elasticsearch(lucene)索引数据过程
倒排索引存储-分段存储(lucene的功能)
在lucene中:lucene index包含了若干个segment
在elasticsearch中:index包含了若干主从shard,shard包干了若干segment
segment是elasticsearch中存储的最小文件单元,也就是分段存储,segment被设计为不可变的
新增:新创建索引时,新建一个segment存储新的数据
删除:由于segment是只读的,所以在索引文件中新增了.del文件,专门存储被删除的数据id,当查询时被删除的数据仍能被查询,进行查询结果合并时才会过滤掉,merge segment时会真正删除
更新:新增和删除的组合
segment的不可变性的优点
- 不需要锁(没有直接修改已经存在段的情况)
- 可以利用内存,由于segment不可变,所以segment被加载到内存后无需改变,只要内存足够,segment就可以长期驻村,大大提升查询性能
- 更新、新增的增量的方式很轻,性能好
segment的不可变性的缺点
- 删除操作不会马上删除有一定的空间浪费
- 频繁更新涉及到大量的删除动作,会有大量的空间浪费
- segment的数量可能非常多,对服务器的文件句柄消耗很大,查询性能会随着segment的数量增加而增加
新增数据的过程
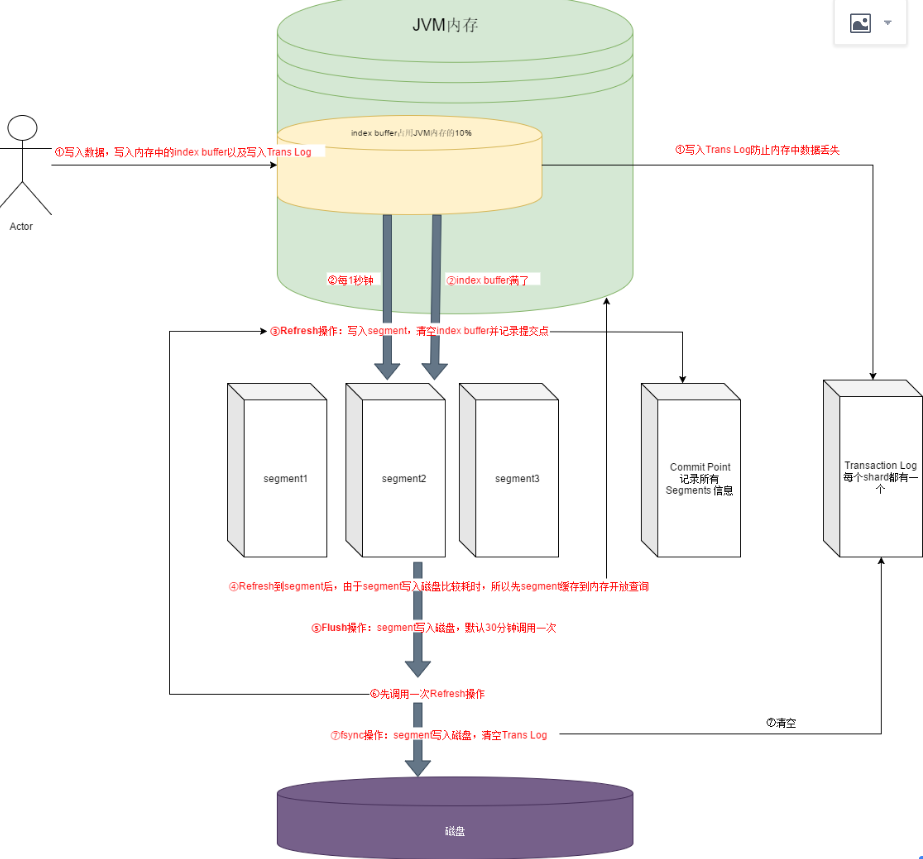
这个流程的目的是:提升写入性能(异步落盘)
1、保存到index buffer中,同时写入Transaction log(防止内存的数据丢失,有点想redo log)
2、当index buffer空间满了(默认占用jvm10%)或每1秒(通过index.refresh_interval 配置)执行Refresh操作,写入segment并清空index buffer(这里的1秒内是查不到刚保存的数据的,所以es也被成为近实时的搜索引擎)
3、于此同时将segment刷入内存,开放查询
4、flush操作将segment写入磁盘(默认30分钟执行一次)
flash操作包含:
- 调用一次refresh
- fsync:将segment写入磁盘
- 清空对应的trans log

elasticsearch(lucene)索引数据过程的更多相关文章
- ES 18 - (底层原理) Elasticsearch写入索引数据的过程 以及优化写入过程
目录 1 Lucene操作document的流程 1.1 添加document的流程 1.2 删除document的流程 2 优化写入流程 - 实现近实时搜索 2.1 流程的改进思路 2.2 设置re ...
- Heka–>Elasticsearch 索引数据过程的优化
Heka 的参数配置跟Elasticsearch的参数没有关系,Heka只负责按照配置发送数据,所以索引的优化主要在 Elaticsearch端来完成. 下面是Elasticsearch的一些相关概念 ...
- elasticsearch批量索引数据示例
示例数据文件document.json(index表示在索引中增加或替换现有文档,create表示如果文档不存在则添加文档,delete表示删除文档): { "index": { ...
- 使用Flink实现索引数据到Elasticsearch
使用Flink实现索引数据到Elasticsearch 2018-07-28 23:16:36 Yanjun 使用Flink处理数据时,可以基于Flink提供的批式处理(Batch Proce ...
- Lucene学习总结之四:Lucene索引过程分析
对于Lucene的索引过程,除了将词(Term)写入倒排表并最终写入Lucene的索引文件外,还包括分词(Analyzer)和合并段(merge segments)的过程,本次不包括这两部分,将在以后 ...
- Lucene学习总结之四:Lucene索引过程分析 2014-06-25 14:18 884人阅读 评论(0) 收藏
对于Lucene的索引过程,除了将词(Term)写入倒排表并最终写入Lucene的索引文件外,还包括分词(Analyzer)和合并段(merge segments)的过程,本次不包括这两部分,将在以后 ...
- Lucene学习笔记: 四,Lucene索引过程分析
对于Lucene的索引过程,除了将词(Term)写入倒排表并最终写入Lucene的索引文件外,还包括分词(Analyzer)和合并段(merge segments)的过程,本次不包括这两部分,将在以后 ...
- Elasticsearch Lucene 数据写入原理 | ES 核心篇
前言 最近 TL 分享了下 <Elasticsearch基础整理>https://www.jianshu.com/p/e8226138485d ,蹭着这个机会.写个小文巩固下,本文主要讲 ...
- 使用Lucene索引和检索POI数据
1.简介 关于空间数据搜索,以前写过<使用Solr进行空间搜索>这篇文章,是基于Solr的GIS数据的索引和检索. Solr和ElasticSearch这两者都是基于Lucene实现的,两 ...
随机推荐
- dotnet 通过 WMI 获取设备厂商
本文告诉大家如何通过 WMI 获取设备厂商 通过 Win32_ComputerSystem 可以获取电脑系统信息 通过下面代码可以获取 机器型号 和 制造厂商 var mc = "Win32 ...
- P3521 [POI2011]ROT-Tree Rotations (线段树合并)
P3521 [POI2011]ROT-Tree Rotations 题意: 给你一颗树,只有叶子节点有权值,你可以交换一个点的左右子树,问你最小的逆序对数 题解: 线段树维护权值个个数即可 然后左右子 ...
- int32 无符号范围 -2147483648~2147483647
int32 无符号范围 -2147483648~2147483647
- Mybatis 多对多(易百教程)
mybatis3.0 添加了association和collection标签专门用于对多个相关实体类数据进行级联查询,但仍不支持多个相关实体类数据的级联保存和级联删除操作.因此在进行实体类多对多映射表 ...
- 为什么IIS应用程序池回收时间默认被设置为1740分钟?
作者:斯科特 福赛斯/Scott Forsyth日期:2013/04/06地址:http://weblogs.asp.net/owscott/why-is-the-iis-default-app-po ...
- 构建锁与同步组件的基石AQS:深入AQS的实现原理与源码分析
Java并发包(JUC)中提供了很多并发工具,这其中,很多我们耳熟能详的并发工具,譬如ReentrangLock.Semaphore,它们的实现都用到了一个共同的基类--AbstractQueuedS ...
- javascript DOM 编程艺术 札记1
一个重要观点 DOM 是指 文档对象模型,它对应浏览器实际认知的东西.html 文本本身和 html 加载到浏览器中显示的东西并不是完全一致的,后者就是 DOM 节点树,它是浏览器实际认知的东西.一个 ...
- C# Charts绘制多条曲线
一.创建winform工程 拖拽控件Chart 二.比如要绘制俩条曲线,设置Chart控件的属性Series 三.chart的属性根据自己的业务需求设计,我这里只设置了图标类型 代码: using S ...
- $Poj2054\ Color\ a\ Tree\ $ 贪心
$poj$ $Description$ 一颗树有 $n$ 个节点,这些节点被标号为:$1,2,3…n,$每个节点 $i$ 都有一个权值 $A[i]$. 现在要把这棵树的节点全部染色,染色的规则是: 根 ...
- JVM之GC回收信息详解
一.-XX:+PrintGCDetails 打印GC日志 参数配置:-Xms10M -Xmx10M -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+Pr ...