吴裕雄 python 机器学习——集成学习AdaBoost算法回归模型
import numpy as np
import matplotlib.pyplot as plt from sklearn import datasets,ensemble
from sklearn.model_selection import train_test_split def load_data_classification():
'''
加载用于分类问题的数据集
'''
# 使用 scikit-learn 自带的 digits 数据集
digits=datasets.load_digits()
# 分层采样拆分成训练集和测试集,测试集大小为原始数据集大小的 1/4
return train_test_split(digits.data,digits.target,test_size=0.25,random_state=0,stratify=digits.target) #集成学习AdaBoost算法回归模型
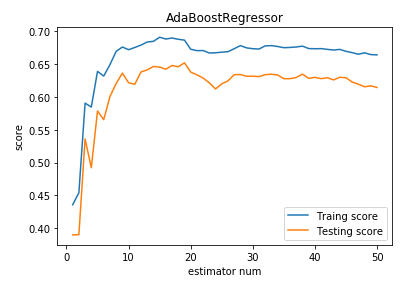
def test_AdaBoostRegressor(*data):
'''
测试 AdaBoostRegressor 的用法,绘制 AdaBoostRegressor 的预测性能随基础回归器数量的影响
'''
X_train,X_test,y_train,y_test=data
regr=ensemble.AdaBoostRegressor()
regr.fit(X_train,y_train)
## 绘图
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
estimators_num=len(regr.estimators_)
X=range(1,estimators_num+1)
ax.plot(list(X),list(regr.staged_score(X_train,y_train)),label="Traing score")
ax.plot(list(X),list(regr.staged_score(X_test,y_test)),label="Testing score")
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc="best")
ax.set_title("AdaBoostRegressor")
plt.show() # 获取分类数据
X_train,X_test,y_train,y_test=load_data_classification()
# 调用 test_AdaBoostRegressor
test_AdaBoostRegressor(X_train,X_test,y_train,y_test)
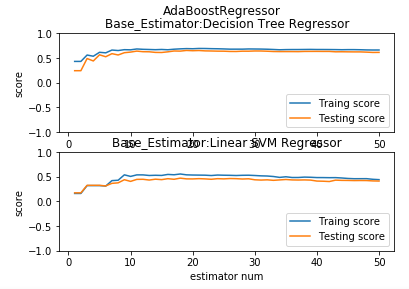
def test_AdaBoostRegressor_base_regr(*data):
'''
测试 AdaBoostRegressor 的预测性能随基础回归器数量的和基础回归器类型的影响
'''
from sklearn.svm import LinearSVR X_train,X_test,y_train,y_test=data
fig=plt.figure()
regrs=[ensemble.AdaBoostRegressor(), # 基础回归器为默认类型
ensemble.AdaBoostRegressor(base_estimator=LinearSVR(epsilon=0.01,C=100))] # 基础回归器为 LinearSVR
labels=["Decision Tree Regressor","Linear SVM Regressor"]
for i ,regr in enumerate(regrs):
ax=fig.add_subplot(2,1,i+1)
regr.fit(X_train,y_train)
## 绘图
estimators_num=len(regr.estimators_)
X=range(1,estimators_num+1)
ax.plot(list(X),list(regr.staged_score(X_train,y_train)),label="Traing score")
ax.plot(list(X),list(regr.staged_score(X_test,y_test)),label="Testing score")
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(-1,1)
ax.set_title("Base_Estimator:%s"%labels[i])
plt.suptitle("AdaBoostRegressor")
plt.show() # 调用 test_AdaBoostRegressor_base_regr
test_AdaBoostRegressor_base_regr(X_train,X_test,y_train,y_test)
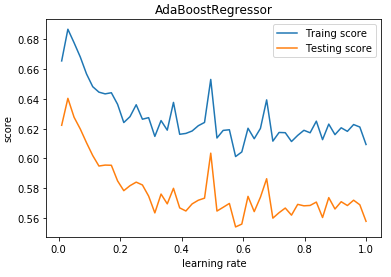
def test_AdaBoostRegressor_learning_rate(*data):
'''
测试 AdaBoostRegressor 的预测性能随学习率的影响
'''
X_train,X_test,y_train,y_test=data
learning_rates=np.linspace(0.01,1)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
traing_scores=[]
testing_scores=[]
for learning_rate in learning_rates:
regr=ensemble.AdaBoostRegressor(learning_rate=learning_rate,n_estimators=500)
regr.fit(X_train,y_train)
traing_scores.append(regr.score(X_train,y_train))
testing_scores.append(regr.score(X_test,y_test))
ax.plot(learning_rates,traing_scores,label="Traing score")
ax.plot(learning_rates,testing_scores,label="Testing score")
ax.set_xlabel("learning rate")
ax.set_ylabel("score")
ax.legend(loc="best")
ax.set_title("AdaBoostRegressor")
plt.show() # 调用 test_AdaBoostRegressor_learning_rate
test_AdaBoostRegressor_learning_rate(X_train,X_test,y_train,y_test)
def test_AdaBoostRegressor_loss(*data):
'''
测试 AdaBoostRegressor 的预测性能随损失函数类型的影响
'''
X_train,X_test,y_train,y_test=data
losses=['linear','square','exponential']
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
for i ,loss in enumerate(losses):
regr=ensemble.AdaBoostRegressor(loss=loss,n_estimators=30)
regr.fit(X_train,y_train)
## 绘图
estimators_num=len(regr.estimators_)
X=range(1,estimators_num+1)
ax.plot(list(X),list(regr.staged_score(X_train,y_train)),label="Traing score:loss=%s"%loss)
ax.plot(list(X),list(regr.staged_score(X_test,y_test)),label="Testing score:loss=%s"%loss)
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(-1,1)
plt.suptitle("AdaBoostRegressor")
plt.show() # 调用 test_AdaBoostRegressor_loss
test_AdaBoostRegressor_loss(X_train,X_test,y_train,y_test)

吴裕雄 python 机器学习——集成学习AdaBoost算法回归模型的更多相关文章
- 吴裕雄 python 机器学习——集成学习AdaBoost算法分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestClassifier分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习梯度提升决策树GradientBoostingRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——人工神经网络与原始感知机模型
import numpy as np from matplotlib import pyplot as plt from mpl_toolkits.mplot3d import Axes3D from ...
- 吴裕雄 python 机器学习——等度量映射Isomap降维模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
- 吴裕雄 python 机器学习——多维缩放降维MDS模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
- 吴裕雄 python 机器学习——多项式贝叶斯分类器MultinomialNB模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,naive_bayes from skl ...
- 吴裕雄 python 机器学习——数据预处理二元化OneHotEncoder模型
from sklearn.preprocessing import OneHotEncoder #数据预处理二元化OneHotEncoder模型 def test_OneHotEncoder(): X ...
随机推荐
- tcolorbox 宏包简明教程
嗯,我消失好几天了.那么,我都在做什么呢?没错,就是写这篇文章了.这篇文章写起来着实有些费神了.于是,如果你觉得这篇文章对你有帮助,不妨扫描文末的二维码,适量赞助一下哦~! tcolorbox 宏包是 ...
- (转)正则表达式:string.replaceAll()中的特殊字符($ \)与matcher.appendReplacement
string.replaceAll中的特殊字符 string.replaceAll(String regex, String replacement)中的replacement参数即替换内容中含有特殊 ...
- Spring-JDBCTemplate介绍
一.Spring对不同的持久化支持: Spring为各种支持的持久化技术,都提供了简单操作的模板和回调 ORM持久化技术 模板类 JDBC org.springframework.jdbc.c ...
- 刷题76. Minimum Window Substring
一.题目说明 题目76. Minimum Window Substring,求字符串S中最小连续字符串,包括字符串T中的所有字符,复杂度要求是O(n).难度是Hard! 二.我的解答 先说我的思路: ...
- Docker+JMeter单机版+MinIO
基于JMeter5.1.1+MinIO JMeter发起压测 MinIO作为文件服务器 一.目录结构: Dockerfile文件: FROM ubuntu:18.04# 基础镜像 MAINTAINE ...
- 数据库Dao层编增删改查写,数据库事务,数据库升级
数据库事务 有两个特点 1.安全性 情景:正常的转账行为,这个时候如果出现停电等异常,已经扣钱但是没有加钱:这个时候就可用数据库事务解决问题 2.高效性: 使用数据库事务添加享受同数量的数据,对比耗时 ...
- 牛客CSP-S提高组赛前集训营2 赛后总结
比赛链接 A.服务器需求 维护每天需要的服务器数量的全局最大值(记为\(Max\))和总和(记为\(sum\)),那么答案为: \[max(Max,\lceil\dfrac{sum}{m}\rceil ...
- 【HTML】如何在网页中屏蔽右键 ?
如何在网页中屏蔽右键 众所周知,要保护一个页面,最基础的就是要屏蔽右键.而现在网页上用得最多的是function click(),即下面这段代码: <script> function ...
- [CF1220C] Substring Game in the Lesson - 博弈论
[CF1220C] Description 给定一个字符串 \(S\) , 同时维护一个区间 \([l,r]\) .轮流操作,每次可以扩展到一个新区间使得原区间是新区间的真子区间,并且字典序更小,不能 ...
- jQuery jqgrid 应用实例
1.html <div class="ibox-content"> <div class=\"jqGrid_wrapper\"> < ...