azkaban 执行hive语句
#hivef.job
type=command
command=hive -f test.sql
#test.sql
use default;
drop table aztest;
create table aztest(id int,name string) row format delimited fields terminated by ",";
load data inpath '/home/lxl/b.txt' into table aztest;
create table azres as select * from aztest;

.png)


.png)

.png)
.png)

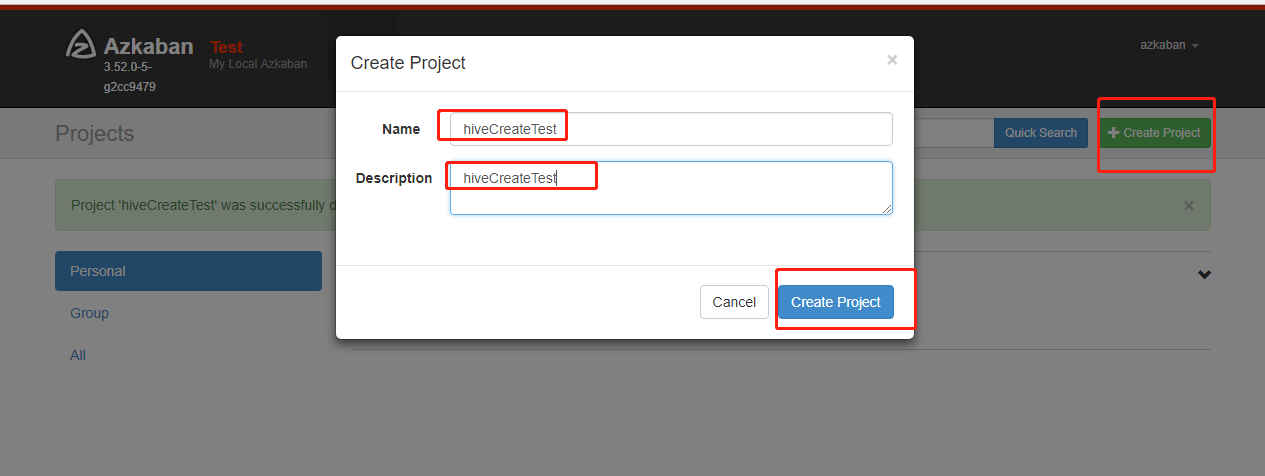
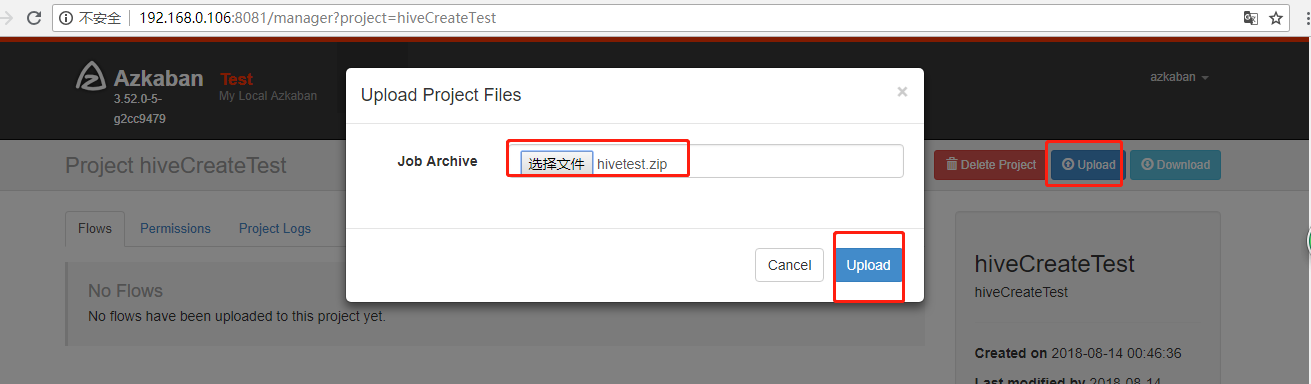
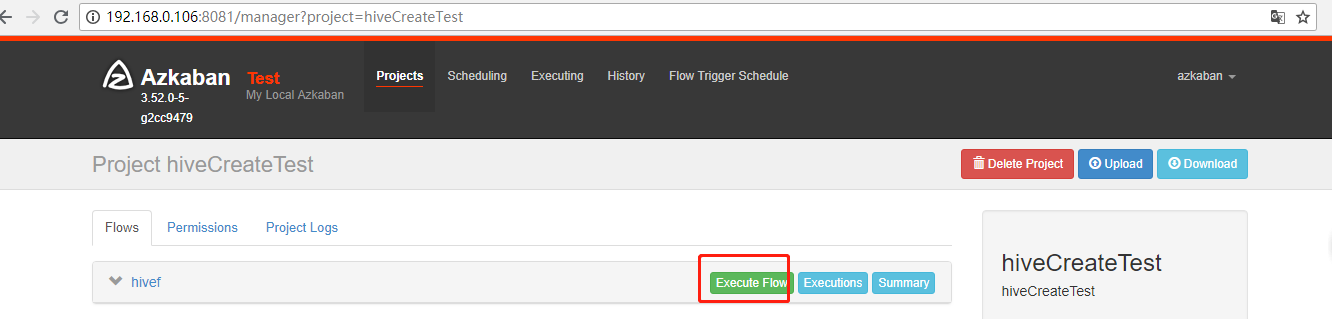

11.执行后显示如下:



.png)
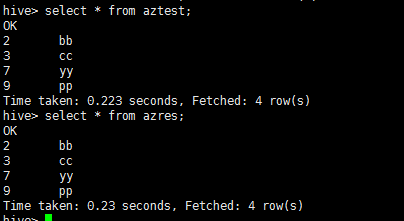
.png)
#hivef.job
type=command
command=sudo -u hdfs hive -f test.sql
#test.sql
use default;
drop table aztest;
create table aztest(id int,name string) row format delimited fields terminated by ",";
load data inpath '/home/lxl/b.txt' into table aztest;
create table azres as select * from aztest;
azkaban 执行hive语句的更多相关文章
- 使用java连接hive,并执行hive语句详解
安装hadoop 和 hive我就不多说了,网上太多文章 自己看去 首先,在机器上打开hiveservice hive --service hiveserver -p 50000 & 打开50 ...
- 使用Hive或Impala执行SQL语句,对存储在HBase中的数据操作
CSSDesk body { background-color: #2574b0; } /*! zybuluo */ article,aside,details,figcaption,figure,f ...
- 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据操作(二)
CSSDesk body { background-color: #2574b0; } /*! zybuluo */ article,aside,details,figcaption,figure,f ...
- 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据操作
http://www.cnblogs.com/wgp13x/p/4934521.html 内容一样,样式好的版本. 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据 ...
- hive高阶1--sql和hive语句执行顺序、explain查看执行计划、group by生成MR
hive语句执行顺序 msyql语句执行顺序 代码写的顺序: select ... from... where.... group by... having... order by.. 或者 from ...
- Hadoop生态圈-Azkaban实现hive脚本执行
Hadoop生态圈-Azkaban实现hive脚本执行 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客中在HDFS分布式系统取的数据,而这个数据的是有之前我通过MapRed ...
- shell中执行hive命令错误:delimited by end-of-file (wanted `EOF')
错误信息: warning: here-document at line 58 delimited by end-of-file (wanted `EOF') 业务场景,使用hive对数据进行批量清洗 ...
- 通过学生-课程关系表,熟悉hive语句
通过学生-课程关系表,熟悉hive语句 1.在hive中创建以下三个表. create table student(Sno int,Sname string,Sex string,Sage int, ...
- 工作中常见的hive语句总结
hive的启动: 1.启动hadoop2.开启 metastore 在开启 hiveserver2服务nohup hive --service metastore >> log.out 2 ...
随机推荐
- latex之行内公式与行间公式
1.行内公式 我是对行内公式的测试$f(x)=1+x+x^2$ 2.行间公式 单行不编号 \begin{equation} \int_0^1(1+x)dx \end{equation} 结果为: 单行 ...
- Python之os模块和sys模块
OS模块:print(os.getcwd())os.chdir('..') #返回上一层目录print(os.getcwd()) os.makedirs('xxxx') #生成多级递归目录os.mkd ...
- vue调用支付接口
html: <div class="paymentHtml" v-html="paymentHtml"></div> script: d ...
- JVM垃圾回收算法解析
JVM垃圾回收算法解析 标记-清除算法 该算法为最基础的算法.它分为标记和清除两个阶段,首先标记出需要回收的对象,在标记结束后,统一回收.该算法存在两个问题:一是效率问题,标记和清除过程效率都不太高, ...
- Ubuntu16.04中安装搜狗输入法
1.从搜狗输入法官网界面下载安装包 https://pinyin.sogou.com/linux/ 2.安装 sudo dpkg -i sogoupinyin_2.1.0.0082_amd64.deb ...
- hdu5007 Post Robot AC自动机
DT is a big fan of digital products. He writes posts about technological products almost everyday in ...
- maven整合ssh框架笔记
具体工程会上传文件sshpro <?xml version="1.0" encoding="UTF-8"?> <web-app xmlns:x ...
- rabbitmq management advance lesson
rabbitmq management advance management install rabbitmq-plugins enable rabbitmq_management visit : h ...
- 【python接口自动化-requests库】【一】requests库安装
1.概念 requests 是用Python语言编写,基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库.它比 urllib 更加方便,可以节约我们大量的工作,完全满 ...
- 【CH5104】I-country 线性dp+路径输出
pre:在网格中,凸多边形可以按行(row)分解成若干段连续的区间 [ l , r ] ,且左端点纵坐标的值(col)满足先减后增,右端点纵坐标先增后减. 阶段:根据这个小发现,可以将阶段设置成每一行 ...