【转】KAFKA分布式消息系统
Kafka[1]是linkedin用于日志处理的分布式消息队列,linkedin的日志数据容量大,但对可靠性要求不高,其日志数据主要包括用户行为(登录、浏览、点击、分享、喜欢)以及系统运行日志(CPU、内存、磁盘、网络、系统及进程状态)。
当前很多的消息队列服务提供可靠交付保证,并默认是即时消费(不适合离线)。高可靠交付对linkedin的日志不是必须的,故可通过降低可靠性来提高性能,同时通过构建分布式的集群,允许消息在系统中累积,使得kafka同时支持离线和在线日志处理。
注:本文中发布者(publisher)与生产者(producer)可以互换,订阅者(subscriber)与消费者(consumer)可以互换。
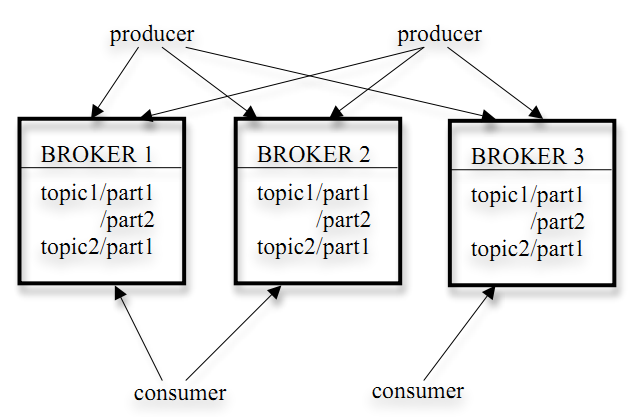
Kafka的架构如下图所示:
Kafka存储策略
- kafka以topic来进行消息管理,每个topic包含多个part(ition),每个part对应一个逻辑log,有多个segment组成。
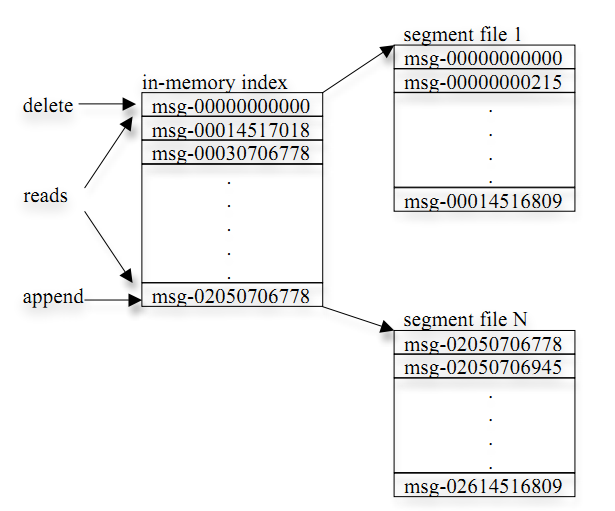
- 每个segment中存储多条消息(见下图),消息id由其逻辑位置决定,即从消息id可直接定位到消息的存储位置,避免id到位置的额外映射。
- 每个part在内存中对应一个index,记录每个segment中的第一条消息偏移。
- 发布者发到某个topic的消息会被均匀的分布到多个part上(随机或根据用户指定的回调函数进行分布),broker收到发布消息往对应part的最后一个segment上添加该消息,当某个segment上的消息条数达到配置值或消息发布时间超过阈值时,segment上的消息会被flush到磁盘,只有flush到磁盘上的消息订阅者才能订阅到,segment达到一定的大小后将不会再往该segment写数据,broker会创建新的segment。
发布与订阅接口
发布消息时,kafka client先构造一条消息,将消息加入到消息集set中(kafka支持批量发布,可以往消息集合中添加多条消息,一次行发布),send消息时,client需指定消息所属的topic。
订阅消息时,kafka client需指定topic以及partition num(每个partition对应一个逻辑日志流,如topic代表某个产品线,partition代表产品线的日志按天切分的结果),client订阅后,就可迭代读取消息,如果没有消息,client会阻塞直到有新的消息发布。consumer可以累积确认接收到的消息,当其确认了某个offset的消息,意味着之前的消息也都已成功接收到,此时broker会更新zookeeper上地offset registry(后面会讲到)。
高效的数据传输
- 发布者每次可发布多条消息(将消息加到一个消息集合中发布), sub每次迭代一条消息。
- 不创建单独的cache,使用系统的page cache。发布者顺序发布,订阅者通常比发布者滞后一点点,直接使用linux的page cache效果也比较后,同时减少了cache管理及垃圾收集的开销。
- 使用sendfile优化网络传输,减少一次内存拷贝。
无状态broker
- Broker没有副本机制,一旦broker宕机,该broker的消息将都不可用。
- Broker不保存订阅者的状态,由订阅者自己保存。
- 无状态导致消息的删除成为难题(可能删除的消息正在被订阅),kafka采用基于时间的SLA(服务水平保证),消息保存一定时间(通常为7天)后会被删除。
- 消息订阅者可以rewind back到任意位置重新进行消费,当订阅者故障时,可以选择最小的offset进行重新读取消费消息。
Consumer group
- 允许consumer group(包含多个consumer,如一个集群同时消费)对一个topic进行消费,不同的consumer group之间独立订阅。
- 为了对减小一个consumer group中不同consumer之间的分布式协调开销,指定partition为最小的并行消费单位,即一个group内的consumer只能消费不同的partition。
Zookeeper 协调控制
1. 管理broker与consumer的动态加入与离开。
2. 触发负载均衡,当broker或consumer加入或离开时会触发负载均衡算法,使得一
个consumer group内的多个consumer的订阅负载平衡。
3. 维护消费关系及每个partion的消费信息。
Zookeeper上的细节:
- 每个broker启动后会在zookeeper上注册一个临时的broker registry,包含broker的ip地址和端口号,所存储的topics和partitions信息。
- 每个consumer启动后会在zookeeper上注册一个临时的consumer registry:包含consumer所属的consumer group以及订阅的topics。
- 每个consumer group关联一个临时的owner registry和一个持久的offset registry。对于被订阅的每个partition包含一个owner registry,内容为订阅这个partition的consumer id;同时包含一个offset registry,内容为上一次订阅的offset。
消息交付保证
- kafka对消息的重复、丢失、错误以及顺序型没有严格的要求。
- kafka提供at-least-once delivery,即当consumer宕机后,有些消息可能会被重复delivery。
- 因每个partition只会被consumer group内的一个consumer消费,故kafka保证每个partition内的消息会被顺序的订阅。
- Kafka为每条消息为每条消息计算CRC校验,用于错误检测,crc校验不通过的消息会直接被丢弃掉。
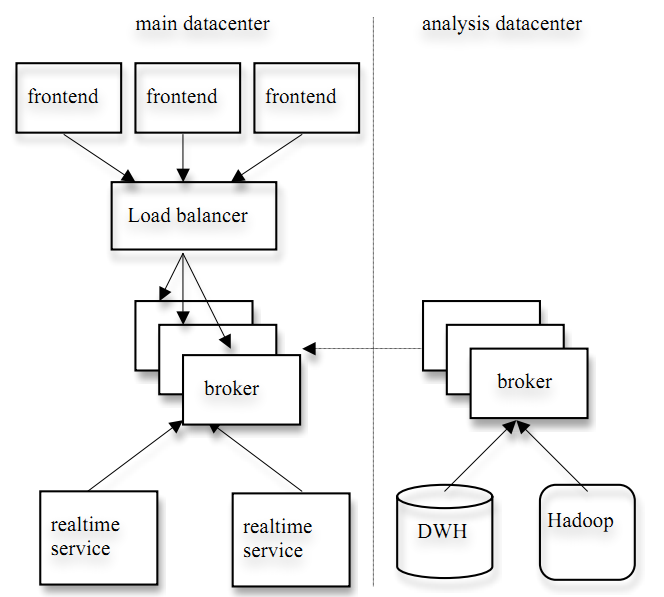
Linkedin的应用环境
如下图,左边的应用于日志数据的在线实时处理,右边的应用于日志数据的离线分析(现将日志pull至hadoop或DWH中)。
Kafka的性能
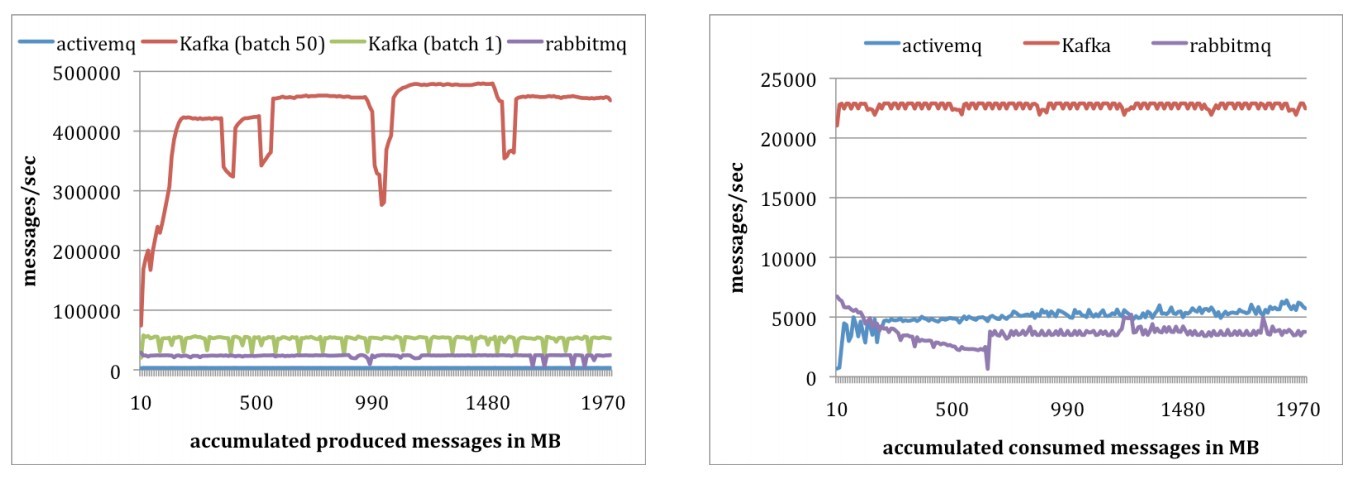
测试环境: 2 Linux machines, each with 8 2GHz cores, 16GB of memory, 6 disks with RAID 10. The two machines are connected with a 1Gb network link. One of the machines was used as the broker and the other machine was used as the producer or the consumer.
测试评价(by me):(1)环境过于简单,不足以说明问题。(2)对于producer持续的波动没有进行分析。(3)只有两台机器zookeeper都省了??
测试结果:如下图,完胜其他的message queue,单条消息发送(每条200bytes),能到50000messages/sec,50条batch方式发送,平均为400000messages/sec.
Kafka未来研究方向
1. 数据压缩(节省网络带宽及存储空间)
2. Broker多副本
3. 流式处理应用
原文链接:http://blog.chinaunix.net/uid-20196318-id-2420884.html
【转】KAFKA分布式消息系统的更多相关文章
- Kafka——分布式消息系统
Kafka——分布式消息系统 架构 Apache Kafka是2010年12月份开源的项目,采用scala语言编写,使用了多种效率优化机制,整体架构比较新颖(push/pull),更适合异构集群. 设 ...
- KAFKA分布式消息系统[转]
KAFKA分布式消息系统 转自:http://blog.chinaunix.net/uid-20196318-id-2420884.html Kafka[1]是linkedin用于日志处理的分布式消 ...
- 在Centos 7上安装配置 Apche Kafka 分布式消息系统集群
Apache Kafka是一种颇受欢迎的分布式消息代理系统,旨在有效地处理大量的实时数据.Kafka集群不仅具有高度可扩展性和容错性,而且与其他消息代理(如ActiveMQ和RabbitMQ)相比,还 ...
- KAFKA分布式消息系统
2015-01-05 大数据平台 Hadoop大数据平台 基本概念 kafka的工作方式和其他MQ基本相同,只是在一些名词命名上有些不同.为了更好的讨论,这里对这些名词做简单解释.通过这些解释应该可以 ...
- [转载] KAFKA分布式消息系统
转载自http://blog.chinaunix.net/uid-20196318-id-2420884.html Kafka[1]是linkedin用于日志处理的分布式消息队列,linkedin的日 ...
- Kafka 分布式消息系统详解
实际上kafka对机器的需求与Hadoop的类似. 原来,对于Linkin这样的互联网企业来说,用户和网站上产生的数据有三种: 需要实时响应的交易数据,用户提交一个表单,输入一段内容,这种数据最后是存 ...
- 分布式消息系统Kafka初步
终于可以写kafka的文章了,Mina的相关文章我已经做了索引,在我的博客中置顶了,大家可以方便的找到.从这一篇开始分布式消息系统的入门. 在我们大量使用分布式数据库.分布式计算集群的时候,是否会遇到 ...
- 分布式消息系统kafka
kafka:一个分布式消息系统 1.背景 最近因为工作需要,调研了追求高吞吐的轻量级消息系统Kafka,打算替换掉线上运行的ActiveMQ,主要是因为明年的预算日流量有十亿,而ActiveMQ的分布 ...
- 分布式消息系统Kafka初步(一) (赞)
终于可以写kafka的文章了,Mina的相关文章我已经做了索引,在我的博客中置顶了,大家可以方便的找到.从这一篇开始分布式消息系统的入门. 在我们大量使用分布式数据库.分布式计算集群的时候,是否会遇到 ...
随机推荐
- linux scull 函数open 方法
open 方法提供给驱动来做任何的初始化来准备后续的操作. 在大部分驱动中, open 应当 进行下面的工作: 检查设备特定的错误(例如设备没准备好, 或者类似的硬件错误 如果它第一次打开, 初始化设 ...
- 用生活例子来形象了解TCP-IP协议
TCP/IP模型四层协议 与 邮件? 1.应用层——与用户直接打交道 类似 要寄的物件 2.传输层——处理和增加源数据并传输到IP层 类似 快递单信息 3.IP层——分配地址和传送数据 类似 分拣站分 ...
- java编译器优化和运行期优化
概述 最近在看jvm优化,总结一下学习的相关知识 (一)javac编译器 编译过程 1.解析与填充符号表过程 1).词法.语法分析 词法分析将源代码的字符流转变为标记集合,单个字符是程序编 ...
- H3C端口状态
- python写的有声小说爬虫
querybook.py from bs4 import BeautifulSoup from lxml import html import xml import requests import s ...
- CSS3 彩色渐变动效按钮
<!DOCTYPE html> <html> <head> <title>Crayon Animate</title> <style ...
- QP简介
QP简介 QP(Quantum Platform)是一个轻量级的.开源的.基于状态机的.事件驱动型应用程序框架.这个框架包括四部分: 事件处理器(QEP): 轻量级的事件驱动框架(QF): 任务调度微 ...
- javascript 闭包的理解(一)
过很多谈如何理解闭包的方法,但大多数文章,都是照抄或者解释<Javascript高级程序设计(第三版)>对于闭包的讲解,甚至例程都不约而同的引用高程三181页‘闭包与变量’一节的那个“返回 ...
- eclipse中竖行选择代码的快捷键
Alt+Shift+A (竖行选择代码)
- Gif动图压缩java版
简单说明下,如果不是压缩动图的话只用java本身的包足够实现压缩和截取图片了,为了能够压缩gif动图,这里引用了两个文件 AnimatedGifEncoder 和 GifDecoder, 先用Deco ...