pytorch bert 源码解读
https://daiwk.github.io/posts/nlp-bert.html
目录
参考最强NLP预训练模型!谷歌BERT横扫11项NLP任务记录
参考https://www.zhihu.com/question/298203515/answer/509703208
概述
本文介绍了一种新的语言表征模型BERT——来自Transformer的双向编码器表征。与最近的语言表征模型不同,BERT旨在基于所有层的左、右语境来预训练深度双向表征。BERT是首个在大批句子层面和token层面任务中取得当前最优性能的基于微调的表征模型,其性能超越许多使用任务特定架构的系统,刷新了11项NLP任务的当前最优性能记录。
目前将预训练语言表征应用于下游任务存在两种策略:feature-based的策略和fine-tuning策略。
- feature-based策略(如 ELMo)使用将预训练表征作为额外特征的任务专用架构。
- fine-tuning策略(如生成预训练 Transformer (OpenAI GPT))引入了任务特定最小参数,通过简单地微调预训练参数在下游任务中进行训练。
在之前的研究中,两种策略在预训练期间使用相同的目标函数,利用单向语言模型来学习通用语言表征。
作者认为现有的技术严重制约了预训练表征的能力,微调策略尤其如此。其主要局限在于标准语言模型是单向的,这限制了可以在预训练期间使用的架构类型。例如,OpenAI GPT使用的是从左到右的架构,其中每个token只能注意Transformer自注意力层中的先前token。这些局限对于句子层面的任务而言不是最佳选择,对于token级任务(如 SQuAD 问答)则可能是毁灭性的,因为在这种任务中,结合两个方向的语境至关重要。
BERT(Bidirectional Encoder Representations from Transformers)改进了基于微调的策略。
BERT提出一种新的预训练目标——遮蔽语言模型(masked language model,MLM),来克服上文提到的单向局限。MLM 的灵感来自 Cloze 任务(Taylor, 1953)。MLM随机遮蔽输入中的一些token,目标在于仅基于遮蔽词的语境来预测其原始词汇id。与从左到右的语言模型预训练不同,MLM目标允许表征融合左右两侧的语境,从而预训练一个深度双向Transformer。除了 MLM,我们还引入了一个“下一句预测”(next sentence prediction)任务,该任务联合预训练文本对表征。
贡献:
- 展示了双向预训练语言表征的重要性。不同于 Radford 等人(2018)使用单向语言模型进行预训练,BERT使用MLM预训练深度双向表征。本研究与 Peters 等人(2018)的研究也不同,后者使用的是独立训练的从左到右和从右到左LM的浅层级联。
- 证明了预训练表征可以消除对许多精心设计的任务特定架构的需求。BERT是首个在大批句子层面和token层面任务中取得当前最优性能的基于微调的表征模型,其性能超越许多使用任务特定架构的系统。
- BERT 刷新了11项NLP任务的当前最优性能记录。本论文还报告了BERT的模型简化测试(ablation study),证明该模型的双向特性是最重要的一项新贡献。代码和预训练模型将发布在goo.gl/language/bert。
BERT
模型架构
BERT 旨在基于所有层的左、右语境来预训练深度双向表征。因此,预训练的 BERT 表征可以仅用一个额外的输出层进行微调,进而为很多任务(如问答和语言推断任务)创建当前最优模型,无需对任务特定架构做出大量修改。
BERT 的模型架构是一个多层双向Transformer编码器,基于Vaswani 等人 (2017)描述的原始实现,在tensor2tensor库中发布(当然,可以抽空看看https://daiwk.github.io/posts/platform-tensor-to-tensor.html和https://daiwk.github.io/posts/platform-tensor-to-tensor-coding.html)。
本文中,我们将层数(即Transformer块)表示为\(L\),将隐层的size表示为\(H\)、自注意力头数表示为\(A\)。在所有实验中,我们将feed-forward/filter的size设置为\(4H\),即H=768时为3072,H=1024时为4096。我们主要看下在两种模型尺寸上的结果:
\(BERT_{BASE}\): L=12, H=768, A=12, Total Parameters=110M\(BERT_{LARGE}\): L=24, H=1024, A=16, Total Parameters=340M
其中,\(BERT_{BASE}\)和OpenAI GPT的大小是一样的。BERT Transformer使用双向自注意力机制,而GPT Transformer使用受限的自注意力机制,导致每个token只能关注其左侧的语境。双向Transformer在文献中通常称为“Transformer 编码器”,而只关注左侧语境的版本则因能用于文本生成而被称为“Transformer 解码器”。
下图显示了BERT/GPT Transformer/ELMo的结构区别:
![]()
- BERT 使用双向Transformer
- OpenAI GPT 使用从左到右的Transformer
- ELMo 使用独立训练的从左到右和从右到左LSTM的级联来生成下游任务的特征。
三种模型中,只有BERT表征会基于所有层中的左右两侧语境。
Input Representation
论文的输入表示(input representation)能够在一个token序列中明确地表示单个文本句子或一对文本句子(例如, [Question, Answer])。对于给定token,其输入表示通过对相应的token、segment和position embeddings进行求和来构造:
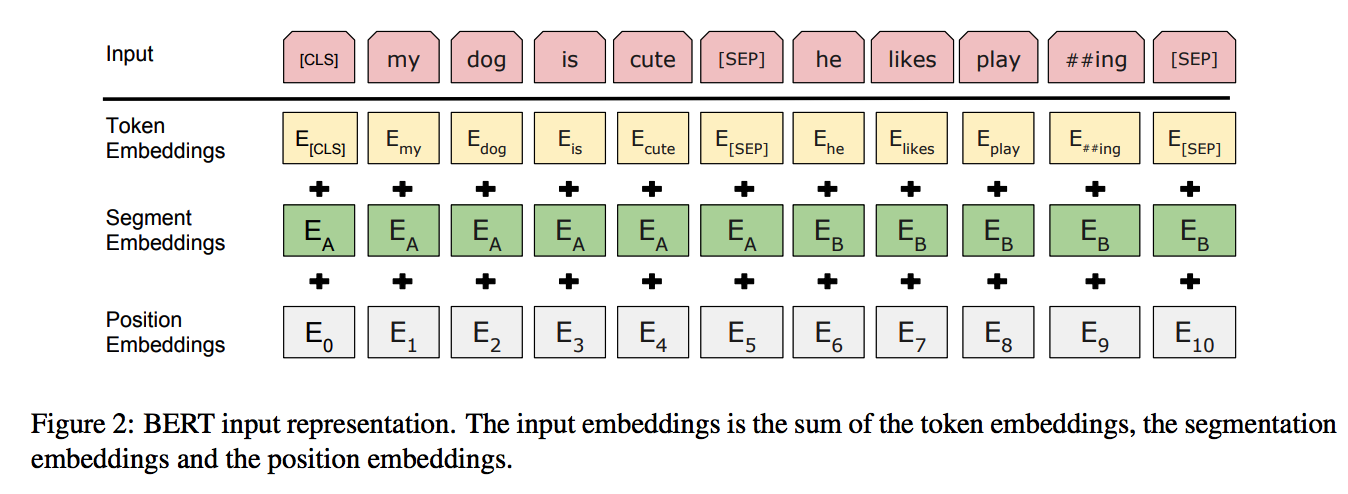
- 使用WordPiece嵌入【GNMT,Google’s neural machine translation system: Bridging the gap between human and machine translation】和30,000个token的词汇表。用##表示分词。
- 使用learned positional embeddings,支持的序列长度最多为512个token。
- 每个序列的第一个token始终是特殊分类嵌入([CLS])。对应于该token的最终隐藏状态(即,Transformer的输出)被用作分类任务的聚合序列表示。对于非分类任务,将忽略此向量。
- 句子对被打包成一个序列。以两种方式区分句子。
- 首先,用特殊标记([SEP])将它们分开。
- 其次,添加一个learned sentence A嵌入到第一个句子的每个token中,一个sentence B嵌入到第二个句子的每个token中。
- 对于单个句子输入,只使用 sentence A嵌入。
Pre-training Tasks
- 它在训练双向语言模型时以减小的概率把少量的词替成了Mask或者另一个随机的词。感觉其目的在于使模型被迫增加对上下文的记忆。(知乎的回答)
- 增加了一个预测下一句的loss。
Task #1: Masked LM
标准条件语言模型只能从左到右或从右到左进行训练,因为双向条件作用将允许每个单词在多层上下文中间接地“see itself”。
为了训练一个深度双向表示(deep bidirectional representation),研究团队采用了一种简单的方法,即随机屏蔽(masking)部分输入token,然后只预测那些被屏蔽的token。论文将这个过程称为“masked LM”(MLM),尽管在文献中它经常被称为Cloze任务(Taylor, 1953)。
在这个例子中,与masked token对应的最终隐藏向量被输入到词汇表上的输出softmax中,就像在标准LM中一样。在团队所有实验中,随机地屏蔽了每个序列中15%的WordPiece token。与去噪的自动编码器(Vincent et al., 2008)相反,只预测masked words而不是重建整个输入。
虽然这确实能让团队获得双向预训练模型,但这种方法有两个缺点。
- 缺点1:预训练和finetuning之间不匹配,因为在finetuning期间从未看到
[MASK]token。
为了解决这个问题,团队并不总是用实际的[MASK]token替换被“masked”的词汇。相反,训练数据生成器随机选择15%的token。
例如在这个句子“my dog is hairy”中,它选择的token是“hairy”。然后,执行以下过程:
数据生成器将执行以下操作,而不是始终用[MASK]替换所选单词:
- 80%的时间:用
[MASK]标记替换单词,例如,my dog is hairy → my dog is [MASK] - 10%的时间:用一个随机的单词替换该单词,例如,
my dog is hairy → my dog is apple - 10%的时间:保持单词不变,例如,
my dog is hairy → my dog is hairy. 这样做的目的是将表示偏向于实际观察到的单词。
Transformer encoder不知道它将被要求预测哪些单词或哪些单词已被随机单词替换,因此它被迫保持每个输入token的分布式上下文表示。此外,因为随机替换只发生在所有token的1.5%(即15%的10%),这似乎不会损害模型的语言理解能力。
- 缺点2:每个batch只预测了15%的token,这表明模型可能需要更多的预训练步骤才能收敛。
团队证明MLM的收敛速度略慢于 left-to-right的模型(预测每个token),但MLM模型在实验上获得的提升远远超过增加的训练成本。
Task #2: Next Sentence Prediction
在为了训练一个理解句子的模型关系,预先训练一个二分类的下一句测任务,这一任务可以从任何单语语料库中生成。具体地说,当选择句子A和B作为预训练样本时,B有50%的可能是A的下一个句子,也有50%的可能是来自语料库的随机句子。例如:
Input =
[CLS] the man went to [MASK] store [SEP]
he bought a gallon [MASK] milk [SEP]
Label = IsNext
Input =
[CLS] the man [MASK] to the store [SEP]
penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
完全随机地选择了NotNext语句,最终的预训练模型在此任务上实现了97%-98%的准确率。
Pre-training Procedure
使用gelu激活函数(Bridging nonlinearities and stochastic regularizers with gaus- sian error linear units),在pytorch里实现如下:
class GELU(nn.Module):
"""
Paper Section 3.4, last paragraph notice that BERT used the GELU instead of RELU
"""
def forward(self, x):
return 0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3))))
Fine-tuning Procedure
Comparison of BERT and OpenAI GPT
实验
网络结构如下:
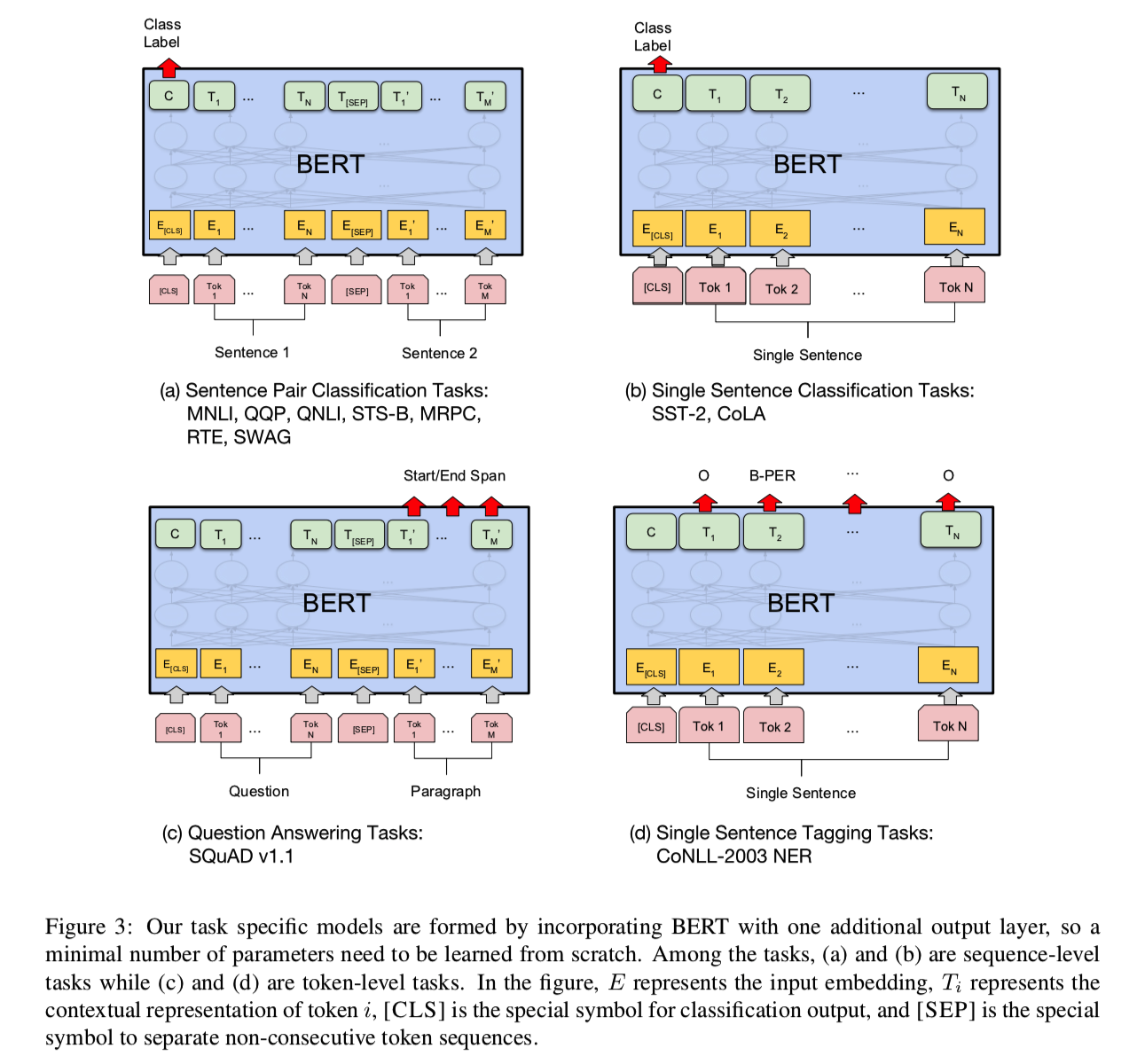
GLUE Datasets
GLUE Results
SQuAD v1.1
Named Entity Recognition
SWAG
Ablation Studies
Effect of Pre-training Tasks
Effect of Model Size
Effect of Number of Training Steps
Feature-based Approach with BERT
代码实现
pytorch版本
https://github.com/codertimo/BERT-pytorch
fork了一份:https://github.com/daiwk/BERT-pytorch
输入data/corpus.small:
Welcome to the \t the jungle \n
I can stay \t here all night \n
可视化,需要:
brew install graphviz # mac
pip3 install git+https://github.com/szagoruyko/pytorchviz
画出bert的架构图的方法(先生成vocab,如果机器的dot不支持pdf,只支持png/jpg等,需要在lib/python3.6/site-packages/torchviz/dot.py中把dot = Digraph(node_attr=node_attr, graph_attr=dict(size="12,12"))改成dot = Digraph(node_attr=node_attr, graph_attr=dict(size="12,12"), format="png")):
import torch
from torch import nn
from torchviz import make_dot, make_dot_from_trace
import sys
sys.path.append("./bert_pytorch-0.0.1a4.src/")
#from trainer import BERTTrainer
from model import BERTLM, BERT
from dataset import BERTDataset, WordVocab
from torch.utils.data import DataLoader
def demo():
lstm_cell = nn.LSTMCell(128, 128)
x = torch.randn(1, 128)
dot = make_dot(lstm_cell(x), params=dict(list(lstm_cell.named_parameters())))
file_out = "xx"
dot.render(file_out)
def bert_dot():
"""
"""
vocab_size = 128
train_dataset_path = "data/bert_train_data.xxx"
vocab_path = "data/vocab.all.xxx"
vocab = WordVocab.load_vocab(vocab_path)
train_dataset = BERTDataset(train_dataset_path, vocab, seq_len=20,
corpus_lines=2000, on_memory=True)
train_data_loader = DataLoader(train_dataset, batch_size=8, num_workers=8)
bert = BERT(len(vocab), hidden=256, n_layers=8, attn_heads=8)
device = torch.device("cpu")
mymodel = BERTLM(bert, vocab_size).to(device)
data_iter = train_data_loader
out_idx = 0
for data in data_iter:
data = {key: value.to(device) for key, value in data.items()}
if out_idx == 0:
g = make_dot(mymodel(data["bert_input"], data["segment_label"]), params=dict(mymodel.named_parameters()))
g.render("./bert-arch")
break
bert_dot()
可以画出这么个图。。图太大,自己下载看看
https://daiwk.github.io/assets/bert-arch.jpeg
{kind=link}
对应的pdf如
https://daiwk.github.io/assets/bert-arch.pdf
对应的dot文件
https://daiwk.github.io/assets/bert-arch
把dot文件转换成其他格式的方式:
input=./bert-arch
output=./bert-arch
dot $input -Tjpeg -o $output.jpeg
dot $input -Tpdf -o $output.pdf
设置一个layer的简单版pdf如下:
https://daiwk.github.io/assets/bert-arch-1layer.pdf
代码解读
transformer部分参考http://nlp.seas.harvard.edu/2018/04/03/attention.htm
可以学习下https://blog.csdn.net/stupid_3/article/details/83184691,讲得很细致呢!
基础知识
参考https://daiwk.github.io/posts/knowledge-pytorch-usage.html
position encoding
代码
class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + Variable(self.pe[:, :x.size(1)],
requires_grad=False)
return self.dropout(x)
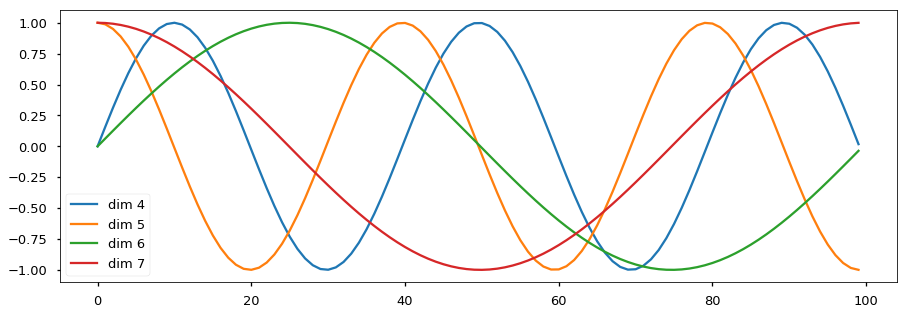
输入是shape为(max_len, d_model)的矩阵,d_model是emb的size。如下图,输入是一个max_len=100,d_model=20的矩阵,图中画的是这20维里的4、5、6、7每一维在100个position的取值。
bert里改名了一下:
class PositionalEmbedding(nn.Module):
def __init__(self, d_model, max_len=512):
super().__init__()
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model).float()
pe.require_grad = False
position = torch.arange(0, max_len).float().unsqueeze(1)
div_term = (torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model)).exp()
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
return self.pe[:, :x.size(1)]
而bert还有另外两个embedding,就是segment和token,这里用很简单的实现:
class SegmentEmbedding(nn.Embedding):
def __init__(self, embed_size=512):
### 输入是segment_label,表示是第1句话,第2句话,还是padding,所以num_embeddings是3
super().__init__(3, embed_size, padding_idx=0)
class TokenEmbedding(nn.Embedding):
def __init__(self, vocab_size, embed_size=512):
super().__init__(vocab_size, embed_size, padding_idx=0)
用的时候是把三者加起来:
class BERTEmbedding(nn.Module):
"""
BERT Embedding which is consisted with under features
1. TokenEmbedding : normal embedding matrix
2. PositionalEmbedding : adding positional information using sin, cos
2. SegmentEmbedding : adding sentence segment info, (sent_A:1, sent_B:2)
sum of all these features are output of BERTEmbedding
"""
def __init__(self, vocab_size, embed_size, dropout=0.1):
"""
:param vocab_size: total vocab size
:param embed_size: embedding size of token embedding
:param dropout: dropout rate
"""
super().__init__()
self.token = TokenEmbedding(vocab_size=vocab_size, embed_size=embed_size)
self.position = PositionalEmbedding(d_model=self.token.embedding_dim)
self.segment = SegmentEmbedding(embed_size=self.token.embedding_dim)
self.dropout = nn.Dropout(p=dropout)
self.embed_size = embed_size
def forward(self, sequence, segment_label):
x = self.token(sequence) + self.position(sequence) + self.segment(segment_label)
return self.dropout(x)
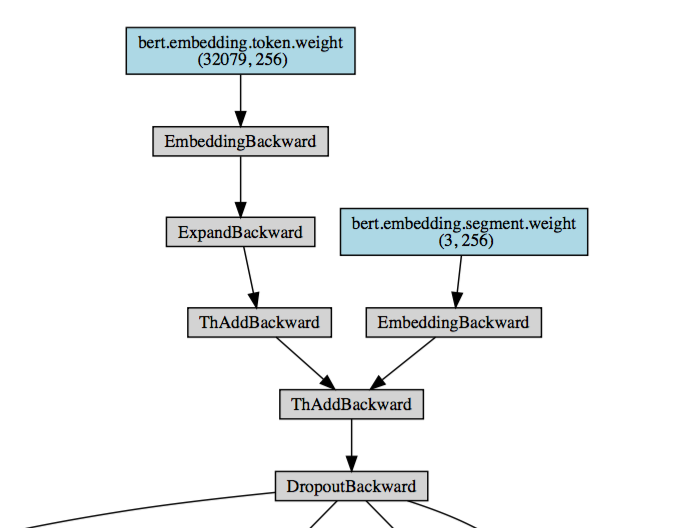
这部分画出来的图就应该是下面这个了:
position-wise feed forward
class PositionwiseFeedForward(nn.Module):
"Implements FFN equation."
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(F.relu(self.w_1(x))))
在bert中,把relu改为gelu,所以:
class GELU(nn.Module):
"""
Paper Section 3.4, last paragraph notice that BERT used the GELU instead of RELU
"""
def forward(self, x):
return 0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3))))
class PositionwiseFeedForward(nn.Module):
"Implements FFN equation."
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
self.activation = GELU()
def forward(self, x):
return self.w_2(self.dropout(self.activation(self.w_1(x))))
attention和Multi-head attention
代码如下:
def attention(query, key, value, mask=None, dropout=None):
"Compute 'Scaled Dot Product Attention'"
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) \
/ math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim = -1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"Take in model size and number of heads."
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
"Implements Figure 2"
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = \
[l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = attention(query, key, value, mask=mask,
dropout=self.dropout)
# 3) "Concat" using a view and apply a final linear.
x = x.transpose(1, 2).contiguous() \
.view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)
注:
画出来的图可以参考[https://daiwk.github.io/assets/bert-arch-1layer.pdf]
有4个Linear,其中三个分别和q,k,v相乘,最后一个和concat后的相乘。大小都是d_model,d_model。因为d_k=d_v=d_model/h,对于q来讲,有h个(d_k, d_model),所以一个(d_model, d_model)就行了。k,v同理。当然,后面还搞了下batches,所以画出来的图是q和k先bmm一下,再和v去bmm一下,最后的concat是就是view一下,然后再和最后那个linear去mm一下。
封装一下:
class Attention(nn.Module):
"""
Compute 'Scaled Dot Product Attention
"""
def forward(self, query, key, value, mask=None, dropout=None):
scores = torch.matmul(query, key.transpose(-2, -1)) \
/ math.sqrt(query.size(-1))
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
class MultiHeadedAttention(nn.Module):
"""
Take in model size and number of heads.
"""
def __init__(self, h, d_model, dropout=0.1):
super().__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linear_layers = nn.ModuleList([nn.Linear(d_model, d_model) for _ in range(3)])
self.output_linear = nn.Linear(d_model, d_model)
self.attention = Attention()
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
batch_size = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = [l(x).view(batch_size, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linear_layers, (query, key, value))]
# 2) Apply attention on all the projected vectors in batch.
x, attn = self.attention(query, key, value, mask=mask, dropout=self.dropout)
# 3) "Concat" using a view and apply a final linear.
x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.h * self.d_k)
return self.output_linear(x)
layernorm和sublayer
class LayerNorm(nn.Module):
"Construct a layernorm module (See citation for details)."
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
class SublayerConnection(nn.Module):
"""
A residual connection followed by a layer norm.
Note for code simplicity the norm is first as opposed to last.
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"Apply residual connection to any sublayer with the same size."
return x + self.dropout(sublayer(self.norm(x)))
transformer里的encoder:
class EncoderLayer(nn.Module):
"Encoder is made up of self-attn and feed forward (defined below)"
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size
def forward(self, x, mask):
"Follow Figure 1 (left) for connections."
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
decoder部分:
class Decoder(nn.Module):
"Generic N layer decoder with masking."
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)
class DecoderLayer(nn.Module):
"Decoder is made of self-attn, src-attn, and feed forward (defined below)"
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
"Follow Figure 1 (right) for connections."
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)
其中的mask部分:
def subsequent_mask(size):
"Mask out subsequent positions."
attn_shape = (1, size, size)
## np.triu:一个上三角矩阵(注意:这里是一个方阵)右上角都是1,左下角都是0
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
return torch.from_numpy(subsequent_mask) == 0
class Batch:
"Object for holding a batch of data with mask during training."
def __init__(self, src, trg=None, pad=0):
self.src = src
self.src_mask = (src != pad).unsqueeze(-2)
if trg is not None:
self.trg = trg[:, :-1]
self.trg_y = trg[:, 1:]
self.trg_mask = \
self.make_std_mask(self.trg, pad)
self.ntokens = (self.trg_y != pad).data.sum()
@staticmethod
def make_std_mask(tgt, pad):
"Create a mask to hide padding and future words."
tgt_mask = (tgt != pad).unsqueeze(-2)
tgt_mask = tgt_mask & Variable(
subsequent_mask(tgt.size(-1)).type_as(tgt_mask.data))
return tgt_mask
在产出数据时把mask加上:
def data_gen(V, batch, nbatches):
"Generate random data for a src-tgt copy task."
for i in range(nbatches):
data = torch.from_numpy(np.random.randint(1, V, size=(batch, 10)))
data[:, 0] = 1
src = Variable(data, requires_grad=False)
tgt = Variable(data, requires_grad=False)
yield Batch(src, tgt, 0)
整个模型:
class EncoderDecoder(nn.Module):
"""
A standard Encoder-Decoder architecture. Base for this and many
other models.
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def forward(self, src, tgt, src_mask, tgt_mask):
"Take in and process masked src and target sequences."
return self.decode(self.encode(src, src_mask), src_mask,
tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
class Generator(nn.Module):
"Define standard linear + softmax generation step."
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
return F.log_softmax(self.proj(x), dim=-1)
def make_model(src_vocab, tgt_vocab, N=6,
d_model=512, d_ff=2048, h=8, dropout=0.1):
"Helper: Construct a model from hyperparameters."
c = copy.deepcopy
attn = MultiHeadedAttention(h, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
position = PositionalEncoding(d_model, dropout)
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(DecoderLayer(d_model, c(attn), c(attn),
c(ff), dropout), N),
nn.Sequential(Embeddings(d_model, src_vocab), c(position)),
nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)),
Generator(d_model, tgt_vocab))
# This was important from their code.
# Initialize parameters with Glorot / fan_avg.
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform(p)
return model
bert中的transformerblock(相当于只有encoder,但是加入了自己的mask):
class TransformerBlock(nn.Module):
"""
Bidirectional Encoder = Transformer (self-attention)
Transformer = MultiHead_Attention + Feed_Forward with sublayer connection
"""
def __init__(self, hidden, attn_heads, feed_forward_hidden, dropout):
"""
:param hidden: hidden size of transformer
:param attn_heads: head sizes of multi-head attention
:param feed_forward_hidden: feed_forward_hidden, usually 4*hidden_size
:param dropout: dropout rate
"""
super().__init__()
self.attention = MultiHeadedAttention(h=attn_heads, d_model=hidden)
self.feed_forward = PositionwiseFeedForward(d_model=hidden, d_ff=feed_forward_hidden, dropout=dropout)
self.input_sublayer = SublayerConnection(size=hidden, dropout=dropout)
self.output_sublayer = SublayerConnection(size=hidden, dropout=dropout)
self.dropout = nn.Dropout(p=dropout)
def forward(self, x, mask):
x = self.input_sublayer(x, lambda _x: self.attention.forward(_x, _x, _x, mask=mask))
x = self.output_sublayer(x, self.feed_forward)
return self.dropout(x)
完整的bert
class BERT(nn.Module):
"""
BERT model : Bidirectional Encoder Representations from Transformers.
"""
def __init__(self, vocab_size, hidden=768, n_layers=12, attn_heads=12, dropout=0.1):
"""
:param vocab_size: vocab_size of total words
:param hidden: BERT model hidden size
:param n_layers: numbers of Transformer blocks(layers)
:param attn_heads: number of attention heads
:param dropout: dropout rate
"""
super().__init__()
self.hidden = hidden
self.n_layers = n_layers
self.attn_heads = attn_heads
# paper noted they used 4*hidden_size for ff_network_hidden_size
self.feed_forward_hidden = hidden * 4
# embedding for BERT, sum of positional, segment, token embeddings
self.embedding = BERTEmbedding(vocab_size=vocab_size, embed_size=hidden)
# multi-layers transformer blocks, deep network
self.transformer_blocks = nn.ModuleList(
[TransformerBlock(hidden, attn_heads, hidden * 4, dropout) for _ in range(n_layers)])
def forward(self, x, segment_info):
# attention masking for padded token
# torch.ByteTensor([batch_size, 1, seq_len, seq_len)
mask = (x > 0).unsqueeze(1).repeat(1, x.size(1), 1).unsqueeze(1)
# embedding the indexed sequence to sequence of vectors
x = self.embedding(x, segment_info)
# running over multiple transformer blocks
for transformer in self.transformer_blocks:
x = transformer.forward(x, mask)
return x
对于pretrain来讲:
class BERTLM(nn.Module):
"""
BERT Language Model
Next Sentence Prediction Model + Masked Language Model
"""
def __init__(self, bert: BERT, vocab_size):
"""
:param bert: BERT model which should be trained
:param vocab_size: total vocab size for masked_lm
"""
super().__init__()
self.bert = bert
self.next_sentence = NextSentencePrediction(self.bert.hidden)
self.mask_lm = MaskedLanguageModel(self.bert.hidden, vocab_size)
def forward(self, x, segment_label):
x = self.bert(x, segment_label)
return self.next_sentence(x), self.mask_lm(x)
class NextSentencePrediction(nn.Module):
"""
2-class classification model : is_next, is_not_next
"""
def __init__(self, hidden):
"""
:param hidden: BERT model output size
"""
super().__init__()
self.linear = nn.Linear(hidden, 2)
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, x):
return self.softmax(self.linear(x[:, 0]))
class MaskedLanguageModel(nn.Module):
"""
predicting origin token from masked input sequence
n-class classification problem, n-class = vocab_size
"""
def __init__(self, hidden, vocab_size):
"""
:param hidden: output size of BERT model
:param vocab_size: total vocab size
"""
super().__init__()
self.linear = nn.Linear(hidden, vocab_size)
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, x):
return self.softmax(self.linear(x))
整个训练过程:
class BERTTrainer:
"""
BERTTrainer make the pretrained BERT model with two LM training method.
1. Masked Language Model : 3.3.1 Task #1: Masked LM
2. Next Sentence prediction : 3.3.2 Task #2: Next Sentence Prediction
please check the details on README.md with simple example.
"""
def __init__(self, bert: BERT, vocab_size: int,
train_dataloader: DataLoader, test_dataloader: DataLoader = None,
lr: float = 1e-4, betas=(0.9, 0.999), weight_decay: float = 0.01, warmup_steps=10000,
with_cuda: bool = True, cuda_devices=None, log_freq: int = 10):
"""
:param bert: BERT model which you want to train
:param vocab_size: total word vocab size
:param train_dataloader: train dataset data loader
:param test_dataloader: test dataset data loader [can be None]
:param lr: learning rate of optimizer
:param betas: Adam optimizer betas
:param weight_decay: Adam optimizer weight decay param
:param with_cuda: traning with cuda
:param log_freq: logging frequency of the batch iteration
"""
# Setup cuda device for BERT training, argument -c, --cuda should be true
cuda_condition = torch.cuda.is_available() and with_cuda
self.device = torch.device("cuda:0" if cuda_condition else "cpu")
# This BERT model will be saved every epoch
self.bert = bert
# Initialize the BERT Language Model, with BERT model
self.model = BERTLM(bert, vocab_size).to(self.device)
# Distributed GPU training if CUDA can detect more than 1 GPU
if with_cuda and torch.cuda.device_count() > 1:
print("Using %d GPUS for BERT" % torch.cuda.device_count())
self.model = nn.DataParallel(self.model, device_ids=cuda_devices)
# Setting the train and test data loader
self.train_data = train_dataloader
self.test_data = test_dataloader
# Setting the Adam optimizer with hyper-param
self.optim = Adam(self.model.parameters(), lr=lr, betas=betas, weight_decay=weight_decay)
self.optim_schedule = ScheduledOptim(self.optim, self.bert.hidden, n_warmup_steps=warmup_steps)
# Using Negative Log Likelihood Loss function for predicting the masked_token
self.criterion = nn.NLLLoss(ignore_index=0)
self.log_freq = log_freq
print("Total Parameters:", sum([p.nelement() for p in self.model.parameters()]))
def train(self, epoch):
self.iteration(epoch, self.train_data)
def test(self, epoch):
self.iteration(epoch, self.test_data, train=False)
def iteration(self, epoch, data_loader, train=True):
"""
loop over the data_loader for training or testing
if on train status, backward operation is activated
and also auto save the model every peoch
:param epoch: current epoch index
:param data_loader: torch.utils.data.DataLoader for iteration
:param train: boolean value of is train or test
:return: None
"""
str_code = "train" if train else "test"
# Setting the tqdm progress bar
data_iter = tqdm.tqdm(enumerate(data_loader),
desc="EP_%s:%d" % (str_code, epoch),
total=len(data_loader),
bar_format="{l_bar}{r_bar}")
avg_loss = 0.0
total_correct = 0
total_element = 0
for i, data in data_iter:
# 0. batch_data will be sent into the device(GPU or cpu)
data = {key: value.to(self.device) for key, value in data.items()}
# 1. forward the next_sentence_prediction and masked_lm model
next_sent_output, mask_lm_output = self.model.forward(data["bert_input"], data["segment_label"])
# 2-1. NLL(negative log likelihood) loss of is_next classification result
next_loss = self.criterion(next_sent_output, data["is_next"])
# 2-2. NLLLoss of predicting masked token word
mask_loss = self.criterion(mask_lm_output.transpose(1, 2), data["bert_label"])
# 2-3. Adding next_loss and mask_loss : 3.4 Pre-training Procedure
loss = next_loss + mask_loss
# 3. backward and optimization only in train
if train:
self.optim_schedule.zero_grad()
loss.backward()
self.optim_schedule.step_and_update_lr()
# next sentence prediction accuracy
correct = next_sent_output.argmax(dim=-1).eq(data["is_next"]).sum().item()
avg_loss += loss.item()
total_correct += correct
total_element += data["is_next"].nelement()
post_fix = {
"epoch": epoch,
"iter": i,
"avg_loss": avg_loss / (i + 1),
"avg_acc": total_correct / total_element * 100,
"loss": loss.item()
}
if i % self.log_freq == 0:
data_iter.write(str(post_fix))
print("EP%d_%s, avg_loss=" % (epoch, str_code), avg_loss / len(data_iter), "total_acc=",
total_correct * 100.0 / total_element)
def save(self, epoch, file_path="output/bert_trained.model"):
"""
Saving the current BERT model on file_path
:param epoch: current epoch number
:param file_path: model output path which gonna be file_path+"ep%d" % epoch
:return: final_output_path
"""
output_path = file_path + ".ep%d" % epoch
torch.save(self.bert.cpu(), output_path)
self.bert.to(self.device)
print("EP:%d Model Saved on:" % epoch, output_path)
return output_path
vocab和dataset
vocab部分:
from collections import Counter
class TorchVocab(object):
"""Defines a vocabulary object that will be used to numericalize a field.
Attributes:
freqs: A collections.Counter object holding the frequencies of tokens
in the data used to build the Vocab.
stoi: A collections.defaultdict instance mapping token strings to
numerical identifiers.
itos: A list of token strings indexed by their numerical identifiers.
"""
def __init__(self, counter, max_size=None, min_freq=1, specials=['<pad>', '<oov>'],
vectors=None, unk_init=None, vectors_cache=None):
"""Create a Vocab object from a collections.Counter.
Arguments:
counter: collections.Counter object holding the frequencies of
each value found in the data.
max_size: The maximum size of the vocabulary, or None for no
maximum. Default: None.
min_freq: The minimum frequency needed to include a token in the
vocabulary. Values less than 1 will be set to 1. Default: 1.
specials: The list of special tokens (e.g., padding or eos) that
will be prepended to the vocabulary in addition to an <unk>
token. Default: ['<pad>']
vectors: One of either the available pretrained vectors
or custom pretrained vectors (see Vocab.load_vectors);
or a list of aforementioned vectors
unk_init (callback): by default, initialize out-of-vocabulary word vectors
to zero vectors; can be any function that takes in a Tensor and
returns a Tensor of the same size. Default: torch.Tensor.zero_
vectors_cache: directory for cached vectors. Default: '.vector_cache'
"""
self.freqs = counter
counter = counter.copy()
min_freq = max(min_freq, 1)
self.itos = list(specials)
# frequencies of special tokens are not counted when building vocabulary
# in frequency order
for tok in specials:
del counter[tok]
max_size = None if max_size is None else max_size + len(self.itos)
# sort by frequency, then alphabetically
words_and_frequencies = sorted(counter.items(), key=lambda tup: tup[0])
words_and_frequencies.sort(key=lambda tup: tup[1], reverse=True)
for word, freq in words_and_frequencies:
if freq < min_freq or len(self.itos) == max_size:
break
self.itos.append(word)
# stoi is simply a reverse dict for itos
self.stoi = {tok: i for i, tok in enumerate(self.itos)}
self.vectors = None
if vectors is not None:
self.load_vectors(vectors, unk_init=unk_init, cache=vectors_cache)
else:
assert unk_init is None and vectors_cache is None
def __eq__(self, other):
if self.freqs != other.freqs:
return False
if self.stoi != other.stoi:
return False
if self.itos != other.itos:
return False
if self.vectors != other.vectors:
return False
return True
def __len__(self):
return len(self.itos)
def vocab_rerank(self):
self.stoi = {word: i for i, word in enumerate(self.itos)}
def extend(self, v, sort=False):
words = sorted(v.itos) if sort else v.itos
for w in words:
if w not in self.stoi:
self.itos.append(w)
self.stoi[w] = len(self.itos) - 1
class Vocab(TorchVocab):
def __init__(self, counter, max_size=None, min_freq=1):
self.pad_index = 0
self.unk_index = 1
self.eos_index = 2
self.sos_index = 3
self.mask_index = 4
super().__init__(counter, specials=["<pad>", "<unk>", "<eos>", "<sos>", "<mask>"],
max_size=max_size, min_freq=min_freq)
def to_seq(self, sentece, seq_len, with_eos=False, with_sos=False) -> list:
pass
def from_seq(self, seq, join=False, with_pad=False):
pass
@staticmethod
def load_vocab(vocab_path: str) -> 'Vocab':
with open(vocab_path, "rb") as f:
return pickle.load(f)
def save_vocab(self, vocab_path):
with open(vocab_path, "wb") as f:
pickle.dump(self, f)
# Building Vocab with text files
class WordVocab(Vocab):
def __init__(self, texts, max_size=None, min_freq=1):
print("Building Vocab")
counter = Counter()
for line in tqdm.tqdm(texts):
if isinstance(line, list):
words = line
else:
words = line.replace("\n", "").replace("\t", "").split()
for word in words:
counter[word] += 1
super().__init__(counter, max_size=max_size, min_freq=min_freq)
def to_seq(self, sentence, seq_len=None, with_eos=False, with_sos=False, with_len=False):
if isinstance(sentence, str):
sentence = sentence.split()
seq = [self.stoi.get(word, self.unk_index) for word in sentence]
if with_eos:
seq += [self.eos_index] # this would be index 1
if with_sos:
seq = [self.sos_index] + seq
origin_seq_len = len(seq)
if seq_len is None:
pass
elif len(seq) <= seq_len:
seq += [self.pad_index for _ in range(seq_len - len(seq))]
else:
seq = seq[:seq_len]
return (seq, origin_seq_len) if with_len else seq
def from_seq(self, seq, join=False, with_pad=False):
words = [self.itos[idx]
if idx < len(self.itos)
else "<%d>" % idx
for idx in seq
if not with_pad or idx != self.pad_index]
return " ".join(words) if join else words
@staticmethod
def load_vocab(vocab_path: str) -> 'WordVocab':
with open(vocab_path, "rb") as f:
return pickle.load(f)
def build():
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("-c", "--corpus_path", required=True, type=str)
parser.add_argument("-o", "--output_path", required=True, type=str)
parser.add_argument("-s", "--vocab_size", type=int, default=None)
parser.add_argument("-e", "--encoding", type=str, default="utf-8")
parser.add_argument("-m", "--min_freq", type=int, default=1)
args = parser.parse_args()
with open(args.corpus_path, "r", encoding=args.encoding) as f:
vocab = WordVocab(f, max_size=args.vocab_size, min_freq=args.min_freq)
print("VOCAB SIZE:", len(vocab))
vocab.save_vocab(args.output_path)
main函数
print("Loading Vocab", args.vocab_path)
vocab = WordVocab.load_vocab(args.vocab_path)
print("Vocab Size: ", len(vocab))
print("Loading Train Dataset", args.train_dataset)
train_dataset = BERTDataset(args.train_dataset, vocab, seq_len=args.seq_len,
corpus_lines=args.corpus_lines, on_memory=args.on_memory)
print("Loading Test Dataset", args.test_dataset)
test_dataset = BERTDataset(args.test_dataset, vocab, seq_len=args.seq_len, on_memory=args.on_memory) \
if args.test_dataset is not None else None
print("Creating Dataloader")
train_data_loader = DataLoader(train_dataset, batch_size=args.batch_size, num_workers=args.num_workers)
test_data_loader = DataLoader(test_dataset, batch_size=args.batch_size, num_workers=args.num_workers) \
if test_dataset is not None else None
print("Building BERT model")
bert = BERT(len(vocab), hidden=args.hidden, n_layers=args.layers, attn_heads=args.attn_heads)
print("Creating BERT Trainer")
trainer = BERTTrainer(bert, len(vocab), train_dataloader=train_data_loader, test_dataloader=test_data_loader,
lr=args.lr, betas=(args.adam_beta1, args.adam_beta2), weight_decay=args.adam_weight_decay,
with_cuda=args.with_cuda, cuda_devices=args.cuda_devices, log_freq=args.log_freq)
print("Training Start")
for epoch in range(args.epochs):
trainer.train(epoch)
trainer.save(epoch, args.output_path)
if test_data_loader is not None:
trainer.test(epoch)
dataset部分:
from torch.utils.data import Dataset
import tqdm
import torch
import random
class BERTDataset(Dataset):
def __init__(self, corpus_path, vocab, seq_len, encoding="utf-8", corpus_lines=None, on_memory=True):
self.vocab = vocab
self.seq_len = seq_len
self.on_memory = on_memory
self.corpus_lines = corpus_lines
self.corpus_path = corpus_path
self.encoding = encoding
with open(corpus_path, "r", encoding=encoding) as f:
if self.corpus_lines is None and not on_memory:
for _ in tqdm.tqdm(f, desc="Loading Dataset", total=corpus_lines):
self.corpus_lines += 1
if on_memory:
self.lines = [line[:-1].split("\t")
for line in tqdm.tqdm(f, desc="Loading Dataset", total=corpus_lines)]
self.corpus_lines = len(self.lines)
if not on_memory:
self.file = open(corpus_path, "r", encoding=encoding)
self.random_file = open(corpus_path, "r", encoding=encoding)
for _ in range(random.randint(self.corpus_lines if self.corpus_lines < 1000 else 1000)):
self.random_file.__next__()
def __len__(self):
return self.corpus_lines
def __getitem__(self, item):
t1, t2, is_next_label = self.random_sent(item)
t1_random, t1_label = self.random_word(t1)
t2_random, t2_label = self.random_word(t2)
# [CLS] tag = SOS tag, [SEP] tag = EOS tag
t1 = [self.vocab.sos_index] + t1_random + [self.vocab.eos_index]
t2 = t2_random + [self.vocab.eos_index]
t1_label = [self.vocab.pad_index] + t1_label + [self.vocab.pad_index]
t2_label = t2_label + [self.vocab.pad_index]
segment_label = ([1 for _ in range(len(t1))] + [2 for _ in range(len(t2))])[:self.seq_len]
bert_input = (t1 + t2)[:self.seq_len]
bert_label = (t1_label + t2_label)[:self.seq_len]
padding = [self.vocab.pad_index for _ in range(self.seq_len - len(bert_input))]
bert_input.extend(padding), bert_label.extend(padding), segment_label.extend(padding)
output = {"bert_input": bert_input,
"bert_label": bert_label,
"segment_label": segment_label,
"is_next": is_next_label}
return {key: torch.tensor(value) for key, value in output.items()}
def random_word(self, sentence):
tokens = sentence.split()
output_label = []
for i, token in enumerate(tokens):
prob = random.random()
if prob < 0.15:
prob /= 0.15
# 80% randomly change token to mask token
if prob < 0.8:
tokens[i] = self.vocab.mask_index
# 10% randomly change token to random token
elif prob < 0.9:
tokens[i] = random.randrange(len(self.vocab))
# 10% randomly change token to current token
else:
tokens[i] = self.vocab.stoi.get(token, self.vocab.unk_index)
output_label.append(self.vocab.stoi.get(token, self.vocab.unk_index))
else:
tokens[i] = self.vocab.stoi.get(token, self.vocab.unk_index)
output_label.append(0)
return tokens, output_label
def random_sent(self, index):
t1, t2 = self.get_corpus_line(index)
# output_text, label(isNotNext:0, isNext:1)
if random.random() > 0.5:
return t1, t2, 1
else:
return t1, self.get_random_line(), 0
def get_corpus_line(self, item):
if self.on_memory:
return self.lines[item][0], self.lines[item][1]
else:
line = self.file.__next__()
if line is None:
self.file.close()
self.file = open(self.corpus_path, "r", encoding=self.encoding)
line = self.file.__next__()
t1, t2 = line[:-1].split("\t")
return t1, t2
def get_random_line(self):
if self.on_memory:
return self.lines[random.randrange(len(self.lines))][1]
line = self.file.__next__()
if line is None:
self.file.close()
self.file = open(self.corpus_path, "r", encoding=self.encoding)
for _ in range(random.randint(self.corpus_lines if self.corpus_lines < 1000 else 1000)):
self.random_file.__next__()
line = self.random_file.__next__()
return line[:-1].split("\t")[1]
官方版
原创文章,转载请注明出处!
本文链接:http://daiwk.github.io/posts/nlp-bert.html
pytorch bert 源码解读的更多相关文章
- Bert系列 源码解读 四 篇章
Bert系列(一)——demo运行 Bert系列(二)——模型主体源码解读 Bert系列(三)——源码解读之Pre-trainBert系列(四)——源码解读之Fine-tune 转载自: https: ...
- Bert系列(二)——源码解读之模型主体
本篇文章主要是解读模型主体代码modeling.py.在阅读这篇文章之前希望读者们对bert的相关理论有一定的了解,尤其是transformer的结构原理,网上的资料很多,本文内容对原理部分就不做过多 ...
- Bert系列(三)——源码解读之Pre-train
https://www.jianshu.com/p/22e462f01d8c pre-train是迁移学习的基础,虽然Google已经发布了各种预训练好的模型,而且因为资源消耗巨大,自己再预训练也不现 ...
- SDWebImage源码解读之SDWebImageDownloaderOperation
第七篇 前言 本篇文章主要讲解下载操作的相关知识,SDWebImageDownloaderOperation的主要任务是把一张图片从服务器下载到内存中.下载数据并不难,如何对下载这一系列的任务进行设计 ...
- SDWebImage源码解读 之 NSData+ImageContentType
第一篇 前言 从今天开始,我将开启一段源码解读的旅途了.在这里先暂时不透露具体解读的源码到底是哪些?因为也可能随着解读的进行会更改计划.但能够肯定的是,这一系列之中肯定会有Swift版本的代码. 说说 ...
- SDWebImage源码解读 之 UIImage+GIF
第二篇 前言 本篇是和GIF相关的一个UIImage的分类.主要提供了三个方法: + (UIImage *)sd_animatedGIFNamed:(NSString *)name ----- 根据名 ...
- SDWebImage源码解读 之 SDWebImageCompat
第三篇 前言 本篇主要解读SDWebImage的配置文件.正如compat的定义,该配置文件主要是兼容Apple的其他设备.也许我们真实的开发平台只有一个,但考虑各个平台的兼容性,对于框架有着很重要的 ...
- SDWebImage源码解读_之SDWebImageDecoder
第四篇 前言 首先,我们要弄明白一个问题? 为什么要对UIImage进行解码呢?难道不能直接使用吗? 其实不解码也是可以使用的,假如说我们通过imageNamed:来加载image,系统默认会在主线程 ...
- SDWebImage源码解读之SDWebImageCache(上)
第五篇 前言 本篇主要讲解图片缓存类的知识,虽然只涉及了图片方面的缓存的设计,但思想同样适用于别的方面的设计.在架构上来说,缓存算是存储设计的一部分.我们把各种不同的存储内容按照功能进行切割后,图片缓 ...
随机推荐
- 关于springmvc 只能在index.jsp页面显示图片的处理办法jsp页面无法显示图片
首先,已经配置好了mvc对静态资源的处理 只有index,jsp可以显示图片 其他页面同样的代码则不显示 后来折腾了半天,发现 index是static的父目录的级别文件 可以向下访问 但是其他的js ...
- 2019.9.29 csp-s模拟测试55 反思总结
不咕咕咕是一种美德[大雾] 头一次体会到爆肝写题解??? 这次考试我们没赶上,是后来掐着时间每个人自己考的.我最后的分数能拿到152…熟悉的一题AC两题爆炸. 强烈吐槽出题人起名走心 T1联: 发现每 ...
- Angular.js的自定义功能
1,自定义指令,在html中输入标签显示想要的指令 html script部分 2,标签中的属性的 有属性值时可以通过函数的参数返回属性值 没有属性值时可以设置属性值(自定义属性值) html部分 ...
- PHP--y2k38的解决方法已经时间格式的常用转换
y2k38又名千年虫问题,又称Uinx Millennium Bug,此漏洞将会影响到所有32位系统下用Unix时间戳整数来记录时间的PHP,及其它编程语言. 一个整型的变量所能保存的最大时间为203 ...
- Hadoop 无法启动的问题
最近乱搞把本来就快要挂了的hdfs又给弄坏了.问题如下, 应该是节点没有启动. [hadoop@namenode hadoop]$ hadoop dfsadmin -report Configured ...
- OpenLayers图层
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN"> <html> <head ...
- Java 分页对象
以前一直没有自己写过分页对象,自己模仿着写了一个分页对象,写完之后感觉也是挺简单的 package com.css.util; import java.io.Serializable;import j ...
- 每日算法之三十四:Multiply Strings
大数相乘,分别都是用字符串表示的两个大数.求相乘之后的结果表示. 首先我们应该考虑一下測试用例会有哪些,先准备測试用例对防御性编程会有比較大的帮助.可以考虑一些极端情况.有以下几种用例: 1)&quo ...
- [运维]Dell R710 raid配置 标签: raid运维 2017-04-15 19:35 581人阅读 评论(16)
Dell R系列的一些服务器,raid的配置都大同小异,公司大部分的服务器,都是Dell R710型号的,这个型号的raid界面配置起来还是很简单的,下面来跟随小编体验一下raid如何配置吧.ps:图 ...
- StatusBar用法
一.StatusBar组件介绍 StatusBar 是 React Native 0.20 起新增的跨平台组件,它可以用来设置并动态改变设备的状态栏显示特性. StatusBar 组件可以同时加载多个 ...