re正则匹配模块_python
一、re模块
1、模块功能
通过re模块的接口接入正则表达式语言,主要用于匹配字符串。
2、正则表达式元字符以及意义
. 代表任意一个字符(除了换行符\n)
^ 以什么开头
$ 以什么结尾
* 重复匹配*前面的字符出现0到多次 【0,正无穷】
+ 重复匹配+前面的字符1到多次【1,正无穷】
? 重复匹配?前面的字符0或1次【0,1】
{数字} 代表前面的匹配次数,如'b{3}'
{数字n,数字m} 代表前面的匹配次数n次到m次
"|" 或
'(abc){2}' 将abc括成一个整体,分组匹配
[] 代表字符集中的字符,或的关系,如'[a-z]',还有取消元字符意义的特殊功能,
如'[^123]',^放在[]里的最前面,代表取反。
如[1-5],-放在[]里面,代表一个范围
\与普通字符,代表一定意义如[\d],具体代表意义如下;(但\与特殊自字符,取消特殊性,如[\^])
\d 匹配所有的数字,相当于[0-9]
\D 匹配非数字字符,相当于[^0-9]
\w 匹配数字字母下划线,相当于[0-9a-zA-Z_]
\W 匹配非数字字母下划线,相当于[^0-9a-zA-Z_]
\s 匹配任意空白符(空格,换行,回车,换页制表符)相当于[ \f\n\r\t]
\S 匹配任意非空白符,相当于[^ \f\n\r\t]
\A 匹配字符串开始,和^区别:\A只匹配行首,在re.M下也不匹配他行行首
\Z 匹配字符串结束,和$区别:\Z只匹配结束,在re.M下也不匹配他行结束
\b 匹配单词的边界,空格之间
\B 匹配非单词的边界,空格之间
() 做分组,弄成整体字符组进行匹配,如'(bs)'
添加组名分组:根据组名查出

查找网址的例子:
import re
print(re.findall('www.(\w+).com',"www.baidu.com")) #['baidu'],得出中间结果
print(re.findall('www.(?:\w+).com',"www.baidu.com")) #['www.baidu.com'],得出所有结果
匹配身份证例子:

3、模块的方法
findall():所有结果都返回到一个列表里
search():返回匹配到的第一个对象(object),可以调用group()方法返回结果(常用)
print(re.search('www.(\w+).com',"www.baidu.com").group())
match():只在字符串开始匹配,只匹配开头符不符合。也是返回一个对象,也用group()返回结果。
split() :分割字符串
print(re.split('k+','sdfkwerkryy')) #['sdf', 'wer', 'ryy']
sub("替换前","替换后","替换的字符串",替换多少个(不写默认全部替换))
print(re.sub('chen','peng','chenxiaozanchen',1)) #pengxiaozanchen
compile():提高一点点效率,编译规则,再调用
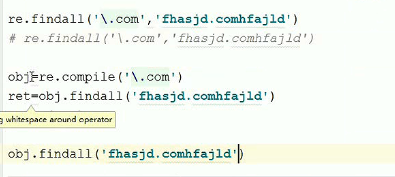
finditer() : 得到的结果不是放到list,而是迭代器


.
re正则匹配模块_python的更多相关文章
- python - re正则匹配模块
re模块 re 模块使 Python 语言拥有全部的正则表达式功能. compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象.该对象拥有一系列方法用于正则表达式匹配和替换. re ...
- 第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签
第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签 标签选择器对象 HtmlXPathSelector()创建标签选择器对象,参数接收response回调的html对象需 ...
- 四 web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签
标签选择器对象 HtmlXPathSelector()创建标签选择器对象,参数接收response回调的html对象需要导入模块:from scrapy.selector import HtmlXPa ...
- 常用的re模块的正则匹配的表达式
07.01自我总结 常用的re模块的正则匹配的表达式 一.校验数字的表达式 1.数字 ^[0-9]\*$ 2.n位的数字 ^\d{n}$ 3.至少n位的数字 ^\d{n,}$ 4.m-n位的数字 ^\ ...
- python中正则匹配之re模块
Python中正则表达式 re:re是提供正则表达式匹配操作的模块 一.什么是正则表达式 正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某个模式匹配,Python 自1.5版本起 ...
- Aho-Corasick算法、多模正则匹配、Snort入门学习
希望解决的问题 . 在一些高流量.高IO的WAF中,是如何对规则库(POST.GET)中的字符串进行多正则匹配的,是单条轮询执行,还是多模式并发执行 . Snort是怎么组织.匹配高达上千条的正则规则 ...
- python_way day18 html-day4, Django路由,(正则匹配页码,包含自开发分页功能), 模板, Model(jDango-ORM) : SQLite,数据库时间字段插入的方法
python_way day18 html-day4 1.Django-路由系统 - 自开发分页功能 2.模板语言:之母板的使用 3.SQLite:model(jDango-ORM) 数据库时间字 ...
- Python正则匹配字母大小写不敏感在读xml中的应用
需要解决的问题:要匹配字符串,字符串中字母的大小写不确定,如何匹配? 问题出现之前是使用字符串比较的方式,比如要匹配'abc',则用语句: if s == 'abc':#s为需要匹配的字符串 prin ...
- 正则 re模块
Python 正则表达式 re 模块 简介 正则表达式(regular expression)是可以匹配文本片段的模式.最简单的正则表达式就是普通字符串,可以匹配其自身.比如,正则表达式 ‘hello ...
随机推荐
- junit 运行(eclipse + IDEA)
记得刚用IDEA 开发的时候, 什么都还不熟,以为junit 运行还跟eclipse 一样, 结果试了后才知道是不一样的. 现在刚好写junit 相关的,也就都记录下来吧 Eclipse:eclip ...
- java设计模式学习笔记--依赖倒转原则
依赖倒转原则简述 1.高层模块不应该依赖低层模块,二者都应该依赖其抽象 2.抽象不应该依赖细节,细节应该依赖抽象 3.依赖倒转得中心思想时面向接口编程 4.依赖倒转原则时基于这样得设计理念:相对于细节 ...
- pads无模命令
W<n>………改变线宽,比如 30. 栅格(Grids) G<xx>………过孔和设计栅格设置.GD<xx>………显示栅格设置.GP………打开或关闭极性栅格.GP r ...
- flutter常用插件(持续更新)
flutter插件官网地址:https://pub.dartlang.org/packages/ 1. image_picker 一个可以从图库选择图片,并可以用相机拍摄新照片的flutter插件 2 ...
- 二、继续学习(主要参考Python编程从入门到实践)
操作列表 具体内容如下: # 操作列表 # 使用for循环遍历整个列表. # 使用for循环处理数据是一种对数据集执行整体操作的不错的方式. magicians = ['alice', 'david' ...
- linux 下查看json 文件 使用jq工具
安装 文档 yum 安装 yum search jq yum -y install jq.x86_64 apt-get install jq jq支持查看 jq . json 文件 查看json文件 ...
- linux(服务器)如何确认网卡(网口)对应的配置文件
服务器装完系统就要配置网络,然而服务器经常是多网卡多网口,我们在某个网口插上网线后,到/etc/sysconfig/network-scripts/下配置ip时无法确定网口对应的配置文件.(比如是et ...
- Spark学习之路 (十八)SparkSQL简单使用[转]
SparkSQL的进化之路 1.0以前: Shark 1.1.x开始: SparkSQL(只是测试性的) SQL 1.3.x: SparkSQL(正式版本)+Dataframe 1.5.x: Spar ...
- 剑指offer-面试题9-用两个栈实现队列-栈和队列
/* 题目: 用两个栈实现一个队列.队列声明如下. */ /* 思路: 将值压入stack1,再从stack1弹出到stack2,则为先进先出. appendTail时直接压入stack1即可,当st ...
- openlayers轨迹播放
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...