<Django> 第三方扩展
1.富文本编辑器
tinymce为例
安装
- pip install django-tinymce
在settings.py中的配置
配置应用
- INSTALLED_APPS = [
- 'django.contrib.admin',
- 'django.contrib.auth',
- 'django.contrib.contenttypes',
- 'django.contrib.sessions',
- 'django.contrib.messages',
- 'django.contrib.staticfiles',
- 'booktest',
- 'tinymce',
- ]
配置设定(主题和大小等)----在settings.py的最后面加
- TINYMCE_DEFAULT_CONFIG = {
- 'theme': 'advanced',
- 'width': 600,
- 'height': 400,
- }
根目录的urls.py中配置url
- url(r'^tinyme/', include('tinymce.urls')),
models.py中定义模型类
- from django.db import models
- from tinymce.models import HTMLField
- # Create your models here.
- class Test1(models.Model):
- content = HTMLField()
迁移
- python manage.py makemigrations
生成表
- python manage.py migrate
表结构(longtext类型)
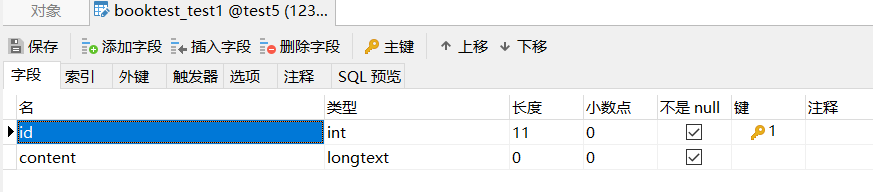
admin.py中完成注册
- from .models import *
- admin.site.register(Test1)
创建超级管理员,前面创建过(略)
在admin中可以看到(成功呈现)
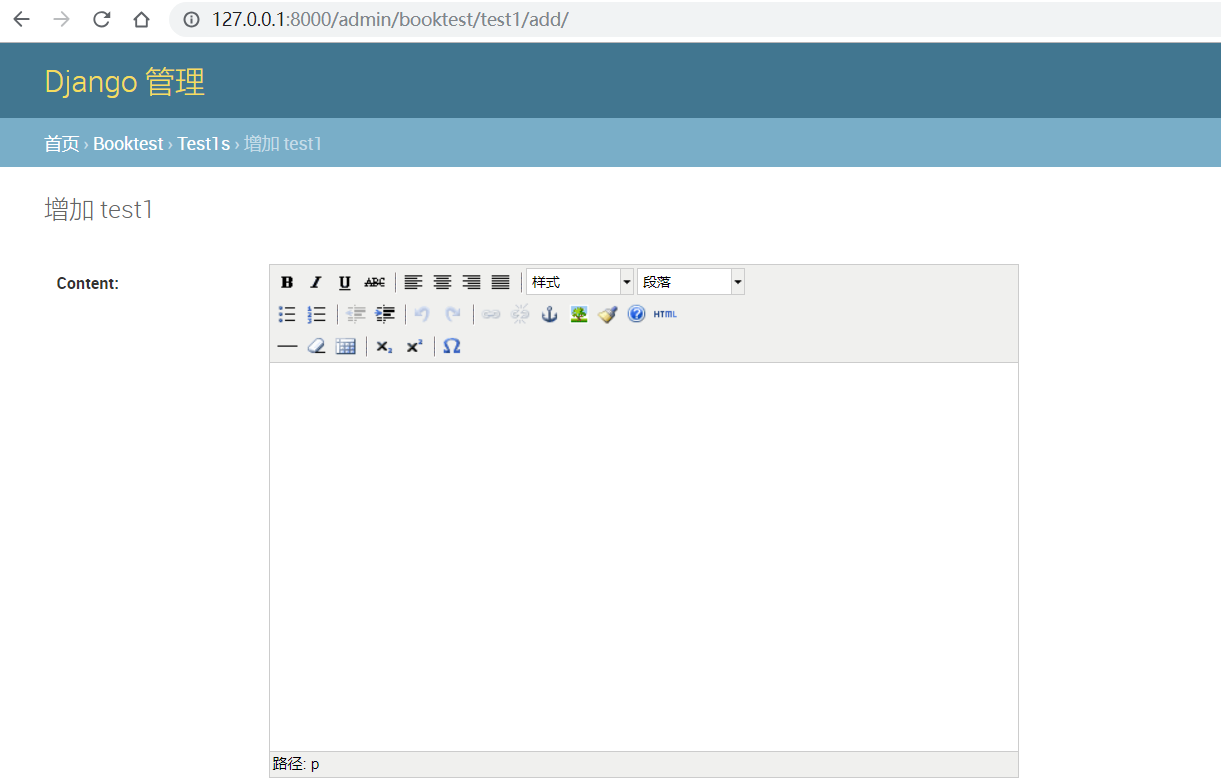
实际上就是HTML
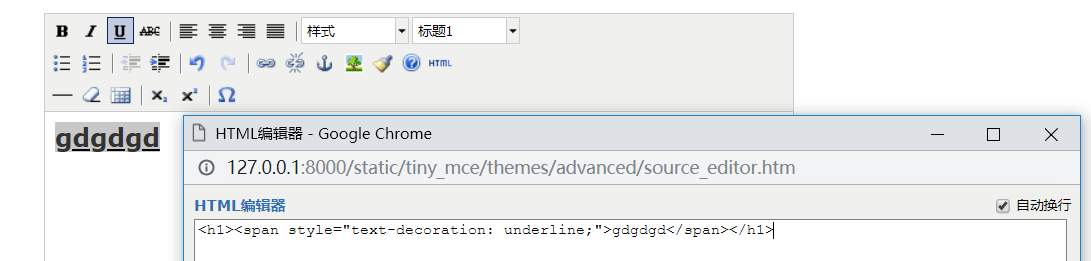
在视图中使用
views.py
- from django.shortcuts import render
- from django.http import HttpResponse
- from django.conf import settings
- import os
- from .models import *
- from django.core.paginator import *
- # Create your views here.
- # 富文本编辑器
- def htmlEditor(request):
- return render(request,'booktest/htmlEditor.html')
- def htmlEditorHandle(request):
- html = request.POST['hcontent']
- # 找到id=1的值
- # test1 = Test1.objects.get(pk=1)
- # 增加一条数据
- test1 = Test1()
- # 改写
- test1.content = html
- # 写进数据库
- test1.save()
- context = {'content':html}
- return render(request,'booktest/htmlShow.html',context=context)
urls.py
- url(r'^htmlEditor/$', views.htmlEditor),
- url(r'^htmlEditorHandle/$', views.htmlEditorHandle),
在静态文件中对应的JS文件
这个文件在安装目录的位置

htmlEditor.html
- <!DOCTYPE html>
- <html lang="zh-CN">
- <head>
- <meta charset="UTF-8">
- <meta name="viewport" content="width=device-width, initial-scale=1">
- <title>htmlEditor</title>
- <script type="text/javascript" src='/static/tiny_mce/tiny_mce.js'></script>
- <script type="text/javascript">
- {# 初始化,settings.py中设定的决定admin中的大小 #}
- tinyMCE.init({
- 'mode':'textareas',
- 'theme':'advanced',
- 'width':400,
- 'height':100
- });
- </script>
- </head>
- <body>
- <form method="post" action="/htmlEditorHandle/">
- {# csrf保护,加这个标签就行 #}
- {% csrf_token %}
- <input type="text" name="hname">
- <br>
- {# 富文本,替换这个textarea #}
- <textarea name='hcontent'>富文本编辑器在这</textarea>
- <br>
- <input type="submit" value="提交">
- </form>
- </body>
- </html>
htmlShow.html
- <!DOCTYPE html>
- <html lang="zh-CN">
- <head>
- <meta charset="UTF-8">
- <meta name="viewport" content="width=device-width, initial-scale=1">
- <title>Title</title>
- </head>
- <body>
- {# 转义后的结果 #}
- {{ content|safe }}
- </body>
- </html>
效果:
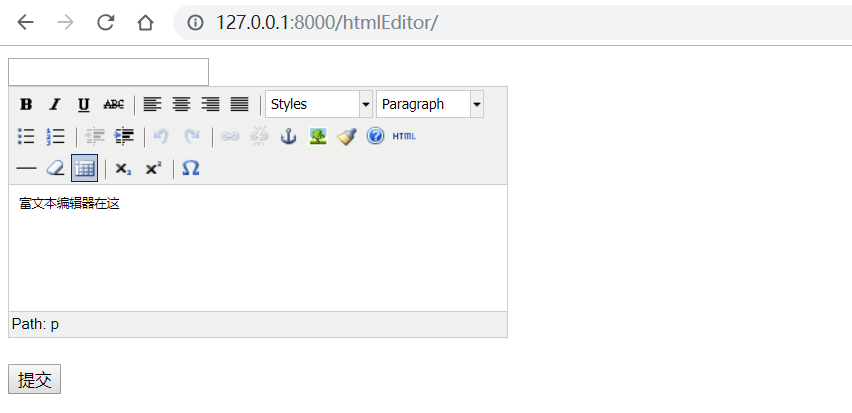
提交
2 缓存
短时间内不发生变化
- 对于中等流量的网站来说,尽可能地减少开销是必要的。缓存数据就是为了保存那些需要很多计算资源的结果,这样的话就不必在下次重复消耗计算资源
- Django自带了一个健壮的缓存系统来保存动态页面,避免对于每次请求都重新计算
- Django提供了不同级别的缓存粒度:可以缓存特定视图的输出、可以仅仅缓存那些很难生产出来的部分、或者可以缓存整个网站
设置缓存
- 通过设置决定把数据缓存在哪里,是数据库中、文件系统还是在内存中
- 通过setting文件的CACHES配置来实现
- 参数TIMEOUT:缓存的默认过期时间,以秒为单位,这个参数默认是300秒,即5分钟;设置TIMEOUT为None表示永远不会过期,值设置成0造成缓存立即失效
缓存到本地
- CACHES={
- 'default': {
- 'BACKEND': 'django.core.cache.backends.locmem.LocMemCache',
- 'TIMEOUT': 60,
- }
- }
缓存到redis,默认采用1数据库
安装包
- pip install django-redis-cache
启动redis数据库,切换数据库1
- C:\Users\123>redis-cli
- 127.0.0.1:6379> select 1
- OK
- 127.0.0.1:6379[1]> keys *
- (empty list or set)
- 127.0.0.1:6379[1]>
settings.py设定
- CACHES = {
- "default": {
- "BACKEND": "redis_cache.cache.RedisCache",
- "LOCATION": "localhost:6379",
- 'TIMEOUT': 60,
- },
- }
views.py
- from django.shortcuts import render
- from django.http import HttpResponse
- from django.conf import settings
- import os
- from .models import *
- from django.core.paginator import *
- # 缓存的包
- from django.views.decorators.cache import cache_page
- # Create your views here.
- # 缓存60秒*15 = 15分钟
- @cache_page(60 * 15)
- def cache1(request):
- return HttpResponse('HELLO 1')
urls.py
- url(r'^cache1/$', views.cache1),
效果

数据库中效果(说明有东西缓存下来了)
- 127.0.0.1:6379[1]> keys *
- 1) ":1:views.decorators.cache.cache_page..GET.b8ae1c07a54f3e5305c8ec159f5ddea7.d41d8cd98f00b204e9800998ecf8427e.zh-Hans.Asia/Shanghai"
- 2) ":1:views.decorators.cache.cache_header..b8ae1c07a54f3e5305c8ec159f5ddea7.zh-Hans.Asia/Shanghai"
- 127.0.0.1:6379[1]> get :1:views.decorators.cache.cache_page..GET.b8ae1c07a54f3e5305c8ec159f5ddea7.d41d8cd98f00b204e9800998ecf8427e.zh-Hans.Asia/Shanghai
- "\x80\x04\x95x\x01\x00\x00\x00\x00\x00\x00\x8c\x14django.http.response\x94\x8c\x0cHttpResponse\x94\x93\x94)\x81\x94}\x94(\x8c\b_headers\x94}\x94(\x8c\x0ccontent-type\x94\x8c\x0cContent-Type\x94\x8c\x18text/html; charset=utf-8\x94\x86\x94\x8c\aexpires\x94\x8c\aExpires\x94\x8c\x1dThu, 09 May 2019 13:13:25 GMT\x94\x86\x94\x8c\rcache-control\x94\x8c\rCache-Control\x94\x8c\x0bmax-age=900\x94\x86\x94u\x8c\x11_closable_objects\x94]\x94\x8c\x0e_handler_class\x94N\x8c\acookies\x94\x8c\x0chttp.cookies\x94\x8c\x0cSimpleCookie\x94\x93\x94)\x81\x94\x8c\x06closed\x94\x89\x8c\x0e_reason_phrase\x94N\x8c\b_charset\x94N\x8c\n_container\x94]\x94C\aHELLO 1\x94aub."
- 127.0.0.1:6379[1]>
验证方法
修改views.py
- @cache_page(60 * 15)
- def cache1(request):
- return HttpResponse('HELLO 111')
效果不变(缓存成功)---直接从缓存lim

- 视图缓存与URL无关,如果多个URL指向同一视图,每个URL将会分别缓存
2.2缓存片段
views.py
- def cache1(request):
- # return HttpResponse('HELLO 111')
- return render(request,'booktest/cache1.html')
cache1.html
- {#加载模块#}
- {% load cache %}
- <!DOCTYPE html>
- <html lang="zh-CN">
- <head>
- <meta charset="UTF-8">
- <meta name="viewport" content="width=device-width, initial-scale=1">
- <title>Title</title>
- </head>
- <body>
- {# 缓存时间以秒为单位 #}
- {% cache 500 hello %}
- hello 2
- {% endcache %}
- </body>
- </html>
验证同上,这里就不验证了,方法1,看看redis数据库,方法2,修改缓存数据,看看视图会不会变
2.3 缓存值
- from django.shortcuts import render
- from django.http import HttpResponse
- from django.conf import settings
- import os
- from .models import *
- from django.core.paginator import *
- # 缓存的包
- from django.views.decorators.cache import cache_page
- # 缓存数据导入的包
- from django.core.cache import cache
- # Create your views here.
- # 缓存60秒*15 = 15分钟
- # @cache_page(60 * 15)
- def cache1(request):
- # return HttpResponse('HELLO 111')
- cache.set('key1','value1',600)
- context = cache.get('key1')
- context = {'key1':context}
- return render(request,'booktest/cache1.html',context=context)
cache1.html
- {#加载模块#}
- {% load cache %}
- <!DOCTYPE html>
- <html lang="zh-CN">
- <head>
- <meta charset="UTF-8">
- <meta name="viewport" content="width=device-width, initial-scale=1">
- <title>Title</title>
- </head>
- <body>
- {# 缓存时间以秒为单位 #}
- {% cache 500 hello %}
- hello 2
- <br>
- {{ key1 }}
- {% endcache %}
- </body>
- </html>
缓存值的操作
- from django.core.cache import cache
- 设置:cache.set(键,值,有效时间)
- 获取:cache.get(键)
- 删除:cache.delete(键)
- 清空:cache.clear()
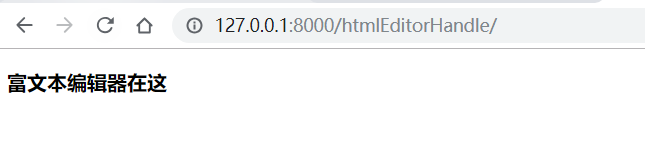
效果
3 全文检索
2个难点:查询和分词
分词高级:学习功能
- haystack:django的一个包,可以方便地对model里面的内容进行索引、搜索,设计为支持whoosh,solr,Xapian,Elasticsearc四种全文检索引擎后端,属于一种全文检索的框架(与搜索引擎交互)
- whoosh:纯Python编写的全文搜索引擎,虽然性能比不上sphinx、xapian、Elasticsearc等,但是无二进制包,程序不会莫名其妙的崩溃,对于小型的站点,whoosh已经足够使用(不需要进行二进制通信)
- jieba:一款免费的中文分词包,如果觉得不好用可以使用一些收费产品
安装三个依赖包
- pip install django-haystack
- pip install whoosh
- pip install jieba
在应用中添加
- INSTALLED_APPS = [
- 'django.contrib.admin',
- 'django.contrib.auth',
- 'django.contrib.contenttypes',
- 'django.contrib.sessions',
- 'django.contrib.messages',
- 'django.contrib.staticfiles',
- 'booktest',
- 'tinymce',
- 'haystack',
- ]
添加搜索引擎(在settings.py中添加)
- HAYSTACK_CONNECTIONS = {
- 'default': {
- # 默认搜索引擎
- 'ENGINE': 'haystack.backends.whoosh_cn_backend.WhooshEngine',
- # 路径+索引
- 'PATH': os.path.join(BASE_DIR, 'whoosh_index'),
- }
- }
- # 自动生成索引(应对增加修改删除)--作用:修改后自动更新索引
- HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
配置URL,在根级urls.py配置
- url(r'^search/', include('haystack.urls')),
应用目录下添加search_indexes.py文件
- # coding=utf-8
- from haystack import indexes
- from .models import Test1
- class Test1InfoIndex(indexes.SearchIndex, indexes.Indexable):
- # 检索这种类型的对象
- text = indexes.CharField(document=True, use_template=True)
- def get_model(self):
- # 得到表
- return Test1
- def index_queryset(self, using=None):
- # 检索表中的哪些数据,在这里是全部数据
- return self.get_model().objects.all()
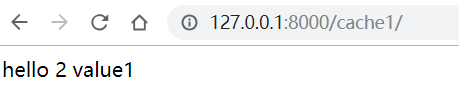
在目录“templates/search/indexes/应用名称/”下创建“模型类名称_text.txt”文件
在这里是test1_text.txt(检索的字段)
- {{ object.content }}
结构如下
在search目录下,建立search.html文件,用于展现检索的结果
结构如下

- <!DOCTYPE html>
- <html lang="zh-CN">
- <head>
- <meta charset="UTF-8">
- <meta name="viewport" content="width=device-width, initial-scale=1">
- <title>检索结果</title>
- </head>
- <body>
- {% if query %}
- <h3>搜索结果如下:</h3>
- {# 传入 query和page对象#}
- {% for result in page.object_list %}
- {{ result.object.id }}
- <br>
- {{ result.object.content|safe }}<br/>
- <hr>
- {% empty %}
- <p>啥也没找到</p>
- {% endfor %}
- {% if page.has_previous or page.has_next %}
- <div>
- {% if page.has_previous %}<a href="?q={{ query }}&page={{ page.previous_page_number }}">{% endif %}« 上一页{% if page.has_previous %}</a>{% endif %}
- |
- {% if page.has_next %}<a href="?q={{ query }}&page={{ page.next_page_number }}">{% endif %}下一页 »{% if page.has_next %}</a>{% endif %}
- </div>
- {% endif %}
- {% endif %}
- </body>
- </html>
在haystack的安装目录下新键ChineseAnalyzer.py文件
所在位置
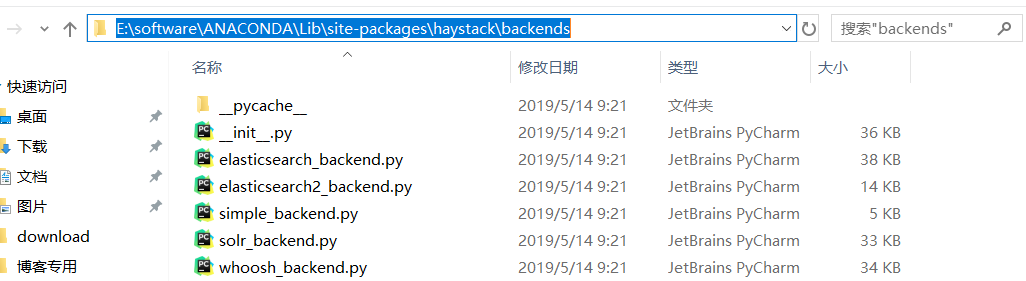
ChineseAnalyzer.py
- import jieba
- from whoosh.analysis import Tokenizer, Token
- class ChineseTokenizer(Tokenizer):
- def __call__(self, value, positions=False, chars=False,
- keeporiginal=False, removestops=True,
- start_pos=0, start_char=0, mode='', **kwargs):
- t = Token(positions, chars, removestops=removestops, mode=mode,
- **kwargs)
- seglist = jieba.cut(value, cut_all=True)
- for w in seglist:
- t.original = t.text = w
- t.boost = 1.0
- if positions:
- t.pos = start_pos + value.find(w)
- if chars:
- t.startchar = start_char + value.find(w)
- t.endchar = start_char + value.find(w) + len(w)
- yield t
- def ChineseAnalyzer():
- return ChineseTokenizer()
复制whoosh_backend.py文件,改名为whoosh_cn_backend.py
- from .ChineseAnalyzer import ChineseAnalyzer
- 查找
- analyzer=StemmingAnalyzer()
- 改为
- analyzer=ChineseAnalyzer()
生成索引
- python manage.py rebuild_index
会生成一个文件夹,结构如下
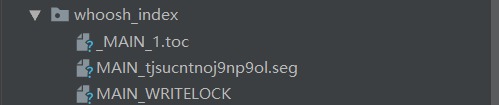
完成配置
在应用的urls.py中url
- url(r'^mysearch/$', views.mysearch),
views.py
- from django.shortcuts import render
- from django.http import HttpResponse
- from django.conf import settings
- import os
- from .models import *
- from django.core.paginator import *
- # 缓存的包
- from django.views.decorators.cache import cache_page
- # 缓存数据导入的包
- from django.core.cache import cache
- # Create your views here.
- # 全文检索+中文分词
- def mysearch(request):
- return render(request,'booktest/mysearch.html')
mysearch.py
- <!DOCTYPE html>
- <html lang="zh-CN">
- <head>
- <meta charset="UTF-8">
- <meta name="viewport" content="width=device-width, initial-scale=1">
- <title>mysearch</title>
- </head>
- <body>
- <form action="/search/" target="_blank" method="get">
- <input type="text" name="q">
- <input type="submit" value="查询">
- </form>
- </body>
- </html>
查询结果

检索结果
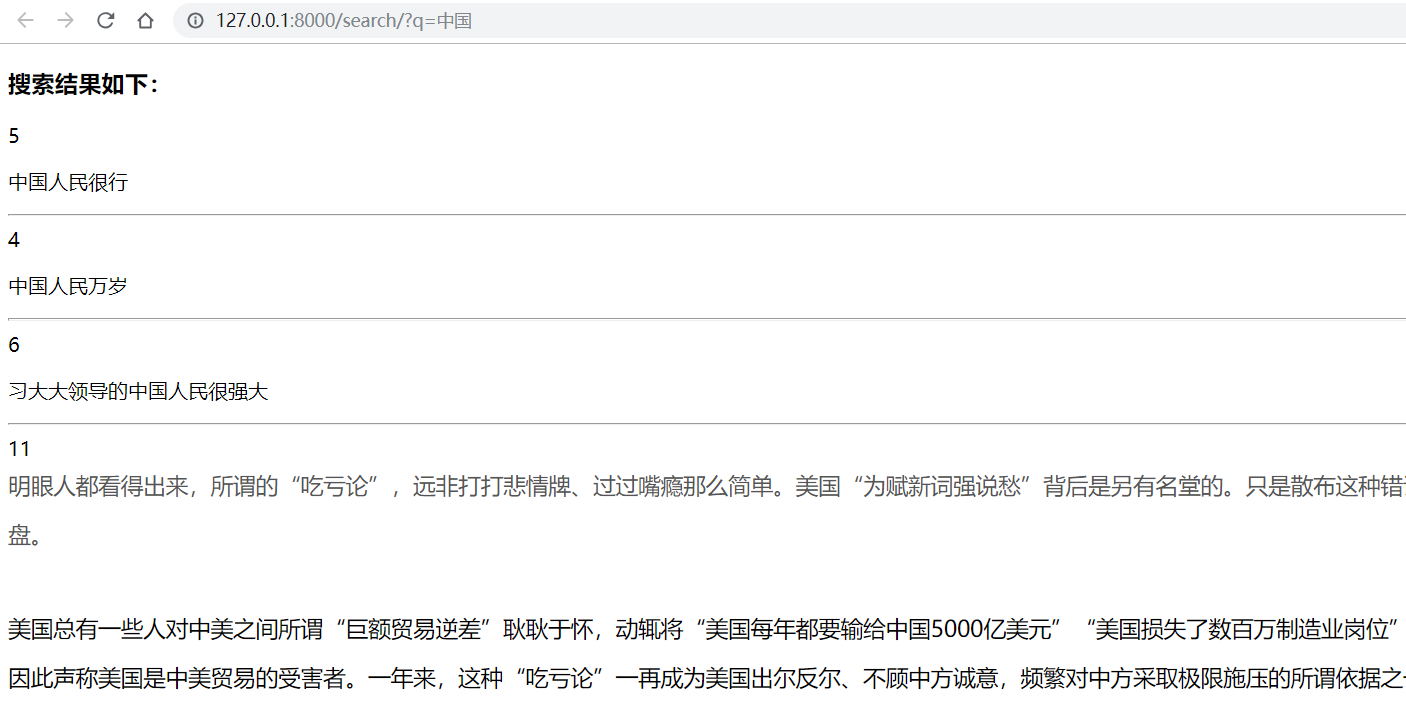
4 celery(未完待续)
开了一个新的进程处理耗时操作
作用:处理耗时的(等待时间长的);处理定时的
- 任务task:就是一个Python函数
- 队列queue:将需要执行的任务加入到队列中
- 工人worker:在一个新进程中,负责执行队列中的任务
- 代理人broker:负责调度,在布置环境中使用redis
安装
celery
- pip install celery==3.1.25
- pip install celery-with-redis==3.0
- pip install django-celery==3.1.17
把应用添加进去
- INSTALLED_APPS = (
- ...
- 'djcelery',
- }
在settings.py中添加
- # 引入celery包
- import djcelery
- djcelery.setup_loader()
- # redis数据库
- BROKER_URL = 'redis://127.0.0.1:6379/2'
- # 在哪个应用中使用
- CELERY_IMPORTS = ('booktest.task')
在应用下增加task.py文件(跟应用urls.py同级)---应用里面的任务
- import time
- from celery import task
- @task
- def sayhello():
- print('hello ...')
- time.sleep(5)
- print('world ...')
迁移
- python manage.py migrate
启动redis---这里已经做成服务,自动启动了
启动worker
- python manage.py celery worker --loglevel=info
报错
- AttributeError: type object 'BaseCommand' has no attribute 'option_list'
找到base.py文件将第60行注释掉
路径

- # options = BaseCommand.option_list
还是报错
- AttributeError: type object 'CeleryCommand' has no attribute 'options'
版本不兼容,之后再去弄吧,先放在这
<Django> 第三方扩展的更多相关文章
- 让时间处理简单化 【第三方扩展类库org.apache.commons.lang.time】
JAVA的时间日期处理一直是一个比较复杂的问题,大多数程序员都不能很轻松的来处理这些问题.首先Java中关于时间的类,从 JDK 1.1 开始,Date的作用很有限,相应的功能已由Calendar与D ...
- laravel中的自定义函数的加载和第三方扩展库加载
l 1. 创建文件 app/Helpers/functions.php <?php // 示例函数 function foo() { return "foo"; } 2. 修 ...
- WeUI教程/第三方扩展及其他UI框架对比
WeUI 是一套同微信原生视觉体验一致的基础样式库,由微信官方设计团队为微信内网页和微信小程序量身设计,令用户的使用感知更加统一.包含button.cell.dialog. progress. toa ...
- Django视图扩展类
Django视图扩展类 扩展类必须配合GenericAPIView使用扩展类内部的方法,在调用序列化器时,都是使用get_serializer 需要自定义get.post等请求方法,内部实现调用扩展类 ...
- django 高级扩展-中间件-上传图片-分页-富文本-celery
""" django 高级扩展 一.静态文件 1.css,js,json,图片,字体等 2.配置setting,在最底下设置静态文件目录,写入下面代码 #配置静态文件目录 ...
- python第三方扩展库及不同类型的测试需安装相对应的第三方库总结
如何安装第三方库 1.通过python的第三方仓库pypi中查找想要的第三方库 pypi地址:https://pypi.python.org/pypi pip是一个安装和管理Python包的工具,通过 ...
- Django中扩展Paginator实现分页
Reference:https://my.oschina.net/kelvinfang/blog/134342 Django中已经实现了很多功能,基本上只要我们需要的功能,都能够找到相应的包.要在Dj ...
- Django组件扩展 总结
1. Form组件扩展: 验证用户输入 obj = Form(reuest,POST,request.FILES) if obj.is_valid(): obj.clean_data else: ob ...
- [py]django第三方分页器django-pure-pagination实战
第三方分页模块: django-pure-pagination 是基于django的pagination做的一款更好用的分页器 参考 配置django-pure-pagination模块 安装 pip ...
随机推荐
- ArrayList集合二
集合的遍历 通过集合遍历,得到集合中每个元素,这是集合中最常见的操作.集合的遍历与数组的遍历很像,都是通过索引的方式,集合遍历方式如下 13 import java.util.ArrayList; 1 ...
- PHP ftp_rename() 函数
定义和用法 ftp_rename() 函数重命名 FTP 服务器上的文件或目录. 如果成功,该函数返回 TRUE.如果失败,则返回 FALSE. 语法 ftp_rename(ftp_connectio ...
- 限时免费 GoodSync 10 同步工具【转】
一款不错的软件,正在开发本身的云盘,要是能够云执行任务就更好了! GoodSync 10是一种简单和可靠的文件备份和文件同步软件.它会自动分析.同步,并备份您的电子邮件.珍贵的家庭照片.联系人,.MP ...
- NX二次开发-通过点击按钮来控制显示工具条
NX9+VS2012 1.打开D:\Program Files\Siemens\NX 9.0\UGII\menus\ug_main.men 找到装配和PMI,在中间加上一段 TOGGLE_BUTTON ...
- Java-Class-C:org.springframework.http.HttpHeaders
ylbtech-Java-Class-C:org.springframework.http.HttpHeaders 1.返回顶部 1.1. import org.springframework.htt ...
- 2019 牛客多校第一场 C Euclidean Distance ?
题目链接:https://ac.nowcoder.com/acm/contest/881/C 题目大意 给定 m 和 n 个整数 ai,$-m \leq a_i \leq m$,求$\sum\limi ...
- MySQL基础管理
1.用户管理 1.用户的作用: 登录:管理相对应的库表 2.定义 定义用户名和白名单 all@'10.0.0.%' 命名用户名时,最好不要太长,要和业务相关 白名单类型: user@'10.0.0.5 ...
- Bootstrap3的响应式缩略图幻灯轮播效果设计
在线演示1 本地下载 HTML <div class="container"> <div class="col-md-12"> &l ...
- python脚本往redis加数据
#-*-coding:utf-8-*-from rediscluster import StrictRedisClusterimport pymysqlimport timeimport cProfi ...
- ie8以下不兼容h5新标签的解决方法
HTML5新添了一些语义化标签,他们能让代码语义化更直观易懂,有利于SEO优化.但是此HTML5新标签在IE6/IE7/IE8上并不能识别,需要进行JavaScript处理. 解决思路就是用js创建h ...