hadoop(二):hdfs HA原理及安装
早期的hadoop版本,NN是HDFS集群的单点故障点,每一个集群只有一个NN,如果这个机器或进程不可用,整个集群就无法使用。为了解决这个问题,出现了一堆针对HDFS HA的解决方案(如:Linux HA, VMware FT, shared NAS+NFS, BookKeeper, QJM/Quorum Journal Manager, BackupNode等); 在HA具体实现方法不同的情况下,HA框架的流程是一致的, 不一致的就是如何存储和管理日志。在Active NN和Standby NN之间要有个共享的存储日志的地方,Active NN把EditLog写到这个共享的存储日志的地方,Standby NN去读取日志然后执行,这样Active和Standby NN内存中的HDFS元数据保持着同步。一旦发生主从切换Standby NN可以尽快接管Active NN的工作; 在 HDP2.4安装(五):集群及组件安装 章节使用ambari创建cluster时,默认并未启用 hdfs ha, 可以通过 ambari 管理界面进行安装
目录:
- SPOF(single point of failure)方案回顾
- hadoop2.x ha 原理
- hadoop2.x ha 详述
- hadoop2.x Federation
- ha 安装配置
SPOF方案回顾:
- Secondary NameNode:它不是HA,它只是阶段性的合并edits和fsimage,以缩短集群启动的时间。当NN失效的时候,Secondary NN并无法立刻提供服务,Secondary NN甚至无法保证数据完整性:如果NN数据丢失的话,在上一次合并后的文件系统的改动会丢失
- Backup NameNode (HADOOP-4539):它在内存中复制了NN的当前状态,算是Warm Standby,可也就仅限于此,并没有failover等。它同样是阶段性的做checkpoint,也无法保证数据完整性
- 手动把name.dir指向NFS(Network File System),这是安全的Cold Standby,可以保证元数据不丢失,但集群的恢复则完全靠手动
- Facebook AvatarNode:Facebook有强大的运维做后盾,所以Avatarnode只是Hot Standby,并没有自动切换,当主NN失效的时候,需要管理员确认,然后手动把对外提供服务的虚拟IP映射到Standby NN,这样做的好处是确保不会发生脑裂的场景。其某些设计思想和Hadoop 2.0里的HA非常相似,从时间上来看,Hadoop 2.0应该是借鉴了Facebook的做法
- Facebook AvatarNode 原理示例图

- PrimaryNN与StandbyNN之间通过NFS来共享FsEdits、FsImage文件,这样主备NN之间就拥有了一致的目录树和block信息;而block的位置信息,可以根据DN向两个NN上报的信息过程中构建起来。这样再辅以虚IP,可以较好达到主备NN快速热切的目的。但是显然,这里的NFS又引入了新的SPOF
- 在主备NN共享元数据的过程中,也有方案通过主NN将FsEdits的内容通过与备NN建立的网络IO流,实时写入备NN,并且保证整个过程的原子性。这种方案,解决了NFS共享元数据引入的SPOF,但是主备NN之间的网络连接又会成为新的问题
hadoop2.X ha 原理:
- hadoop2.x之后,Clouera提出了QJM/Qurom Journal Manager,这是一个基于Paxos算法实现的HDFS HA方案,它给出了一种较好的解决思路和方案,示意图如下:
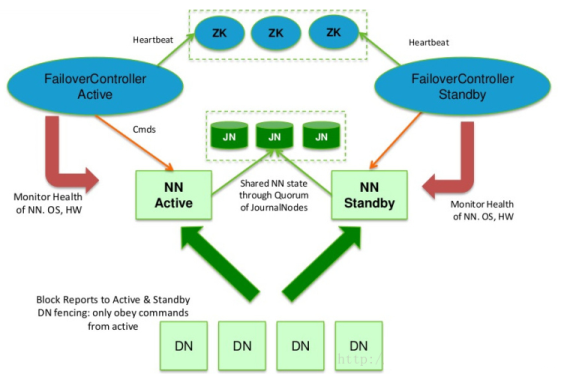
- 基本原理就是用2N+1台 JN 存储EditLog,每次写数据操作有大多数(>=N+1)返回成功时即认为该次写成功,数据不会丢失了。当然这个算法所能容忍的是最多有N台机器挂掉,如果多于N台挂掉,这个算法就失效了。这个原理是基于Paxos算法
- 在HA架构里面SecondaryNameNode这个冷备角色已经不存在了,为了保持standby NN时时的与主Active NN的元数据保持一致,他们之间交互通过一系列守护的轻量级进程JournalNode
- 任何修改操作在 Active NN上执行时,JN进程同时也会记录修改log到至少半数以上的JN中,这时 Standby NN 监测到JN 里面的同步log发生变化了会读取 JN 里面的修改log,然后同步到自己的的目录镜像树里面,如下图:
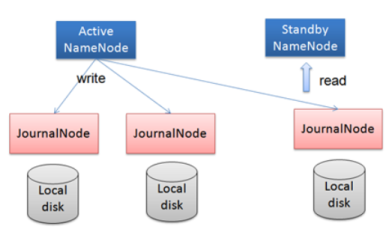
- 当发生故障时,Active的 NN 挂掉后,Standby NN 会在它成为Active NN 前,读取所有的JN里面的修改日志,这样就能高可靠的保证与挂掉的NN的目录镜像树一致,然后无缝的接替它的职责,维护来自客户端请求,从而达到一个高可用的目的
- QJM方式来实现HA的主要优势:
- 不需要配置额外的高共享存储,降低了复杂度和维护成本
- 消除spof
- 系统鲁棒性(Robust:健壮)的程度是可配置
- JN不会因为其中一台的延迟而影响整体的延迟,而且也不会因为JN的数量增多而影响性能(因为NN向JN发送日志是并行的)
hadoop2.x ha 详述:
- datanode的fencing: 确保只有一个NN能命令DN。HDFS-1972中详细描述了DN如何实现fencing
- 每个NN改变状态的时候,向DN发送自己的状态和一个序列号
- DN在运行过程中维护此序列号,当failover时,新的NN在返回DN心跳时会返回自己的active状态和一个更大的序列号。DN接收到这个返回则认为该NN为新的active
- 如果这时原来的active NN恢复,返回给DN的心跳信息包含active状态和原来的序列号,这时DN就会拒绝这个NN的命令
- 客户端fencing:确保只有一个NN能响应客户端请求,让访问standby nn的客户端直接失败。在RPC层封装了一层,通过FailoverProxyProvider以重试的方式连接NN。通过若干次连接一个NN失败后尝试连接新的NN,对客户端的影响是重试的时候增加一定的延迟。客户端可以设置重试此时和时间
- Hadoop提供了ZKFailoverController角色,部署在每个NameNode的节点上,作为一个deamon进程, 简称zkfc,示例图如下:

- FailoverController主要包括三个组件:
- HealthMonitor: 监控NameNode是否处于unavailable或unhealthy状态。当前通过RPC调用NN相应的方法完成
- ActiveStandbyElector: 管理和监控自己在ZK中的状态
- ZKFailoverController 它订阅HealthMonitor 和ActiveStandbyElector 的事件,并管理NameNode的状态
- ZKFailoverController主要职责:
- 健康监测:周期性的向它监控的NN发送健康探测命令,从而来确定某个NameNode是否处于健康状态,如果机器宕机,心跳失败,那么zkfc就会标记它处于一个不健康的状态
- 会话管理:如果NN是健康的,zkfc就会在zookeeper中保持一个打开的会话,如果NameNode同时还是Active状态的,那么zkfc还会在Zookeeper中占有一个类型为短暂类型的znode,当这个NN挂掉时,这个znode将会被删除,然后备用的NN,将会得到这把锁,升级为主NN,同时标记状态为Active
- 当宕机的NN新启动时,它会再次注册zookeper,发现已经有znode锁了,便会自动变为Standby状态,如此往复循环,保证高可靠,需要注意,目前仅仅支持最多配置2个NN
- master选举:如上所述,通过在zookeeper中维持一个短暂类型的znode,来实现抢占式的锁机制,从而判断那个NameNode为Active状态
hadoop2.x Federation:
- 单Active NN的架构使得HDFS在集群扩展性和性能上都有潜在的问题,当集群大到一定程度后,NN进程使用的内存可能会达到上百G,NN成为了性能的瓶颈
- 常用的估算公式为1G对应1百万个块,按缺省块大小计算的话,大概是64T (这个估算比例是有比较大的富裕的,其实,即使是每个文件只有一个块,所有元数据信息也不会有1KB/block)
- 为了解决这个问题,Hadoop 2.x提供了HDFS Federation, 示意图如下:
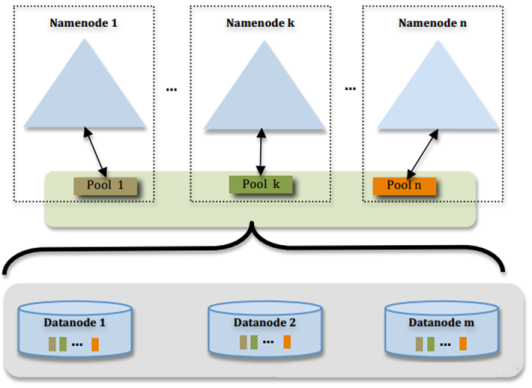
- 多个NN共用一个集群里的存储资源,每个NN都可以单独对外提供服务
- 每个NN都会定义一个存储池,有单独的id,每个DN都为所有存储池提供存储
- DN会按照存储池id向其对应的NN汇报块信息,同时,DN会向所有NN汇报本地存储可用资源情况
- 如果需要在客户端方便的访问若干个NN上的资源,可以使用客户端挂载表,把不同的目录映射到不同的NN,但NN上必须存在相应的目录
- 设计优势:
- 改动最小,向前兼容;现有的NN无需任何配置改动;如果现有的客户端只连某台NN的话,代码和配置也无需改动
- 分离命名空间管理和块存储管理
- 客户端挂载表:通过路径自动对应NN、使Federation的配置改动对应用透明
- 思考:与上面ha方案中介绍的最多2个NN冲突?
ha 安装配置:
- 关于NameNode高可靠需要配置的文件有core-site.xml和hdfs-site.xml
- 关于ResourceManager高可靠需要配置的文件有yarn-site.xml (参数配置及说明见第四章)
- 操作的过程可通过 ambarir 的管理界面提供的 "enable NameNode HA" 完成,如下图:
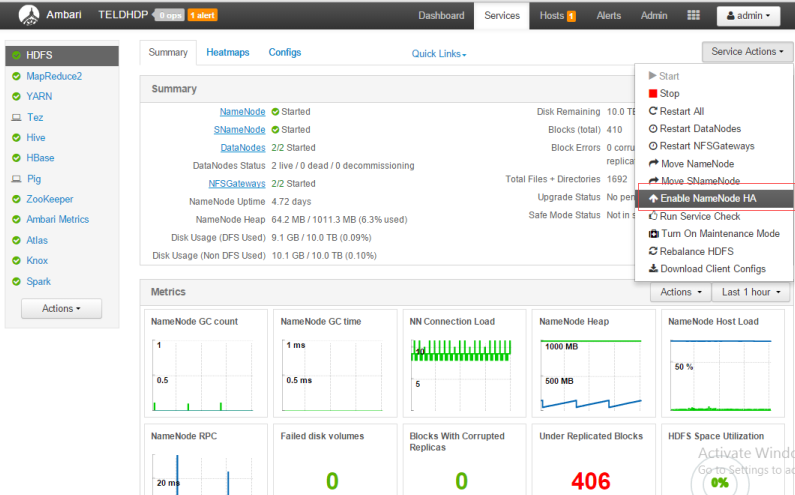
- 系统要求:至少3台以上zookeeper服务器,在原来基础上,将 hdp2\hdp3\R作为zookeeper
- 停止HBase所有服务,设置JN安装在host,及standby NN 节点主机,如下图:

- 按默认配置安装的 secondary NN将去被删除,同时安装 standby NN, 在 R、hdp1、hdp2上配置 JN服务,如下:

- 登陆至 active NN (hdp4), 执行下面的命令
- 命令: sudo su hdfs -l -c 'hdfs dfsadmin -safemode enter' (进入安全模式)
- 命令: sudo su hdfs -l -c 'hdfs dfsadmin -saveNamespace' (create checkpoint)
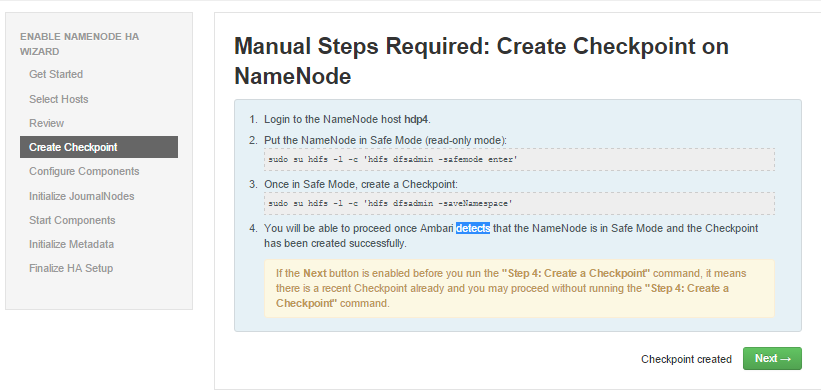
- ambari 检测到 NN进入安全模式并且checkpoint 后进入组件配置,如图:
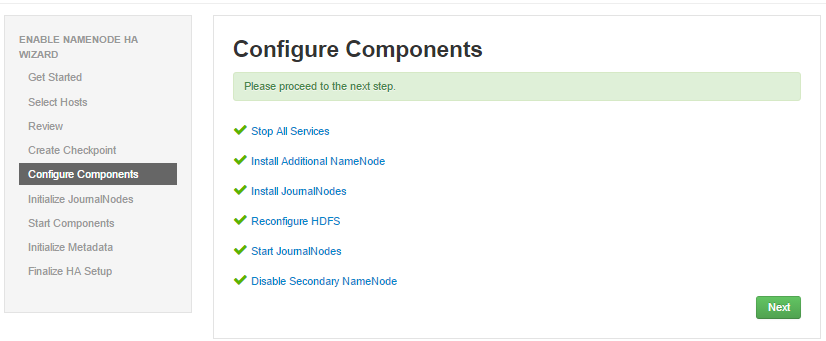
- 初始化JN节点,进入 hdp4,执行命令:sudo su hdfs -l -c 'hdfs namenode -initializeSharedEdits'
- ambari检测到初始化成功后,进入下一步,如图 start component
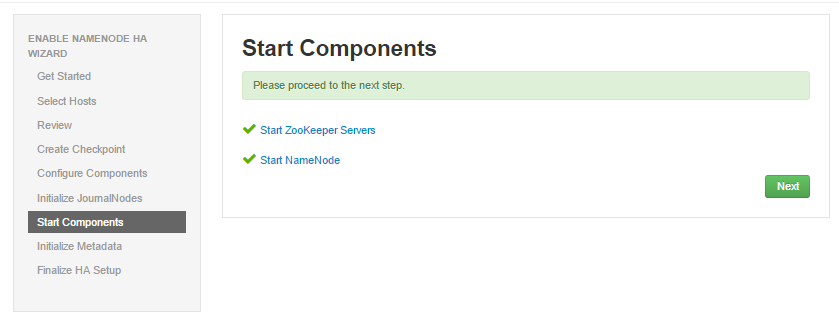
- 手工初始化 NN HA Metadata, 登陆hdp4主机,命令如下:
- 命令: sudo su hdfs -l -c 'hdfs zkfc -formatZK'
- 登陆到standy NN (R), 执行命令:
- 命令: sudo su hdfs -l -c 'hdfs namenode -bootstrapStandby'
- 成功执行上面命令后,点击“下一步”,开始HA安装,成功后如图:

- 回到 ambari 面板
hadoop(二):hdfs HA原理及安装的更多相关文章
- hdfs HA原理
早期的hadoop版本,NN是HDFS集群的单点故障点,每一个集群只有一个NN,如果这个机器或进程不可用,整个集群就无法使用.为了解决这个问题,出现了一堆针对HDFS HA的解决方案(如:Linux ...
- Hadoop的HDFS和MapReduce的安装(三台伪分布式集群)
一.创建虚拟机 1.从网上下载一个Centos6.X的镜像(http://vault.centos.org/) 2.安装一台虚拟机配置如下:cpu1个.内存1G.磁盘分配20G(看个人配置和需求,本人 ...
- hadoop的Namenode HA原理详解
为什么要Namenode HA? 1. NameNode High Availability即高可用. 2. NameNode 很重要,挂掉会导致存储停止服务,无法进行数据的读写,基于此NameNod ...
- Hadoop中HDFS工作原理
转自:http://blog.csdn.net/sdlyjzh/article/details/28876385 Hadoop其实并不是一个产品,而是一些独立模块的组合.主要有分布式文件系统HDFS和 ...
- Hadoop之HDFS读写原理
一.HDFS基本概念 HDFS全称是Hadoop Distributed System.HDFS是为以流的方式存取大文件而设计的.适用于几百MB,GB以及TB,并写一次读多次的场合.而对于低延时数据访 ...
- 【Hadoop学习之四】HDFS HA搭建(QJM)
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 由于NameNode对于整个HDF ...
- Hadoop(HDFS,YARN)的HA集群安装
搭建Hadoop的HDFS HA及YARN HA集群,基于2.7.1版本安装. 安装规划 角色规划 IP/机器名 安装软件 运行进程 namenode1 zdh-240 hadoop NameNode ...
- 3.配置HDFS HA
安装zookeeper下载zookeeper编辑zookeeper配置文件创建myid文件启动zookeeper配置HDFS HA配置手动HA配置自动HA启动HDFS HA namenode负责管理整 ...
- HDFS HA架构以及源代码引导
HA体系架构 相关知识介绍 HDFS master/slave架构,HDFS节点分为NameNode节点和DataNode节点. NameNode存有HDFS的元数据:主要由FSImage和EditL ...
随机推荐
- Selenium Grid原理
转载: http://blog.csdn.net/five3/article/details/9428655 Selenium-Grid版本 selenium-grid分为版本1和版本2,其实它的2个 ...
- magento启用SSL改http成https
Magento是电子商务网站,对于网站的用户信息安全来说,让Magento使用SSL连接是一个很好的解决方案.如果在页面的边栏或者底部放上些表明本站使用安全连接的图片,显得更专业,让客户有安全感,对于 ...
- H - 放苹果
Time Limit:1000MS Memory Limit:10000KB 64bit IO Format:%I64d & %I64u Submit Status Des ...
- nginx模块_使用gdb调试nginx源码
工欲善其事必先利其器,如何使用调试工具gdb一步步调试nginx是了解nginx的重要手段. ps:本文的目标人群是像我这样初接触Unix编程的同学,如果有什么地方错误请指正. 熟悉gdb的使用 这里 ...
- Condition的await-signal流程详解(转)
上一篇文章梳理了condtion,其中侧重流程,网上看到这篇文章文章介绍的很细.值得学习.特意转载过来. 转载请注明出处:http://blog.csdn.net/luonanqin 转载路径:h ...
- xampp访问403 Access forbidden 解决办法
本地可以访问,换一台机子就不行了,是因为权限没有开启,安装目录xampp\apache\conf\extra内有个httpd-xampp.conf文件,打开, 最后一段是 # # New XAMPP ...
- CUDA 程序中的同步
前言 在并发,多线程环境下,同步是一个很重要的环节.同步即是指进程/线程之间的执行顺序约定. 本文将介绍如何通过共享内存机制实现块内多线程之间的同步. 至于块之间的同步,需要使用到 global me ...
- csu 1604 SunnyPig (bfs)
Description SunnyPig is a pig who is much cleverer than any other pigs in the pigpen. One sunny morn ...
- ListView中convertView和ViewHolder的工作原理
http://blog.csdn.net/bill_ming/article/details/8817172
- SQL注入测试平台 SQLol -2.SELECT注入测试
前面,我们已经安装好了SQLol,打开http://localhost/sql/,首先跳转到http://localhost/sql/select.php,我们先从select模块进行测试. 一条完成 ...