现代软件工程HW1:词频统计
作业详细要求:http://www.cnblogs.com/denghp83/p/8627840.html
基本功能
1. 统计文件的字符数(只需要统计Ascii码,汉字不用考虑,换行符不用考虑,'\0'不用考虑)(ascii码大小在[32,126]之间)
2. 统计文件的单词总数
3. 统计文件的总行数(任何字符构成的行,都需要统计)(不要只看换行符的数量,要小心最后一行没有换行符的情形)(空行算一行)
4. 统计文件中各单词的出现次数,输出频率最高的10个。
5. 对给定文件夹及其递归子文件夹下的所有文件进行统计
6. 统计两个单词(词组)在一起的频率,输出频率最高的前10个。
7. 在Linux系统下,进行性能分析,过程写到blog中(附加题)
注意:
a) 空格,水平制表符,换行符,均算字符
b) 单词的定义:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
英文字母:A-Z,a-z
字母数字符号:A-Z,a-z,0-9
分割符:空格,非字母数字符号
例如:”file123”是一个单词,”123file”不是一个单词。file,File和FILE是同一个单词。
如果两个单词只有最后的数字结尾不同,则认为是同一个单词,例如,windows,windows95和windows7是同一个单词,iPhone4和IPhone5是同一个单词,但是,windows和windows32a是不同的单词,因为他们不是仅有数字结尾不同
输出按字典顺序,例如,windows95,windows98和windows2000同时出现时,输出windows2000
单词长度只需要考虑[4, 1024],超出此范围的不用统计。
c)词组的定义:windows95 good, windows2000 good123,可以算是同一种词组。按照词典顺序输出。三词相同的情形,比如good123 good456 good789,根据定义,则是 good123 good123 这个词组出现了两次。
两个合法单词之间,出现一个非法字符串,比如:windows2000 abc good123,因为abc按照定义不是单词,因此这个词组其实是windows2000 good123,中间的abc当做分隔符看待。
good123 good456 good789这种情况,由于这三个单词与good123都是同一个词,最终统计结果是good123 good123这个词组出现了2次。
两个单词分属两行,也可以直接组成一个词组。统计词组,只看顺序上,是否相邻。
d) 输入文件名以命令行参数传入。需要遍历整个文件夹时,则要输入文件夹的路径。
e) 输出文件result.txt
characters: number
words: number
lines: number
<word>: number
<word>为文件中真实出现的单词大小写格式,例如,如果文件中只出现了File和file,程序不应当输出FILE,且<word>按字典顺序(基于ASCII)排列,上例中程序应该输出File: 2
f) 根据命令行参数判断是否为目录
g) 将所有文件中的词汇,进行统计,最终只输出一个整体的词频统计结果。
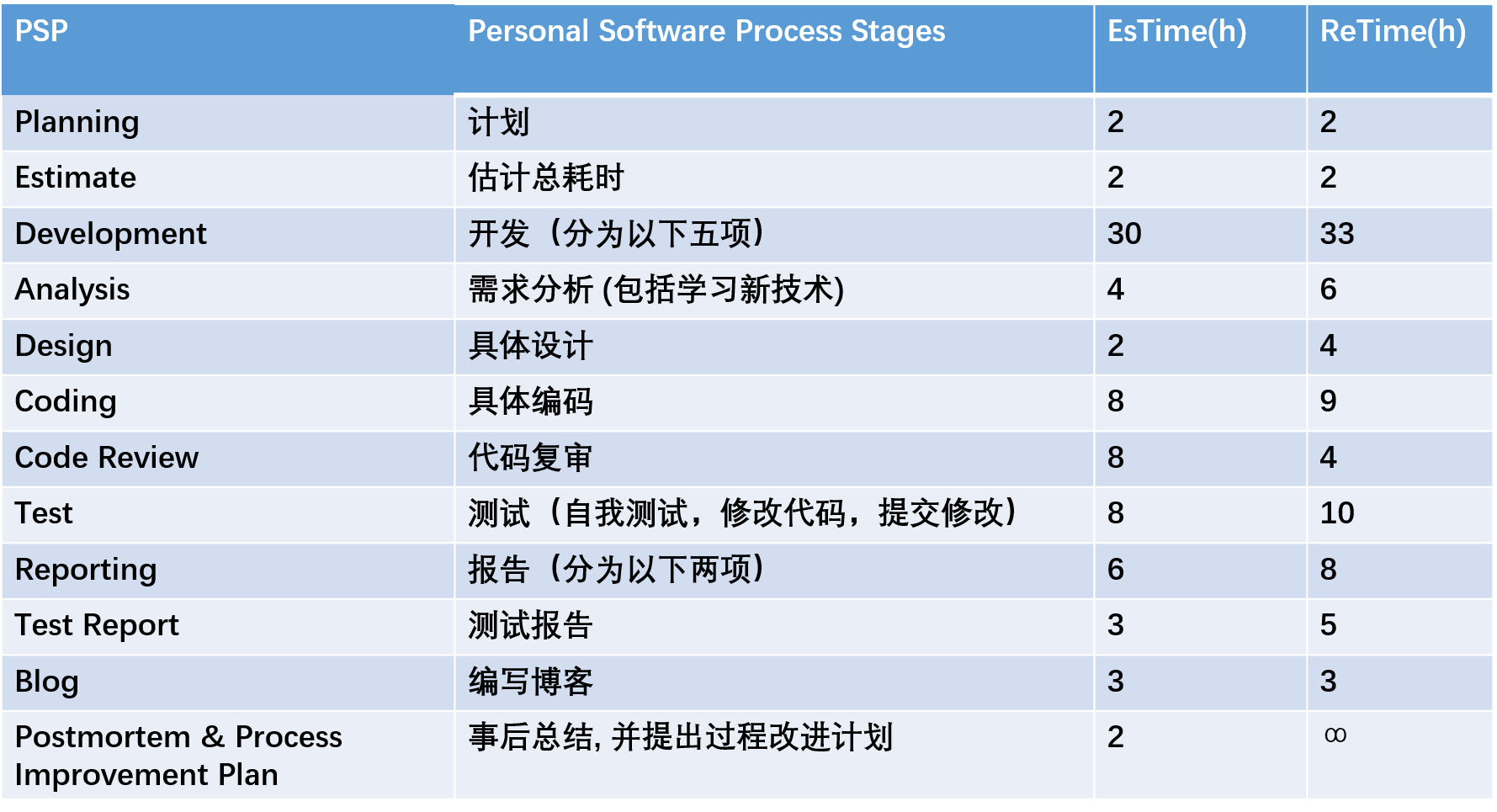
PSP表格:
一、需求分析
①从宏观到微观,先忽略对一个文件的具体操作,发现作业要求中的字符统计等功能均需要对文件夹中的每个文件进行遍历,故优先实现文件夹遍历读取文件功能。采用深度优先方式遍历文件,具体方法参考 https://blog.csdn.net/qq289665044/article/details/48623325 。
②考虑细节问题,对文件调用函数进行读操作,读入字符进行处理。考虑到C++中getline较方便,初步决定使用getline获取文件中一行行的内容,再进行相应处理。
③考虑遍历需求,应当设定结构体并进行相关遍历。考虑到需求中“既要保留字典序最小的原型,又要忽略大小写和无关后缀进行统计”,结构体中应该至少包含原型、重复次数、标准型三个变量。进一步考虑发现,对一组n个标准型相同的单词,有n-1个其实没必要保存,故考虑通过unordered_map实现,将标准型作为KEY,可以节省空间。
④考虑测试需求,应学习单元测试、Ubuntu下测试等知识。
⑤综合上述需求,需要学习C++相关内容,包括文件操作、输出、自带命令行编译等,需要学习vs下性能测试,还需要熟悉linux下的各种操作。
二、具体设计
①设计两个类:Word和Phrase,Word中包含重复次数、原型,Phrase中包含重复次数、词1、词2,用作数据存储。词和字符串的处理一律采用string类。
②配置两个全局Map,其KEY为toupper标准化的单词原型,例如ABcde234的标准型是ABCED,abdfe./.qwert 的标准型是 ABDFE QWERT,用作全局存储。Phrase的KEY设计为“词1”+“ ”+“词2”
③思路:遍历文件,逐行读入,调用Operate函数处理这一行字符串,按规矩存入和统计,再由排序函数按KEY值(标准型)排出存于Map中的TOP10。
④测试方法:设计空文件夹、一个文件、多个文件、文件夹中包含文件夹等等样例测试,并使用grof和vs中的性能测试进行调试。
三、具体编码
此处直接放上Windows版和Linux版的源码,其中Linux版参考了某赵姓大佬的建议和 https://blog.csdn.net/angle_birds/article/details/8503039.
Windows:
//#include "WordsFrequency.h"
#include<iostream>
#include<unordered_map>
#include<string>
#include<fstream>
#include<algorithm>
#include<time.h>
#include<iomanip>
#include<io.h> //if Windows, use this and dfsFolder()
//#include<dirent.h>//if linux, use this and traverseFile() and using namespace std;
class Word {
public:
string value;
int repeatTimes;
public:
Word();
~Word();
};
Word::Word() {
this->value = "";
this->repeatTimes = ;
}
Word::~Word(){} class Phrase {
public:
string firstWord;
string secondWord;
int repeatTimes;
public:
Phrase();
~Phrase();
};
Phrase::Phrase() {
this->firstWord = "";
this->secondWord = "";
this->repeatTimes = ;
}
Phrase::~Phrase(){} void dfsFolder(string folderPath, int depth);
int wordType(char n);
bool IsChar(char n);
void wordOperate(string &str);
void wordMapInsert(string word);
vector<Word> wordTopTen();
void phraseMapInsert(Phrase phrase);
vector<Phrase> phraseTopTen();
//above: something move in from WordsFrequency.h string strNew, strOld;
int charSum=,lineSum=,wordSum=;
unordered_map<string, Word> wordMap;
unordered_map<string, Phrase> phraseMap; //dfs traverse files in Windows, consult https://blog.csdn.net/qq289665044/article/details/48623325
void dfsFolder(string folderPath, int depth)
{
ifstream infile;
string strReg;
_finddata_t fileInfo;
string strFind = folderPath + "/*.*";
long handle = _findfirst(strFind.c_str(), &fileInfo); //if fail
if (handle == -)
{
cout << "cannot match the folder path" << endl;
return ;
} do
{
//prevent to dfs files on its same depth(".") or from its root("..")
if (fileInfo.attrib == _A_SUBDIR){
int depthTemp = depth;
if (strcmp(fileInfo.name, ".") != && strcmp(fileInfo.name, "..") != )
dfsFolder(folderPath + '/' + fileInfo.name, depthTemp + );
}
else{
infile.open(folderPath + '/' + fileInfo.name, ios::in); while (getline(infile, strReg)) {
lineSum++;
wordOperate(strReg);
}
infile.close();
}
} while (!_findnext(handle, &fileInfo)); _findclose(handle);
} //traverseFile in Linux
/*
void listDir(char *path){
DIR *pDir;
struct dirent *ent;
int i = 0;
char childpath[512];
pDir = opendir(path);
memset(childpath, 0, sizeof(childpath));
while ((ent = readdir(pDir)) != NULL) {
if (ent->d_type & DT_DIR) {
if (strcmp(ent->d_name, ".") == 0 || strcmp(ent->d_name, "..") == 0)
continue;
sprintf(childpath, "%s/%s", path, ent->d_name);
listDir(childpath);
}
else
{
sprintf(childpath, "%s/%s", path, ent->d_name);
traverseFile(childpath);
}
}
}
*/ //judge wordType,1:alpha,2:symbol,0:others
int wordType(char n) {
if ((n >= && n <= )|| (n >= && n <= ) || (n >= && n <= )) {
if ((n >= && n <= ) || (n >= && n <= )) return ;
else return ;
}
else return ;
} //judge if n is a char.(ascii 32~126)
bool IsChar(char n) {
if (n >= && n <= ) return true;
return false;
} //when getline, operate the string and realize function:find Words' and Phrases' frequency.
void wordOperate(string &strx) {
Phrase phTemp;
size_t length = +strx.length();
int wordBegin, wordEnd;
bool flag = true; strx += " ";//avoid overflow or miss for(int i=;(size_t)i<length-;i++)
if (IsChar(strx[i])) charSum++;//------charSum---------- for (wordBegin = ; wordType(strx[wordBegin]) == && (size_t)wordBegin < length; wordBegin++) {
//if (IsChar(strx[wordBegin])) charSum++;
}//find the first alpha for (int it = wordBegin; strx[it] != '\0' && (size_t)it < length; it++) {
if (wordType(strx[it])==) {
for (wordEnd = wordBegin; wordEnd - wordBegin < && (size_t)wordEnd < length; wordEnd++) {
if (wordType(strx[wordEnd])!=) {
flag = false;
break;
}
}//when flag==false,it means the thing we find is NOT a word
if (wordEnd == length && wordEnd-wordBegin<) flag = false;//boundary condition if (flag == true) {
wordSum++;
strNew = strx.substr(wordBegin, it - wordBegin);
wordMapInsert(strNew); if (strOld != "") {
phTemp.firstWord = strOld;
phTemp.secondWord = strNew;
phraseMapInsert(phTemp);
}
strOld = strNew;
}//if it's a word, insert into wordMap; if it can be used to build a phrase,
//insert into phraseMap, update strNew
flag = true;
wordBegin = it + ;
}
}
} //deal with word and insert into wordMap
void wordMapInsert(string word) {
if (wordType(word[])!=) return; string wordTemp = word;
string::iterator it=word.end(); while (wordType(*it) != ) it--; //find alpha word.erase(it + , word.end());//throw tails transform(word.begin(), word.end(), word.begin(), ::toupper);
wordMap[word].repeatTimes++;//transform to upper and repeatTimes++ if (wordMap[word].value == "" || wordMap[word].value.compare(wordTemp)>)
wordMap[word].value = wordTemp;
//if the origin shape of word < value, update value=word.originShape
} //rank words by repeatTimes ,rank 10
vector<Word>wordTopTen() {
vector<Word> rankTen();//at first, rankTen[i].repeatTimes=0
unordered_map<string,Word>::iterator it = wordMap.begin(); //insert rank to select top10
for (; it != wordMap.end(); it++){
if (it->second.repeatTimes > rankTen[].repeatTimes) {
if (it->second.repeatTimes > rankTen[].repeatTimes)
rankTen.insert(rankTen.begin(), it->second);
else {
for (int i = ; i <= ; i++) {
if ((it->second.repeatTimes >= rankTen[i].repeatTimes) && (it->second.repeatTimes <= rankTen[i - ].repeatTimes)) {
rankTen.insert(rankTen.begin() + i, it->second);
break;
}
}
}
}
}
rankTen.erase(rankTen.begin() + , rankTen.end());
return rankTen;
} //deal with phrase and insert into phraseMap
void phraseMapInsert(Phrase phrase) {
if (wordType(phrase.firstWord[])!= || wordType(phrase.secondWord[])!=) return; Phrase phTemp;
phTemp.firstWord = phrase.firstWord;
phTemp.secondWord = phrase.secondWord; string::iterator it1 = phrase.firstWord.end();
string::iterator it2 = phrase.secondWord.end();
it1--; it2--;
while (wordType(*it1)!=) {
it1--;
};
while (wordType(*it2)!=) {
it2--;
};
phrase.firstWord.erase(it1 + , phrase.firstWord.end());
phrase.secondWord.erase(it2 + , phrase.secondWord.end());//同wordMapInsert中的操作,对两个单词分别去除尾部无关字符 transform(phrase.firstWord.begin(), phrase.firstWord.end(), phrase.firstWord.begin(), ::toupper);
transform(phrase.secondWord.begin(), phrase.secondWord.end(), phrase.secondWord.begin(), ::toupper);
string upperStr = phrase.firstWord +" "+ phrase.secondWord;
phraseMap[upperStr].repeatTimes++;//转化为大写,统计词频 if (phraseMap[upperStr].firstWord == "" || (phraseMap[upperStr].firstWord + phraseMap[upperStr].secondWord).compare(phTemp.firstWord + phTemp.secondWord)>) {
phraseMap[upperStr].firstWord = phTemp.firstWord;
phraseMap[upperStr].secondWord = phTemp.secondWord;
}//词组原型与map中存的value比较,留下字典序较小的
} //rank phrases by repeatTimes ,rank 10
vector<Phrase> phraseTopTen() {
vector<Phrase> rankTen();//at first, rankTen[i].repeatTimes=0
unordered_map<string, Phrase>::iterator it = phraseMap.begin(); //insert rank to select top10
for (; it != phraseMap.end();it++) {
if (it->second.repeatTimes > rankTen[].repeatTimes) {
if (it->second.repeatTimes > rankTen[].repeatTimes)
rankTen.insert(rankTen.begin(), it->second);
else {
for (int i = ; i <= ; i++) {
if ((it->second.repeatTimes >= rankTen[i].repeatTimes) && (it->second.repeatTimes <= rankTen[i - ].repeatTimes)) {
rankTen.insert(rankTen.begin() + i, it->second);
break;
}
}
}
}
} rankTen.erase(rankTen.begin() + , rankTen.end());
return rankTen;
} int main(int argc, char * argv[]) {
string fileName=argv[];
ofstream fout;
fout.open("result.out", ios::out);
//printf("please enter the filePath:\n");
//getline(cin, fileName);
cout << "wait a moment plz....." << endl; double timeSum;
clock_t tStart = clock();
dfsFolder(fileName, );
vector<Word> word= wordTopTen();
vector<Phrase> phrase = phraseTopTen();
timeSum =(double)(clock() - tStart) / CLOCKS_PER_SEC; //printf("NumOfChar:%d\n", charSum);
fout << "NumOfChar:" << charSum << endl;
//printf("NumOfWord:%d\n", wordSum);
fout << "NumOfWord:" << wordSum << endl;
//printf("NumOfLine:%d\n\n", lineSum);
fout << "NumOfLine:" << lineSum << endl;
//printf("Top10 Words:\n");
fout << "Top10 Words:" << endl; for (int i = ; i < ; i++) {
fout << setw() << word[i].value << " " << word[i].repeatTimes << endl;
}
fout << endl;
fout << "Top10 Phrases:" << endl;
for (int i = ; i < ; i++) {
fout << setw() << phrase[i].firstWord << " " << setw() << phrase[i].secondWord << " " << phrase[i].repeatTimes << endl;
}
fout << endl;
fout << "TimeSum:" << setprecision()<< timeSum <<"S"<< endl;
fout.close();
/*for (int i = 0; i < 10; i++) {
cout << setw(12)<< word[i].value <<" "<< word[i].repeatTimes << endl;
}
printf("\nTop10 Phrases:\n");
for (int i = 0; i < 10; i++) {
cout << setw(12)<< phrase[i].firstWord << " " <<setw(12)<< phrase[i].secondWord <<" "<<phrase[i].repeatTimes<< endl;
}
printf("\nTimeSum:%.2fs\n", timeSum);*/ }
Linux:
//#include "WordsFrequency.h"
#include<iostream>
#include<unordered_map>
#include<string>
#include<fstream>
#include<algorithm>
#include<time.h>
#include<iomanip>
#include<string.h>
//#include<io.h> //if Windows, use this and dfsFolder()
#include<dirent.h>//if linux, use this and traverseFile() and
#include<sys/stat.h> using namespace std;
class Word {
public:
string value;
int repeatTimes;
public:
Word();
~Word();
};
Word::Word() {
this->value = "";
this->repeatTimes = ;
}
Word::~Word(){} class Phrase {
public:
string firstWord;
string secondWord;
int repeatTimes;
public:
Phrase();
~Phrase();
};
Phrase::Phrase() {
this->firstWord = "";
this->secondWord = "";
this->repeatTimes = ;
}
Phrase::~Phrase(){} void dfsFolder(string folderPath, int depth);
void dfsFolderLinux(string folderPath);
int wordType(char n);
bool IsChar(char n);
void wordOperate(string &str);
void wordMapInsert(string word);
vector<Word> wordTopTen();
void phraseMapInsert(Phrase phrase);
vector<Phrase> phraseTopTen();
//above: something move in from WordsFrequency.h string strNew, strOld;
int charSum=,lineSum=,wordSum=;
unordered_map<string, Word> wordMap;
unordered_map<string, Phrase> phraseMap; //dfs traverse files in Windows, consult https://blog.csdn.net/qq289665044/article/details/48623325
/*
void dfsFolder(string folderPath, int depth)
{
ifstream infile;
string strReg;
_finddata_t fileInfo;
string strFind = folderPath + "/*.*";
long handle = _findfirst(strFind.c_str(), &fileInfo); //if fail
if (handle == -1)
{
cout << "cannot match the folder path" << endl;
return ;
} do
{
//prevent to dfs files on its same depth(".") or from its root("..")
if (fileInfo.attrib == _A_SUBDIR){
int depthTemp = depth;
if (strcmp(fileInfo.name, ".") != 0 && strcmp(fileInfo.name, "..") != 0)
dfsFolder(folderPath + '/' + fileInfo.name, depthTemp + 1);
}
else{
infile.open(folderPath + '/' + fileInfo.name, ios::in); while (getline(infile, strReg)) {
lineSum++;
wordOperate(strReg);
}
infile.close();
}
} while (!_findnext(handle, &fileInfo)); _findclose(handle);
}
*/ //traverseFile in Linux
void dfsFolderLinux(string folderPath)
{
DIR *dir_ptr;
struct stat infobuf;
struct dirent *direntp;
string name, temp;
ifstream infile;
string strReg;
if ((dir_ptr = opendir(folderPath.c_str())) == NULL)
perror("can not open");
else
{
while ((direntp = readdir(dir_ptr)) != NULL)
{
temp = "";
name = direntp->d_name;
if (name == "." || name == "..")
{
;
}
else
{
temp += folderPath;
temp += "/";
temp += name; if ((stat(temp.c_str(), &infobuf)) == -)
printf("#########\n");
if ((infobuf.st_mode & ) == )
{ dfsFolderLinux(temp);
}
else
{
infile.open(temp, ios::in);
while (getline(infile, strReg)) {
lineSum++;
wordOperate(strReg);
}
infile.close();
}
}
}
}
closedir(dir_ptr);
} //judge wordType,1:alpha,2:symbol,0:others
int wordType(char n) {
if ((n >= && n <= )|| (n >= && n <= ) || (n >= && n <= )) {
if ((n >= && n <= ) || (n >= && n <= )) return ;
else return ;
}
else return ;
} //judge if n is a char.(ascii 32~126)
bool IsChar(char n) {
if (n >= && n <= ) return true;
return false;
} //when getline, operate the string and realize function:find Words' and Phrases' frequency.
void wordOperate(string &strx) {
Phrase phTemp;
size_t length = +strx.length();
int wordBegin, wordEnd;
bool flag = true; strx += " ";//avoid overflow or miss for(int i=;(size_t)i<length-;i++)
if (IsChar(strx[i])) charSum++;//------charSum---------- for (wordBegin = ; wordType(strx[wordBegin]) == && (size_t)wordBegin < length; wordBegin++) {
//if (IsChar(strx[wordBegin])) charSum++;
}//find the first alpha for (int it = wordBegin; strx[it] != '\0' && (size_t)it < length; it++) {
if (wordType(strx[it])==) {
for (wordEnd = wordBegin; wordEnd - wordBegin < && (size_t)wordEnd < length; wordEnd++) {
if (wordType(strx[wordEnd])!=) {
flag = false;
break;
}
}//when flag==false,it means the thing we find is NOT a word
if (wordEnd == length && wordEnd-wordBegin<) flag = false;//boundary condition if (flag == true) {
wordSum++;
strNew = strx.substr(wordBegin, it - wordBegin);
wordMapInsert(strNew); if (strOld != "") {
phTemp.firstWord = strOld;
phTemp.secondWord = strNew;
phraseMapInsert(phTemp);
}
strOld = strNew;
}//if it's a word, insert into wordMap; if it can be used to build a phrase,
//insert into phraseMap, update strNew
flag = true;
wordBegin = it + ;
}
}
} //deal with word and insert into wordMap
void wordMapInsert(string word) {
if (wordType(word[])!=) return; string wordTemp = word;
string::iterator it=word.end(); while (wordType(*it) != ) it--; //find alpha word.erase(it + , word.end());//throw tails transform(word.begin(), word.end(), word.begin(), ::toupper);
wordMap[word].repeatTimes++;//transform to upper and repeatTimes++ if (wordMap[word].value == "" || wordMap[word].value.compare(wordTemp)>)
wordMap[word].value = wordTemp;
//if the origin shape of word < value, update value=word.originShape
} //rank words by repeatTimes ,rank 10
vector<Word>wordTopTen() {
vector<Word> rankTen();//at first, rankTen[i].repeatTimes=0
unordered_map<string,Word>::iterator it = wordMap.begin(); //insert rank to select top10
for (; it != wordMap.end(); it++){
if (it->second.repeatTimes > rankTen[].repeatTimes) {
if (it->second.repeatTimes > rankTen[].repeatTimes)
rankTen.insert(rankTen.begin(), it->second);
else {
for (int i = ; i <= ; i++) {
if ((it->second.repeatTimes >= rankTen[i].repeatTimes) && (it->second.repeatTimes <= rankTen[i - ].repeatTimes)) {
rankTen.insert(rankTen.begin() + i, it->second);
break;
}
}
}
}
}
rankTen.erase(rankTen.begin() + , rankTen.end());
return rankTen;
} //deal with phrase and insert into phraseMap
void phraseMapInsert(Phrase phrase) {
if (wordType(phrase.firstWord[])!= || wordType(phrase.secondWord[])!=) return; Phrase phTemp;
phTemp.firstWord = phrase.firstWord;
phTemp.secondWord = phrase.secondWord; string::iterator it1 = phrase.firstWord.end();
string::iterator it2 = phrase.secondWord.end();
it1--; it2--;
while (wordType(*it1)!=) {
it1--;
};
while (wordType(*it2)!=) {
it2--;
};
phrase.firstWord.erase(it1 + , phrase.firstWord.end());
phrase.secondWord.erase(it2 + , phrase.secondWord.end());//同wordMapInsert中的操作,对两个单词分别去除尾部无关字符 transform(phrase.firstWord.begin(), phrase.firstWord.end(), phrase.firstWord.begin(), ::toupper);
transform(phrase.secondWord.begin(), phrase.secondWord.end(), phrase.secondWord.begin(), ::toupper);
string upperStr = phrase.firstWord +" "+ phrase.secondWord;
phraseMap[upperStr].repeatTimes++;//转化为大写,统计词频 if (phraseMap[upperStr].firstWord == "" || (phraseMap[upperStr].firstWord + phraseMap[upperStr].secondWord).compare(phTemp.firstWord + phTemp.secondWord)>) {
phraseMap[upperStr].firstWord = phTemp.firstWord;
phraseMap[upperStr].secondWord = phTemp.secondWord;
}//词组原型与map中存的value比较,留下字典序较小的
} //rank phrases by repeatTimes ,rank 10
vector<Phrase> phraseTopTen() {
vector<Phrase> rankTen();//at first, rankTen[i].repeatTimes=0
unordered_map<string, Phrase>::iterator it = phraseMap.begin(); //insert rank to select top10
for (; it != phraseMap.end();it++) {
if (it->second.repeatTimes > rankTen[].repeatTimes) {
if (it->second.repeatTimes > rankTen[].repeatTimes)
rankTen.insert(rankTen.begin(), it->second);
else {
for (int i = ; i <= ; i++) {
if ((it->second.repeatTimes >= rankTen[i].repeatTimes) && (it->second.repeatTimes <= rankTen[i - ].repeatTimes)) {
rankTen.insert(rankTen.begin() + i, it->second);
break;
}
}
}
}
} rankTen.erase(rankTen.begin() + , rankTen.end());
return rankTen;
} int main(int argc, char * argv[]) {
string fileName=argv[];
ofstream fout;
fout.open("result.out", ios::out);
//printf("please enter the filePath:\n");
//getline(cin, fileName);
cout << "wait a moment plz....." << endl; double timeSum;
clock_t tStart = clock();
//dfsFolder(fileName, 0);
dfsFolderLinux(fileName);
vector<Word> word= wordTopTen();
vector<Phrase> phrase = phraseTopTen();
timeSum =(double)(clock() - tStart) / CLOCKS_PER_SEC; //printf("NumOfChar:%d\n", charSum);
fout << "NumOfChar:" << charSum << endl;
//printf("NumOfWord:%d\n", wordSum);
fout << "NumOfWord:" << wordSum << endl;
//printf("NumOfLine:%d\n\n", lineSum);
fout << "NumOfLine:" << lineSum << endl;
//printf("Top10 Words:\n");
fout << "Top10 Words:" << endl;
for (int i = ; i < ; i++) {
fout << setw() << word[i].value << " " << word[i].repeatTimes << endl;
}
fout << endl;
fout << "Top10 Phrases:" << endl;
for (int i = ; i < ; i++) {
fout << setw() << phrase[i].firstWord << " " << setw() << phrase[i].secondWord << " " << phrase[i].repeatTimes << endl;
}
fout << endl;
fout << "TimeSum:" << setprecision()<< timeSum <<"S"<< endl;
fout.close();
}
相关注释应该还算足够,其实原版中文注释更适当一些,考虑到需求里要求代码内不得含有中文字符,只好一一翻成英文。
四、测试
I 单元测试
采用VS中自带的单元测试框架进行测试,结合断点调试及变量观察,保证每个函数功能符合预期。
II 白盒测试
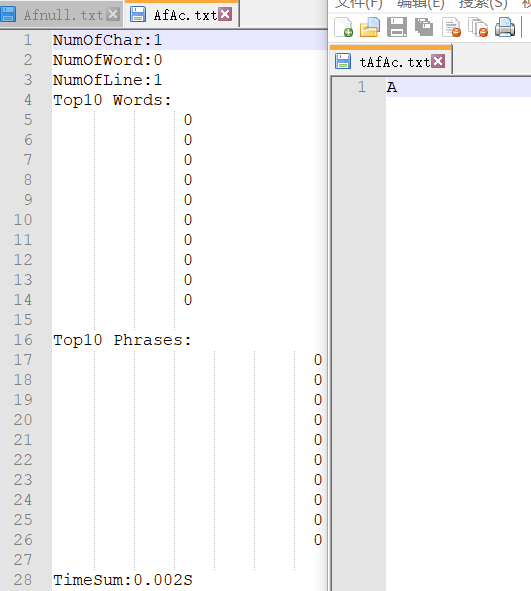
①读入空文件夹、只含一个空文件。
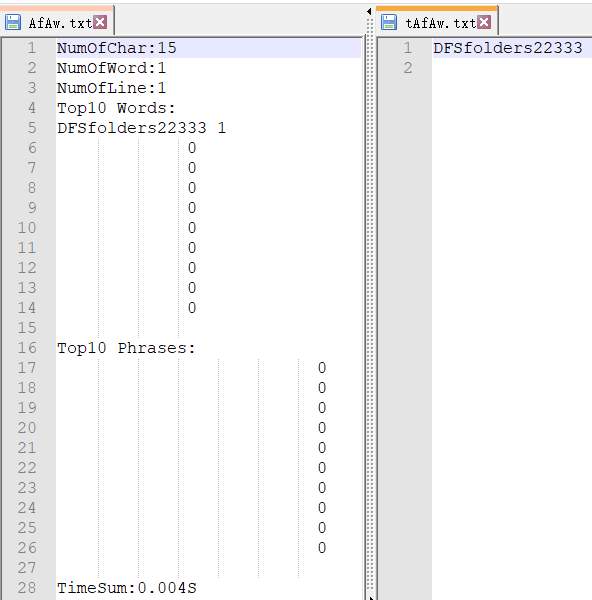
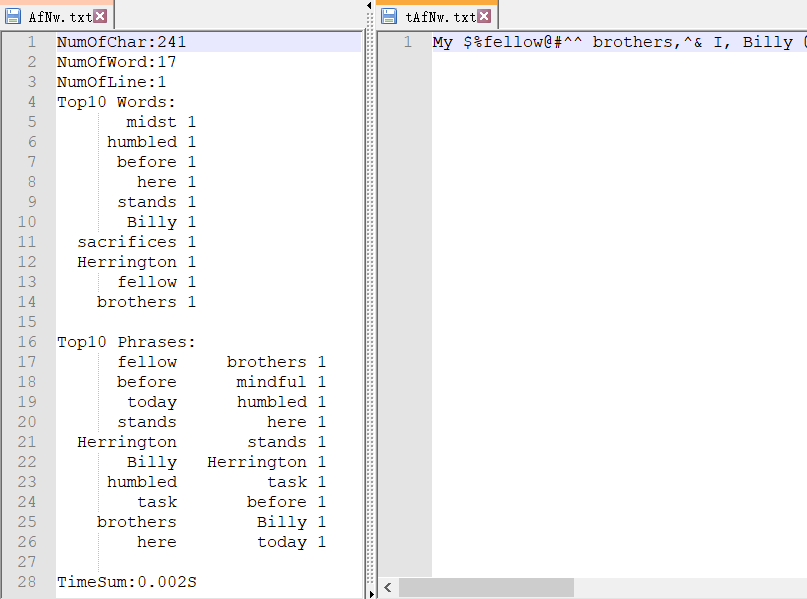
②读入含有单字符的文件、含有一个单词的文件、含有词组的文件。(右侧为用于测试的文件,带t前缀)
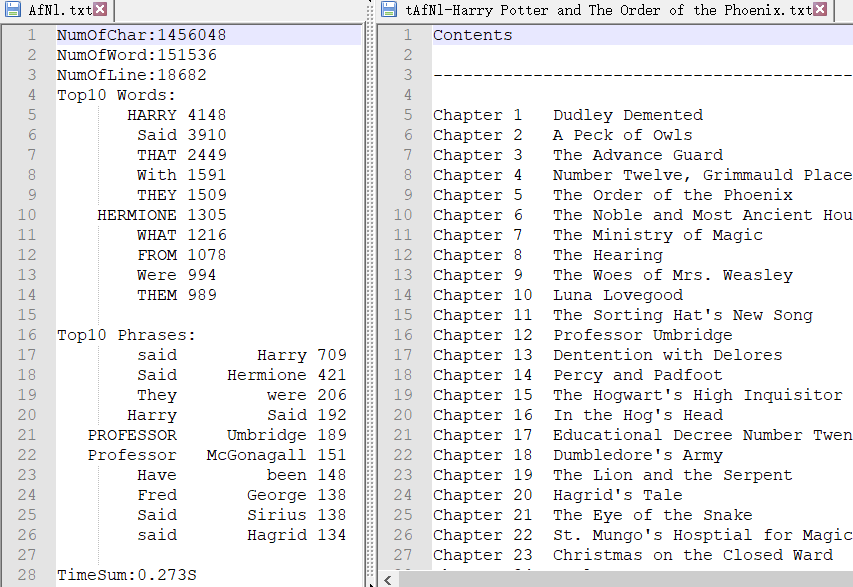
③读入含有多行的单文件。
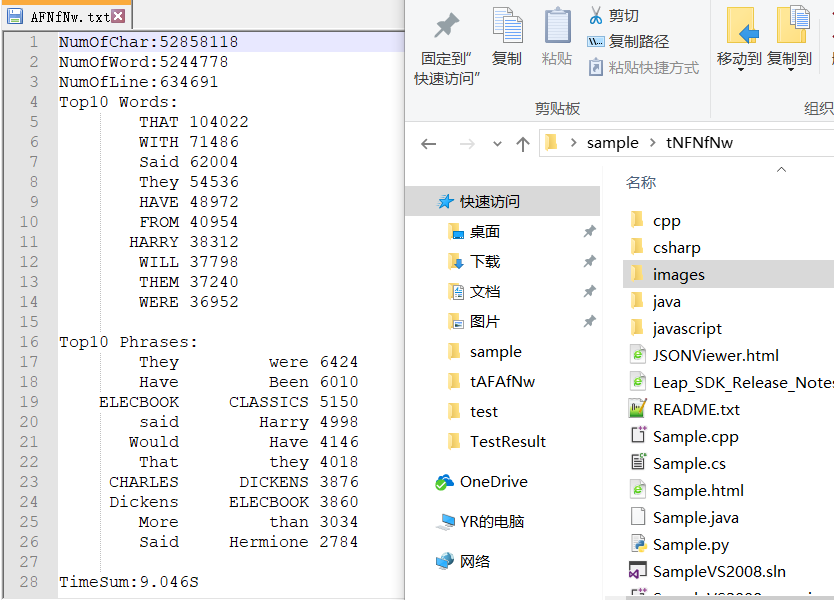
④读入多文件
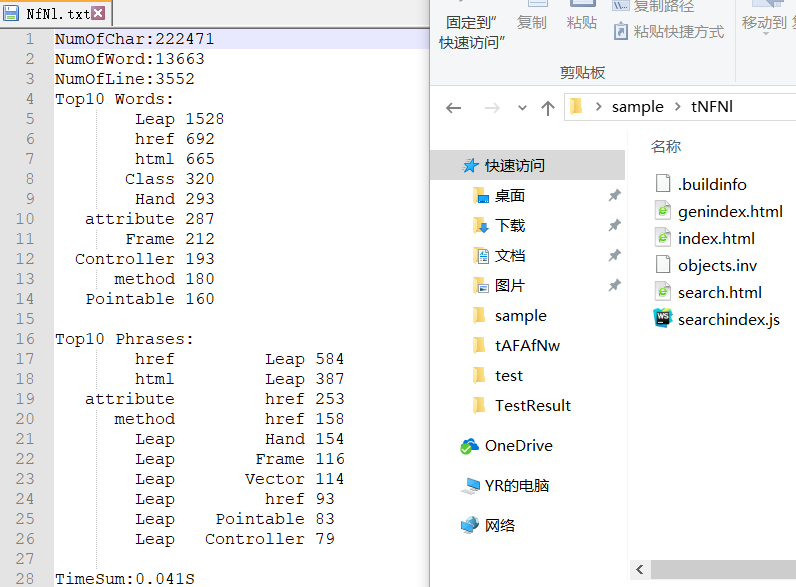
⑤读入带子文件夹的多文件
III 黑盒测试
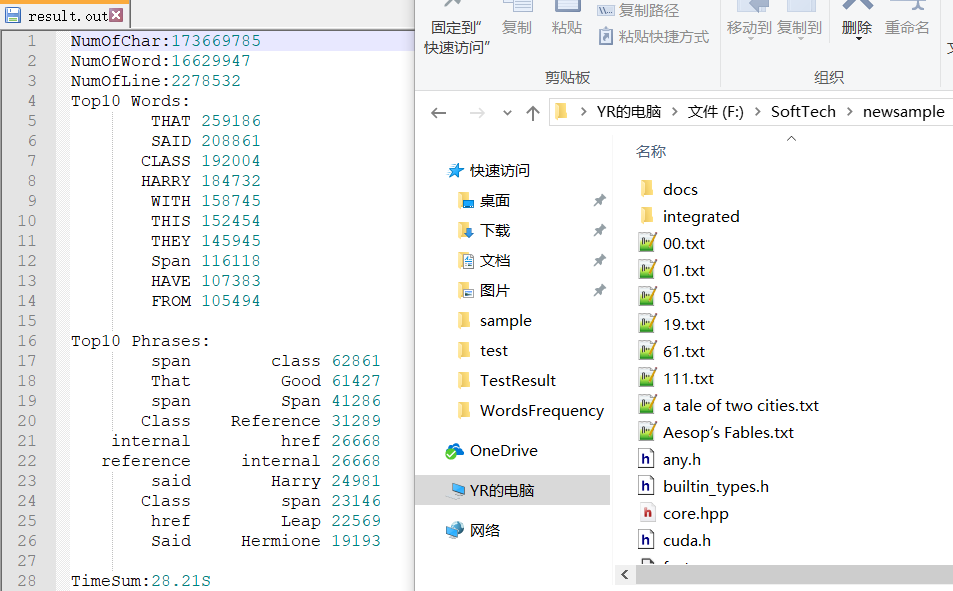
读入助教提供的文件newsample,结果中TOP10的单词和词组与预期结果一致,字符数、单词数和行数有较小的不同。
四、性能分析:
Windows下:采用vs2015自带性能分析工具进行热行分析,图如下:
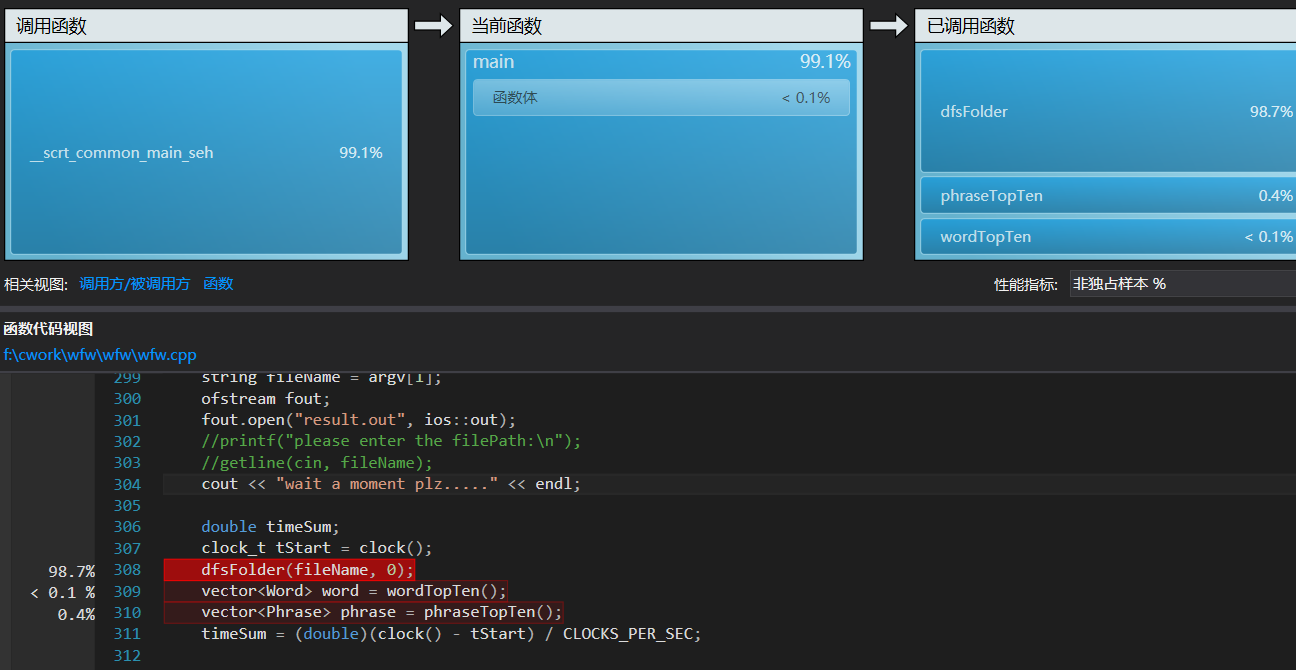
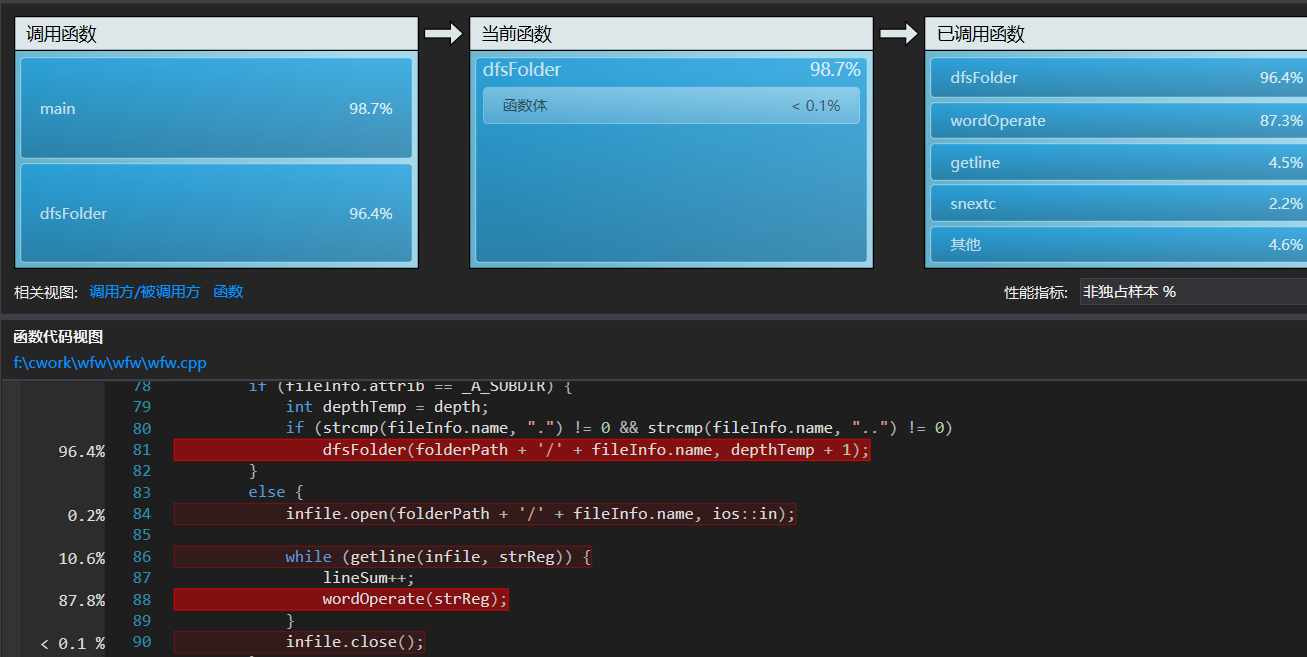
可以看到,递归调用的文件遍历行数理所当然地占了几乎所有时间,毕竟它是程序基石。同时,wordOperate函数作为总操作的顶层函数,也占用了相当多时间。继续。
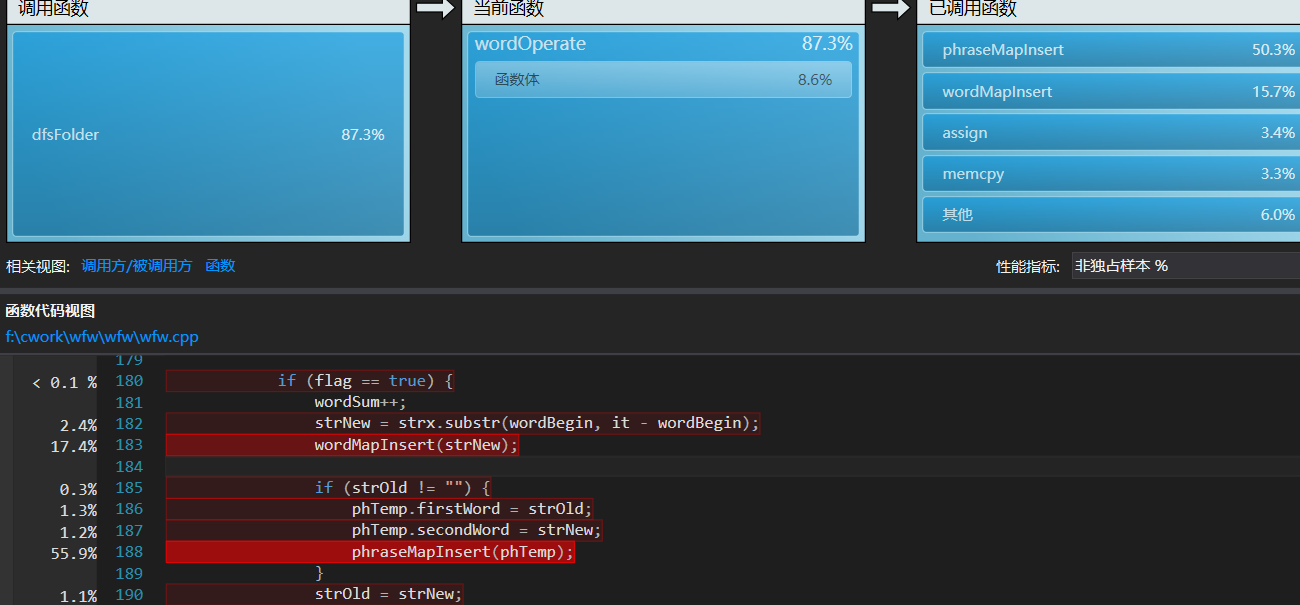
可见phraseMapInsert和wordMapInsert占去多数资源,再进一步深入。
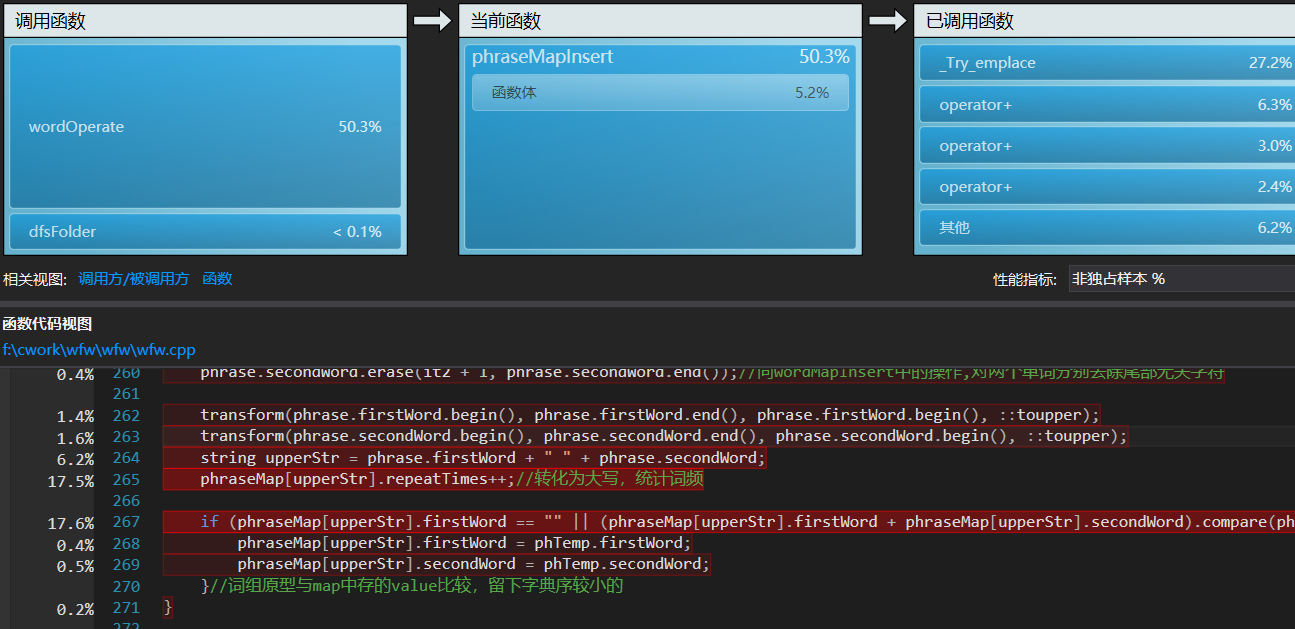
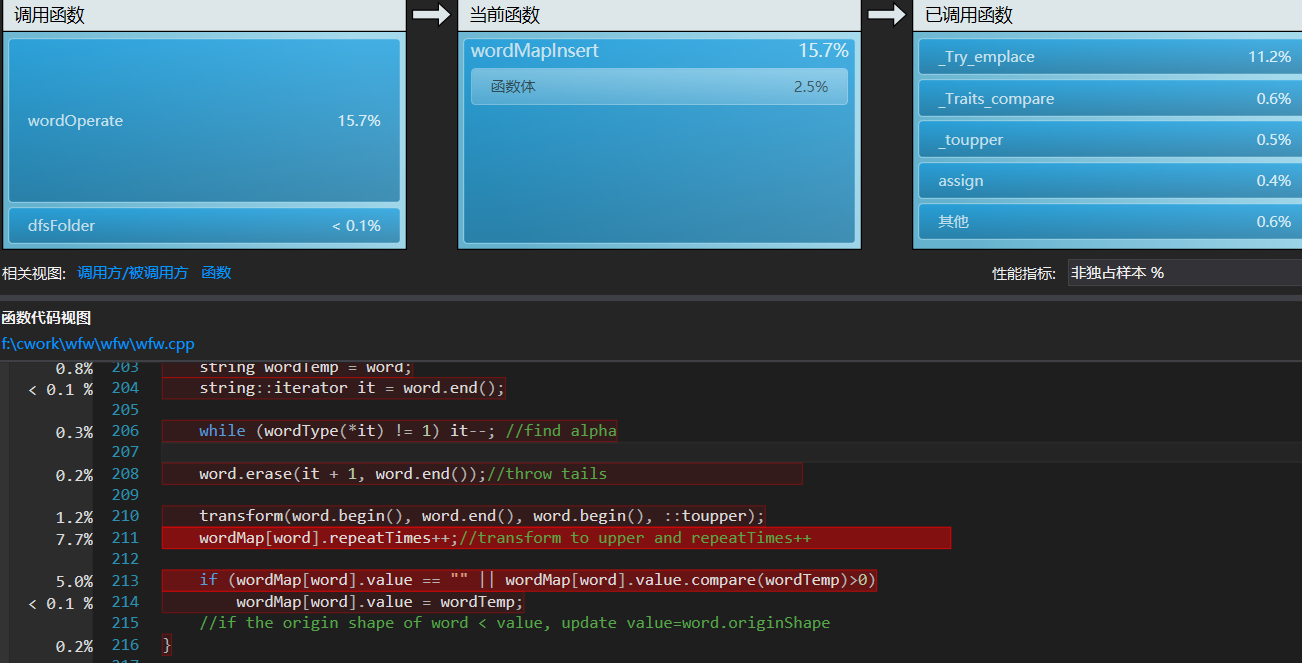
可见这两个函数中,耗时最多的热行是unordered_map的生成和string的比较,经考虑,string的遍历比较和map结点的生成,暂时无法缺省,这两部分耗时可以看做设计时选择数据结构unordered_map和string的代价。
这份代价正是程序的主要时间开销,由此,我短期内很难在不改变数据结构选择的基础上做进一步优化,分析完毕。
Linux下:gprof 导出的函数耗时表如下:
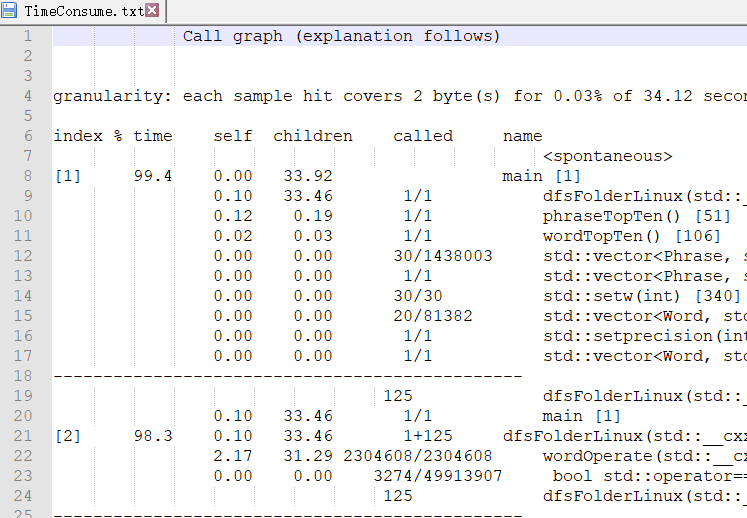
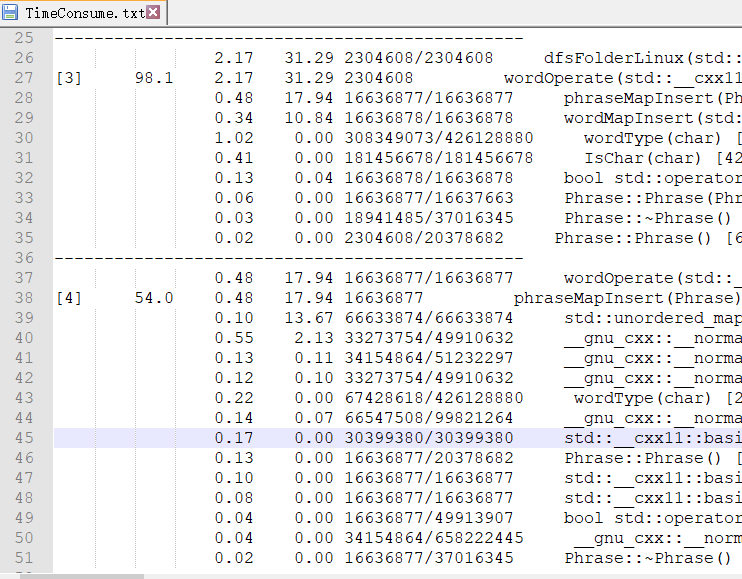
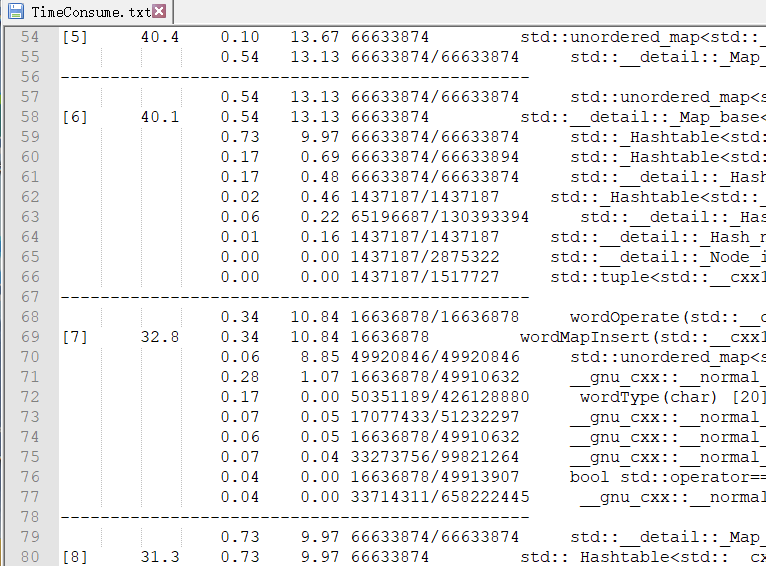
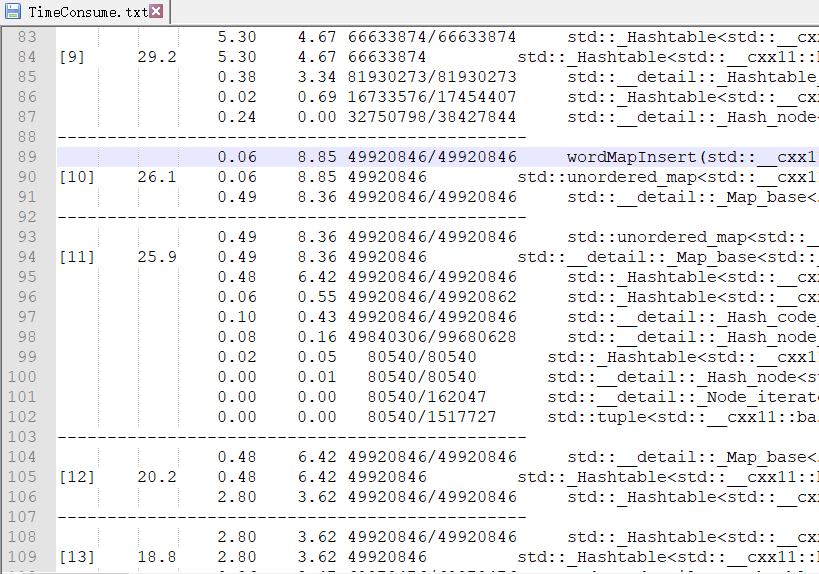
后边基本CPU耗时占比都比较小。经分析可以看出,Hashtable的生成占去主要时间,与Window下性能分析的结果基本一致。
五、总结与反思
由于课业繁忙,本次作业虽限时一周,我却从本周一才开始需求分析,周一晚上才开始正式敲代码,实际开发时间差不多是两天半里见缝插针的三十几小时,周三晚上还熬了一个通宵,期间遇到的各种困难包括数据结构不熟悉、算法设计考虑不周、对单元测试和性能调试不了解、Linux下操作不熟甚至Ubuntu版本落后需要重装等等,靠着组里各路大佬的鼎力相助,总算是在ddl之前交上了,感慨万千。
收获方面,我学到了Windows和Linux下文件遍历的方法,学到了C++中相关数据结构的操作和算法设计,学到了平台移植以及测试、性能分析的方法和技巧,短短三天可以说收获颇丰了。
反思这一次作业,我发现自己的编程基础相当不扎实,写排序算法时还特意去查了一下插入排序怎么写,对类自带的各种函数也基本靠着查手册来做,菜的真实,需要多做多练多学。编程过程中,由于对github不熟悉,我在做版本更新改进、性能调整时,都没做commit,先前较失败的版本丢失了,只留下了完成品,今后编程中应该养成及时commit的习惯,以供来日借鉴、预防重蹈覆辙。
本程序在Windows10下跑助教的样例,耗时28S,而在Ubuntu16下需要50+S,其中的原因我还没弄清楚;单元测试时,我对那些改变了全局变量的函数进行测试,总是很难达到预期,最后不得不修改函数,因此我准备阅读单元测试相关书籍,系统地学习单元测试方法,向TDD靠拢。
值得称道的地方:效率还算高,没有出大差错,在编程中应用了之前读书笔记中提到的简洁代码编程方法,积极地查找各种方法和学习。
本次作业总结与反思如上,至此告一段落,博客提交的ddl也快要到了。来日方长,这一次的教训牢记于心,继续前行吧。
现代软件工程HW1:词频统计的更多相关文章
- 软件工程第一次个人项目——词频统计by11061153柴泽华
一.预计工程设计时间 明确要求: 15min: 查阅资料: 1h: 学习C++基础知识与特性: 4-5h: 主函数编写及输入输出部分: 0.5h: 文件的遍历: 1h: 编写两种模式的词频统计函数: ...
- USTC《现代软件工程》春季学期——第一次个人作业:词频统计
截止日期 2018年3月29日23:59 要求 1. 对源文件(*.txt,*.cpp,*.h,*.cs,*.html,*.js,*.java,*.py,*.php等,文件夹内的所有文件)统计字符数. ...
- C# 词频统计 东北师范大学 软件项目管理 第一次作业
一.作为杨老师的学生第一次听杨老师讲课,印象最深的就是:工程中所有步骤之间是乘法,如果任何一步为0,工程就做不出来了.以前所有老师讲到的都是不要太在乎结果,努力的过程很重要,但是这在软件工程中不合适了 ...
- 作业3-个人项目<词频统计>
上了一天的课,现在终于可以静下来更新我的博客了. 越来越发现,写博客是一种享受.来看看这次小林老师的“作战任务”. 词频统计 单词: 包含有4个或4个以上的字 ...
- C语言实现词频统计——第二版
原需求 1.读取文件,文件内包可含英文字符,及常见标点,空格级换行符. 2.统计英文单词在本文件的出现次数 3.将统计结果排序 4.显示排序结果 新需求: 1.小文件输入. 为表明程序能跑 2.支持命 ...
- c语言实现词频统计
需求: 1.设计一个词频统计软件,统计给定英文文章的单词频率. 2.文章中包含的标点不计入统计. 3.将统计结果以从大到小的排序方式输出. 设计: 1.因为是跨专业0.0···并不会c++和java, ...
- python瓦登尔湖词频统计
#瓦登尔湖词频统计: import string path = 'D:/python3/Walden.txt' with open(path,'r',encoding= 'utf-8') as tex ...
- Hadoop上的中文分词与词频统计实践 (有待学习 http://www.cnblogs.com/jiejue/archive/2012/12/16/2820788.html)
解决问题的方案 Hadoop上的中文分词与词频统计实践 首先来推荐相关材料:http://xiaoxia.org/2011/12/18/map-reduce-program-of-rmm-word-c ...
- pyspark进行词频统计并返回topN
Part I:词频统计并返回topN 统计的文本数据: what do you do how do you do how do you do how are you from operator imp ...
随机推荐
- thinkphp 上传安全
网站的上传功能也是一个非常容易被攻击的入口,所以对上传功能的安全检查是尤其必要的. 大理石平台支架 系统提供的上传类Think\Upload提供了安全方面的支持,包括对文件后缀.文件类型.文件大小以及 ...
- NX二次开发-UFUN求两个向量的叉乘UF_VEC3_cross
NX9+VS2012 #include <uf.h> #include <uf_ui.h> #include <uf_vec.h> #include <uf_ ...
- Android 配置正式签名和debug签名
为了测试微信分享,微信分享必须有签名信息才能成功调用微信,所以需要debug 下设置签名,方便调试build.gradle里,配置2个签名: signingConfigs { release { ke ...
- c++ pb_ds库,实现 红黑树,Splay
C++ pb_ds库 #include <ext/pb_ds/assoc_container.hpp>#include <ext/pb_ds/tree_policy.hpp> ...
- ggplot2在一幅图上画两条曲线
ggplot2在一幅图上画两条曲线 print(data)后的结果是 C BROWN.P MI.P 0 0.9216 0.9282 30 0.9240 0.9282 100 0.9255 0.9282 ...
- 基于Netty的RPC架构学习笔记(四):netty线程模型源码分析(一)
文章目录 如何提高NIO的工作效率 举个
- Balking Pattern不需要就不用做
word自动保存功能,如果文档被修改了,后台线程每隔一段时间会自动执行保存功能,但是如果用户在自动保存之前用Ctrl+S手动保存呢?自动保存还会执行吗?答案是不会,因为这个操作时不需要重复做的. pu ...
- redis随记
CONFIG REWRITE 将config文件 将服务器当前所使用的配置记录到 redis.conf 文件中.
- .Net 动态编译(c# 脚本)
1 用.NET提供的类动态编译代码字符串,生成DLL存于内存中,加载到程序域 2 用反射的方式调用这个DLL 将要被编译和执行的代码读入并以字符串方式保存声明CSharpCodeProvider对象实 ...
- Gamma(1)
目前为止看到的解释Gamma来由说得最清楚的一篇文章:https://www.cambridgeincolour.com/tutorials/gamma-correction.htm 几点总结. 1, ...