Python爬虫学习笔记——豆瓣登陆(三)
之前是不会想到登陆一个豆瓣会需要写三次博客,修改三次代码的。
本来昨天上午之前的代码用的挺好的,下午时候,我重新注册了一个号,怕豆瓣大号被封,想用小号爬,然后就开始出问题了,发现无法模拟登陆豆瓣了,开始想难道是账号的问题?就又修改成原来的账号和密码,发现仍然无法登陆
想不会这么衰吧,还没开始怕就被豆瓣封了?但是浏览器登录又没有任何问题,这个时候自己完全摸不着头脑,折腾了半天还是不能解决。
最后想起来有Fiddler 这个神器,就抓了一下request和response包,发现response headers里有一个Location,Raw文件里写着302 Found,一查,是链接被重定向了,Location里的就是新的重定向的链接,浏览器能够自动重定向,所以不会出问题,但是代码不会自动给你重定向。可是!!!!!蛋疼的是!!!我看了headers返回的Location链接!!!!不是和原来一毛一样吗!!!!!
傻逼的是又折腾了好久。。。结果!!!尼玛的链接竟然从http的变成了https的,我压根没留意到s的区别。。。浪费了我个吧小时- -#

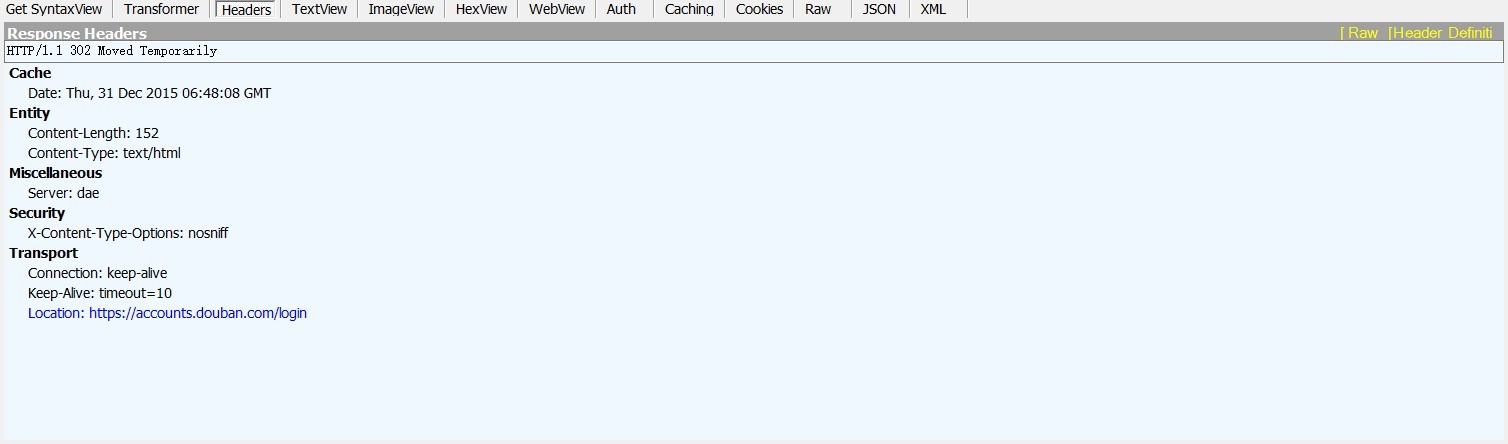
把链接都改为https以后,昨天能用了,但今天写的时候,突然又出error了,
captchaAddr = soup.find('img',id='captcha_image')['src'] line 28
TypeError: 'NoneType' object is not subscriptable
是find最后返回了一个None,这表示没有找到验证码的图片,这个就是豆瓣的一个机制,不一定要输入验证码,所以可以稍微修改一下代码,最后的代码如下:
- #-*- coding:utf-8 -*-
- import requests
- from bs4 import BeautifulSoup
- import html5lib
- import re
- import urllib
- s = requests.Session()
- url1 = 'https://accounts.douban.com/login'
- url2 = 'https://www.douban.com/people/****/contacts'
- formdata={
- "redir":"https://www.douban.com/",
- "form_email":"your email",
- "form_password":"your password",
- #'captcha-solution':'blood',
- #'captcha-id':'cRPGXEYPFHjkfv3u7K4Pm0v1:en',
- "login":u"登录"
- }
- headers = {
- "user-agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 Safari/537.36",
- #"Location": "https://accounts.douban.com/login"
- }
- r1 = s.post(url1,data=formdata,headers=headers)
- rcontent = r1.text
- soup = BeautifulSoup(rcontent,"html5lib")
- #安装了html5lib没用python本身的html解析库
- captchaAddr = soup.find('img',id='captcha_image')['src']
- if captchaAddr != None:
- reCaptchaID = r'<input type="hidden" name="captcha-id" value="(.*?)"/'
- captchaID = re.findall(reCaptchaID,rcontent)
- print(captchaID)
- urllib.request.urlretrieve(captchaAddr,"captcha.jpg")
- captcha = input('please input the captcha:')
- formdata['captcha-solution'] = captcha
- formdata['captcha-id'] = captchaID
- r1 = s.post(url1,data=formdata,headers=headers)
- r2 = s.get(url2)
- f = open('spider2.txt','w',encoding='utf-8')
- f.write(r1.text)
- f.close()
Python爬虫学习笔记——豆瓣登陆(三)的更多相关文章
- Python爬虫学习笔记——豆瓣登陆(一)
#-*- coding:utf-8 -*- import requests from bs4 import BeautifulSoup import html5lib import re import ...
- Python爬虫学习笔记——豆瓣登陆(二)
昨天能够登陆成功,但是不能使用cookies,今天试了一下requests库的Session(),发现可以保持会话了,代码只是稍作改动. #-*- coding:utf-8 -*- import re ...
- python爬虫学习笔记(一)——环境配置(windows系统)
在进行python爬虫学习前,需要进行如下准备工作: python3+pip官方配置 1.Anaconda(推荐,包括python和相关库) [推荐地址:清华镜像] https://mirrors ...
- Python爬虫学习笔记(三)
Cookies: 以抓取https://www.yaozh.com/为例 Test1(不使用cookies): 代码: import urllib.request # 1.添加URL url = &q ...
- Python爬虫学习 - day2 - 站点登陆
利用Python完成简单的站点登陆 最近学习到了爬虫,瞬时觉得很高大上,想取什么就取什么,感觉要上天.这里分享一个简单的登陆抽屉新热榜的教程(因为它不需要验证码,目前还没有学会图像识别.哈哈),供大家 ...
- Python爬虫学习笔记——防豆瓣反爬虫
开始慢慢测试爬虫以后会发现IP老被封,原因应该就是单位时间里面访问次数过多,虽然最简单的方法就是降低访问频率,但是又不想降低访问频率怎么办呢?查了一下最简单的方法就是使用转轮代理IP,网上找了一些方法 ...
- Python爬虫学习笔记之模拟登陆并爬去GitHub
(1)环境准备: 请确保已经安装了requests和lxml库 (2)分析登陆过程: 首先要分析登陆的过程,需要探究后台的登陆请求是怎样发送的,登陆之后又有怎样的处理过程. 如果已经 ...
- python爬虫学习笔记
爬虫的分类 1.通用爬虫:通用爬虫是搜索引擎(Baidu.Google.Yahoo等)“抓取系统”的重要组成部分.主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份. 简单来讲就是尽可 ...
- 一入爬虫深似海,从此游戏是路人!总结我的python爬虫学习笔记!
前言 还记得是大学2年级的时候,偶然之间看到了学长在学习python:我就坐在旁边看他敲着代码,感觉很好奇.感觉很酷,从那之后,我就想和学长一样的厉害,就想让学长教我,请他吃了一周的饭,他答应了.从此 ...
随机推荐
- C++全局变量的声明和定义
(1)编译单元(模块) 在VC或VS上编写完代码,点击编译按钮准备生成exe文件时,编译器做了两步工作: 第一步,将每个.cpp(.c)和相应的.h文件编译成obj文件: 第二步,将工程中所有 ...
- 解决maven Generating project in Interactive mode卡死问题(转)
原文链接:http://blog.csdn.net/only_wan/article/details/52975760 mvn 创建时在generating project in interactiv ...
- maven的简单安装与配置
什么是Maven? Maven可以被理解成"知识的积累",也可以被翻译为"专家".它是一个项目管理工具. 它的主要服务即源于java平台的项目构建.依赖管理和项 ...
- poj1651 区间dp
//Accepted 200 KB 0 ms //dp区间 //dp[i][j]=min(dp[i][k]+dp[k][j]+a[i]*a[k]*a[j]) i<k<j #include ...
- 封装定制的Kali Live ISO
打造专属的Kali ISO – 简介 封装定制的Kali ISO很简单,很有趣,很有意义.你可以用Debian的live-build脚本对Kali ISO进行全面的配置.这些脚本以一系列配置文件的方式 ...
- BZOJ 3450 Easy
注意细节啊... 和上一道差不多. #include<iostream> #include<cstdio> #include<cstring> #include&l ...
- mantis增加密码修改
解决方式就是考虑修改Mantisbt PHP程序,增加一个密码修改框,这样管理员就可以直接修改用户密码了. 操作步骤如下: 1) 修改文件 manage_user_edit_page.p ...
- ERP权限系统(七)
添加链接权限的字段: //权限管理 n.Target = "MainFrame"; //折叠 TreeView1.Nodes.Add(n); n.Expanded = false;
- Android消息推送
1.引言 所谓的消息推送就是从服务器端向移动终端发送连接,传输一定的信息.比如一些新闻客户端,每隔一段时间收到一条或者多条通知,这就是从服务器端传来的推送消息:还比如常用的一些IM软件如微信.GTal ...
- HDU 3038
http://acm.hdu.edu.cn/showproblem.php?pid=3038 题意:[1-n]的区间,有m个询问,每个询问表示[a,b]的和是s,问一共有多少组矛盾 sum[i]表示i ...