CUDA并行计算 | 线程模型与内存模型
前言
CUDA(Compute Unified Device Architecture)是显卡厂商NVIDIA推出的通用并行计算平台和编程模型,它利用NVIDIA GPU中的并行计算引擎能更有效地解决复杂的计算问题。通过使用CUDA,开发人员可以像在CPU上那样直接访问GPU设备的虚拟指令集和存储设备,大大提高了GPU算法或程序的开发效率。CUDA平台可以通过CUDA加速库、编译器指令、应用编程接口以及行业标准程序语言的扩展(包括C、C++、Fortan、Python)来使用。
在CUDA学习的过程中,CUDA的线程模型和内存结构是必须要掌握的基础知识,这决定了你是否能够写一个完整的CUDA程序。CUDA算法开发通常有两个步骤:算法初稿、性能优化。如果不掌握线程模型和内存模型,算法初稿就无法完成,更谈不上性能。而性能优化更是对这两个方面有着较高的要求,需要不仅掌握,而且深入掌握。
CUDA线程模型(如何组织线程)
在CUDA线程模型中,线程(Thread)是GPU的最小执行单元,能够完成一个最小的逻辑意义的操作,每个线程都有自己的指令地址计数器和寄存器状态,利用自身的数据执行当前的指令。而线程束(Warp)则是GPU的基本执行单元,包含32个线程,GPU每次调用线程都是以线程束为单位的,在一个线程束中,所有的线程按照单指令多线程(SIMT)方式执行,即所有线程执行相同的指令。多个线程束位于一个最高维度为3的线程块(Block)中,同一个线程块中的所有线程,都可以使用共享内存来进行通信、同步。线程块又通过一个最高维度为3的网格(Grid)来管理。CUDA的线程结构图如图1所示:
图1 CUDA线程结构
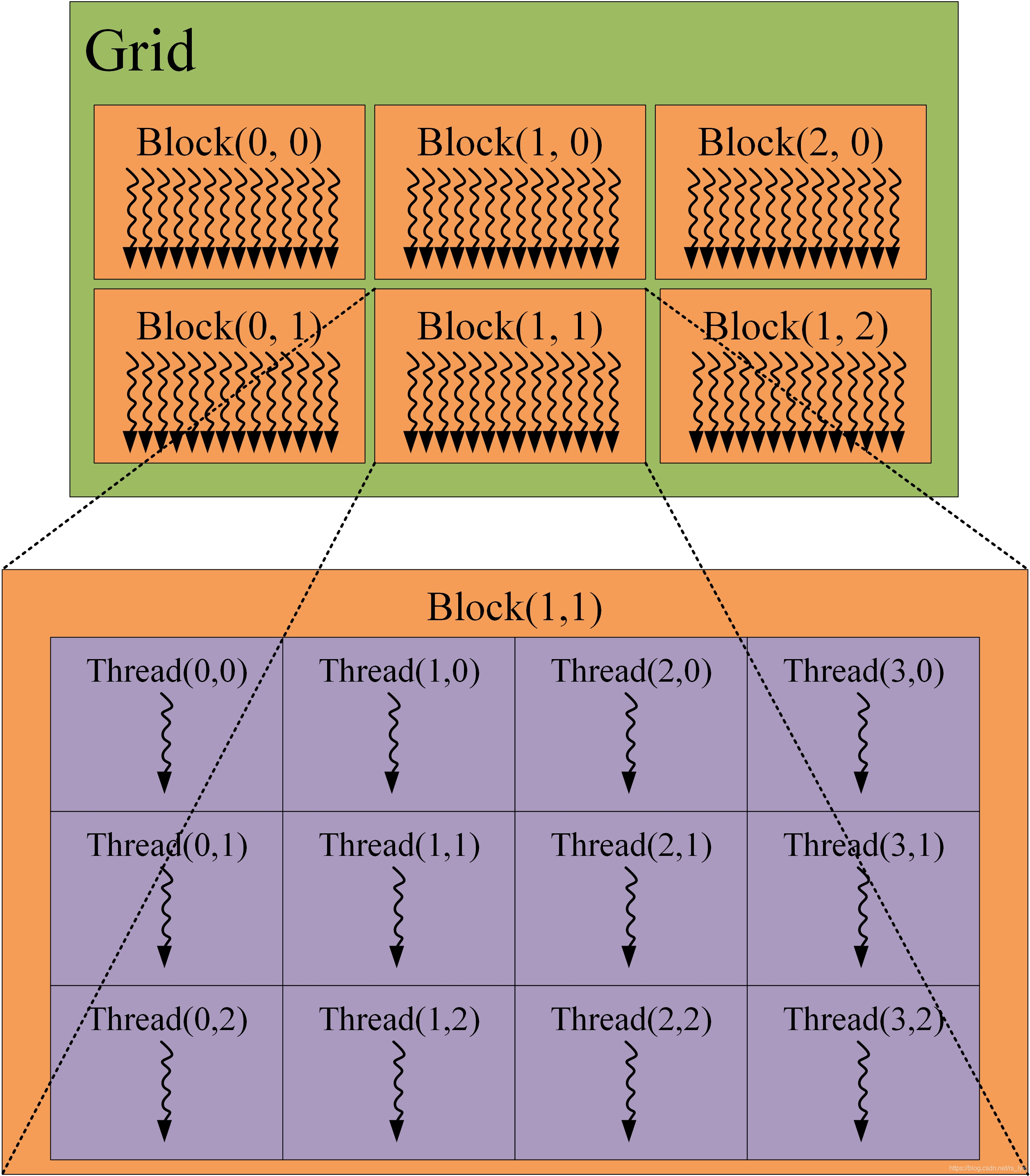
举个最简单常用的例子,对于二维影像,我们可以一个线程对应一个像素,一个线程块对应一块区域,一个Grid对应整个影像。
CUDA内存模型(了解不同内存优缺点,合理使用)
CUDA内存模型中,有两种类型的存储器:不可编程存储器和可编程存储器,前者并不对开发人员开放存取接口,包括一级缓存和二级缓存;后者可以显式地控制数据在内存空间中的存取,包括寄存器、共享内存、本地内存、常量内存、纹理内存以及全局内存。可编程存储器的结构如图2所示:
图2 CUDA内存结构
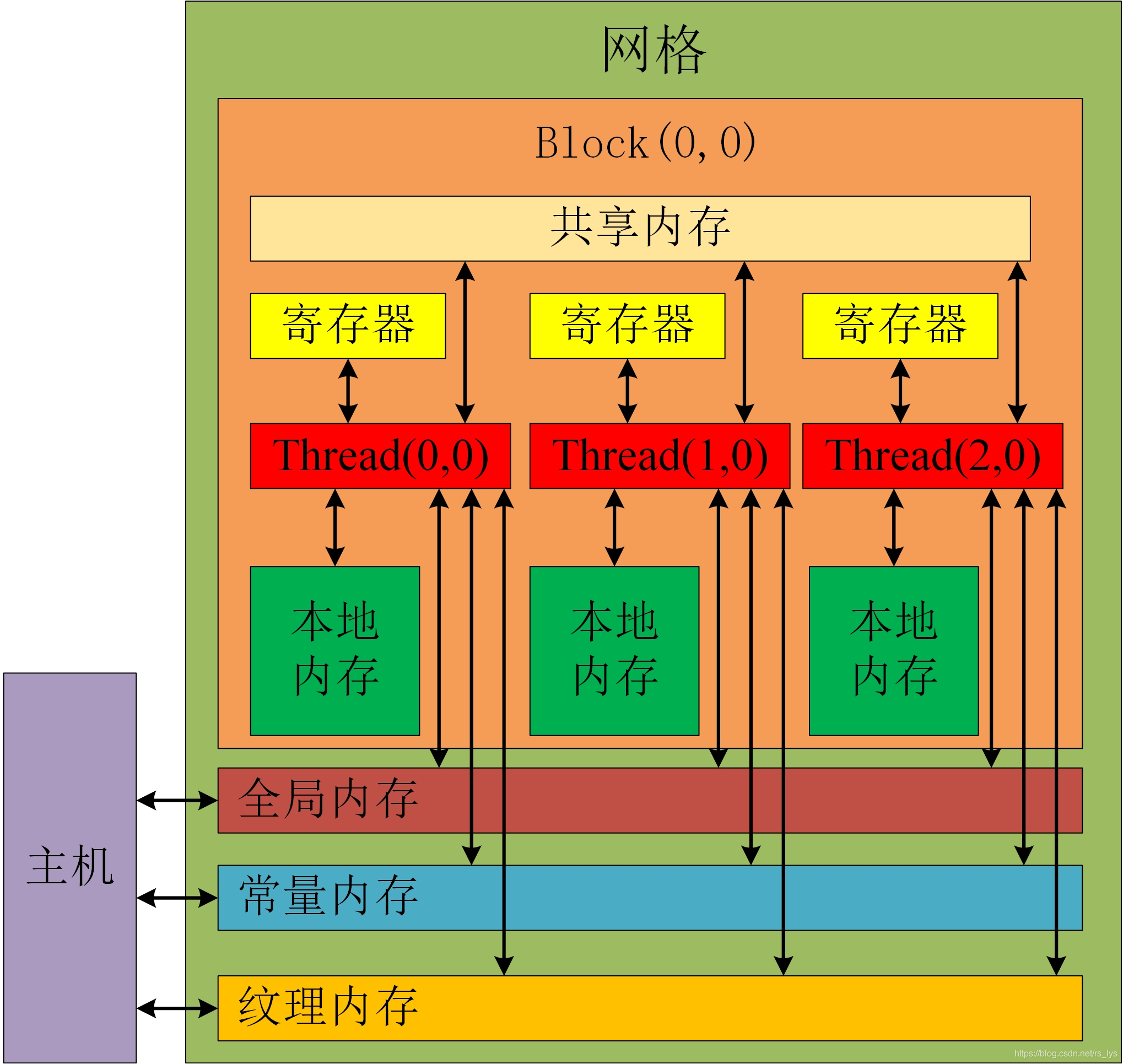
它们的特点如下:
寄存器:寄存器是GPU上运行速度最快的内存空间,分配于每个线程中,保存线程核函数中声明的没有其它修饰符的自变量。寄存器对于每个线程来说是私有的,数量也是有限的,在Fermi架构中,每个线程最多有63个寄存器,Kepler架构将限制数量扩展至256个,在线程核函数中使用较少的寄存器可以使SM中有更多的常驻线程块,增加使用率和性能。而如果一个核函数使用了超过了硬件限制数量的寄存器,将会用本地内存代替多出的寄存器,降低算法性能。
本地内存:线程核函数中原则上应该存储在寄存器中但由于某些原因(如寄存器数量使用超出限制或变量占用内存过大)而无法进入寄存器空间的变量将溢出到本地内存中,本地内存访问符合高效内存访问要求,对于计算能力在2.0以上的GPU来说,本地内存数据存储在每个SM的一级缓存和每个设备的二级缓存中。
共享内存:共享内存是片上内存,与本地内存和全局内存相比具有更高的带宽和更低的延迟。共享内存由线程块分配,声明周期伴随着整个线程块,线程块中的每个线程都可以共享其存储空间,这也是共享内存的意义所在,当一个线程块执行完毕,其分配的共享内存将被释放且重新分配给其他线程块。
共享内存是同一个线程块的线程之间通信的基本方式,一个块内的线程可以通过使用共享内存而相互合作。常用的合作方式是在计算前,将全局内存读进共享内存中,而读取的方式是每个线程负责读取某一个位置的数据,读完之后块内的所有线程都能够使用整个共享内存中的数据。因为共享内存的延迟低带宽高,所以这种方式比直接读取全局内存要高效得多。需要注意的是读取全局内存至共享内存时要注意同步(线程块内只有一个线程束的情况除外),在CUDA C中同步的方式是使用线程同步函数__syncthreads()来设立一个执行障碍点,即同一个线程块中的所有线程必须等待其他所有线程执行到这个函数处才能往下执行,这样可以确保需要的全局内存被全部载入共享内存,避免潜在的数据冲突。
核函数中存储在共享内存的变量通过修饰符__shared__修饰。
__shared__ int shared_memory[];
常量内存:常量内存驻留在设备内存中,并在每个SM专用的常量缓存中缓存,常量内存变量使用修饰符__constant__修饰,必须在全局空间内和所有核函数之外进行声明,对同一编译单元中的所有线程核函数可见,核函数只能对常量进行读操作。
纹理内存:纹理内存驻留在设备内存中,并在每个SM的只读缓存中缓存,是一种通过指定的制度缓存访问的全局内存,是对二维空间局部性的优化,访问二维数据时可以达到最优性能。
全局内存:全局内存常驻于设备内存中,是GPU中最大、延迟最高、最常使用的内存,它贯穿于应用程序的整个生命周期。全局内存通过缓存来实现数据存取,对全局内存进行访问时,必须注意内存访问的两个特性:对齐内存访问和合并内存访问。
当访问内存的第一个地址是缓存粒度的偶数倍时(二级缓存为32字节,一级缓存为128字节),满足合并访问,可以获得更高的访问效率,而非对齐访问则会造成带宽浪费。
当一个线程束中全部的32个线程访问一个连续的内存块时,满足合并内存访问,可以最大化全局内存吞吐量。这是由于GPU可通过一次寻址和一次读写指令对连续的32字节(二级缓存)或128字节(一级缓存)进行一次读取,如果满足合并访问,则一个线程束通过一次寻址即可完成访问,效率非常高;反之如果不满足合并访问,则最坏的情况需要32次寻址才能完成访问,这是对内存带宽的一种极大的浪费。图3描述了合并访问与非合并访问的两种方式。
图3 合并访问示意图
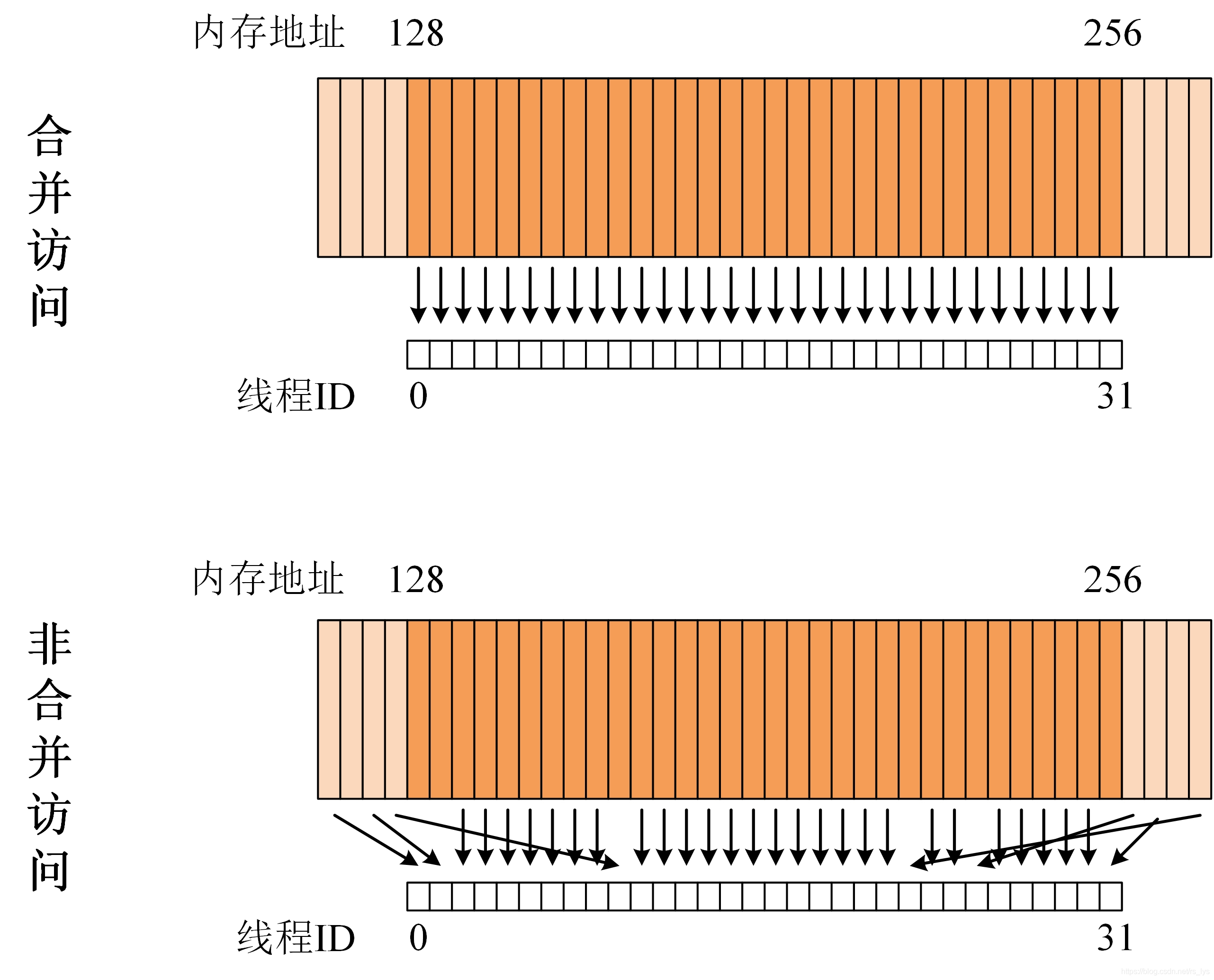
从个人项目经验来说,
1. 全局内存是不得不用,但是要尽量减少读写次数,因为它真的很慢。对于新手,算法初稿可以全部使用全局内存,可以将算法最快实现,后面再去优化。对于老手,肯定是在算法初稿就会考虑更快的读写方式了。
2. 共享内存是优化算法内存读写效率的利器,是减少全局内存读写次数的不二选择,这得益于同一个线程块中的线程共享同一块共享内存,所以最常见的思路就是将需要重复读写的全局内存一次性读入共享内存中反复使用。
3. 寄存器是速度最快的,奈何一个kernel所能使用的数量实在有限,所以一般情况下要使用最大化,将能用的都用上,这就要考性能监测工具来监测每个线程的使用量了,如NVIDIA Nsight Visual Studio Edition,性能优化不可缺工具之一 link。
当然也有一些算法,使用超量的寄存器,给每个线程增加操作数(内存操作、运算操作)来减少延迟Latency(内存延迟、运算延迟),可以达到更高的性能。详细请参考 link。因为在CUDA运算里,延迟确实非常恐怖,尤其是全局内存读写延迟,高达400 ~ 600个时钟周期,也就是说从你发读写指令到指令执行完,需要400 ~ 600时钟周期。所以通常通过开辟大量的线程以及线程内增加并发指令来隐藏延迟。
CUDA并行计算 | 线程模型与内存模型的更多相关文章
- GPU的线程模型和内存模型
遇见C++ AMP:在GPU上做并行计算 Written by Allen Lee I see all the young believers, your target audience. I see ...
- Java 线程 — JMM Java内存模型
JMM Java Memory Model,Java内存模型,属于语言级的内存模型 并发编程中存在的问题: 如何通信:用于线程之间交换信息.两种方式:共享内存,消息传递 如何同步:用于控制不同线程间操 ...
- 【CUDA 基础】4.1 内存模型概述
title: [CUDA 基础]4.1 内存模型概述 categories: - CUDA - Freshman tags: - CUDA内存模型 - CUDA内存层次结构 - 寄存器 - 共享内存 ...
- 线程安全&Java内存模型
目录 Java内存模型 关于线程安全 Volatile关键字 Synchronized锁 重入锁 Lock锁 死锁 乐观锁与悲观锁 乐观锁(适合多读场景) 悲观锁(适合多写场景) Java内存模型 J ...
- PHP:执行模型和内存模型
PHP:执行模型和内存模型 背景 对于任何一种语言,了解其执行模型和内存模型都是有意义的,本文中的内容不见得正确,请多批评. 执行模型 每个请求都是一个独立的PHP进程,两个请求之间会完全隔离,会话和 ...
- 【Java线程】Java内存模型总结
学习资料:http://www.infoq.com/cn/articles/Java-memory-model-1 Java的并发采用的是共享内存模型(而非消息传递模型),线程之间共享程序的公共状态, ...
- (转)【Java线程】Java内存模型总结
Java的并发采用的是共享内存模型(而非消息传递模型),线程之间共享程序的公共状态,线程之间通过写-读内存中的公共状态来隐式进行通信.多个线程之间是不能直接传递数据交互的,它们之间的交互只能通过共享变 ...
- 【Java并发】线程安全和内存模型
一.概述 1.1 什么是线程安全? 1.2 案例 1.3 线程安全解决办法: 二.synchronized 2.1 概述 2.2 同步代码块 2.3 同步方法 2.4 静态同步函数 2.5 总结 三. ...
- 深入理解Java虚拟机读书笔记8----Java内存模型与线程
八 Java内存模型与线程 1 Java内存模型 ---主要目标:定义程序中各个变量的访问规则,即在虚拟机中将变量存储到内存和从内存中取出变量这样的底层细节. ---此处的变量和J ...
随机推荐
- 使用Git实现Laravel项目的自动化部署
简介 不知道大家一开始是怎么使用 git 进行开发的,反正我个人是先将代码提交到 github 仓库,然后用 SSH 登录到服务器,然后进行克隆或者版本更新.听起来就很麻烦,当然实际操作中也很麻烦,那 ...
- 前端agl分页的写法
<!-- 分页组件开始 --> <script src="../plugins/angularjs/pagination.js"></script&g ...
- 【Dart学习】-- Dart之extends && implements && with的用法与区别
一,概述 继承(关键字 extends) 混入 mixins (关键字 with) 接口实现(关键字 implements) 这三种关系可以同时存在,但是有前后顺序: extends -> m ...
- ac自动机fail树上按询问建立上跳指针——cf963D
解法看着吓人,其实就是为了优化ac自动机上暴力跳fail指针.. 另外这题对于复杂度的分析很有学习价值 /* 给定一个母串s,再给定n个询问(k,m) 对于每个询问,求出长度最小的t,使t是s的子串, ...
- Ext 行模型与Grid视图
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- centos 下安装 shpinx2.1.7 记录
安装sphinx yum install -y mysql mysql-devel yum install automake autoconf cd /usr/local/src/ wget http ...
- 【Java架构:基础技术】一篇文章搞掂:Eclipse
Eclipse中使用SVN 1.打开资源库视图 https://www.cnblogs.com/liangguangqiong/p/7965770.html 一.编辑器方面 格式化取消自动换行:打开E ...
- Rubber Ducky简介
USB Rubber Ducky是一款模仿人工键盘输入的设备,外形和U盘一样,模拟键盘输入速度可达到1000个字符每分钟,并且适合任何操作系统,包括安卓等移动OS,它使用的是它特定的脚本语言,用记事本 ...
- 3. Python基础语法
注释 我们在文言文中经常会看到注释,注释可以帮助读者对文章的理解.代码中的注释也是一样,优秀的代码注释可以帮助读者对代码的理解.当然在代码编写过程中,注释的使用不一定只是描述一段代码,也可能的是对代码 ...
- Flink 配置文件详解
前面文章我们已经知道 Flink 是什么东西了,安装好 Flink 后,我们再来看下安装路径下的配置文件吧. 安装目录下主要有 flink-conf.yaml 配置.日志的配置文件.zk 配置.Fli ...