Lenet 神经网络-实现篇(2)
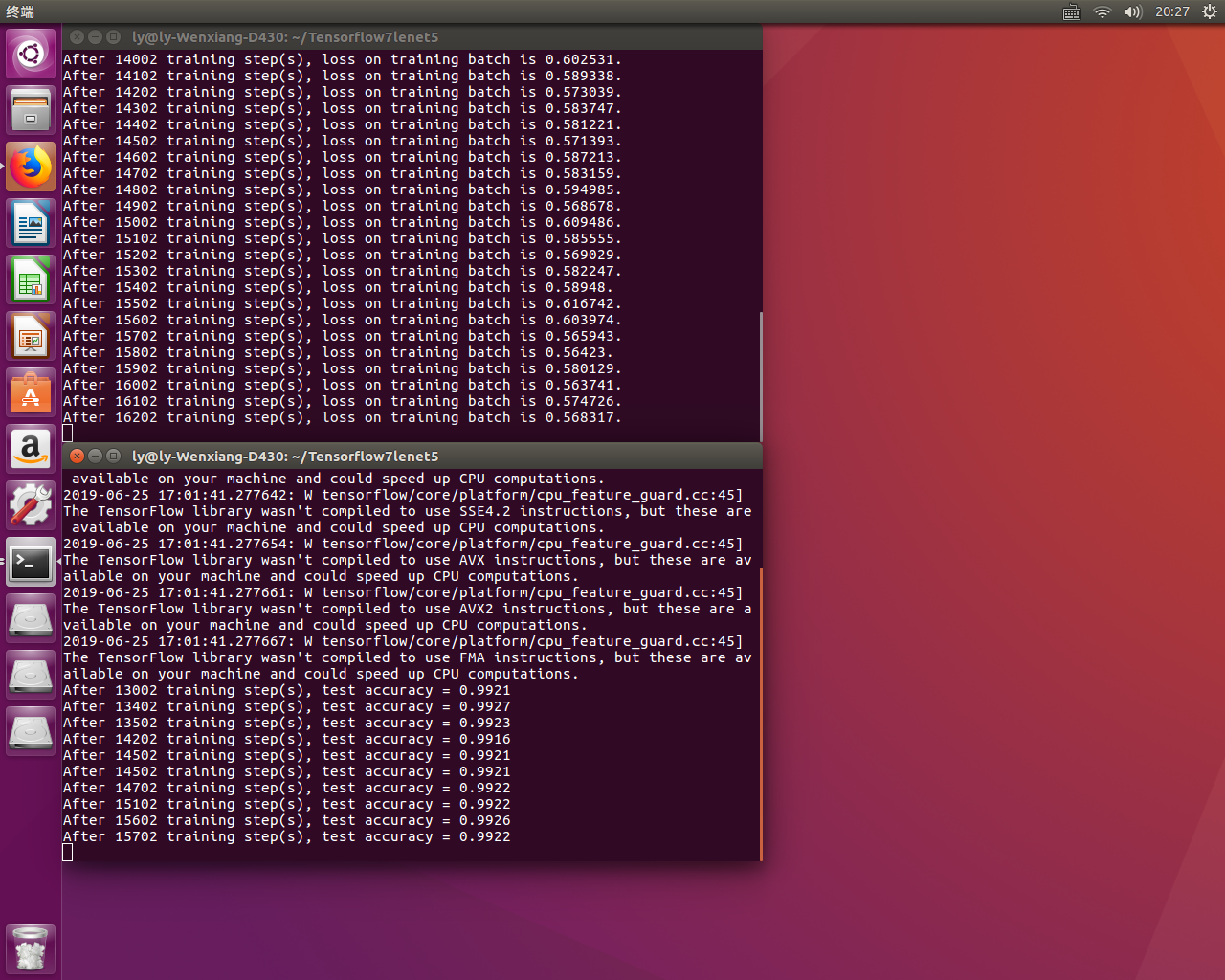
Lenet 神经网络在 Mnist 数据集上的实现,主要分为三个部分:前向传播过程(mnist_lenet5_forward.py)、反向传播过程(mnist_lenet5_backword.py)、
#coding:utf-8
import tensorflow as tf
#每张图片分辨率为28*28
IMAGE_SIZE = 28
#Mnist数据集为灰度图,故输入图片通道数NUM_CHANNELS取值为1
NUM_CHANNELS = 1
#第一层卷积核大小为5
CONV1_SIZE = 5
#卷积核个数为32
CONV1_KERNEL_NUM = 32
#第二层卷积核大小为5
CONV2_SIZE = 5
#卷积核个数为64
CONV2_KERNEL_NUM = 64
#全连接层第一层为 512 个神经元
FC_SIZE = 512
#全连接层第二层为 10 个神经元
OUTPUT_NODE = 10 #权重w计算
def get_weight(shape, regularizer):
w = tf.Variable(tf.truncated_normal(shape,stddev=0.1))
if regularizer != None: tf.add_to_collection('losses', tf.contrib.layers.l2_regularizer(regularizer)(w))
return w #偏置b计算
def get_bias(shape):
b = tf.Variable(tf.zeros(shape))
return b #卷积层计算
def conv2d(x,w):
return tf.nn.conv2d(x, w, strides=[1, 1, 1, 1], padding='SAME') #最大池化层计算
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') def forward(x, train, regularizer):
#实现第一层卷积
conv1_w = get_weight([CONV1_SIZE, CONV1_SIZE, NUM_CHANNELS, CONV1_KERNEL_NUM], regularizer)
conv1_b = get_bias([CONV1_KERNEL_NUM])
conv1 = conv2d(x, conv1_w)
#非线性激活
relu1 = tf.nn.relu(tf.nn.bias_add(conv1, conv1_b))
#最大池化
pool1 = max_pool_2x2(relu1) #实现第二层卷积
conv2_w = get_weight([CONV2_SIZE, CONV2_SIZE, CONV1_KERNEL_NUM, CONV2_KERNEL_NUM],regularizer)
conv2_b = get_bias([CONV2_KERNEL_NUM])
conv2 = conv2d(pool1, conv2_w)
relu2 = tf.nn.relu(tf.nn.bias_add(conv2, conv2_b))
pool2 = max_pool_2x2(relu2) #获取一个张量的维度
pool_shape = pool2.get_shape().as_list()
#pool_shape[1] 为长 pool_shape[2] 为宽 pool_shape[3]为高
nodes = pool_shape[1] * pool_shape[2] * pool_shape[3]
#得到矩阵被拉长后的长度,pool_shape[0]为batch值
reshaped = tf.reshape(pool2, [pool_shape[0], nodes]) #实现第三层全连接层
fc1_w = get_weight([nodes, FC_SIZE], regularizer)
fc1_b = get_bias([FC_SIZE])
fc1 = tf.nn.relu(tf.matmul(reshaped, fc1_w) + fc1_b)
#如果是训练阶段,则对该层输出使用dropout
if train: fc1 = tf.nn.dropout(fc1, 0.5) #实现第四层全连接层
fc2_w = get_weight([FC_SIZE, OUTPUT_NODE], regularizer)
fc2_b = get_bias([OUTPUT_NODE])
y = tf.matmul(fc1, fc2_w) + fc2_b
return y
#coding:utf-8
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import mnist_lenet5_forward
import os
import numpy as np #batch的数量
BATCH_SIZE = 100
#初始学习率
LEARNING_RATE_BASE = 0.005
#学习率衰减率
LEARNING_RATE_DECAY = 0.99
#正则化
REGULARIZER = 0.0001
#最大迭代次数
STEPS = 50000
#滑动平均衰减率
MOVING_AVERAGE_DECAY = 0.99
#模型保存路径
MODEL_SAVE_PATH="./model/"
#模型名称
MODEL_NAME="mnist_model" def backward(mnist):
#卷积层输入为四阶张量
#第一阶表示每轮喂入的图片数量,第二阶和第三阶分别表示图片的行分辨率和列分辨率,第四阶表示通道数
x = tf.placeholder(tf.float32,[
BATCH_SIZE,
mnist_lenet5_forward.IMAGE_SIZE,
mnist_lenet5_forward.IMAGE_SIZE,
mnist_lenet5_forward.NUM_CHANNELS])
y_ = tf.placeholder(tf.float32, [None, mnist_lenet5_forward.OUTPUT_NODE])
#前向传播过程
y = mnist_lenet5_forward.forward(x,True, REGULARIZER)
#声明一个全局计数器
global_step = tf.Variable(0, trainable=False)
#对网络最后一层的输出y做softmax,求取输出属于某一类的概率
ce = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
#向量求均值
cem = tf.reduce_mean(ce)
#正则化的损失值
loss = cem + tf.add_n(tf.get_collection('losses'))
#指数衰减学习率
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
mnist.train.num_examples / BATCH_SIZE,
LEARNING_RATE_DECAY,
staircase=True)
#梯度下降算法的优化器
#train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
train_step = tf.train.MomentumOptimizer(learning_rate,0.9).minimize(loss, global_step=global_step)
#采用滑动平均的方法更新参数
ema = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
ema_op = ema.apply(tf.trainable_variables())
#将train_step和ema_op两个训练操作绑定到train_op上
with tf.control_dependencies([train_step, ema_op]):
train_op = tf.no_op(name='train') #实例化一个保存和恢复变量的saver
saver = tf.train.Saver()
#创建一个会话
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
#通过 checkpoint 文件定位到最新保存的模型,若文件存在,则加载最新的模型
ckpt = tf.train.get_checkpoint_state(MODEL_SAVE_PATH)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path) for i in range(STEPS):
#读取一个batch数据,将输入数据xs转成与网络输入相同形状的矩阵
xs, ys = mnist.train.next_batch(BATCH_SIZE)
reshaped_xs = np.reshape(xs,(
BATCH_SIZE,
mnist_lenet5_forward.IMAGE_SIZE,
mnist_lenet5_forward.IMAGE_SIZE,
mnist_lenet5_forward.NUM_CHANNELS))
#读取一个batch数据,将输入数据xs转成与网络输入相同形状的矩阵
_, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={x: reshaped_xs, y_: ys})
if i % 100 == 0:
print("After %d training step(s), loss on training batch is %g." % (step, loss_value))
saver.save(sess, os.path.join(MODEL_SAVE_PATH, MODEL_NAME), global_step=global_step) def main():
mnist = input_data.read_data_sets("./data/", one_hot=True)
backward(mnist) if __name__ == '__main__':
main()
#coding:utf-8
import time
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import mnist_lenet5_forward
import mnist_lenet5_backward
import numpy as np TEST_INTERVAL_SECS = 5 #创建一个默认图,在该图中执行以下操作
def test(mnist):
with tf.Graph().as_default() as g:
x = tf.placeholder(tf.float32,[
mnist.test.num_examples,
mnist_lenet5_forward.IMAGE_SIZE,
mnist_lenet5_forward.IMAGE_SIZE,
mnist_lenet5_forward.NUM_CHANNELS])
y_ = tf.placeholder(tf.float32, [None, mnist_lenet5_forward.OUTPUT_NODE])
#训练好的网络,故不使用 dropout
y = mnist_lenet5_forward.forward(x,False,None) ema = tf.train.ExponentialMovingAverage(mnist_lenet5_backward.MOVING_AVERAGE_DECAY)
ema_restore = ema.variables_to_restore()
saver = tf.train.Saver(ema_restore) #判断预测值和实际值是否相同
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
## 求平均得到准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) while True:
with tf.Session() as sess:
ckpt = tf.train.get_checkpoint_state(mnist_lenet5_backward.MODEL_SAVE_PATH)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
# 根据读入的模型名字切分出该模型是属于迭代了多少次保存的
global_step = ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1]
reshaped_x = np.reshape(mnist.test.images,(
mnist.test.num_examples,
mnist_lenet5_forward.IMAGE_SIZE,
mnist_lenet5_forward.IMAGE_SIZE,
mnist_lenet5_forward.NUM_CHANNELS))
#利用多线程提高图片和标签的批获取效率
coord = tf.train.Coordinator()#
threads = tf.train.start_queue_runners(sess=sess, coord=coord)#
accuracy_score = sess.run(accuracy, feed_dict={x:reshaped_x,y_:mnist.test.labels})
print("After %s training step(s), test accuracy = %g" % (global_step, accuracy_score))
#关闭线程协调器
coord.request_stop()#
coord.join(threads)#
else:
print('No checkpoint file found')
return
time.sleep(TEST_INTERVAL_SECS) def main():
mnist = input_data.read_data_sets("./data/", one_hot=True)
test(mnist) if __name__ == '__main__':
main()
Lenet 神经网络-实现篇(2)的更多相关文章
- Lenet 神经网络-实现篇(1)
Lenet 神经网络结构为: ①输入为 32*32*1 的图片大小,为单通道的输入: ②进行卷积,卷积核大小为 5*5*1,个数为 6,步长为 1,非全零填充模式: ③将卷积结果通过非线性激活函数: ...
- Pytorch1.0入门实战一:LeNet神经网络实现 MNIST手写数字识别
记得第一次接触手写数字识别数据集还在学习TensorFlow,各种sess.run(),头都绕晕了.自从接触pytorch以来,一直想写点什么.曾经在2017年5月,Andrej Karpathy发表 ...
- 【原创 深度学习与TensorFlow 动手实践系列 - 4】第四课:卷积神经网络 - 高级篇
[原创 深度学习与TensorFlow 动手实践系列 - 4]第四课:卷积神经网络 - 高级篇 提纲: 1. AlexNet:现代神经网络起源 2. VGG:AlexNet增强版 3. GoogleN ...
- 【原创 深度学习与TensorFlow 动手实践系列 - 3】第三课:卷积神经网络 - 基础篇
[原创 深度学习与TensorFlow 动手实践系列 - 3]第三课:卷积神经网络 - 基础篇 提纲: 1. 链式反向梯度传到 2. 卷积神经网络 - 卷积层 3. 卷积神经网络 - 功能层 4. 实 ...
- TensorFlow 实战卷积神经网络之 LeNet
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习.深度学习的知识! LeNet 项目简介 1994 年深度学习三巨头之一的 Yan L ...
- 单层感知机_线性神经网络_BP神经网络
单层感知机 单层感知机基础总结很详细的博客 关于单层感知机的视频 最终y=t,说明经过训练预测值和真实值一致.下面图是sign函数 根据感知机规则实现的上述题目的代码 import numpy as ...
- Paper/ Overview | CNN(未完待续)
目录 I. 基础知识 II. 早期尝试 1. Neocognitron, 1980 2. LeCun, 1989 A. 概况 B. Feature maps & Weight sharing ...
- 人工智能系统Google开源的TensorFlow官方文档中文版
人工智能系统Google开源的TensorFlow官方文档中文版 2015年11月9日,Google发布人工智能系统TensorFlow并宣布开源,机器学习作为人工智能的一种类型,可以让软件根据大量的 ...
- Tensorflow高速入门2--实现手写数字识别
Tensorflow高速入门2–实现手写数字识别 环境: 虚拟机ubuntun16.0.4 Tensorflow 版本号:0.12.0(仅使用cpu下) Tensorflow安装见: http://b ...
随机推荐
- LeetCodeTwo Sum IV 树的遍历+Hash大法好
题意 给定一颗二叉搜索树,返回是否存在两个节点的值之和为给定值K. 思路 同Two Sum.使用Hash表解决.只是要写个树的遍历而已,选取DFS. 源码 class Solution { publi ...
- 简单scrapy爬虫实例
简单scrapy爬虫实例 流程分析 抓取内容:网站课程 页面:https://edu.hellobi.com 数据:课程名.课程链接及学习人数 观察页面url变化规律以及页面源代码帮助我们获取所有数据 ...
- AspxDashboardView 更新参数
AspxDashboardView 更新参数 function SetThrendDashboardView() { console.log("就是这样被你征服"); var to ...
- 未安装Oracle数据库,使用PL\SQL Developer连接远程数据库解决方案
使用PL/SQL远程连接Oracle服务器 背景:本地未安装oracle数据库服务器,希望远程连接Oracle服务器 1.下载oracle数据库客户端 下载64位windows的instantclie ...
- c++ 踩坑大法好 枚举
1,枚举是个啥? c++允许程序员创建自己的数据类型,枚举数据类型是程序员自定义的一种数据类型,其值是一组命名整数常量. ,wed,thu,fri,sat,sun}; //定义一个叫day的数据类型, ...
- 登录时 按Enter 进入登录界面 或者下一行
function keyLogin() { if (event.keyCode == 13) //回车键的键值为13 $(".btn-submit").click(); //调用登 ...
- FOJ-2013 A Short Problem (前缀和)
Problem Description The description of this problem is very short. Now give you a string(length N), ...
- 小匠第二周期打卡笔记-Task03
一.过拟合欠拟合及其解决方案 知识点记录 模型选择.过拟合和欠拟合: 训练误差和泛化误差: 训练误差 :模型在训练数据集上表现出的误差, 泛化误差 : 模型在任意一个测试数据样本上表现出的误差的期望, ...
- C++-对象指针的滥用
C++ 中经常出现使用对象指针,而不是直接使用对象本身的代码,比如下面这个例子: Object *myObject = new Object; 而不是使用: myObject.testFunc(); ...
- python3 win 建立虚拟环境(virtualenv)
1.安装virtualenv pip3 install virtualenv 2.进入即将创建虚拟环境的目录 cd xxxx 3.创建虚拟环境 py -3 -m venv testxunihua 4. ...