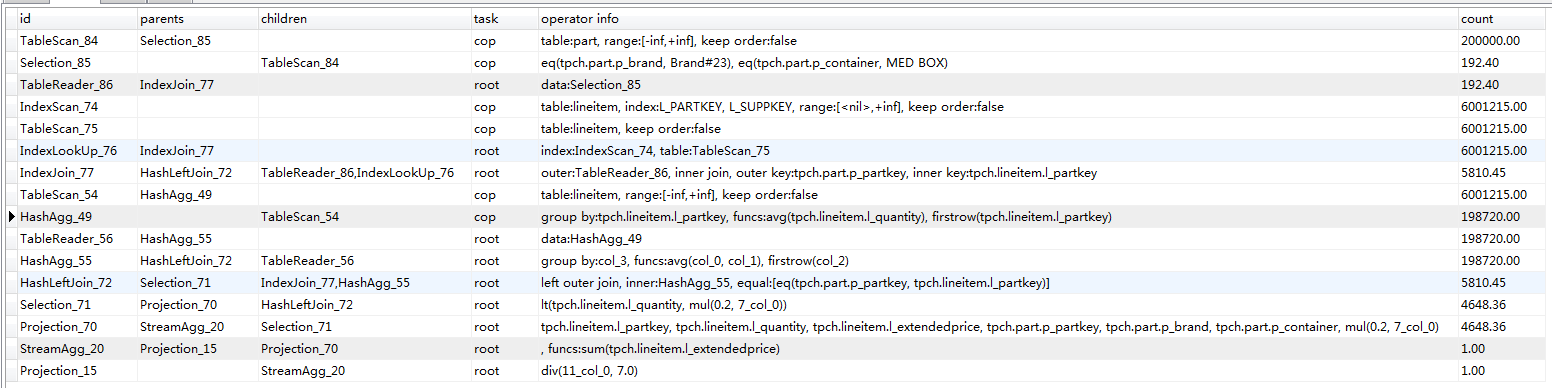
TiDB的执行计划比较复杂,需要转换为查询树后,才能看到比较清楚
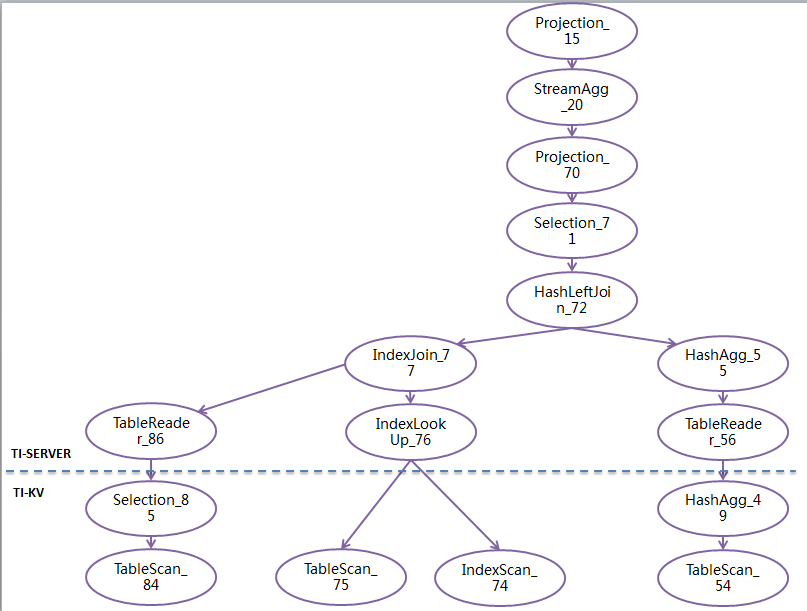
从下而上的执行,上层收到下层的数据处理后,再向上递交
84、85、86读取part表
74、75、76读取lineitem表
77 将两者进行join
54、49、56、55汇总lineitme表,并进行分组的平均值的计算
在72进行55和77进行融合和再过滤
71、70、20、15过滤汇总和计算,得到最终结果。
但由于part表是小表,对linetiem的两次扫描和计算都很浪费。所以性能不佳。
Mysql与TiDB的执行计划规则与解读
由于大家对Mysql和TiDB的执行计划规则不了解,所以解读会比较困难,但如果掌握了如何解读执行计划,能够理解数据库的执行方式以及进行对应的优化
下面学习一下,执行计划规则与解读,我们将分别学习两种数据库的执行计划,这样也有利于进行对比
Mysql执行计划
在SQL语句前添加EXPLAIN可以查询到对应SQL的执行计划,例如:EXPLAIN select * from part
执行计划共有12列
id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra
| 类别 | 可选值 | 解释说明 |
| id |
标识执行的顺序,按数值大小进行执行,如果数值一样大,按排列顺序执行 id列为null的就表示这是一个结果集,不需要对其进行执行 |
|
| select_type | 查询类型 | |
| SIMPLE | 简单查询(不使用UNION或子查询) | |
| PRIMARY | 最外层的SELECT语句 | |
| UNION | 在UNION结构中的第二个及以上的SELECT语句 | |
| DEPENDENT UNION | 在UNION结构中的第二个及以上的SELECT语句,依赖外层查询 | |
| UNION RESULT | UNION的结果 | |
| SUBQUERY | 子查询中的第一个SELECT语句 | |
| DEPENDENT SUBQUERY | 子查询中的第一个SELECT语句,依赖于外层查询 | |
| DERIVED | 子查询中FROM后面的语句 | |
| MATERIALIZED | 物化视图子查询 | |
| UNCACHEABLE SUBQUERY | 查询结果没有被缓存且需要重新外层查询计算每行数据的子查询 | |
| UNCACHEABLE UNION | 结构中第二个及之后的SELECT语句且没有生成查询缓存 | |
| table | 被查询的表名 | |
| partitions | 表的分区,若不是分区表该字段为null,如果是分区表则显示用到的分区名称 | |
| type |
表连接的类型 性能按排列顺序从好至坏,除了all之外,其他的type都可以使用到索引 |
|
| system |
表中只有一行数据或者是空表,且只能用于myisam和memory表。 如果是Innodb引擎表,type列在这个情况通常都是all或者index |
|
| const | 使用唯一索引或者主键,返回记录一定是1行记录的等值where条件时,通常type是const。其他数据库也叫做唯一索引扫描 | |
| eq_ref |
出现在要连接过个表的查询计划中,驱动表只返回一行数据,且这行数据是第二个表的主键或者唯一索引,且必须为not null, 唯一索引和主键是多列时,只有所有的列都用作比较时才会出现eq_ref |
|
| ref |
每次和之前的表做连接时,读取所有符合条件的索引值。 如果连接使用索引的最左边前缀字段,或者索引不是主键或UNIQUE索引,会用到这种连接方式, 也就是说如果连接不能基于每个符合连接条件的索引值选择出单独的一行,则会使用这种连接方式。 |
|
| fulltext |
使用FULLTEXT索引来建立连接 全文索引的优先级很高,若全文索引和普通索引同时存在时,mysql不管代价,优先选择使用全文索引 |
|
| ref_or_null | 连接类型类似ref,除此之外,MySQL会额外扫描出包含NULL值的行。这种连接方式通常用于有子查询的情形下。 | |
| unique_subquery |
这种连接方式在某种情况下会代替eq_ref,如value IN (SELECT primary_key FROM single_table WHERE some_expr), 这种方式使用索引查询功能代替子查询,以获得更好的执行效率。 |
|
| index_subquery |
这种连接方式类似unique_subquery。它会代替IN子查询,但是它适用于非unique索引的子查询, 用于in形式子查询使用到了辅助索引或者in常数列表,子查询可能返回重复值,可以使用索引将子查询去重 如value IN (SELECT key_column FROM single_table WHERE some_expr) |
|
| range |
使用索引扫描出指定范围的行。key字段指示使用的索引。key_len指示索引的最大长度。ref字段会显示NULL 常见于使用>,<,is null,between ,in ,like等运算符的查询中。 |
|
| index_merge |
使用索引合并的连接方式。在这种情况下,key字段会包含使用的索引,key_len包含使用索引的最长索引部分。 表示查询使用了两个以上的索引,最后取交集或者并集,常见and ,or的条件使用了不同的索引, 官方排序这个在ref_or_null之后,但是实际上由于要读取数个索引,性能可能大部分时间都不如range |
|
| index |
这种索引连接类型和ALL相同,除了索引树被扫描到。这会出现在两种情况下:一、如果该索引是一个覆盖索引查询,且只扫描出索引树。 在这种情况下,Extra字段会显示Using index。二、通过索引顺序来执行全表扫描。 |
|
| all | 全表扫描数据文件,然后再在server层进行过滤返回符合要求的记录。 | |
| possible_keys | 可供选择的索引。可以有多个用逗号分隔 | |
| key |
实际选择的索引 select_type为index_merge时,这里可能出现两个以上的索引,其他的select_type这里只会出现一个 |
|
| key_len |
用于处理查询的索引长度,如果是单列索引,那就整个索引长度算进去, 如果是多列索引,那么查询不一定都能使用到所有的列,具体使用到了多少个列的索引,这里就会计算进去,没有使用到的列,这里不会计算进去。 留意下这个列的值,算一下你的多列索引总长度就知道有没有使用到所有的列了。 要注意,mysql的ICP特性使用到的索引不会计入其中。另外,key_len只计算where条件用到的索引长度,而排序和分组就算用到了索引,也不会计算到key_len中。 |
|
| ref |
如果是使用的常数等值查询,这里会显示const,如果是连接查询,被驱动表的执行计划这里会显示驱动表的关联字段 如果是条件使用了表达式或者函数,或者条件列发生了内部隐式转换,这里可能显示为func 例如:tpch.partsupp.PS_PARTKEY,tpch.partsupp.PS_SUPPKEY表示使用了partsupp表的两个字段与当前表的索引进行比较 |
|
| rows | 执行计划中估算的扫描行数,不是精确值 | |
| filtered | 表示存储引擎返回的数据在server层过滤后,剩下多少满足查询的记录数量的比例,注意是百分比,不是具体记录数。 | |
| extra | 查询的描述信息,种类非常多。这里只列一些常用的。一个查询中可以有多个种类,使用逗号进行分隔 | |
| using temporary | 表示使用了临时表存储中间结果。临时表可以是内存临时表和磁盘临时表,执行计划中看不出来,需要查看status变量,used_tmp_table,used_tmp_disk_table才能看出来。 | |
| using where |
表示存储引擎返回的记录并不是所有的都满足查询条件,需要在server层进行过滤。查询条件中分为限制条件和检查条件, 5.6之前,存储引擎只能根据限制条件扫描数据并返回,然后server层根据检查条件进行过滤再返回真正符合查询的数据。 5.6.x之后支持ICP特性,可以把检查条件也下推到存储引擎层,不符合检查条件和限制条件的数据,直接不读取,这样就大大减少了存储引擎扫描的记录数量。extra列显示using index condition |
|
| distinct | 在select部分使用了distinc关键字 | |
| no tables used | 不带from字句的查询或者From dual查询 | |
| using index | 查询时不需要全表查询,直接通过索引就可以获取查询的数据。 | |
| using intersect | 表示使用and的各个索引的条件时,该信息表示是从处理结果获取交集 | |
| using union | 表示使用or连接各个使用索引的条件时,该信息表示从处理结果获取并集 | |
| using filesort | 排序时无法使用到索引时,就会出现这个。常见于order by和group by语句中 | |
| firstmatch(tb_name) | 5.6.x开始引入的优化子查询的新特性之一,常见于where字句含有in()类型的子查询。如果内表的数据量比较大,就可能出现这个 | |
| loosescan(m..n) | 5.6.x之后引入的优化子查询的新特性之一,在in()类型的子查询中,子查询返回的可能有重复记录时,就可能出现这个 |
TiDB执行计划
TiDB的数据存储与ti-kv,而数据处理在ti-server分属与不同应用。ti-server需要数据时,需要先调用ti-kv进行扫描,然后再从ti-kv拿到数据。
在ti-server层面需要执行的过滤/汇总/分组,送到ti-kv扫描时去运行就可以减少传输的数据量,加快处理速度。这个操作称为“下推”
同Mysql一样,在SQL语句前添加EXPLAIN可以查询到对应SQL的执行计划,例如:EXPLAIN select * from part
执行计划共有6列
id | parents | children | task | operator info | count
| 类别 | 可选值 | 解释说明 |
| id |
operator 的 id,在整个执行计划中唯一的标识一个 operator。 id由两部分组成:操作类型+序号。 操作类型有很多种,也代表提供了不同的处理能力,如TableReader 和 TableScan等等 序号是创立执行计划时生成的,大小无作用,只是为了避免重复。 执行计划从上至下的方式运行,任务内可能会有并行,例如到多个ti-kv上提取数据 任务间也会有并行,具体看任务实现,union算子就会驱动所有的child同时执行。 而对于无关联的任务,可能就不会并行了。(未得到官方确认) |
|
| parents |
这个 operator 的 parent。目前的执行计划可以看做是一个 operator 构成的树状结构, 数据从 child 流向 parent,每个 operator 的 parent 有且仅有一个 |
|
| children | 这个 operator 的 children,也即是这个 operator 的数据来源 | |
| task |
当前的执行计划在 task 级别的拓扑关系是一个 root task 后面可以跟许多 cop task, root task 使用 cop task 的输出结果作为输入。 cop task 中执行的也即是 tidb 下推到 tikv 上的任务,每个 cop task 分散在 tikv 集群中,由多个进程共同执行 |
|
| root | 在tidb-server 上执行的任务 | |
| cop | 在tikv上执行的任务 | |
| count | 预计当前 operator 将会输出的数据条数,基于统计信息以及 operator 的执行逻辑估算而来 | |
| operator info | 操作类型中会输出的明细信息,需要结合操作类型一起看 |
下面这个表格专门对operator相关内容进行说明
| 类别 | 操作类型 | info信息样例值 | 解释说明 |
| 数据读 | |||
| TableScan | 在ti-kv上进行数据扫描 | ||
| table:part | 操作的表名,这里指的是操作part表 | ||
| range:[-inf,+inf] | range的范围从-inf开始到+inf结束。如果没有开始或者结束使用<nil>,例如range:[<nil>,+inf] | ||
| keep order:false | 是否进行排序:true排序,false不排序 | ||
| TableReader | ti-server从ti-kv读取数据的操作 | ||
| data:Selection_85 | 这里是指Ti-Server拿到ti-kv扫描结果Selection_85的数据 | ||
| 索引读 | |||
| IndexReader |
直接从索引中读取索引列,适用于 SQL 语句中仅引用了该索引相关的列或主键; |
||
| IndexLookUp |
index:IndexScan_74, table:TableScan_75 |
表示从索引中过滤部分数据,仅返回这些数据的 Handle ID,通过 Handle ID 再次查找表数据, 这种方式需要两次从 TiKV 获取数据。Index 的读取方式是由优化器自动选择的。 |
|
| IndexScan | 官网没有说明 | ||
| table:partsupp, | 操作的表 | ||
| index:PS_PARTKEY, PS_SUPPKEY | 索引列 | ||
| range:[<nil>,+inf] | 范围 | ||
| 过滤 | keep order:false | 排序 | |
| Selection |
表示 SQL 语句中的选择条件,通常出现在 WHERE/HAVING/ON 子句中。 如果task为cop,则表示比较选择条件进行了下推。 |
||
| eq(tpch.part.p_brand, Brand#23) |
内容一般是选择的条件 包括:eg/le/lt/ge |
||
| 映射 | |||
| Projection | 对应 SQL 语句中的 SELECT 列表,功能是将每一条输入数据映射成新的输出数据。 | ||
| tpch.part.p_container, mul(0.2, 7_col_0) | 一般是映射的字段列表 | ||
| offset:0 | |||
| count:10 | |||
|
聚集 Aggregation |
对应 SQL 语句中的 Group By 语句或者没有 Group By 语句但是存在聚合函数,例如 count 或 sum 函数等。 | ||
| HashAgg |
是基于哈希的聚合算法,如果 Hash Aggregation 紧邻 Table 或者 Index 的读取算子, 则聚合算子会在 TiKV 端进行预聚合,以提高计算的并行度和减少网络开销。 |
||
| group by:tpch.lineitem.l_partkey | 分组 | ||
| funcs:avg(tpch.lineitem.l_quantity) | 函数 | ||
| StreamAgg | 官方没有说明 | ||
| funcs:sum(tpch.lineitem.l_extendedprice) | 函数 | ||
|
联合 join |
Hash Join 的原理是将参与连接的小表预先装载到内存中,读取大表的所有数据进行连接。 部分join方式还没有遇到过,暂时没有添加进来 |
||
| IndexJoin | 官方没有说明 | ||
| inner join | |||
|
index:IndexScan_74 inner key:tpch.lineitem.l_partkey |
|||
|
outer:TableReader_86 outer key:tpch.part.p_partkey |
|||
| HashLeftJoin | 官方没有说明 | ||
| inner join | |||
| left outer join | |||
| inner:HashAgg_55 | |||
| equal:[eq(tpch.part.p_partkey, tpch.lineitem.l_partkey)] | |||
| Apply |
用来描述子查询的一种算子,行为类似于 Nested Loop,即每次从外表中取一条数据, 带入到内表的关联列中,并执行,最后根据 Apply 内联的 Join 算法进行连接计算。 Apply 一般会被查询优化器自动转换为 Join 操作。用户在编写 SQL 的过程中应尽量避免 Apply 算子的出现。 |
||
| 暂时没有遇到过 | |||
| 其它 | |||
| Sort | tpch.lineitem.l_returnflag:asc | 排序处理,一般是字段名:asc(desc) |
执行器的接口在executor.go文件中,实现一般是*Exec命名的
type executor interface {
SetSrcExec(executor)
GetSrcExec() executor
ResetCounts()
Counts() []int64
Next(ctx context.Context) ([][]byte, error)
// Cursor returns the key gonna to be scanned by the Next() function.
Cursor() (key []byte, desc bool)
}
indexScan的实现
type indexScanExec struct {
*tipb.IndexScan
colsLen int
kvRanges []kv.KeyRange
startTS uint64
isolationLevel kvrpcpb.IsolationLevel
mvccStore MVCCStore
cursor int
seekKey []byte
pkStatus int
start int
counts []int64
src executor
}
练习
联系解读一下,以下sql的执行计划
select
sum(l_extendedprice * l_discount) as revenue # 潜在的收入增加量
from
lineitem
where
l_shipdate >= '1994-01-01' # DATE是从[1993, 1997]中随机选择的一年的1月1日
and l_shipdate < date_add('1994-01-01', interval '' year) # 一年内
and l_discount between 0.06 - 0.01 and 0.06 + 0.01
and l_quantity < 24; # QUANTITY在区间[24, 25]中随机选择

select
100.00 * sum(case
when p_type like 'PROMO%' # 促销零件
then l_extendedprice * (1 - l_discount) # 某一特定时间的收入
else 0
end) / sum(l_extendedprice * (1 - l_discount)) as promo_revenue
from
lineitem,
part
where
l_partkey = p_partkey
and l_shipdate >= '1995-09-01' # DATE是从1993年到1997年中任一年的任一月的一号
and l_shipdate < date_add('1995-09-01', interval '' month);

MYSQL与TiDB的执行计划的更多相关文章
- MySQL学习系列2--MySQL执行计划分析EXPLAIN
原文:MySQL学习系列2--MySQL执行计划分析EXPLAIN 1.Explain语法 EXPLAIN SELECT …… 变体: EXPLAIN EXTENDED SELECT …… 将执行 ...
- python/MySQL(索引、执行计划、BDA、分页)
---恢复内容开始--- python/MySQL(索引.执行计划.BDA.分页) MySQL索引: 所谓索引的就是具有(约束和加速查找的一种方式) 创建索引的缺点是对数据进行(修改.更新.删除) ...
- MySQL统计信息以及执行计划预估方式初探
数据库中的统计信息在不同(精确)程度上描述了表中数据的分布情况,执行计划通过统计信息获取符合查询条件的数据大小(行数),来指导执行计划的生成.在以Oracle和SQLServer为代表的商业数据库,和 ...
- MySQL 索引管理与执行计划
1.1 索引的介绍 索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息.如果想按特定职员的姓来查找他或她,则与在表中搜索所有的行相比,索引有助于更快地获取信息. ...
- 【mysql】mysql 调优之 ——执行计划 explain
1.what is explain(explain 是个什么东东) explain(解释),在 Mysql 中 作为一个关键词,用来解释 Mysql 是如何执行语句,可以连接 select .dele ...
- MySQL — 优化之explain执行计划详解(转)
EXPLAIN简介 EXPLAIN 命令是查看查询优化器如何决定执行查询的主要方法,使用EXPLAIN,只需要在查询中的SELECT关键字之前增加EXPLAIN这个词即可,MYSQL会在查询上设置一个 ...
- MySQL(四)执行计划
转载自:Oo若离oO,原文链接 在MySQL中使用explain查询SQL的执行计划 目录 一.什么是执行计划 二.如何分析执行计划 一.什么是执行计划 要对执行计划有个比较好的理解,需要先对MySQ ...
- mysql explain extended 查看 执行计划
本文以转移至本人的个人博客,请多多关注! 本文以转移至本人的个人博客,请多多关注! 本文以转移至本人的个人博客,请多多关注! 本文以转移至本人的个人博客,请多多关注! 1. explain 可以查看 ...
- mysql的索引和执行计划
一.mysql的索引 索引是帮助mysql高效获取数据的数据结构.本质:索引是数据结构 1:索引分类 普通索引:一个索引只包含单个列,一个表可以有多个单列索引. 唯一索引:索引列的值必须唯一 ,但允许 ...
随机推荐
- SpringCloud使用Feign实现服务间通信
SpringCloud的服务间通信主要有两种办法,一种是使用Spring自带的RestTemplate,另一种是使用Feign,这里主要介绍后者的通信方式. 整个实例一共用到了四个项目,一个Eurek ...
- vuejs的双向绑定实现原理
Vue在初始化的时候,会有两个大步骤: 1.Compile 从root的节点开始编译,根据正则表达式,把特殊的v-*类的标签,全部转换成对应的内存中的object 2.Observe 全部的data, ...
- 最简单的操作 jetty IDEA 【debug】热加载
[博客园cnblogs笔者m-yb原创,转载请加本文博客链接,笔者github: https://github.com/mayangbo666,公众号aandb7,QQ群927113708] http ...
- CSS 隐藏ul
老师要求只能用css做出覆盖ul时显示ul,之前一直在试 [ display:none display:block ]后来发现一直是闪烁的状态 不能实现消失 然后就试用了透明度,一下就可以了 ...
- python day27--网络编程
一‘.网络基础 1.什么是IP IP地址是指互联网协议地址(英语:Internet Protocol Address,又译为网际协议地址),是IP Address的缩写.IP地址是IP协议提供的一种统 ...
- 关于idea的debug
idea的debug真的是超级好用哎.分享几个今天学会的新方式: 1.右键会发现此选项 ,点击出现 在输入框中输入,可以通过某些公式单独计算. 2.点击属性值,右键点击set values 会出现一个 ...
- java.lang.ClassNotFoundException:oracle.jdbc.OracleDriver
在使用JDBC时经常碰到java.lang.ClassNotFoundException:oracle.jdbc.OracleDriver问题 这是jvm找不到驱动类文件,可能是以下原因: 没有导入驱 ...
- File类相关操作
1.File类常见方法: 创建: boolean createNewFile():在指定位置创建文件 如果该文件已经存在,则不创建,返回false,和输出流不一样,输出流对象一建立就创立文件,而且文件 ...
- ANSYS耦合
目录 定义 如何生成耦合自由度集 1.在给定节点处生成并修改耦合自由度集 2.耦合重合节点. 3.迫使节点有相同的表现方式 生成更多的耦合集 1. CPLGEN 2.CPSGEN 使用耦合注意事项 约 ...
- Processing 编程学习指南 (丹尼尔·希夫曼 著)
https://processing.org/reference/ 第1章 像素 (已看) 第2章 Processing (已看) 第3章 交互 (已看) 第4章 变量 (已看) 第5章 条件语句 ( ...