Cross Validation done wrong
Cross Validation done wrong
Cross validation is an essential tool in statistical learning 1 to estimate the accuracy of your algorithm. Despite its great power it also exposes some fundamental risk when done wrong which may terribly bias your accuracy estimate.
In this blog post I'll demonstrate - using the Python scikit-learn2framework - how to avoid the biggest and most common pitfall of cross validation in your experiments.
Theory first
Cross validation involves randomly dividing the set of observations intok groups (or folds) of approximately equal size. The first fold is treated as a validation set, and the machine learning algorithm is trained on the remaining k-1 folds. The mean squared error is then computed on the held-out fold. This procedure is repeated k times; each time, a different group of observations is treated as a validation set.
This process results in k estimates of the MSE quantity, namely MSE1, MSE2,...MSEk. The cross validation estimate for the MSE is then computed by simply averaging these values:
This value is an estimate, say MSE^, of the real MSE and our goal is to make this estimate as accurate as possible.
Hands on
Let's now have a look at one of the most typical mistakes when using cross validation. When cross validation is done wrong the result is that MSE^ does not reflect its real value MSE. In other words, you may think that you just found a perfect machine learning algorithm with incredibly low MSE, while in reality you simply wrongly applied CV.
I'll first show you - hands on - a wrong application of cross validation and then we will fix it together. The code is also available as an IPython notebook on github.
Dataset generation
|
1
2
3
4
5
6
7
8
9
|
# Import pandas
import pandas as pd
from pandas import *
# Import scikit-learn
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import *
from sklearn.metrics import *
import random
|
To make things simple let's first generate some random data and let's pretend that we want to build a machine learning algorithm to predict the outcome. I'll first generate a dataset of 100 entries. Each entry has10.000 features. But, why so many? Well, to demonstrate our issue I need to generate some correlation between our inputs and output which is purely casual. You'll understand the why later in this post.
|
1
2
3
4
5
6
|
features = np.random.randint(0,10,size=[100,10000])
target = np.random.randint(0,2,size=100)
df = DataFrame(features)
df['target'] = target
df.head()
|
Feature selection
At this point we would like to know what are the features that are more useful to train our predictor. This is called feature selection. The simplest approach to do that is to find which of the 10.000 features in our input is mostly correlated the target. Using pandas this is very easy to do thanks to the corr() function. We run corr() on our dataframe, we order the correlation values, and we pick the first two features.
|
1
2
3
4
5
6
7
8
9
10
|
corr = df.corr()['target'][df.corr()['target'] < 1].abs()
corr.sort(ascending=False)
corr.head()
# 3122 0.392430
# 830 0.367405
# 8374 0.351462
# 9801 0.341806
# 5585 0.336950
# Name: target, dtype: float64
|
Start the training
Great! Out of the 10.000 features we have been able to select two of them, i.e. feature number 3122 and 830 that have a 0.36 and 0.39correlation with the output. At this point let's just drop all the other columns and use these two features to train a simpleLogisticRegression. We then use scikit-learn cross_val_score to compute MSE^ which in this case is equal to 0.33. Pretty good!
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
features = corr.index[[0,1]].values
training_input = df[features].values
training_output = df['target']
logreg = LogisticRegression()
# scikit learn return the negative value for MSE
# http://stackoverflow.com/questions/21443865/scikit-learn-cross-validation-negative-values-with-mean-squared-error
mse_estimate = -1 * cross_val_score(logreg, training_input, training_output, cv=10, scoring='mean_squared_error')
mse_estimate
# array([ 0.45454545, 0.27272727, 0.27272727, 0.5 , 0.4 ,
# 0.2 , 0.2 , 0.44444444, 0.33333333, 0.22222222])
DataFrame(mse_estimate).mean()
# 0 0.33
# dtype: float64
|
Knowledge leaking
According to the previous estimate we built a system that can predict a random noise target from a random noise input with a MSE of just0.33. The result is, as you can expect, wrong. But why?
The reason is rather counterintuitive and this is why this mistake is so common3. When we applied the feature selection we used information from both the training set and the test sets used for the cross validation, i.e. the correlation values. As a consequence our LogisticRegressionknew information in the test sets that were supposed to be hidden to it. In fact, when you are computing MSEi in the i-th iteration of the cross validation you should be using only the information on the training fold, and nothing should come from the test fold. In our case the model did indeed have information from the test fold, i.e. the top correlated features. I think the term knowledge leaking express this concept fairly well.
The schema that follows shows you how the knowledge leaked into theLogisticRegression because the feature selection has been appliedbefore the cross validation procedure started. The model knows something about the data highlighted in yellow that it shoulnd't know, its top correlated features.
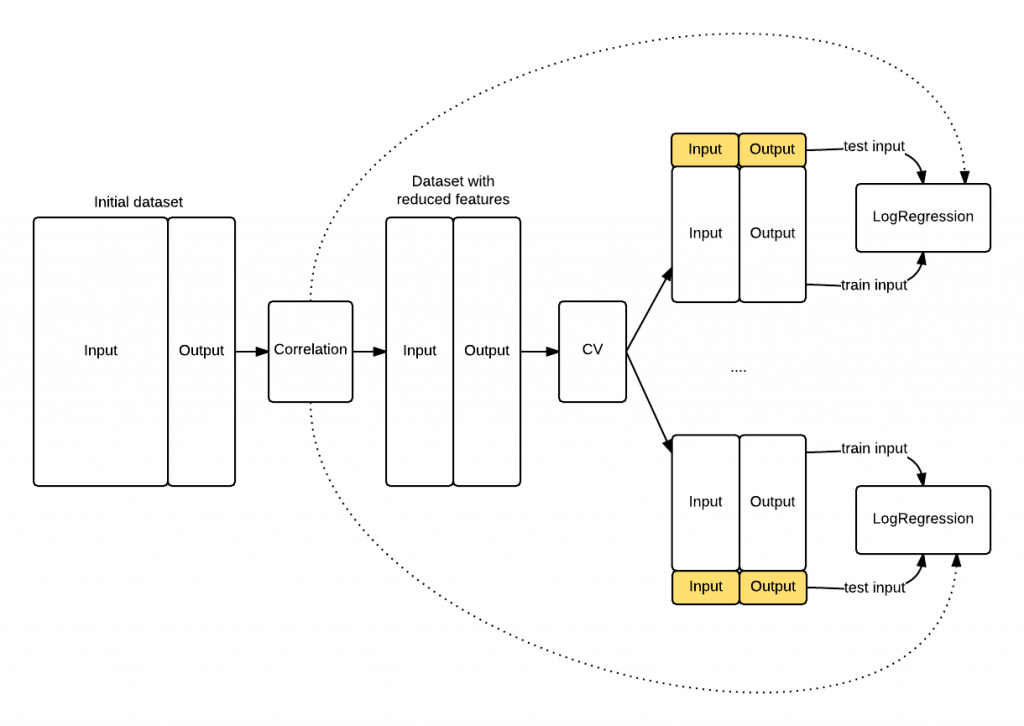 Figure 1. The exposed knowledge leaking. The LogisticRegression knows the top correlated features of the entire dataset (hence including test folds) because of the initial correlation operation, whilst it should be exposed only to the training fold information.
Figure 1. The exposed knowledge leaking. The LogisticRegression knows the top correlated features of the entire dataset (hence including test folds) because of the initial correlation operation, whilst it should be exposed only to the training fold information.
Proof that our model is biased
To check that we were actually wrong let's do the following:
* Take out a portion of the data set (take_out_set).
* Train the LogisticRegression on the remaining data using the same feature selection we did before.
* After the training is done check the MSE on the take_out_set.
Is the MSE on the take_out_set similar to the MSE^ we estimated with the CV? The answer is no, and we got a much more reasonable MSE of0.53 that is much higher than the MSE^ of 0.33.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
take_out_set = df.ix[random.sample(df.index, 30)]
training_set = df[~(df.isin(take_out_set)).all(axis=1)]
corr = training_set.corr()['target'][df.corr()['target'] < 1].abs()
corr.sort(ascending=False)
features = corr.index[[0,1]].values
training_input = training_set[features].values
training_output = training_set['target']
logreg = LogisticRegression()
logreg.fit(training_input, training_output)
# LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
# intercept_scaling=1, max_iter=100, multi_class='ovr',
# penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
# verbose=0)
y_take_out = logreg.predict(take_out_set[features])
mean_squared_error(take_out_set.target, y_take_out)
# 0.53333333333333333
|
Cross validation done right
In the previous section we have seen that if you inject test knowledge in your model your cross validation procedure will be biased. To avoid this let's compute the features correlation during each cross validation batch. The difference is that now the features correlation will use only the information in the training fold instead of the entire dataset. That's the key insight causing the bias we saw previously. The following graph shows you the revisited procedure. This time we got a realistic MSE^ of0.53 that confirms the data is randomly distributed.
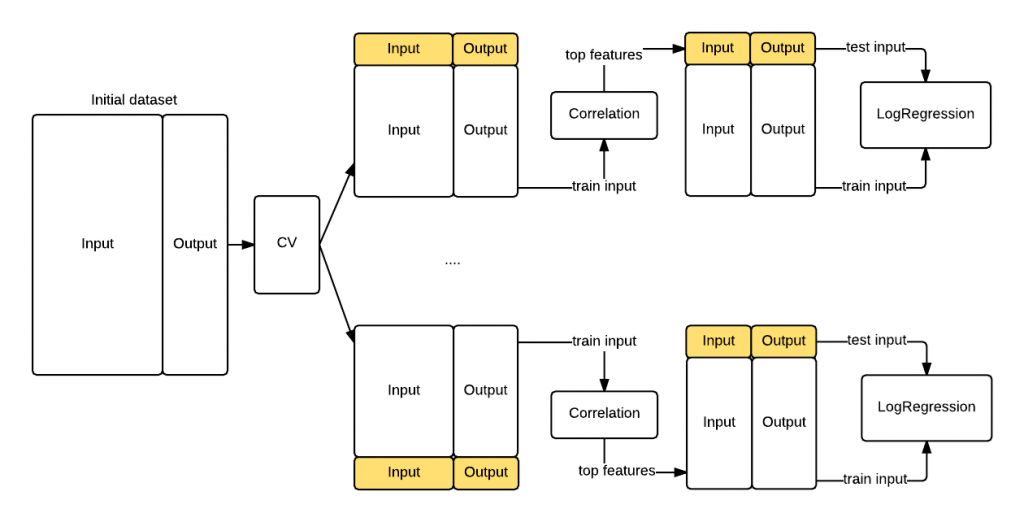 Figure 2. Revisited cross validation workflow with the correlation step performed for each of the K train/test folds.
Figure 2. Revisited cross validation workflow with the correlation step performed for each of the K train/test folds.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
kf = KFold(df.shape[0], n_folds=10)
mse = []
fold_count = 0
for train, test in kf:
print("Processing fold %s" % fold_count)
train_fold = df.ix[train]
test_fold = df.ix[test]
# find best features
corr = train_fold.corr()['target'][train_fold.corr()['target'] < 1].abs()
corr.sort(ascending=False)
features = corr.index[[0,1]].values
# Get training examples
train_fold_input = train_fold[features].values
train_fold_output = train_fold['target']
# Fit logistic regression
logreg = LogisticRegression()
logreg.fit(train_fold_input, train_fold_output)
# Check MSE on test set
pred = logreg.predict(test_fold[features])
mse.append(mean_squared_error(test_fold.target, pred))
# Done with the fold
fold_count += 1
print(DataFrame(mse).mean())
# Processing fold 0
# Processing fold 1
# Processing fold 2
# Processing fold 3
# Processing fold 4
# Processing fold 5
# Processing fold 6
# Processing fold 7
# Processing fold 8
# Processing fold 9
DataFrame(mse).mean()
# 0 0.53
# dtype: float64
|
Conclusion
We have seen how doing features selection at the wrong step can terribly bias the MSE estimate of your machine learning algorithm. We have also seen how to correctly apply cross validation by simply moving one step down the features selection such that the knowledge from the test data does not leak in our learning procedure.
If you want to make sure you don't leak info across the train and test set scikit learn gives you additional extra tools like the feature selection pipeline4 and the classes inside the feature selection module5.
Finally, if you want know more about cross validation and its tradeoffs both R. Kohavi6 and Y. Bengio with Y. Grandvalet7 wrote on this topic.
If you liked this post you should consider following me on twitter.
Let me know your comments!
References
- Lecture 1 on cross validation - Statistical Learning @ Stanford
- Scikit-learn framework
- Lecture 2 on cross validation - Statistical Learning @ Stanford
- Scikit-learn feature selection pipeline
- Scikit-learn feature selection modules
- R. Kohavi. A study of cross-validation and bootstrap for accuracy estimation and model selection
- Y. Bengio and Y. Grandvalet. No unbiased estimator of the variance of k-fold cross-validation
Posted onJuly 29, 2015Authormottalrd
10 thoughts on “Cross Validation done wrong”
Gael Varoquauxsays:
To do feature selection inside a cross-validation loop, you should really be using the feature selection objects inside a pipeline:
http://scikit-learn.org/stable/auto_examples/feature_selection/feature_selection_pipeline.html
http://scikit-learn.org/stable/modules/feature_selection.html
That way you can use the model selection tools of scikit-learn:
http://scikit-learn.org/stable/modules/model_evaluation.htmlAnd you are certain that you won't be leaking info across train and test sets.
Cross Validation done wrong的更多相关文章
- 交叉验证(Cross Validation)原理小结
交叉验证是在机器学习建立模型和验证模型参数时常用的办法.交叉验证,顾名思义,就是重复的使用数据,把得到的样本数据进行切分,组合为不同的训练集和测试集,用训练集来训练模型,用测试集来评估模型预测的好坏. ...
- 交叉验证 Cross validation
来源:CSDN: boat_lee 简单交叉验证 hold-out cross validation 从全部训练数据S中随机选择s个样例作为训练集training set,剩余的作为测试集testin ...
- 交叉验证(cross validation)
转自:http://www.vanjor.org/blog/2010/10/cross-validation/ 交叉验证(Cross-Validation): 有时亦称循环估计, 是一种统计学上将数据 ...
- 10折交叉验证(10-fold Cross Validation)与留一法(Leave-One-Out)、分层采样(Stratification)
10折交叉验证 我们构建一个分类器,输入为运动员的身高.体重,输出为其从事的体育项目-体操.田径或篮球. 一旦构建了分类器,我们就可能有兴趣回答类似下述的问题: . 该分类器的精确率怎么样? . 该分 ...
- Cross Validation(交叉验证)
交叉验证(Cross Validation)方法思想 Cross Validation一下简称CV.CV是用来验证分类器性能的一种统计方法. 思想:将原始数据(dataset)进行分组,一部分作为训练 ...
- S折交叉验证(S-fold cross validation)
S折交叉验证(S-fold cross validation) 觉得有用的话,欢迎一起讨论相互学习~Follow Me 仅为个人观点,欢迎讨论 参考文献 https://blog.csdn.net/a ...
- 交叉验证(Cross Validation)简介
参考 交叉验证 交叉验证 (Cross Validation)刘建平 一.训练集 vs. 测试集 在模式识别(pattern recognition)与机器学习(machine lea ...
- cross validation笔记
preface:做实验少不了交叉验证,平时常用from sklearn.cross_validation import train_test_split,用train_test_split()函数将数 ...
- 几种交叉验证(cross validation)方式的比较
模型评价的目的:通过模型评价,我们知道当前训练模型的好坏,泛化能力如何?从而知道是否可以应用在解决问题上,如果不行,那又是哪里出了问题? train_test_split 在分类问题中,我们通常通过对 ...
随机推荐
- windows下 apache 二级域名相关配置
小编今天给大家总结下 windows 下 apache的二级域名的相关配置 利用.htaccess将域名绑定到子目录 下面就利用本地127.0.0.1进行测试 我们这里以 www.jobs.com 为 ...
- 华为C语言编程规范
DKBA华为技术有限公司内部技术规范DKBA 2826-2011.5C语言编程规范2011年5月9日发布 2011年5月9日实施华为技术有限公司Huawei Technologies Co., Ltd ...
- WPF自定义控件(一)——Button
接触WPF也有两个多月了,有了一定的理论基础和项目经验,现在打算写一个系列,做出来一个WPF的控件库.一方面可以加强自己的水平,另一方面可以给正在学习WPF的同行一个参考.本人水平有限,难免有一些错误 ...
- 刀哥多线程全局队列gcd-09-global_queue
全局队列 是系统为了方便程序员开发提供的,其工作表现与并发队列一致 全局队列 & 并发队列的区别 全局队列 没有名称 无论 MRC & ARC 都不需要考虑释放 日常开发中,建议使用& ...
- 【转】Java JDBC连接SQL Server2005错误:通过端口 1433 连接到主机 localhost 的 TCP/IP 连接失败
错误原因如下: Exception in thread "main" org.hibernate.exception.JDBCConnectionException: Cannot ...
- JVM学习总结五(番外)——VisualVM
距离上次介绍Jconsole已经时隔两周了,这期间由于工作中要用go来做一个新项目,所以精力都用在入门go上了,不过发现go语言用起来真的挺不错的,比python感觉还好点,大家没事可以了解下. ...
- ExtJS 等待两个/多个store加载完再执行操作的方法
ExtJS是一种主要用于创建前端用户界面,是一个基本与后台技术无关的前端ajax框架. Extjs加载Store是异步加载的,这有很多好处.但是当我们要在两个或多个不同的store加载完再执行一些操作 ...
- C# SQL增删查改
DBHelper: /// <summary> /// 执行查询 /// </summary> /// <param name="sql">有效 ...
- java判断某个字符串包含某个字符串的个数
/** * 判断str1中包含str2的个数 * @param str1 * @param str2 * @return counter */ public static int countStr(S ...
- Mono for Android (4)-- 图片转为二进制,二进制转回图片
最近纠结蓝牙打印的问题,想着图片先转为二进制发给打印机,找了好多资料,终于成功了,贴出来共享一下 先是图片转换为二进制的: Bitmap bitmap = BitmapFactory.DecodeRe ...