bs4爬虫入门
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 16 13:35:33 2018 @author: zhen
"""
import urllib
import urllib.request
from bs4 import BeautifulSoup # 设置目标rootUrl,使用urllib.request.Request创建请求
rootUrl = "https://www.cnblogs.com/"
request = urllib.request.Request(rootUrl) header = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36"
# 使用add_header设置请求头,将代码伪装成浏览器
request.add_header("User-Agent", header) # 使用urllib.request.urlopen打开页面,使用read方法保存html代码
htmlUrl = urllib.request.urlopen(request).read() # 使用BeautifulSoup创建html代码的BeautifulSoup实例,存为beautifulSoup
beautifulSoup = BeautifulSoup(htmlUrl) # 获取尾页(对照前一小节获取尾页的内容看你就明白了)
total_page = int(beautifulSoup.find("div",class_= "pager").findAll("a")[-2].get_text()) list_item = beautifulSoup.findAll("a",class_="titlelnk")
for i in list_item: # 遍历所有的内容
href = i["href"] # 获取对应的href
req = urllib.request.Request(href)
req.add_header("User-Agent", header)
html = urllib.request.urlopen(req).read()
soup = BeautifulSoup(html)
# 获取标题
titleContent = soup.find("a", id="cb_post_title_url")
if titleContent is not None: # 判读是否为空
title = titleContent.get_text()
# 获取内容
content = soup.find("div").get_text().strip()
print(title, "\n=====================================\n", content[1:100])
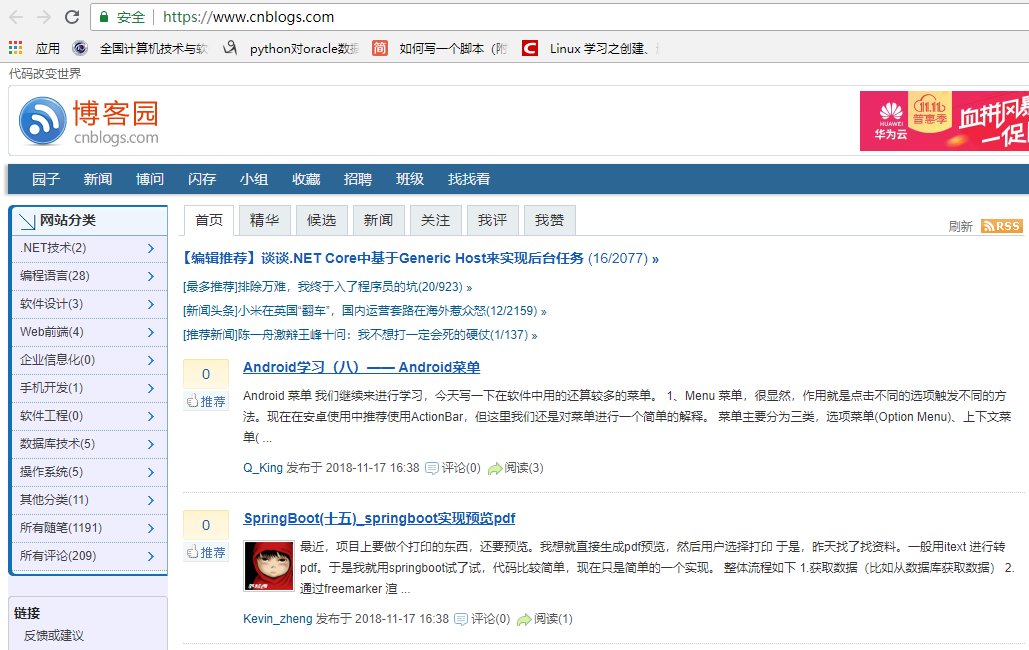
爬虫结果:


bs4爬虫入门的更多相关文章
- 爬虫入门之爬取策略 XPath与bs4实现(五)
爬虫入门之爬取策略 XPath与bs4实现(五) 在爬虫系统中,待抓取URL队列是很重要的一部分.待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪 ...
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- 【网络爬虫入门05】分布式文件存储数据库MongoDB的基本操作与爬虫应用
[网络爬虫入门05]分布式文件存储数据库MongoDB的基本操作与爬虫应用 广东职业技术学院 欧浩源 1.引言 网络爬虫往往需要将大量的数据存储到数据库中,常用的有MySQL.MongoDB和Red ...
- Python 爬虫入门(二)——爬取妹子图
Python 爬虫入门 听说你写代码没动力?本文就给你动力,爬取妹子图.如果这也没动力那就没救了. GitHub 地址: https://github.com/injetlee/Python/blob ...
- Python 爬虫入门之爬取妹子图
Python 爬虫入门之爬取妹子图 来源:李英杰 链接: https://segmentfault.com/a/1190000015798452 听说你写代码没动力?本文就给你动力,爬取妹子图.如果 ...
- 【网络爬虫入门01】应用Requests和BeautifulSoup联手打造的第一条网络爬虫
[网络爬虫入门01]应用Requests和BeautifulSoup联手打造的第一条网络爬虫 广东职业技术学院 欧浩源 2017-10-14 1.引言 在数据量爆发式增长的大数据时代,网络与用户的沟 ...
- python网络爬虫入门(二)
刚去看了一下,18年2月份写了第一篇关于爬虫的文章(仅仅介绍了使用requests库去获取HTML代码),一年多之后看来很稚嫩也没有多少参考的意义,但没想着要去修改它,留着也是一个回忆吧.至少证明着我 ...
随机推荐
- HttpClient和HttpURLConnection的使用和区别(下)
转自来自点击打开链接 接着上一篇,我们继续来分析HttpURLConnection的使用,以及两者的共同点和区别. 目录 用法 HttpURLConnection 区别 引用资料 用法 HttpURL ...
- cracking the coding interview系列C#实现
原版内容转自:CTCI面试系列——谷歌面试官经典作品 | 快课网 此系列为C#实现版本 谷歌面试官经典作品(CTCI)目录 1.1 判断一个字符串中的字符是否唯一 1.2 字符串翻转 1.3 去除 ...
- spring boot 集成 thymeleaf
例如meta标签,低版本标签必须要闭合,高版本不用这么严格. pom文件引入高版本jar包如下,propertis里添加:
- 【Collection、泛型】
[Collection.泛型] 主要内容 Collection集合 迭代器 增强for 泛型 第一章 Collection集合 1.1 集合概述 集合:集合是java中提供的一种容器,可以用来存储多个 ...
- iOS app 支持HTTPS iOS开发者相关
2016年12月21日更新开发者中心链接https://developer.apple.com/news/?id=12212016b该链接是苹果昨天刚在官网给的正式回复 如下: App Transpo ...
- java开发,年薪15W的你和年薪50W的他的差距
在这个IT系统动辄就是上亿流量的时代,Java作为大数据时代应用最广泛的语言,诞生了一批又一批的新技术,包括HBase.Hadoop.MQ.Netty.SpringCloud等等 . 一些独角 ...
- 使用 Portainer UI 管理 Docker 主机
Docker 使用命令行的方式来管理有时候并没有那么直观,可以使用 Portainer 的 UI 来管理 Docker 主机和 Docker Swarm 集群. 安装 Portainer 环境:cen ...
- ABP默认生成数据库结构
数据库设计文档 -- MyFirstABP 数据库设计文档 数据库名:MyFirstABP 序号 表名 说明 1 AbpFeatures 2 AbpEditions 3 AbpLanguage ...
- Oracle添加定时任务
1.创建存储过程 注:执行语句后,如果需要请添加commit 2.添加定时job,执行存储过程 declare job_delete number; begin dbms_job.submit( jo ...
- 深入理解JavaScript的事件循环(Event Loop)
一.什么是事件循环 JS的代码执行是基于一种事件循环的机制,之所以称作事件循环,MDN给出的解释为 因为它经常被用于类似如下的方式来实现 while (queue.waitForMessage()) ...