ElasticSearch 5学习(8)——分布式文档存储(wait_for_active_shards新参数分析)
学完ES分布式集群的工作原理以及一些基本的将数据放入索引然后检索它们的所有方法,我们可以继续学习在分布式系统中,每个分片的文档是被如何索引和查询的。
路由
首先,我们需要明白,文档和分片之间是如何匹配的,这就是路由。当你索引一个文档,它被存储在单独一个主分片上。Elasticsearch是如何知道文档属于哪个分片的呢?当你创建一个新文档,它是如何知道是应该存储在分片1还是分片2上的呢?
进程不能是随机的,因为我们将来要检索文档。事实上,它根据一个简单的算法决定:
shard = hash(routing) % number_of_primary_shards
routing值是一个任意字符串,它默认是_id但也可以自定义。这个routing字符串通过哈希函数生成一个数字,然后除以主切片的数量得到一个余数(remainder),余数的范围永远是0到number_of_primary_shards - 1,这个数字就是特定文档所在的分片。
这也解释了为什么主分片的数量只能在创建索引时定义且不能修改:如果主分片的数量在未来改变了,所有先前的路由值就失效了,文档也就永远找不到了。
所有的文档API(get、index、delete、bulk、update、mget)都接收一个routing参数,它用来自定义文档到分片的映射。自定义路由值可以确保所有相关文档——例如属于同一个人的文档——被保存在同一分片上。
例如,可以这样设置参数:
POST twitter/tweet?routing=kimchy
{
"user" : "kimchy",
"post_date" : "2009-11-15T14:12:12",
"message" : "trying out Elasticsearch"
}
主分片和复制分片如何交互
在文档确认存储到哪个主分片以后,接下来就是主分片将数据复制到复制分片的任务,为了阐述意图,我们假设有三个节点的集群。它包含一个叫做blogs的索引并拥有两个主分片。每个主分片有两个复制分片。相同的分片不会放在同一个节点上,所以我们的集群是这样的:
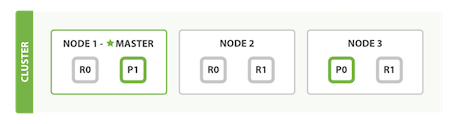
我们能够发送请求给集群中任意一个节点。每个节点都有能力处理任意请求。每个节点都知道任意文档所在的节点,所以也可以将请求转发到需要的节点。下面的例子中,我们将发送所有请求给Node 1,这个节点我们将会称之为请求节点(requesting node)。一般情况下,当我们发送请求,最好的做法是循环通过所有节点请求,这样可以平衡负载。
新建、索引和删除文档
新建、索引和删除请求都是写(write)操作,它们必须在主分片上成功完成才能复制到相关的复制分片上。
下面是在主分片和复制分片上成功新建、索引或删除一个文档必要的顺序步骤:
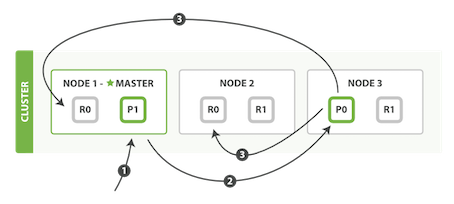
- 客户端给Node 1发送新建、索引或删除请求。
- 节点使用文档的_id确定文档属于分片0。它转发请求到Node 3,分片0位于这个节点上。
- Node 3在主分片上执行请求,如果成功,它转发请求到相应的位于Node 1和Node 2的复制节点上。当所有的复制节点报告成功,Node 3报告成功到请求的节点,请求的节点再报告给客户端。
客户端接收到成功响应的时候,文档的修改已经被应用于主分片和所有的复制分片。你的修改生效了。
有很多可选的请求参数允许你更改这一过程。你可能想牺牲一些安全来提高性能。这些选项很少使用因为Elasticsearch已经足够快。
注意:下面的参数只对ElasticSearch 5.0以下的版本有效,在ElasticSearch 5.0之后貌似使用wait_for_active_shards代替了consistency。所以之前的参数了解即可,实际可以参考:Create Index—Wait For Active Shards。
replication(注意在ElasticSearch 5.0开始被废弃)
复制默认的值是sync。这将导致主分片得到复制分片的成功响应后才返回。
如果你设置replication为async,请求在主分片上被执行后就会返回给客户端。它依旧会转发请求给复制节点,但你将不知道复制节点成功与否。
上面的这个选项不建议使用。默认的sync复制允许Elasticsearch强制反馈传输。async复制可能会因为在不等待其它分片就绪的情况下发送过多的请求而使Elasticsearch过载。
consistency(注意在ElasticSearch 5.0开始被废弃)
默认主分片在尝试写入时需要规定数量(quorum)或过半的分片(可以是主节点或复制节点)可用。这是防止数据被写入到错的网络分区。规定的数量计算公式如下:
int( (primary + number_of_replicas) / 2 ) + 1
consistency允许的值为one(只有一个主分片),all(所有主分片和复制分片)或者默认的quorum或过半分片。
注意number_of_replicas是在索引中的的设置,用来定义复制分片的数量,而不是现在活动的复制节点的数量。如果你定义了索引有3个复制节点,那规定数量是:
int( (primary + 3 replicas) / 2 ) + 1 = 3
但如果你只有2个节点,那你的活动分片不够规定数量,也就不能索引或删除任何文档。
注意:
- 新索引默认有1个复制分片,这意味着为了满足
quorum的要求需要两个活动的分片。当然,这个默认设置将阻止我们在单一节点集群中进行操作。为了避开这个问题,规定数量只有在number_of_replicas大于一时才生效。 - 一个疑惑,是不是
primary值一直都只会是1???
wait_for_active_shards(新参数)
在ElasticSearch 5.0中可以用wait_for_active_shards参数表示:等待活动的分片,具体的值和consistency类似,下面用wait_for_active_shards演示一个实际使用的例子。
开始我们先设置一个新的索引:
PUT /active
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 3
}
}
我们默认先只打开两个节点,等下我们设置wait_for_active_shards值为3,按照上面讲解的我们如果只有两个节点,那么活动的分片最多也就2个,所以是不够的,会等待新的活动节点的到来。(这里我们只能通过少一个节点的方法演示缺少活动分片,因为我们不方便演示出让某个分片处于不活动的状态。)


因为我们只有两个节点,所以活动的分片最多也只有两个。下面我们执行文档存储操作,并且添加参数wait_for_active_shards=3:
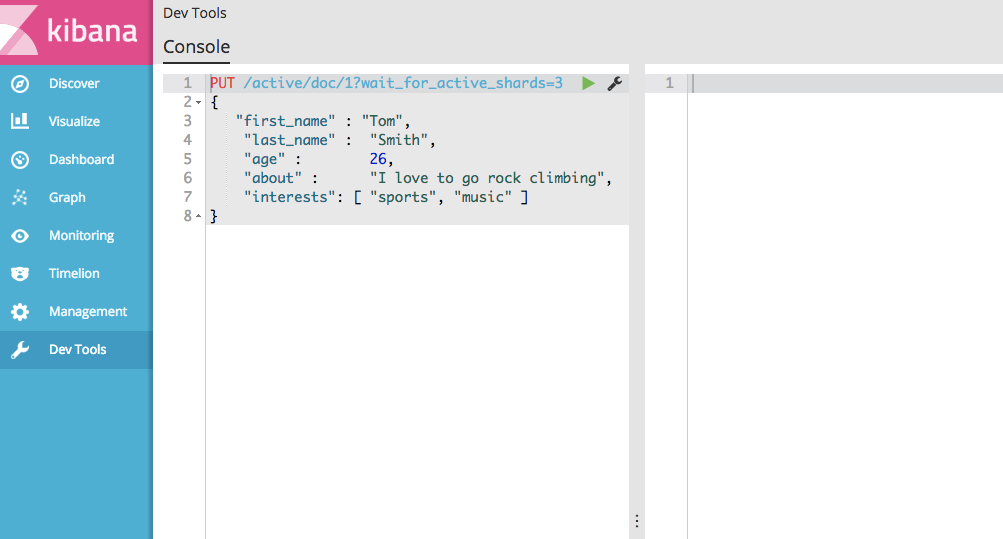
可以发现,确实开始处于等待状态,没有马上返回结果,下面我们参数开启第三个节点,让索引拥有第三个活动分片:
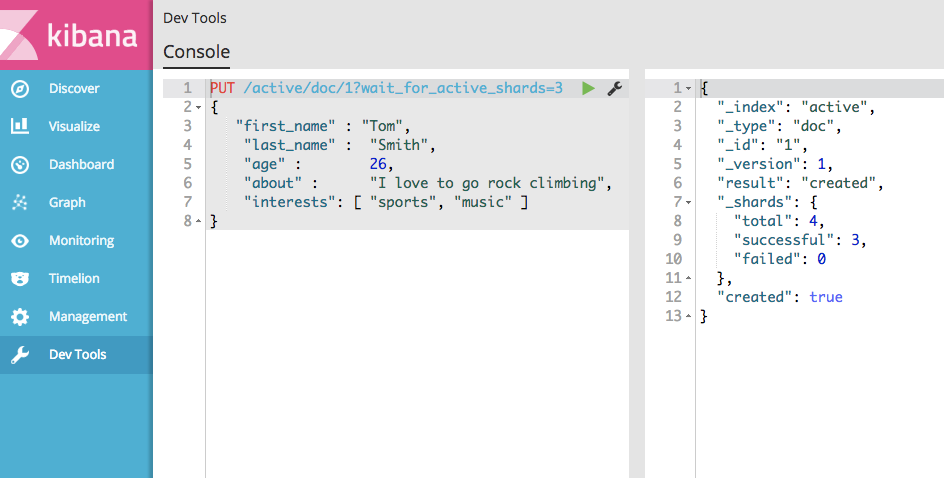

可以看到一旦我们的节点开启,文档的存储马上就会返回成功。
教程中关于这部分网上很多朋友不太理解,我们可以通过查看官方文档和实践去证明自己的想法,希望上面的分析大家可以理解一些,还有不对的地方大家可以一起学习。
timeout
当分片副本不足时会怎样?Elasticsearch会等待更多的分片出现。默认等待一分钟。如果需要,你可以设置timeout参数让它终止的更早:100表示100毫秒,30s表示30秒。
检索文档
文档能够从主分片或任意一个复制分片被检索。

下面我们罗列在主分片或复制分片上检索一个文档必要的顺序步骤:
- 客户端给Node 1发送get请求。
- 节点使用文档的_id确定文档属于分片0。分片0对应的复制分片在三个节点上都有。此时,它转发请求到Node 2。
- Node 2返回文档(document)给Node 1然后返回给客户端。
对于读请求,为了平衡负载,请求节点会为每个请求选择不同的分片——它会循环所有分片副本(包括主分片)。
可能的情况是,一个被索引的文档已经存在于主分片上却还没来得及同步到复制分片上。这时复制分片会报告文档未找到,主分片会成功返回文档。一旦索引请求成功返回给用户,文档则在主分片和复制分片都是可用的。
局部更新文档
update API结合了之前提到的读和写的模式。

下面我们罗列执行局部更新必要的顺序步骤:
- 客户端给Node 1发送更新请求。
- 它转发请求到主分片所在节点Node 3。
- Node 3从主分片检索出文档,修改_source字段的JSON,然后在主分片上重建索引。如果有其他进程修改了文档,它以
retry_on_conflict设置的次数重复步骤3,都未成功则放弃。 - 如果Node 3成功更新文档,它同时转发文档的新版本到Node 1和Node 2上的复制节点以重建索引。当所有复制节点报告成功,Node 3返回成功给请求节点,然后返回给客户端。
updateAPI还接受routing、replication(弃)、consistency(弃)和timout参数。
基于文档的复制
当主分片转发更改给复制分片时,并不是转发更新请求,而是转发整个文档的新版本。记住这些修改转发到复制节点是异步的,它们并不能保证到达的顺序与发送相同。如果Elasticsearch转发的仅仅是修改请求,修改的顺序可能是错误的,那得到的就是个损坏的文档。
多文档模式
mget和bulk API与单独的文档类似。差别是请求节点知道每个文档所在的分片。它把多文档请求拆成每个分片的对文档请求,然后转发每个参与的节点。
一旦接收到每个节点的应答,然后整理这些响应组合为一个单独的响应,最后返回给客户端。

下面我们将罗列通过一个mget请求检索多个文档的顺序步骤:
- 客户端向Node 1发送
mget请求。 - Node 1为每个分片构建一个多条数据检索请求,然后转发到这些请求所需的主分片或复制分片上。当所有回复被接收,Node 1构建响应并返回给客户端。
routing 参数可以被docs中的每个文档设置。

下面我们将罗列使用一个bulk执行多个create、index、delete和update请求的顺序步骤:
- 客户端向Node 1发送
bulk请求。 - Node 1为每个分片构建批量请求,然后转发到这些请求所需的主分片上。
- 主分片一个接一个的按序执行操作。当一个操作执行完,主分片转发新文档(或者删除部分)给对应的复制节点,然后执行下一个操作。一旦所有复制节点报告所有操作已成功完成,节点就报告success给请求节点,后者(请求节点)整理响应并返回给客户端。
bulk API还可以在最上层使用replication(弃)和consistency(弃)参数,routing参数则在每个请求的元数据中使用。
总结
以上就是关于在分布式系统中,每个分片的文档是被如何索引和查询的。虽然版本的更新有一些参数会更新,但是整体的内部实现应该不会有太大的变化,分享一个学习方法,学习的时候把新旧的版本内容通过对比,不仅可以更好理解知识,而且可以加深印象。更何况旧的不会被很快淘汰,学了又何妨!
转载请注明出处。
作者:wuxiwei
出处:http://www.cnblogs.com/wxw16/p/6192549.html
ElasticSearch 5学习(8)——分布式文档存储(wait_for_active_shards新参数分析)的更多相关文章
- ElasticSearch权威指南学习(分布式文档存储)
路由文档到分片 当你索引一个文档,它被存储在单独一个主分片上.Elasticsearch是如何知道文档属于哪个分片的呢?当你创建一个新文档,它是如何知道是应该存储在分片1还是分片2上的呢? 进程不能是 ...
- ElasticSearch 学习记录之 分布式文档存储往ES中存数据和取数据的原理
分布式文档存储 ES分布式特性 屏蔽了分布式系统的复杂性 集群内的原理 垂直扩容和水平扩容 真正的扩容能力是来自于水平扩容–为集群添加更多的节点,并且将负载压力和稳定性分散到这些节点中 ES集群特点 ...
- ElasticSearch文档及分布式文档存储
1.什么是文档? 文档由索引(_index),类型(_type),唯一标识(_id) 组成,我们为 _index(索引) 分配相关逻辑地址分片,该索引下的数据会根据索引以及类型计算哈希来分配数据存储的 ...
- elasticsearch 基础 —— 分布式文档存储原理
路由一个文档到一个分片中 当索引一个文档的时候,文档会被存储到一个主分片中. Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?当我们创建文档时,它如何决定这个文档应当被存储在分片 ...
- Elasticsearch 分布式文档存储
shard = hash(routing) % number_of_primary_shards决定文档在哪个分片上,routing 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值. ...
- 分布式文档存储数据库 MongoDB
MongoDB 详细介绍 MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的.他支持的数据结构非常松散,是类似json的bjson格式,因此可以 ...
- 分布式文档存储数据库之MongoDB基础入门
一.MongoDB简介 MongoDB是用c++语言开发的一款易扩展,易伸缩,高性能,开源的,schema free 的基于文档的nosql数据库:所谓nosql是指不仅仅是sql的意思,它拥有部分s ...
- 分布式文档存储数据库之MongoDB索引管理
前文我们聊到了MongoDB的简介.安装和对collection的CRUD操作,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/13941797.html:今天我 ...
- 分布式文档存储数据库之MongoDB副本集
前文我们聊到了mongodb的索引的相关作用和介绍以及索引的管理,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/13950287.html:今天我们来聊下mon ...
随机推荐
- Unity3d学习 相机的跟随
最近在写关于相机跟随的逻辑,其实最早接触相机跟随是在Unity官网的一个叫Roll-a-ball tutorial上,其中简单的涉及了关于相机如何跟随物体的移动而移动,如下代码: using Unit ...
- webpack之傻瓜式教程
接触webpack也有挺长一段时间了,公司的项目也是一直用着webpack在打包处理,但前几天在教新人的情况下,遇到了一个问题,那就是:尽管网上的webpack教程满天飞,但是却很难找到一个能让新人快 ...
- 制作类似ThinkPHP框架中的PATHINFO模式功能
一.PATHINFO功能简述 搞PHP的都知道ThinkPHP是一个免费开源的轻量级PHP框架,虽说轻量但它的功能却很强大.这也是我接触学习的第一个框架.TP框架中的URL默认模式即是PathInfo ...
- 分享一个SQLSERVER脚本(计算数据库中各个表的数据量和每行记录所占用空间)
分享一个SQLSERVER脚本(计算数据库中各个表的数据量和每行记录所占用空间) 很多时候我们都需要计算数据库中各个表的数据量和每行记录所占用空间 这里共享一个脚本 CREATE TABLE #tab ...
- 【夯实PHP基础】UML序列图总结
原文地址 序列图主要用于展示对象之间交互的顺序. 序列图将交互关系表示为一个二维图.纵向是时间轴,时间沿竖线向下延伸.横向轴代表了在协作中各独立对象的类元角色.类元角色用生命线表示.当对象存在时,角色 ...
- 【代码笔记】iOS-获得当前的月的天数
一,代码. #import "ViewController.h" @interface ViewController () @end @implementation ViewCon ...
- SVN的使用
- Ajax.BeginForm方法 参数
感谢博主 http://www.cnblogs.com/zzgblog/p/5454019.html toyoung 在Asp.Net的MVC中的语法,在Razor页面中使用,替代JQuery的Aja ...
- NYOJ 954
首先观察: 2! = 2×1 = (2)10 = (10)2, 则第一个1是第2位,2!有1个质因数23! = 3×2×1 ...
- 钉钉开放平台demo调试异常问题解决:hostname in certificate didn't match
今天研究钉钉的开放平台,结果一个demo整了半天,这帮助系统写的也很难懂.遇到两个问题: 1.首先是执行demo时报unable to find valid certification path to ...