一条Sql的Spark之旅
背景
SQL作为一门标准的、通用的、简单的DSL,在大数据分析中有着越来越重要的地位;Spark在批处理引擎领域当前也是处于绝对的地位,而Spark2.0中的SparkSQL也支持ANSI-SQL 2003标准。因此SparkSQL在大数据分析中的地位不言而喻。
本文将通过分析一条SQL在Spark中的解析执行过程来梳理SparkSQL执行的一个流程。
案例分析
代码
val spark = SparkSession.builder().appName("TestSql").master("local[*]").enableHiveSupport().getOrCreate()
val df = spark.sql("select sepal_length,class from origin_csvload.csv_iris_qx order by sepal_length limit 10 ")
df.show(3)
我们在数仓中新建了一张表origin_csvload.csv_iris_qx,然后通过SparkSQL执行了一条SQL,由于整个过程由于是懒加载的,需要通过Terminal方法触发,此处我们选择show方法来触发。
源码分析
词法解析、语法解析以及分析
sql方法会执行以下3个重点:
sessionState.sqlParser.parsePlan(sqlText):将SQL字符串通过ANTLR解析成逻辑计划(Parsed Logical Plan)sparkSession.sessionState.executePlan(logicalPlan):执行逻辑计划,此处为懒加载,只新建QueryExecution实例,并不会触发实际动作。需要注意的是QueryExecution其实是包含了SQL解析执行的4个阶段计划(解析、分析、优化、执行)QueryExecution.assertAnalyzed():触发语法分析,得到分析计划(Analyzed Logical Plan)
def sql(sqlText: String): DataFrame = {
//1:Parsed Logical Plan
Dataset.ofRows(self, sessionState.sqlParser.parsePlan(sqlText))
}
def ofRows(sparkSession: SparkSession, logicalPlan: LogicalPlan): DataFrame = {
val qe = sparkSession.sessionState.executePlan(logicalPlan)//d-1
qe.assertAnalyzed()//d-2
new Dataset[Row](sparkSession, qe, RowEncoder(qe.analyzed.schema))
}
//d-1
def executePlan(plan: LogicalPlan): QueryExecution = new QueryExecution(sparkSession, plan)
//2:Analyzed Logical Plan
lazy val analyzed: LogicalPlansparkSession.sessionState.analyzer.executeAndCheck(logical)
解析计划和分析计划
sql解析后计划如下:
== Parsed Logical Plan ==
'GlobalLimit 10
+- 'LocalLimit 10
+- 'Sort ['sepal_length ASC NULLS FIRST], true
+- 'Project ['sepal_length, 'class]
+- 'UnresolvedRelation `origin_csvload`.`csv_iris_qx`
主要是将SQL一一对应地翻译成了catalyst的操作,此时数据表并没有被解析,只是简单地识别为表。而分析后的计划则包含了字段的位置、类型,表的具体类型(parquet)等信息。
== Analyzed Logical Plan ==
sepal_length: double, class: string
GlobalLimit 10
+- LocalLimit 10
+- Sort [sepal_length#0 ASC NULLS FIRST], true
+- Project [sepal_length#0, class#4]
+- SubqueryAlias `origin_csvload`.`csv_iris_qx`
+- Relation[sepal_length#0,sepal_width#1,petal_length#2,petal_width#3,class#4] parquet
此处有个比较有意思的点,UnresolvedRelation origin_csvload.csv_iris_qx被翻译成了一个子查询别名,读取文件出来的数据注册成了一个表,这个是不必要的,后续的优化会消除这个子查询别名。
优化以及执行
以DataSet的show方法为例,show的方法调用链为showString->getRows->take->head->withAction,我们先来看看withAction方法:
def head(n: Int): Array[T] = withAction("head", limit(n).queryExecution)(collectFromPlan)
private def withAction[U](name: String, qe: QueryExecution)(action: SparkPlan => U) = {
val
result= SQLExecution.withNewExecutionId(sparkSession, qe) {
action(qe.executedPlan)
}
result
}
withAction方法主要执行如下逻辑:
1. 拿到缓存的解析计划,使用遍历优化器执行解析计划,得到若干优化计划。
2. 获取第一个优化计划,遍历执行前优化获得物理执行计划,这是已经可以执行的计划了。
3. 执行物理计划,返回实际结果。至此,这条SQL之旅就结束了。
//3:Optimized Logical Plan,withCachedData为Analyzed Logical Plan,即缓存的变量analyzed
lazy val optimizedPlan: LogicalPlan = sparkSession.sessionState.optimizer.execute(withCachedData)
lazy val sparkPlan: SparkPlan = planner.plan(ReturnAnswer(optimizedPlan)).next()
//4:Physical Plan
lazy val executedPlan: SparkPlan = prepareForExecution(sparkPlan)
优化计划及物理计划
优化后的计划如下,可以看到SubqueryAliases已经没有了。
== Optimized Logical Plan ==
GlobalLimit 10
+- LocalLimit 10
+- Sort [sepal_length#0 ASC NULLS FIRST], true
+- Project [sepal_length#0, class#4]
+- Relation[sepal_length#0,sepal_width#1,petal_length#2,petal_width#3,class#4] parquet
具体的优化点如下图所示,行首有!表示优化的地方。
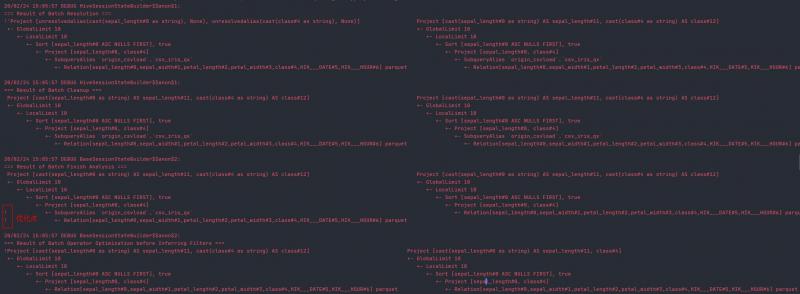
其中"=== Result of Batch Finish Analysis ==="表示"Finish Analysis"的规则簇(参见附录一)被应用成功,可以看到该规则簇中有一个消除子查询别名的规则EliminateSubqueryAliases
Batch("Finish Analysis", Once,
EliminateSubqueryAliases,
ReplaceExpressions,
ComputeCurrentTime,
GetCurrentDatabase(sessionCatalog),
RewriteDistinctAggregates)
最后根据物理计划生成规则(附录二)可以得到物理计划,这就是已经可以执行的计划了。具体如下:
== Physical Plan ==
TakeOrderedAndProject(limit=10, orderBy=[sepal_length#0 ASC NULLS FIRST], output=[sepal_length#0,class#4])
+- *(1) Project [sepal_length#0, class#4]
+- *(1) FileScan parquet origin_csvload.csv_iris_qx[sepal_length#0,class#4] Batched: true, Format: Parquet, Location: CatalogFileIndex[hdfs://di124:8020/user/hive/warehouse/origin_csvload.db/csv_iris_qx], PartitionCount: 1, PartitionFilters: [], PushedFilters: [], ReadSchema: struct<sepal_length:double,class:string>
总结
本文简述了一条SQL是如何从字符串经过词法解析、语法解析、规则优化等步骤转化成可执行的物理计划,最后以一个Terminal方法触发逻辑返回结果。本文可为后续SQL优化提供一定思路,之后可再详述具体的SQL优化原则。
附录一:优化方法
分析计划会依次应用如下优化:
- 前置优化。当前为空。
- 默认优化。主要有如下类别,每个类别分别有若干优化规则。
- Optimize Metadata Only Query
- Extract Python UDFs
- Prune File Source Table Partitions
- Parquet Schema Pruning
- Finish Analysis
- Union
- Subquery
- Replace Operators
- Aggregate
- Operator Optimizations
- Check Cartesian Products
- Decimal Optimizations
- Typed Filter Optimization
- LocalRelation
- OptimizeCodegen
- RewriteSubquery
- 后置优化。当前为空。
- 用户提供的优化。来自
experimentalMethods.extraOptimizations,当前也没有。
附录二:物理计划生成规则
生成物理执行计划的规则如下:
- PlanSubqueries
- EnsureRequirements
- CollapseCodegenStages
- ReuseExchange
- ReuseSubquery
本文由博客一文多发平台 OpenWrite 发布!
一条Sql的Spark之旅的更多相关文章
- 一条 SQL 在 Apache Spark 之旅
转载自过往记忆大数据 https://www.iteblog.com/archives/2561.html Spark SQL 是 Spark 众多组件中技术最复杂的组件之一,它同时支持 SQL 查询 ...
- 一条SQL语句的千回百转
SQL语言相信大家都不陌生,从本质上来说,它是一种结构化查询语言,是用来数据库之间的通信的编程语言.作为一名Java程序员,我们从Java角度来看,SQL语言相当于Java接口,而数据库是实现这个接口 ...
- 一条数据的HBase之旅,简明HBase入门教程-Write全流程
如果将上篇内容理解为一个冗长的"铺垫",那么,从本文开始,剧情才开始正式展开.本文基于提供的样例数据,介绍了写数据的接口,RowKey定义,数据在客户端的组装,数据路由,打包分发, ...
- 一条数据的HBase之旅,简明HBase入门教程-开篇
常见的HBase新手问题: 什么样的数据适合用HBase来存储? 既然HBase也是一个数据库,能否用它将现有系统中昂贵的Oracle替换掉? 存放于HBase中的数据记录,为何不直接存放于HDFS之 ...
- 小记---------spark组件与其他组件的比较 spark/mapreduce ;spark sql/hive ; spark streaming/storm
Spark与Hadoop的对比 Scala是Spark的主要编程语言,但Spark还支持Java.Python.R作为编程语言 Hadoop的编程语言是Java
- 师兄大厂面试遇到这条 SQL 数据分析题,差点含泪而归!
写在前面:我是「云祁」,一枚热爱技术.会写诗的大数据开发猿.昵称来源于王安石诗中一句 [ 云之祁祁,或雨于渊 ] ,甚是喜欢. 写博客一方面是对自己学习的一点点总结及记录,另一方面则是希望能够帮助更多 ...
- 一条Sql语句分组排序并且限制显示的数据条数
如果我想得到这样一个结果集:分组排序,并且每组限定记录集的数量,用一条SQL语句能办到吗? 比如说,我想找出学生期末考试中,每科的前3名,并按成绩排序,只用一条SQL语句,该怎么写? 表[TScore ...
- jdbc在mysql下一次执行多条sql脚本
默认连接mysql的时候一次只能执行一条sql.要批量执行sql需要在jdbcUrl中增加“allowMultiQueries=true”参数,完整jdbcUrl如下: jdbc:mysql://l ...
- JavaWeb 学习009-4个页面,5条sql语句(添加、查看、修改、删除)
===========++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++==+++++++++ 2016-12-3------ ...
随机推荐
- VirtualBox扩充磁盘&清空安装包
1.virtual box 扩充磁盘空间 D:\VirtualBox\VBoxManage.exe modifyhd "E:\virtual box\daisyyun\daisyyun.vd ...
- Oracle GoldenGate to Confluent with Kafka Connect
Confluent is a company founded by the team that built Apache Kafka. It builds a platform around Kafk ...
- [洛谷P4012] [网络流24题] 深海机器人问题
Description 深海资源考察探险队的潜艇将到达深海的海底进行科学考察. 潜艇内有多个深海机器人.潜艇到达深海海底后,深海机器人将离开潜艇向预定目标移动. 深海机器人在移动中还必须沿途采集海底生 ...
- latex之在windows环境下能够在latex中使用中文
今天要把前段时间的实验用英语先记录下来,自己就想根据原来会议的模版弄一个简易的页面(英语),突然想到之前用英文模板时是不能输入中文的,于是想着怎么在latex中输入中文,折腾了许久,终于成功了,现在分 ...
- git reset --hard HEAD^ 在cmd中执行报错
报错: D:\git-root\test>git reset --hard HEAD^ More? More? fatal: ambiguous argument 'HEAD ': unknow ...
- 《前端之路》--- 重温 Koa2
目录 一.简单介绍 二. 路由 三.请求数据 四. 静态资源加载 五. 静态资源加载 六. koa2加载模板引擎 七. koa2 中简单使用 mysql 数据库 八. koa2 中使用单元检测 九. ...
- ffplay的使用
https://www.cnblogs.com/renhui/p/8458802.html
- 本地Linux虚拟机内网穿透,服务器文件下载到本地磁盘
本地Linux虚拟内网穿透 把服务器文件下载到本地磁盘 https://natapp.cn/ 1.注册账户点击免费隧道
- Git详解之文件状态
前言 其实文件状态根据不同场景有不同的描述,例如:已跟踪.未跟踪.已暂存.已修改.未修改等等,乱七八糟的,今天个人根据自己的使用经验对其进行分类,如有不同建议或者更好的想法也可以留言评论,万分感谢! ...
- .net core 认证与授权(二)
前言 这篇紧接着一来写的,在第一篇中介绍了认证与授权,同时提出了这套机制其实就是模拟现实中的认证与授权. 同样这篇介绍在这套机制下,用户信息管理机制?这里就会问了,上一篇中认证和授权不是都ok了吗,怎 ...