Pandas 基础(9) - 组合方法 merge
首先, 还是以天气为例, 准备如下数据:
df1 = pd.DataFrame({
'city': ['newyork', 'chicago', 'orlando'],
'temperature': [21, 24, 32],
})
df2 = pd.DataFrame({
'city': ['newyork', 'chicago', 'orlando'],
'humidity': [89, 79, 80],
})
df = pd.merge(df1, df2, on='city')
输出: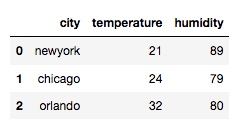
上面的例子就是以 'city' 为基准对两个 dataframe 进行合并, 但是两组数据都是高度一致, 下面调整一下:
df1 = pd.DataFrame({
'city': ['newyork', 'chicago', 'orlando', 'baltimore'],
'temperature': [21, 24, 32, 29],
})
df2 = pd.DataFrame({
'city': ['newyork', 'chicago', 'san francisco'],
'humidity': [89, 79, 80],
})
df = pd.merge(df1, df2, on='city')
输出: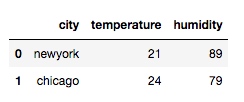
从输出我们看出, 通过 merge 合并, 会取两个数据的交集.
那么, 我们应该可以设想到, 可以通过调整参数, 来达到不同的取值范围.
取并集:
df = pd.merge(df1, df2, on='city', how='outer')
输出: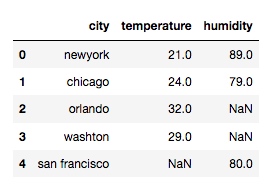
左对齐:
df = pd.merge(df1, df2, on='city', how='left')
输出:
右对齐:
df = pd.merge(df1, df2, on='city', how='right')


另外, 在我们取并集的时候, 我们有时可能会想要知道, 某个数据是来自哪边, 可以通过 indicator 参数来获取:
df = pd.merge(df1, df2, on='city', how='outer', indicator=True)
输出:
在上面的例子中, 被合并的数据的列名是没有冲突的, 所以合并的很顺利, 那么如果两组数据有相同的列名, 又会是什么样呢? 看下面的例子:
df1 = pd.DataFrame({
'city': ['newyork', 'chicago', 'orlando', 'baltimore'],
'temperature': [21, 24, 32, 29],
'humidity': [89, 79, 80, 69],
})
df2 = pd.DataFrame({
'city': ['newyork', 'chicago', 'san francisco'],
'temperature': [30, 32, 28],
'humidity': [80, 60, 70],
})
df = pd.merge(df1, df2, on='city')
输出:
我们发现, 相同的列名被自动加上了 'x', 'y' 作为区分, 为了更直观地观察数据, 我们也可以自定义这个区分的标志:
df3 = pd.merge(df1, df2, on='city', suffixes=['_left', '_right'])
输出:
好了, 以上, 就是关于 merge 合并的相关内容, enjoy~~~
Pandas 基础(9) - 组合方法 merge的更多相关文章
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- numpy&pandas基础
numpy基础 import numpy as np 定义array In [156]: np.ones(3) Out[156]: array([1., 1., 1.]) In [157]: np.o ...
- 利用Python进行数据分析(9) pandas基础: 汇总统计和计算
pandas 对象拥有一些常用的数学和统计方法. 例如,sum() 方法,进行列小计: sum() 方法传入 axis=1 指定为横向汇总,即行小计: idxmax() 获取最大值对应的索 ...
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一.reindex() 方法:重新索引 针对 Series 重新索引指的是根据index参数重新进行排序. 如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行. 不想用缺失值,可以用 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- Pandas基础学习与Spark Python初探
摘要:pandas是一个强大的Python数据分析工具包,pandas的两个主要数据结构Series(一维)和DataFrame(二维)处理了金融,统计,社会中的绝大多数典型用例科学,以及许多工程领域 ...
- Pandas 基础(1) - 初识及安装 yupyter
Hello, 大家好, 昨天说了我会再更新一个关于 Pandas 基础知识的教程, 这里就是啦......Pandas 被广泛应用于数据分析领域, 是一个很好的分析工具, 也是我们后面学习 machi ...
- 基于 Python 和 Pandas 的数据分析(2) --- Pandas 基础
在这个用 Python 和 Pandas 实现数据分析的教程中, 我们将明确一些 Pandas 基础知识. 加载到 Pandas Dataframe 的数据形式可以很多, 但是通常需要能形成行和列的数 ...
- python学习笔记(四):pandas基础
pandas 基础 serise import pandas as pd from pandas import Series, DataFrame obj = Series([4, -7, 5, 3] ...
随机推荐
- ThreadPool study
线程池浅析 线程池顾名思义就是放线程的池子 Thread Pool. 那么为什么要有线程池呢?有些时候系统需要处理非常多的执行时间很短的请求,如果每一个请求都开启一个新的线程,则系统创建销毁线程的开销 ...
- PPT文件太大时可以考虑另存为PPTX格式
遇到一个PPT文件有24M,30多页,里面主要有一些图片. 使用自带的图片压缩功能进行压缩,发现没有什么改变,后来找了一些工具软件压缩,最多也只能减少22%. 后来另存为PPTX格式,减小到1.74M ...
- JavaScript基础知识(字符串的方法)
字符串的方法 1.字符串: 在js中被单引号或双引号包起来的内容都是字符串: var t = "true"; console.log(typeof t);// "stri ...
- day5_函数返回值
每个函数都有返回值,如果没有在函数里面指定返回值的话,在python里面函数执行完之后,默认会返回一个None,函数也可以有多个返回值,如果有多个返回值的话,会把返回值都放到一个元组中,返回的是一个元 ...
- 点击刷新验证码所需要的onclick函数
<img src="__APP__/Public/verify" onclick="this.src=this.src+'?'+Math.random()" ...
- 基于Enterprise Architect完成数据库建模
基于Enterprise Architect完成数据库建模 “工欲善其事必先利其器”,Enterprise Architect是一款非常便利的设计工具,目前我也是刚刚使用没多久,进行过系统设计.UML ...
- Storm UI说明
一.Storm ui 首页主要分为4块: Cluster Summary,Topology summary,Supervisor summary,Nimbus Configuration Cluste ...
- git中设置http代理和取消http代理
设置http代理 git config --global https.proxy https://127.0.0.1:1080 取消http代理git config --global --unset ...
- 【UML】NO.46.EBook.5.UML.1.006-【UML 大战需求分析】- 用例图(Use Case Diagram)
1.0.0 Summary Tittle:[UML]NO.46.EBook.1.UML.1.006-[UML 大战需求分析]- 用例图(Use Case Diagram) Style:DesignPa ...
- 台式电脑、笔记本快捷选择启动项Boot 快捷键大全
我们在安装系统时,会去设置电脑是从硬盘启动.U盘启动.光驱启动.网卡启动. 一般设置的方法有两种:一种是进BIOS主板菜单设置启动项顺序:另一种就是我在这里要介绍的快捷选择启动项. 以下是网友整理的各 ...