python爬虫实战:基础爬虫(使用BeautifulSoup4等)
以前学习写爬虫程序时候,我没有系统地学习爬虫最基本的模块框架,只是实现自己的目标而写出来的,最近学习基础的爬虫,但含有完整的结构,大型爬虫含有的基础模块,此项目也有,“麻雀虽小,五脏俱全”,只是没有考虑优化和稳健性问题。
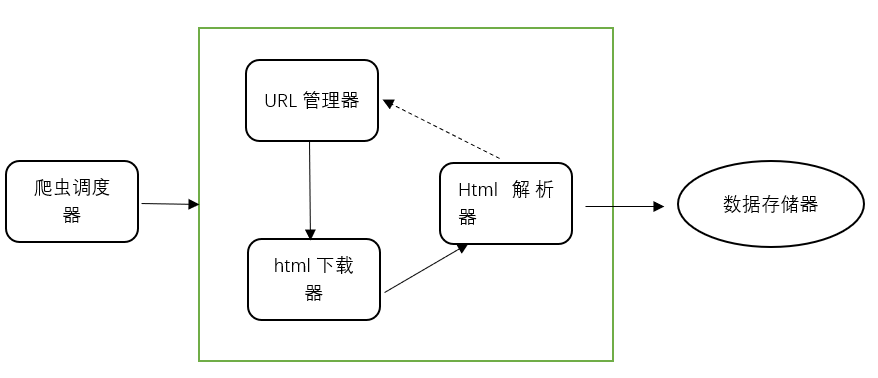 爬虫框架
爬虫框架
爬虫框架包括这五大模块,简单介绍作用:1.爬虫调度器:协调其他四大模块工作;2.URL管理器:就是管理提供爬取的链接,分为已爬取URL集合和未爬取URL集合;3.html下载器:下载URL的整个html网页;4.html解析器:将下载的网页进行解析,获得有效数据;5.数据存储器:存储解析后的数据,以文件或数据库形式存储。
项目准备爬取百度百科的一些名词解释和链接,这是小的项目,许多方法简化处理,做起来简洁有效。下面是具体步骤:
1、URL管理器
根据作用可知,它包括2个集合,已爬取和未爬取URL链接,所以使用python的set()类型进行去重,防止重复死循环。这里在实践时候我存在疑问,后面再讨论。去重方案主要有3种:1)内存去重,2)关系数据库去重,3)缓存数据库去重;明显地,大型成熟爬虫会选择后两种,避免内存大小限制,而现在尚未成熟的小项目,就使用第1种。
class UrlManager(): # URL管理器
def __init__(self):
self.new_urls = set() # 未爬取集合(去重)
self.old_urls = set() def has_new_url(self):
return self.new_url_size() != 0 # 判断是否有未爬取 def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url def add_new_url(self, url): # 将新的URL添加到未爬取集合
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url) def add_new_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url) def new_url_size(self):
# print(len(self.new_urls))
return len(self.new_urls) def old_url_size(self):
return len(self.old_urls)
几个函数作用很清晰,它会将新的链接加入未爬取集合,爬取过的URL就存入old_urls集合中。
2、HTML下载器
这里本来用requests包操作,但是我在后面运行程序时出现错误,所以后来我用了urllib包代替,而requests是它的高级封装,按往常也是用这个,具体是函数返回值出问题还是其他原因还没找出来,给出2个方法,需要大家指正。
import urllib.request class HtmlDownloader(object):
def download(self, url):
if url is None:
return None
user_agent = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64)'
headers = {'User-Agent': user_agent}
html_content = urllib.request.Request(url,headers=headers)#urlopen(url)
response=urllib.request.urlopen(html_content)
if response.getcode() == 200:
# print(response.read())
return response.read()#.decode('utf-8')
return None
这个是成功的方法,使用urllib打开URL链接,添加请求头可以更好的模拟正常访问,根据状态码返回内容。而存在问题的requests如下:
import requests#使用requests包爬取,结果提示页面不存在 class HtmlDownloader(object): # HTML下载器
def download(self, url):
if url is None:
return None
user_agent = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64)'
headers = {'User-Agent': user_agent}
respondse = requests.get(url, headers=headers)
# print(url)
if respondse.status_code != 200:
return None
# respondse.encoding = 'utf-8'
# print(respondse.content)
return respondse.content
测试时候可看出urllib的respondse.read()与requests的content都是bytes类型,从代码阅读上大体一样,经过几次尝试,以为是编解码问题,最后还是没能找出问题,所以用了urllib进行。
3、HTML下载器
这里使用BeautifulSoup4进行解析,bs4进行解析可以很简洁的几行代码完成,功能强大常使用。先分析网页结构格式,写出匹配表达式获取数据。

分析之后标题title = soup.find('dd', class_='lemmaWgt-lemmaTitle-title').find('h1')。获取tag中包含的所有文本内容,包括子孙tag中的内容,并将结果作为Unicode字符串返回,词条解释可写出式子匹配summary = soup.find('div', class_='lemma-summary')。
import re
from urllib.parse import urljoin
from bs4 import BeautifulSoup class HtmlParser(object):
def _get_new_data(self, page_url, soup):
data = {}
data['url'] = page_url
title = soup.find('dd', class_='lemmaWgt-lemmaTitle-title').find('h1')
data['title'] = title.get_text()
summary = soup.find('div', class_='lemma-summary')
data['summary'] = summary.get_text()
# print(summary_node.get_text())
return data def _get_new_urls(self, page_url, soup):
new_urls = set()
# print(new_urls)
links = soup.find_all('a', href=re.compile('/item/\w+')) for link in links:
new_url = link['href']
new_full_url = urljoin(page_url, new_url)
new_urls.add(new_full_url)
# print(new_full_url)
return new_urls def parser(self, page_url, html_cont):
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont, 'html.parser')
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
这里使用了正则表达式来匹配网页中的词条链接:links = soup.find_all('a', href=re.compile('/item/\w+'))
4、数据存储器
包括两个方法,store_data:将目标数据存到列表中;out_html:数据输出外存,这里存为html格式,也可以根据需要存为csv、txt形式。
import codecs class DataOutput(object):#数据存储器
def __init__(self):
self.datas=[] def store_data(self,data):
if data is None:
return
self.datas.append(data) def output_html(self):
fout=codecs.open('baike.html','w',encoding='utf-8')
fout.write("<html>")
fout.write("<head><meta charset='utf-8'/></head>")
fout.write("<body>")
fout.write("<table>")
for data in self.datas:
print(data["title"])
fout.write("<tr>")
fout.write("<td>%s</td>"%data['url'])
fout.write("<td>%s</td>"%data['title'])
fout.write("<td>%s</td>" % data['summary'])
fout.write("</tr>")
# self.datas.remove(data)
fout.write("</table>")
fout.write("</body>")
fout.write("</html>")
fout.close()
爬取数据量少的情况下可用以上方法,否则要使用分批存储,避免发生异常,数据丢失。
5、爬虫调度器
终于到最后步骤了,也是关键的一步,协调上面所有“器”,爬虫开始!
from craw_pratice.adataOutput import DataOutput
from craw_pratice.ahtmlDownloader import HtmlDownloader
from craw_pratice.ahtmlParser import HtmlParser
from craw_pratice.aurlManeger import UrlManager class spiderman(object):
def __init__(self):
self.manage = UrlManager()
self.downloader = HtmlDownloader()
self.parser = HtmlParser()
self.output = DataOutput() def crawl(self, root_url):
self.manage.add_new_url(root_url)
# 判断URL管理器中是否有新的URL,同时判断抓去了多少个URL
while (self.manage.has_new_url() and self.manage.old_url_size() < 100):
try:
new_url = self.manage.get_new_url() # 从管理器获取新的URL
print("已经抓取%s个链接: %s" % (self.manage.old_url_size(), new_url))
html = self.downloader.download(new_url) # 下载网页
# print(html)
new_urls, data = self.parser.parser(new_url, html) # 解析器抽取网页数据
print(data)
self.manage.add_new_urls(new_urls)
self.output.store_data(data) # 存储
except Exception: print("crawl failed")
self.output.output_html() if __name__ == "__main__":
root_url = 'https://baike.baidu.com/item/Python/407313'
spider_man = spiderman()
spider_man.crawl(root_url)
至此,整个爬虫项目完成了,效果如图:
这是我成功后的小总结,而过程并不是如此顺利,而是遇到小问题,对程序代码不断debug,比如:
上面说到的requests问题,导致爬取的链接不存在,一直提示页面不存在。后来采取urllib解决。还有第3中urljoin的调用,整个小爬虫项目我用到的是python3.6,已经把urlparse模块封装到urllib里面,所以不采用import parser。
这个项目实践让我学习到爬虫最基本的框架,各个功能都实现模块化,清晰简洁,为之后实现大型成熟的爬虫项目做了铺垫,分享学习心得,希望能学得更好,要继续努力!
python爬虫实战:基础爬虫(使用BeautifulSoup4等)的更多相关文章
- 爬虫实战:爬虫之 web 自动化终极杀手 ( 上)
欢迎大家前往腾讯云技术社区,获取更多腾讯海量技术实践干货哦~ 作者:陈象 导语: 最近写了好几个简单的爬虫,踩了好几个深坑,在这里总结一下,给大家在编写爬虫时候能给点思路.本次爬虫内容有:静态页面的爬 ...
- python应用之爬虫实战1 爬虫基本原理
知识内容: 1.爬虫是什么 2.爬虫的基本流程 3.request和response 4.python爬虫工具 参考:http://www.cnblogs.com/linhaifeng/article ...
- PHP 中的 cURL 爬虫实战基础
最近准备入手 PHP 爬虫,发现 PHP 的 cURL 这一知识点不可越过.本文探讨基础实战,需要提前了解命令行的使用并会进行 PHP 的环境搭建. cURL 的概念 cURL,Client URL ...
- Python 爬虫实战
图片爬虫实战 链接爬虫实战 糗事百科爬虫实战 微信爬虫实战 多线程爬虫实战
- python网络爬虫实战PDF高清完整版免费下载|百度云盘|Python基础教程免费电子书
点击获取提取码:vg1y python网络爬虫实战帮助读者学习Python并开发出符合自己要求的网络爬虫.网络爬虫,又被称为网页蜘蛛,网络机器人,是一种按照一定的规则,自动地抓取互联网信息的程序或者脚 ...
- Python实战:爬虫的基础
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用的名字还有蚂蚁.自动索引.模拟程序或者蠕 ...
- python爬虫实战:利用scrapy,短短50行代码下载整站短视频
近日,有朋友向我求助一件小事儿,他在一个短视频app上看到一个好玩儿的段子,想下载下来,可死活找不到下载的方法.这忙我得帮,少不得就抓包分析了一下这个app,找到了视频的下载链接,帮他解决了这个小问题 ...
- Java基础-爬虫实战之爬去校花网网站内容
Java基础-爬虫实战之爬去校花网网站内容 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 爬虫这个实现点我压根就没有把它当做重点,也没打算做网络爬虫工程师,说起爬虫我更喜欢用Pyt ...
- Python爬虫实战八之利用Selenium抓取淘宝匿名旺旺
更新 其实本文的初衷是为了获取淘宝的非匿名旺旺,在淘宝详情页的最下方有相关评论,含有非匿名旺旺号,快一年了淘宝都没有修复这个. 可就在今天,淘宝把所有的账号设置成了匿名显示,SO,获取非匿名旺旺号已经 ...
- Python爬虫实战六之抓取爱问知识人问题并保存至数据库
大家好,本次为大家带来的是抓取爱问知识人的问题并将问题和答案保存到数据库的方法,涉及的内容包括: Urllib的用法及异常处理 Beautiful Soup的简单应用 MySQLdb的基础用法 正则表 ...
随机推荐
- 简述http协议及抓包分析
1:HTTP请求头和响应头的格式 1:HTTP请求格式:<request-line><headers><blank line>[<request-body&g ...
- scrapy基本的流程 糗事百科
https://www.cnblogs.com/c-x-a/p/9889623.html 创建scrapy工程 1.scrapy startproject xxx xxx就是你的项目名,这里我们给我们 ...
- [bzoj2668] [洛谷P3159] [cqoi2012] 交换棋子
Description 有一个n行m列的黑白棋盘,你每次可以交换两个相邻格子(相邻是指有公共边或公共顶点)中的棋子,最终达到目标状态.要求第i行第j列的格子只能参与mi,j次交换. Input 第一行 ...
- Myeclipse 2017 下载+安装+激活+集成配置【JRE 8+Tomcat 9+MySQL 5.7.29】
Myeclipse 2017 的下载 Myeclipse 2017 下载地址:https://www.jianguoyun.com/p/DTEBo1cQ6LnsBxj9984C Myeclipse 2 ...
- python 3 创建虚拟环境(Win10)
python 3 创建虚拟环境(Win10) ①为什么要用虚拟环境? 为了解决一个环境多个项目的版本冲突问题 ②如何创建虚拟环境? 用窗口键+R来打开win10的运行窗口,然后在运行输入框输入cmd, ...
- linux--->linux下composer 安装
composer 安装 进入var/src目录中 下载composer安装包 curl -sS https://getcomposer.org/installer | php 设置全局访问 sudo ...
- Nginx(二) 常用配置
全局配置段 # 允许运行nginx服务器的用户和用户组 user www-data; # 并发连接数处理(进程数量),跟cpu核数保存一致: worker_processes auto; # 存放 n ...
- Linux 常用工具iptables
iptables简介 netfilter/iptables(简称为iptables)组成Linux平台下的包过滤防火墙,与大多数的Linux软件一样,这个包过滤防火墙是免费的,它可以代替昂贵的商业防火 ...
- Windows环境安装与配置RocketMQ
1.下载RocketMQ http://rocketmq.apache.org/release_notes/release-notes-4.3.0/ 2.解压下载的安装包rocketmq-all-4. ...
- mongodb centos7 安装
安装MongoDB的方法有很多种,可以源代码安装,在CentOS也可以用yum源安装的方法.由于MongoDB更新得比较快,我比较喜欢用yum源安装的方法.64位Centos下的安装步骤如下: 1.准 ...